









论文题目:Dynamic Convolution: Attention over Convolution Kernels
前几天发布了关于动态卷积CondConv的文章.今天,我想介绍另一种类型动态卷积Dynamic Convolution,相关文章链接在本文的开头已经给出,感兴趣的可以自己去下载并阅读.最近发现这个卷积的研究比较热门,研究者们试图要打破常规卷积对数据"一视同仁"的思想,设计一种依赖于输入样本的卷积即每个样本的拥有各自的卷积权重,并非"一视同仁",而是"厚此薄彼".
本文将分几个章节进行阐述,并在最后给出Pytorch的具体实现.
Dynamic Convolution解决问题
轻量级的网络和高性能的深度网络相比,网络的深度和通道受到了约束,导致网络的性能下降,特征的表达能力有限,网络的识别性能下降.为此,作者设计了Dynamic Convolution来在不增加网络宽度和深度的情况下,提升模型的表达能力.
Dynamic Convolution的思想
为了在网络的性能和计算负载中寻求平衡,通过多卷积核融合提升模型表达能力。需要注意的是:所得卷积核与输入相关,即不同数据具有不同的卷积,这也就是动态卷积的由来。
动态感知器模型
作者通过感知器模型引出了动态卷积,我们设感知器模型如下图,W,b,g分别表示权重,偏置和激活函数.
![]()
动态感知器的定义如下图,动态感知器模型如图(1),它的权值和偏置分别是通过(2)和(3)中多个权值和偏置通过加权求和得到的,(4)表示对权值系数的约束这里权值系数不是固定的,而是随着输入数据的变化而变化,具有更强的特征表达能力.动态卷积Dynamic Convolution和动态感知器中W和b计算一样.
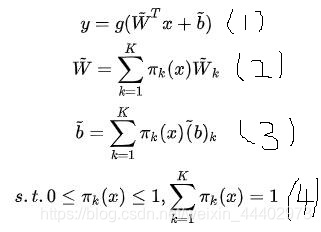
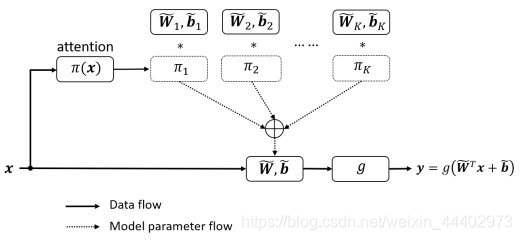
动态感知器的图解如下图所示,和上图公式表达是吻合的.
作者也指出:相比静态感知器,动态感知器需要两个额外的计算:(a)注意力权值计算;(2)动态权值融合。尽管如此,这两点额外计算相比感知器的计算量可以忽略:
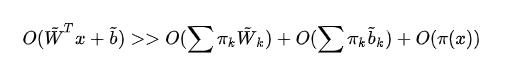
Dynamic Convolution设计和实现
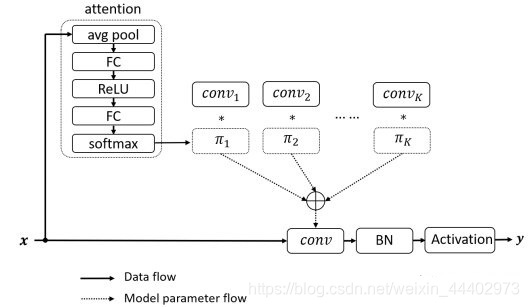
相比动态感知器,Dynamic Convolution的权值通过多个卷积核来实现,每个卷积核都有各自的权重系,权重系数是通过输入数据x通过GAP操作得到的,GAP是指上图attention,得到权值系数后和对应卷积进行相乘,之后求和得到最终的卷积权重,之后和x进行矩阵乘法得到输出,完成Dynamic Convolution操作.
Dynamic Convolution代码实现(Pytorch)
GAP代码实现:
class attention2d(nn.Module):
def __init__(self, in_planes, K,):
super(attention2d, self).__init__()
self.avgpool = nn.AdaptiveAvgPool2d(1)
self.fc1 = nn.Conv2d(in_planes, K, 1,)
self.fc2 = nn.Conv2d(K, K, 1,)
def forward(self, x):
x = self.avgpool(x)
x = self.fc1(x)
x = F.relu(x)
x = self.fc2(x).view(x.size(0), -1)
return F.softmax(x, 1)Dynamic Convolution实现代码
class Dynamic_conv2d(nn.Module):
def __init__(self, in_planes, out_planes, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True, K=4,):
super(Dynamic_conv2d, self).__init__()
assert in_planes%groups==0
self.in_planes = in_planes
self.out_planes = out_planes
self.kernel_size = kernel_size
self.stride = stride
self.padding = padding
self.dilation = dilation
self.groups = groups
self.bias = bias
self.K = K
self.attention = attention2d(in_planes, K, )
self.weight = nn.Parameter(torch.Tensor(K, out_planes, in_planes//groups, kernel_size, kernel_size), requires_grad=True)
if bias:
self.bias = nn.Parameter(torch.Tensor(K, out_planes))
else:
self.bias = None
def forward(self, x):#将batch视作维度变量,进行组卷积,因为组卷积的权重是不同的,动态卷积的权重也是不同的
softmax_attention = self.attention(x)
batch_size, in_planes, height, width = x.size()
x = x.view(1, -1, height, width)# 变化成一个维度进行组卷积
weight = self.weight.view(self.K, -1)
# 动态卷积的权重的生成, 生成的是batch_size个卷积参数(每个参数不同)
aggregate_weight = torch.mm(softmax_attention, weight).view(self.out_planes, -1, self.kernel_size, self.kernel_size)
if self.bias is not None:
aggregate_bias = torch.mm(softmax_attention, self.bias).view(-1)
output = F.conv2d(x, weight=aggregate_weight, bias=aggregate_bias, stride=self.stride, padding=self.padding,
dilation=self.dilation, groups=self.groups*batch_size)
else:
output = F.conv2d(x, weight=aggregate_weight, bias=None, stride=self.stride, padding=self.padding,
dilation=self.dilation, groups=self.groups * batch_size)
output = output.view(batch_size, self.out_planes, output.size(-2), output.size(-1))
return outputDynamic Convolution实验
将经典卷积网络中传统卷积替换为Dynamic Convolution前后实验对比:
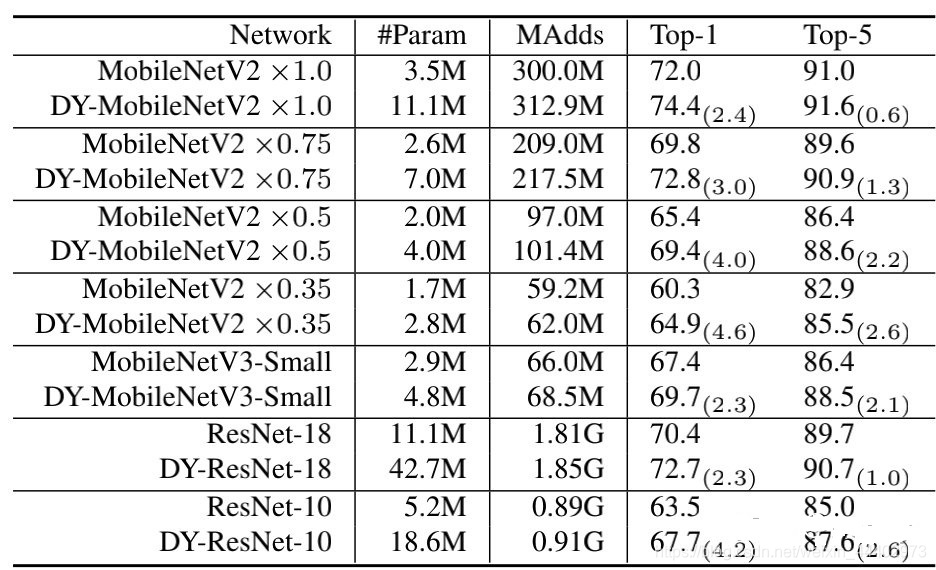
具体细节可以自己下载论文看看.谢谢大家!!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









