







 本文介绍了如何使用Python爬虫技术获取2020东京奥运会各国奖牌数据,详细讲述了从数据爬取、数据处理到数据可视化的全过程,包括各国金、银、铜牌奖牌榜的爬取,数据整合,以及通过世界地图和多系列柱状图进行可视化展示。
本文介绍了如何使用Python爬虫技术获取2020东京奥运会各国奖牌数据,详细讲述了从数据爬取、数据处理到数据可视化的全过程,包括各国金、银、铜牌奖牌榜的爬取,数据整合,以及通过世界地图和多系列柱状图进行可视化展示。
爬取数据1
1、数据来源:https://2020.cctv.com/medal_list/index.shtml
数据为下面图片的表格数据

2、具体代码
2.1需要提前下载好的pip install 库名
from selenium import webdriver
import lxml.html
import csv
2.2获取网页完整代码
#自动打开chrome,获取代码
driver = webdriver.Chrome('D:\\数据分析\\chromedriver_win32\\chromedriver.exe')
driver.get('https://2020.cctv.com/medal_list/index.shtml')
content=driver.page_source
driver.quit() #关闭chrome
2.3本地创建 .csv,存储爬下来的数据
f = open('nation_data.csv', 'w' , encoding='utf-8')
csv_writer = csv.writer(f)
#表头
csv_writer.writerow((["排名", "国家", "金牌", "银牌", "铜牌", "总数"]))
2.4定位xpath,写入文件
metree = lxml.html.etree
parser = metree.HTML(content)
td_list = parser.xpath("/html/body/div[3]/div/div/div/div[1]/div[3]/div[2]/div/div[3]/table/tbody[@id='medal_list1']//tr")
for td_item in td_list:
num_item= td_item.xpath('.//text()')
csv_writer.writerow(num_item)
f.close() #关闭文件
2.5.csv无乱码转换,请看我的另一篇文章https://blog.csdn.net/weixin_44394124/article/details/120097063?spm=1001.2014.3001.5501

爬取出来的部分数据如图所示
数据爬取2
1、爬取每个国家的金、银、铜牌奖牌榜,如下图(中国和美国)
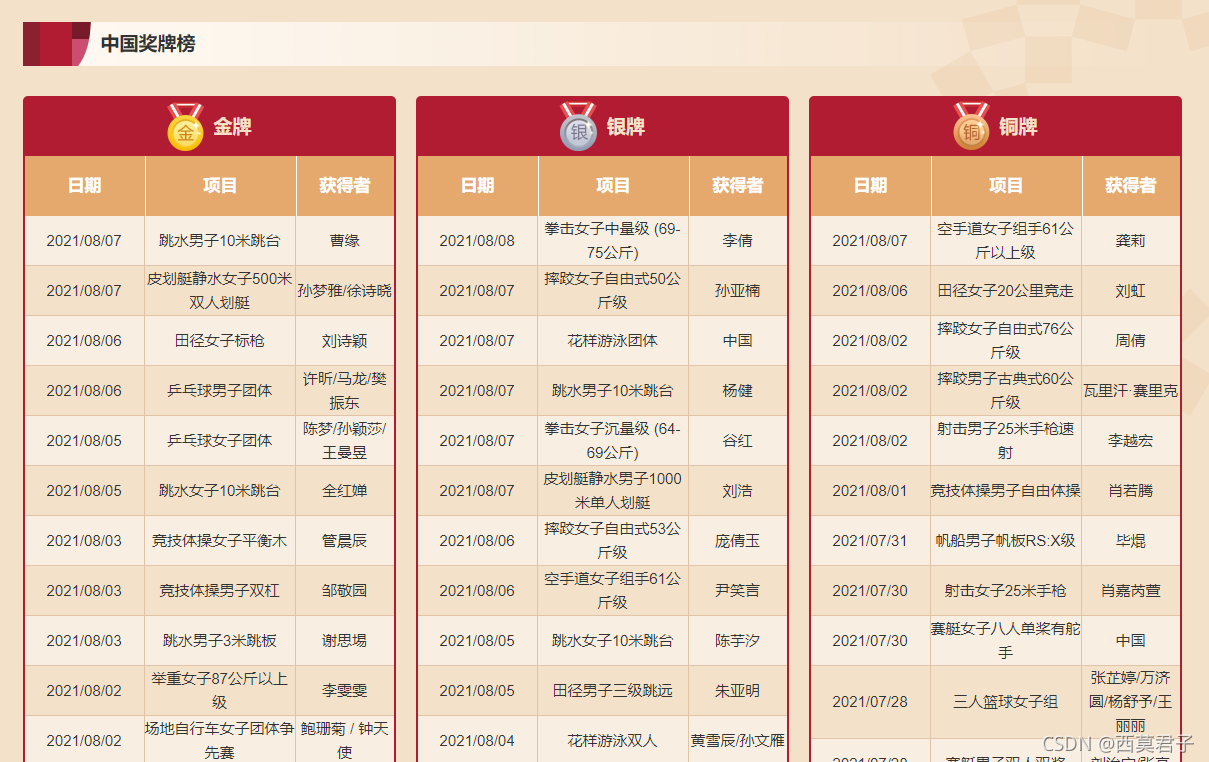

页面来源:
https://2020.cctv.com/medal_list/details/index.shtml?countryid=USA
https://2020.cctv.com/medal_list/details/index.shtml?countryidCHN
https://2020.cctv.com/medal_list/details/index.shtml?countryidJPN
可以看出除了countryid={}不同,其他都相同
2、三字母国家代码
(http://api.cntv.cn/olympic/getOlyMedals?serviceId=pcocean&itemcode=GEN-------------------------------&t=jsonp&cb=banomedals)来源,如下图

复制到nation.txt文件
然后通过
import pandas as pd
file = open('D:\\Olympic_Games\\nation.txt', 'r', encoding='utf-8')
strfile = file.read()
s1=strfile.split('},{')
nat_list=[]
for i in s1:
nat_list.append(i[-4:-1])
file.close()
#nation_data最加一列
csv_data = pd.read_csv('nation_data.csv', low_memory = False)#example.csv是需要被追加的CSV文件,low_memory防止弹出警告
csv_df = pd.DataF 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1363
1363

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









