







目录
前言
目前,计算机的硬件条件已经大大改善,即使是在普通的笔记本电脑上,多核都已经是标配了,更不用说专业的服务器了。如果跑在强劲服务器机器上的应用程序依然是单线程架构,那实在是有点暴殄天物了。不过,Kafka Java Consumer 就是单线程的设计,你是不是感到很惊讶。所以,探究它的多线程消费方案,就显得非常必要了。
kafka consumer 设计原理
从 Kafka 0.10.1.0 版本开始,KafkaConsumer 就变为了双线程的设计,即用户主线程和心跳线程。
所谓用户主线程,就是你启动 Consumer 应用程序 main 方法的那个线程,而新引入的心跳线程(Heartbeat Thread)只负责定期给对应的 Broker 机器发送心跳请求,以标识消费者应用的存活性(liveness)。引入这个心跳线程还有一个目的,那就是期望它能将心跳频率与主线程调用 KafkaConsumer.poll 方法的频率分开,从而解耦真实的消息处理逻辑与消费者组成员存活性管理。
单线程的设计能够简化 Consumer 端的设计。Consumer 获取到消息后,处理消息的逻辑是否采用多线程,完全由你决定。这样,你就拥有了把消息处理的多线程管理策略从 Consumer 端代码中剥离的权利。
多线程的方案
我们要明确的是,KafkaConsumer 类不是线程安全的 (thread-safe)。所有的网络 I/O 处理都是发生在用户主线程中,因此,你在使用过程中必须要确保线程安全。简单来说,不能在多个线程中共享同一个 KafkaConsumer 实例,否则程序会抛出 ConcurrentModificationException 异常。
由于kafka consumer不是线程安全,我么你能制定两种多线程的方案。
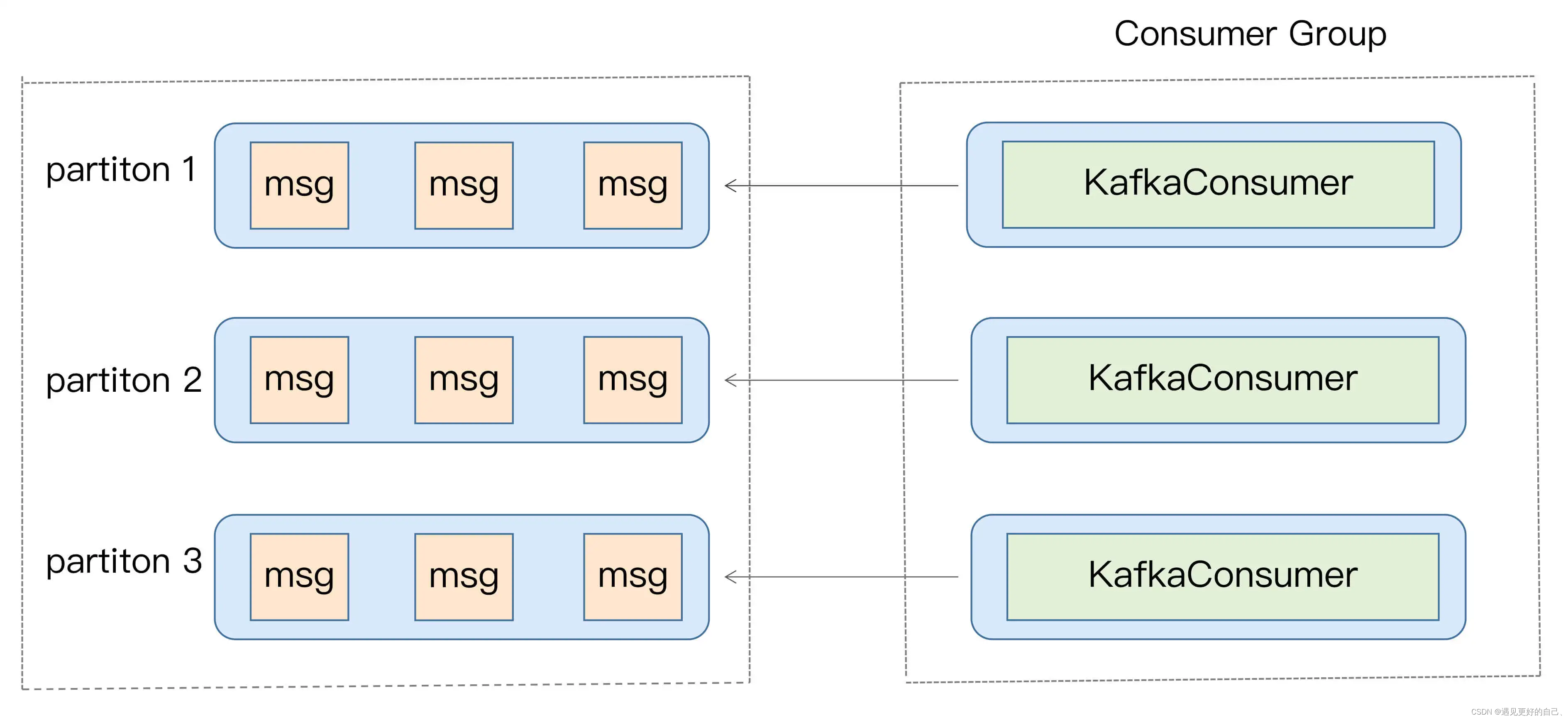
1.消费者程序启动多个线程,每个线程维护专属的 KafkaConsumer 实例,负责完整的消息获取、消息处理流程。如下图所示:
2.消费者程序使用单或多线程获取消息,同时创建多个消费线程执行消息处理逻辑。获取消息的线程可以是一个,也可以是多个,每个线程维护专属的 KafkaConsumer 实例,处理消息则交由特定的线程池来做,从而实现消息获取与消息处理的真正解耦。具体架构如下图所示:
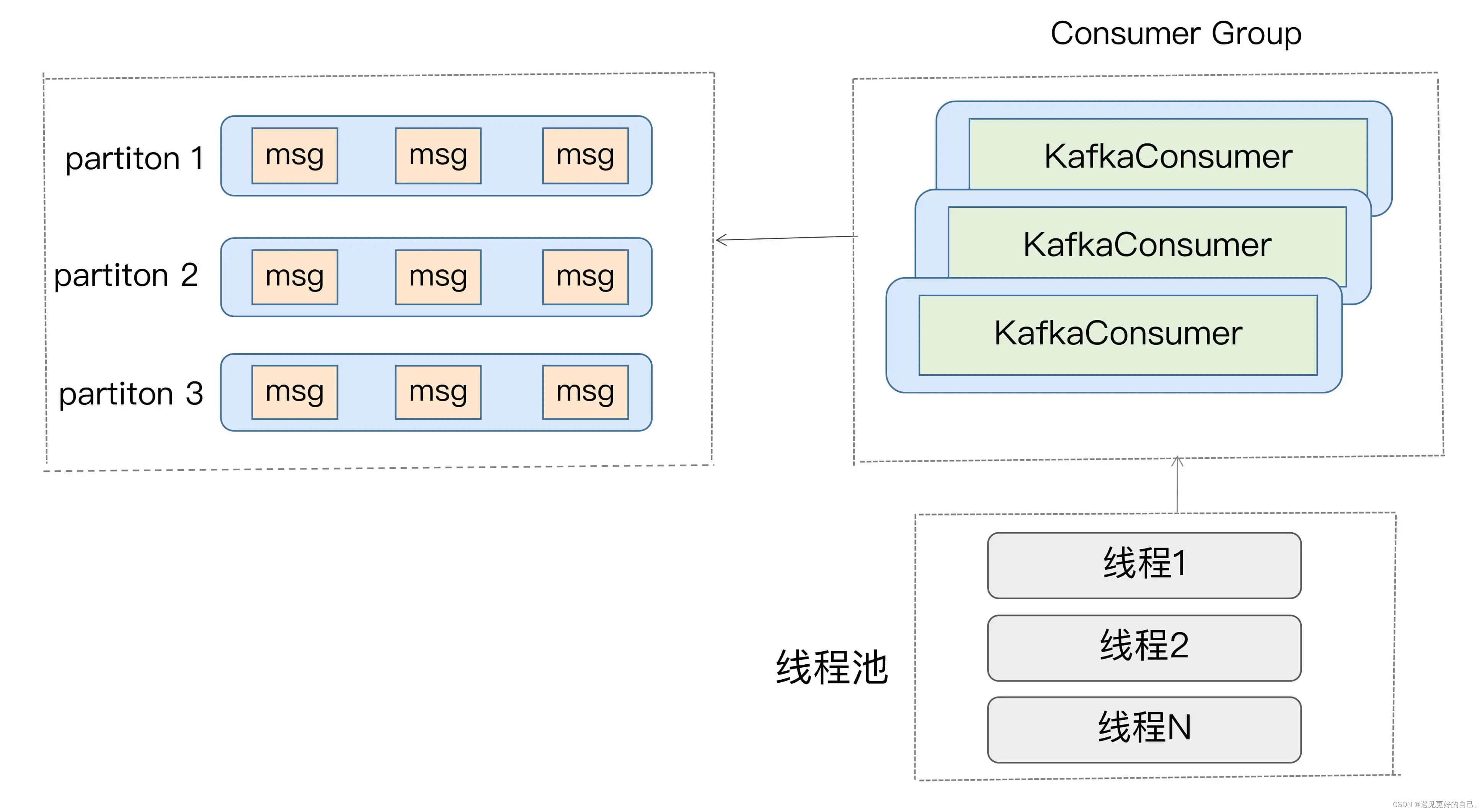
我们来打个比方。比如一个完整的消费者应用程序要做的事情是 1、2、3、4、5,那么方案 1 的思路是粗粒度化的工作划分,也就是说方案 1 会创建多个线程,每个线程完整地执行 1、2、3、4、5,以实现并行处理的目标,它不会进一步分割具体的子任务;而方案 2 则更细粒度化,它会将 1、2 分割出来,用单线程(也可以是多线程)来做,对于 3、4、5,则用另外的多个线程来做。
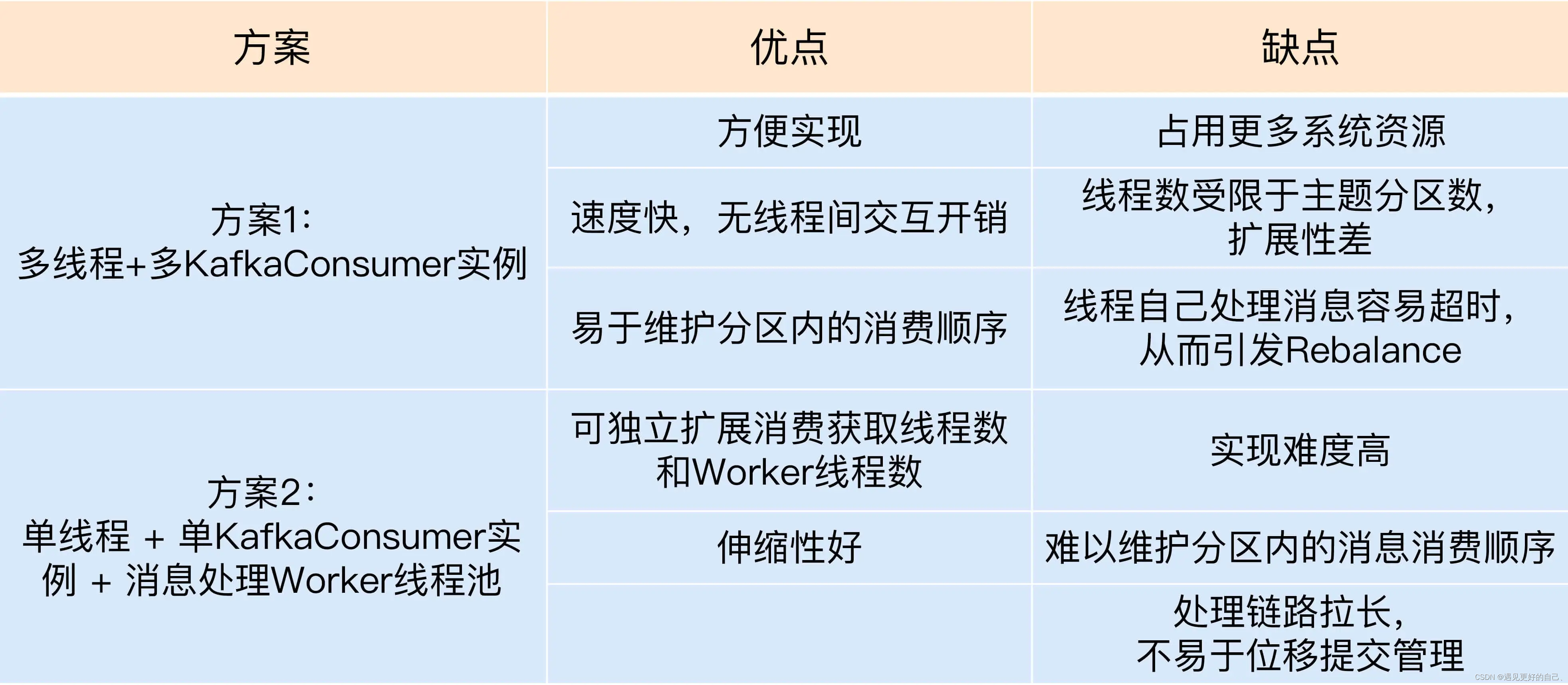
这两种方案的比较如下:
实现代码示例如下:
方案一的代码:
public class KafkaConsumerRunner implements Runnable {
private final AtomicBoolean closed = new AtomicBoolean(false);
private final KafkaConsumer consumer;
public void run() {
try {
consumer.subscribe(Arrays.asList("topic"));
while (!closed.get()) {
ConsumerRecords records =
consumer.poll(Duration.ofMillis(10000));
// 执行消息处理逻辑
}
} catch (WakeupException e) {
// Ignore exception if closing
if (!closed.get()) throw e;
} finally {
consumer.close();
}
}
// Shutdown hook which can be called from a separate thread
public void shutdown() {
closed.set(true);
consumer.wakeup();
}这段代码创建了一个 Runnable 类,表示执行消费获取和消费处理的逻辑。每个 KafkaConsumerRunner 类都会创建一个专属的 KafkaConsumer 实例。在实际应用中,你可以创建多个 KafkaConsumerRunner 实例,并依次执行启动它们,以实现方案 1 的多线程架构
方案2 的代码:
private final KafkaConsumer<String, String> consumer;
private ExecutorService executors;
...
private int workerNum = ...;
executors = new ThreadPoolExecutor(
workerNum, workerNum, 0L, TimeUnit.MILLISECONDS,
new ArrayBlockingQueue<>(1000),
new ThreadPoolExecutor.CallerRunsPolicy());
...
while (true) {
ConsumerRecords<String, String> records =
consumer.poll(Duration.ofSeconds(1));
for (final ConsumerRecord record : records) {
executors.submit(new Worker(record));
}
}
..














 7537
7537











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









