









今天是2020.10.01,是个喜庆的日子,中秋和国庆同天贺。祝福祖国越来越好,祝福普天下的家庭幸福美满。今天,主要介绍一下数据结构中的优先队列(PriorityQueue)如何使用Python实现以及优先队列的应用之海量数据中如何寻找K大数。
什么是优先队列(取自百度百科)?
普通的队列是一种先进先出的数据结构,元素在队列尾追加,而从队列头删除。在优先队列中,元素被赋予优先级。当访问元素时,具有最高优先级的元素最先删除。优先队列具有最高级先出 (first in, largest out)的行为特征。通常采用堆数据结构来实现。通俗一些描述就是,出队的时候,元素按照优先级进行出队。
优先队列不再遵循先入先出的原则,而是分为两种情况:
- 最大优先队列,无论入队顺序,当前最大的元素优先出队。
- 最小优先队列,无论入队顺序,当前最小的元素优先出队。
比如有一个最大优先队列,它的最大元素是8,那么虽然元素8并不是队首元素,但出队的时候仍然让元素8首先出队:

要满足以上需求,利用线性数据结构并非不能实现,但是时间复杂度较高,最坏时间复杂度O(n),并不是最理想的方式。其实借助二叉堆可以大大降低时间复杂度。如下介绍。
二叉堆特性
- 最大堆的堆顶是整个堆中的最大元素
- 最小堆的堆顶是整个堆中的最小元素
因此,用最大堆来实现最大优先队列,每一次入队操作就是堆的插入操作,每一次出队操作就是删除堆顶节点。如下演示:
借助堆实现优先队列
入队操作(插入元素5):
(1) 首先将元素5插入到树的末尾
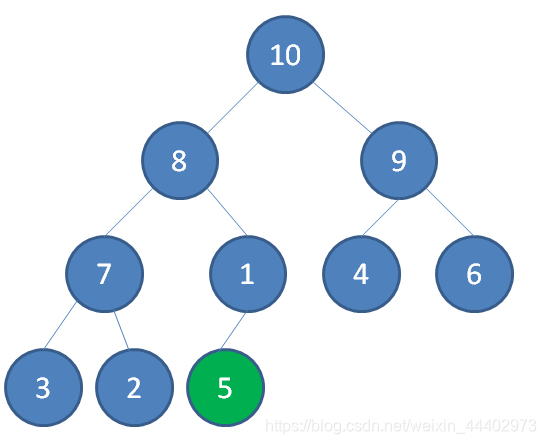
(2) 向上调整,找到5合适位置,使得满足大根堆
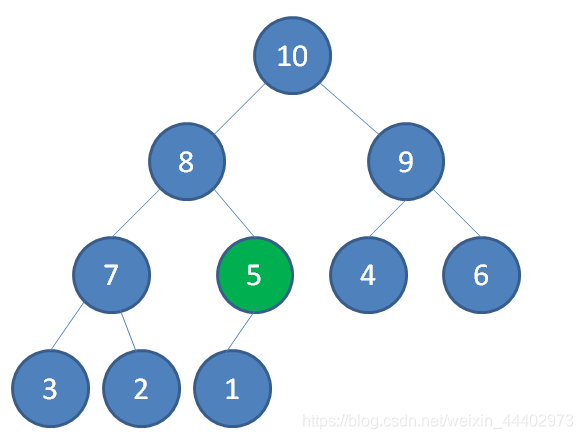
出队操作(删除根节点):
(1).把原堆顶节点10“出队”
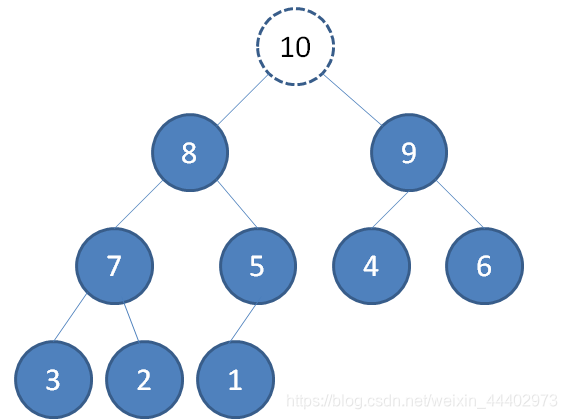
(2).最后一个节点1替换到堆顶位置
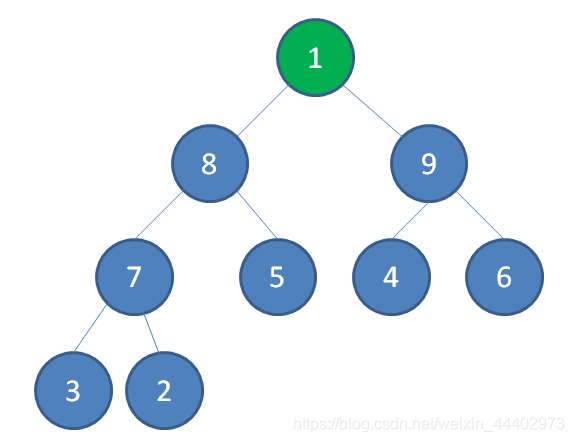
(3).节点1下沉,节点9成为新堆顶
代码实现
# coding:utf-8
'''
普通队列:先进先出,插入在队尾,删除在队头
优先队列:优先队列具有最高级先出 (first in, largest out)的行为特征。通常采用堆数据结构来实现。
堆是完全二叉树
'''
class priorityQueue(object):
def __init__(self):
self.queue = []
def put(self,val):
# 向最小堆中插入元素,需要调整,直到满足最小堆的要求
self.queue.append(val)
cur = len(self.queue) - 1
while cur > 0:
parent = (cur - 1) // 2
if self.queue[parent] > self.queue[cur]:
self.queue[parent],self.queue[cur] = self.queue[cur],self.queue[parent]
else:
break
cur = parent
def get(self):
first = self.top()
last = self.queue.pop()
if not self.empty():
self.queue[0] = last
cur = 0
while cur < len(self.queue):
left = 2 * cur + 1
right = 2 * cur + 2
if left >= len(self.queue) or right >= len(self.queue):
break
if self.queue[cur] <= min(self.queue[left],self.queue[right]):
break
if self.queue[left] < self.queue[right]:
self.queue[left],self.queue[cur] = self.queue[cur],self.queue[left]
cur = left
else:
self.queue[right],self.queue[cur] = self.queue[cur],self.queue[right]
cur = right
return first
def find(self,val):
return val in self.queue
def getIndex(self,index):
if index >= len(self.queue):
raise Exception("The index is out of range!")
return self.queue[index]
def top(self):
# 取堆的根元素
if self.empty():
raise Exception("The Queue is Empty!")
return self.queue[0]
def empty(self):
return len(self.queue) == 0海量数据中寻找K大数
借助python优先队列包来实现优先队列。时间复杂度为nlog(k).
# coding:utf-8
from queue import PriorityQueue
# 适合海量数据的o(nlogk)的方法
def heapFindNk(nums,k):
pq = PriorityQueue()
for num in nums:
pq.put(num)
if pq.qsize() > k:
pq.get()
res = []
while pq.qsize():
res.append(pq.get())
return res
nums = [4,5,1,2,0]
k = 2
print(heapFindNk(nums,k))
参考博客:
https://www.sohu.com/a/256022793_478315
https://baike.baidu.com/item/%E4%BC%98%E5%85%88%E9%98%9F%E5%88%97/9354754?fr=aladdin


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









