






暑期没有事情干,寻思学学数据挖掘,本篇博客也是我初学MATLAB情况下写的(代码可直接放在一个文件里)。
一方面我想加深自己的理解,另一方面希望可以给使用MATLAB并学习决策树而感到无法下手的读者一个参考,了解到我每一个环节的处理,顺便说一下,我对数据集采用了10次10折交叉验证;当然,我对代码的理解远没有到那种如臂指使,心之所向、代码即往的境界,没有什么妙手,因此读者请放心并耐心查看(这些代码不长也多有重复)。本篇博文也只是抛砖引玉,以此来引出那些珠玉。毕竟独学而无友,则孤陋而寡闻。
废话不说,直接开始。巧妇难为无米之炊,手法再高明,没有数据也只能是悻悻然干瞪眼。我们所用的数据是UCI的wine数据,网址如下:https://archive.ics.uci.edu/ml/datasets/Wine
至于怎么处理数据,请参考这篇博文:https://blog.csdn.net/qq_32892383/article/details/82225663#title1
既然你学到了决策树,那那些算法ID3、ID4你肯定听过,那些不纯性度量你也一定知道,但在这我还是列一下三种熵度量:
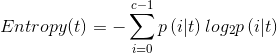
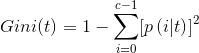
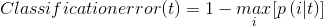
我们选择的是第一种信息熵度量。
- 首先处理数据
clear
clc
f=fopen('C:\Users\HP\Desktop\大数据\wine.data');
wine=textscan(f,'%f%f%f%f%f%f%f%f%f%f%f%f%f%f','delimiter',',');
fclose(f);
%将标签放在最后一列
[m,n]=size(wine);
for i=1:n-1
data(:,i)=wine{:,i+1};
end
data(:,n)=wine{:,1};
- 我们的计算就围绕计算熵算起的,所以我们需要写一个计算熵的函数。这里排除了0*log0=NaN的情况
%%
%计算熵的函数
function [Ent_A,Ent_B]=Ent(data,lamda)
%data为按照某一属性排列后的数据集
%lamda记录按某一属性排序后二分的位置
c=3; %c作为label类别数
[m,n]=size(data);
data1=data(1:lamda,:);
data2=data(lamda+1:end,:);
Ent_A=0; Ent_B=0;
%计算熵
for i=1:c
data1_p(i)=sum(data1(:,n)==i)/lamda;
if data1_p(i)~=0
Ent_A=Ent_A-data1_p(i)*log2(data1_p(i));
end
data2_p(i)=sum(data2(:,n)==i)/(m-lamda);
if data2_p(i)~=0
Ent_B=Ent_B-data2_p(i)*log2(data2_p(i));
end
end
end
- 这只是计算熵,接下来我们怎么哪一个是最优属性呢?所以我们写了一个函数,寻找最优属性,并顺带返回它的最优化分数值即阈(yu)值。本来最大化信息增益,就是最小化均值熵的问题,我也不需要计算信息增益。但是在这里多此一举的原因,我看见一个练习题:说将结点划分为更小的后继结点后,结点熵不会增加。(这本书叫数据挖掘导论,Pang-Ning Tan等著)我对我没有数学过程证明的结论感到心里没底,我自己又不想去思考这样的问题,想着验证一下如果计算的信息增益Gain<0,那么这个结论就错了。请原谅我的懒得动脑。
- 我还要再说的一点是:因为它们是连续值,不像离散属性一样,用了这个属性就不会再用了,还会再次用到。因为你很难保证依照某一属性划分后的样本,不再以这个属性划分类别。
%%
%寻找最优化分属性 attribute
%最优化分数值 value
%划分位置 lamda
function [attribute,value,lamda]=pre(data);
total_attribute=13; %属性个数
Ent_parent=0; %父节点熵
c=3;
[m,n]=size(data);
for j=1:c
data_p(j)=sum(data(:,n)==j)/m;
if data_p(j)~=0
Ent_parent=Ent_parent-data_p(j)*log2(data_p(j));
end
end
%计算最优化分属性
min_Ent=inf;
for i=1:total_attribute
data=sortrows(data,i);
for j=1:m-1
if data(j,n)~=data(j+1,n)
[Ent_A,Ent_B]=Ent(data,j);
Ent_pre=Ent_A*j/m+Ent_B*(m-j)/m;
if Ent_pre<min_Ent
min_Ent=Ent_pre;
%记录此时的划分数值和属性
attribute=i;
value=data(j,i);
lamda=j;
end
end
end
%信息增益
gain=Ent_parent-min_Ent;
if gain<0
disp('算法有误,请重新设计');
return
end
end
end
- 找到了最优化分属性,就可以建立决策树分类了,采用递归建立决策树。一旦你熟悉了递归,你就可以说是一个中级的level了。这里我在主程序中选取的精确度P是90%,就是一个样本中90%以上的样本都为同一类的就不需要再次建立判断条件了。
- %%
%建立决策树
%P控制精确度,防止分支过多,即过拟合现象
function tree=decision_tree(data,P)
[m,n]=size(data);
c=3;
tree=struct('value','null','left','null','right','null');
[attribute,value,lamda]=pre(data);
data=sortrows(data,attribute);
tree.value=[attribute,value];
tree.left=data(1:lamda,:);
tree.right=data(lamda+1:end,:);
%终止构建条件
for i=1:c
left_label(i)=sum(tree.left(:,n)==i);
right_label(i)=sum(tree.right(:,n)==i);
end
[num,max_label]=max(left_label);
if num~=lamda&&(num/lamda)<P
tree.left=decision_tree(tree.left,P);
else
tree.left=[max_label num];
end
[num,max_label]=max(right_label);
if num~=(m-lamda)&&(num/(m-lamda))<P
tree.right=decision_tree(tree.right,P);
else
tree.right=[max_label num];
end
end
- 然而,虽然我们得到了决策树的结构,但总免不了一些人的苛刻要求,有没有图啊。想来也是,毕竟图更明显嘛!所以我们为了画出这个树状图,需要做一些准备,这只是准备,显现还在主程序里了。以下程序的写法参考了一下这篇博文:
- https://blog.csdn.net/sinat_31857633/article/details/82693202
%%
%数据可视化,准备绘树状图
%nodes为0
%iter为1,记录迭代次数
%A记录了树状图的节点信息,包括treeplot的结点序列
function [A,iter]=print_tree(tree,A,iter,nodes)
A{iter,1}=strcat('attribute:',num2str(tree.value(1)));
A{iter,2}=strcat('阈值:',num2str(tree.value(2)));
A{iter,3}=nodes;
iter=iter+1;nodes=iter-1;
if isstruct(tree.left)
[A,iter]=print_tree(tree.left,A,iter,nodes);
else
A{iter,1}=strcat('label:',num2str(tree.left(1)));
A{iter,2}=strcat('个数:',num2str(tree.left(2)));
A{iter,3}=nodes;
iter=iter+1;
end
if isstruct(tree.right)
[A,iter]=print_tree(tree.right,A,iter,nodes);
else
A{iter,1}=strcat('label:',num2str(tree.right(1)));
A{iter,2}=strcat('个数:',num2str(tree.right(2)));
A{iter,3}=nodes;
iter=iter+1;
end
end
- 照理说这里决策树的建立再加一个主程序就结束了,但是我前面说了我对数据集采用了10次10折交叉验证,所以还要写一个测试树的函数。
%%
%计算测试集正确、错误类别个数
function [right,error]=testtree(tree,test,right,error)
%right代表测试集中判断正确类别的个数
%error代表测试集中判断错误类别的个数
attribute=tree.value(1);
value=tree.value(2);
test_left=test(find(test(:,attribute)<=value),:);
test_right=test(find(test(:,attribute)>value),:);
if isstruct(tree.left)
[right,error]=testtree(tree.left,test_left,right,error);
else
[m,n]=size(test_left);
for i=1:m
if test_left(i,n)==tree.left(1)
right=right+1;
else
error=error+1;
end
end
end
if isstruct(tree.right)
[right,error]=testtree(tree.right,test_right,right,error);
else
[m,n]=size(test_right);
for i=1:m
if test_right(i,n)==tree.right(1)
right=right+1;
else
error=error+1;
end
end
end
end
再加上主程序:
%%
%主程序
%交叉验证
%10次10折交叉验证划分数据集
cov_iter=1;%交叉验证迭代次数
k=10;%划分10个子集
while cov_iter<=k
train=data;
train_index=0;
test_index=1;
for i=1:3
s=sum(data(:,n)==i);
total=round(s/k);
sel=randperm(s,total);
test(test_index:test_index+total-1,:)=data(train_index+sel,:);
train(train_index+sel,:)=[];
train_index=train_index+s-total;
test_index=test_index+total;
end
P=0.9;
tree=decision_tree(train,P);
[right,error]=testtree(tree,test,0,0);
accuracy(cov_iter)=right/(right+error);
cov_iter=cov_iter+1;
end
display(strcat('测试集平均准确率为',num2str(mean(accuracy)*100),'%'));
%绘制决策树模型
A={};%A为节点描述
iter=1;%iter为迭代次数
nodes=0;%根节点序列
[A,~]=print_tree(tree,A,iter,nodes);
[m,n]=size(A);
for i=1:m
nodes(i)=A{i,n};
name1{1,i}=A{i,1};
name2{1,i}=A{i,2};
end
treeplot(nodes);
[x,y]=treelayout(nodes);
for i=1:m
text(x(1,i),y(1,i),{[name1{1,i}];[name2{1,i}]},'VerticalAlignment','bottom','HorizontalAlignment','center')
end
title(strcat('葡萄酒决策树 精度为',num2str(P*100),'%'));
到这里就结束了。合起来,我们的程序就是(大家只需要改一下打开的文件名那里就可以运行啦)以下,如果你看了连运行都不会,我只能说:呵呵!因为这些代码都是本人编写并确认无误的,没有错误。在以下附上我们的图片和结果:
clear
clc
f=fopen('C:\Users\HP\Desktop\大数据\wine.data');
wine=textscan(f,'%f%f%f%f%f%f%f%f%f%f%f%f%f%f','delimiter',',');
fclose(f);
%将标签放在最后一列
[m,n]=size(wine);
for i=1:n-1
data(:,i)=wine{:,i+1};
end
data(:,n)=wine{:,1};
%%
%主程序
%交叉验证
%10次10折交叉验证划分数据集
cov_iter=1;%交叉验证迭代次数
k=10;%划分10个子集
while cov_iter<=k
train=data;
train_index=0;
test_index=1;
for i=1:3
s=sum(data(:,n)==i);
total=round(s/k);
sel=randperm(s,total);
test(test_index:test_index+total-1,:)=data(train_index+sel,:);
train(train_index+sel,:)=[];
train_index=train_index+s-total;
test_index=test_index+total;
end
P=0.9;
tree=decision_tree(train,P);
[right,error]=testtree(tree,test,0,0);
accuracy(cov_iter)=right/(right+error);
cov_iter=cov_iter+1;
end
display(strcat('测试集平均准确率为',num2str(mean(accuracy)*100),'%'));
%绘制决策树模型
A={};%A为节点描述
iter=1;%iter为迭代次数
nodes=0;%根节点序列
[A,~]=print_tree(tree,A,iter,nodes);
[m,n]=size(A);
for i=1:m
nodes(i)=A{i,n};
name1{1,i}=A{i,1};
name2{1,i}=A{i,2};
end
treeplot(nodes);
[x,y]=treelayout(nodes);
for i=1:m
text(x(1,i),y(1,i),{[name1{1,i}];[name2{1,i}]},'VerticalAlignment','bottom','HorizontalAlignment','center')
end
title(strcat('葡萄酒决策树 精度为',num2str(P*100),'%'));
%%
%计算熵的函数
function [Ent_A,Ent_B]=Ent(data,lamda)
%data为按照某一属性排列后的数据集
%lamda记录按某一属性排序后二分的位置
c=3; %c作为label类别数
[m,n]=size(data);
data1=data(1:lamda,:);
data2=data(lamda+1:end,:);
Ent_A=0; Ent_B=0;
%计算熵
for i=1:c
data1_p(i)=sum(data1(:,n)==i)/lamda;
if data1_p(i)~=0
Ent_A=Ent_A-data1_p(i)*log2(data1_p(i));
end
data2_p(i)=sum(data2(:,n)==i)/(m-lamda);
if data2_p(i)~=0
Ent_B=Ent_B-data2_p(i)*log2(data2_p(i));
end
end
end
%%
%寻找最优化分属性 attribute
%最优化分数值 value
function [attribute,value,lamda]=pre(data);
total_attribute=13; %属性个数
Ent_parent=0; %父节点熵
c=3;
[m,n]=size(data);
for j=1:c
data_p(j)=sum(data(:,n)==j)/m;
if data_p(j)~=0
Ent_parent=Ent_parent-data_p(j)*log2(data_p(j));
end
end
%计算最优化分属性
min_Ent=inf;
for i=1:total_attribute
data=sortrows(data,i);
for j=1:m-1
if data(j,n)~=data(j+1,n)
[Ent_A,Ent_B]=Ent(data,j);
Ent_pre=Ent_A*j/m+Ent_B*(m-j)/m;
if Ent_pre<min_Ent
min_Ent=Ent_pre;
%记录此时的划分数值和属性
attribute=i;
value=data(j,i);
lamda=j;
end
end
end
%信息增益
gain=Ent_parent-min_Ent;
if gain<0
disp('算法有误,请重新设计');
return
end
end
end
%%
%建立决策树
%P控制精确度,防止分支过多,即过拟合现象
function tree=decision_tree(data,P)
[m,n]=size(data);
c=3;
tree=struct('value','null','left','null','right','null');
[attribute,value,lamda]=pre(data);
data=sortrows(data,attribute);
tree.value=[attribute,value];
tree.left=data(1:lamda,:);
tree.right=data(lamda+1:end,:);
%终止构建条件
for i=1:c
left_label(i)=sum(tree.left(:,n)==i);
right_label(i)=sum(tree.right(:,n)==i);
end
[num,max_label]=max(left_label);
if num~=lamda&&(num/lamda)<P
tree.left=decision_tree(tree.left,P);
else
tree.left=[max_label num];
end
[num,max_label]=max(right_label);
if num~=(m-lamda)&&(num/(m-lamda))<P
tree.right=decision_tree(tree.right,P);
else
tree.right=[max_label num];
end
end
%%
%数据可视化,准备绘树状图
function [A,iter]=print_tree(tree,A,iter,nodes)
A{iter,1}=strcat('attribute:',num2str(tree.value(1)));
A{iter,2}=strcat('阈值:',num2str(tree.value(2)));
A{iter,3}=nodes;
iter=iter+1;nodes=iter-1;
if isstruct(tree.left)
[A,iter]=print_tree(tree.left,A,iter,nodes);
else
A{iter,1}=strcat('label:',num2str(tree.left(1)));
A{iter,2}=strcat('个数:',num2str(tree.left(2)));
A{iter,3}=nodes;
iter=iter+1;
end
if isstruct(tree.right)
[A,iter]=print_tree(tree.right,A,iter,nodes);
else
A{iter,1}=strcat('label:',num2str(tree.right(1)));
A{iter,2}=strcat('个数:',num2str(tree.right(2)));
A{iter,3}=nodes;
iter=iter+1;
end
end
%%
%计算测试集正确、错误类别个数
function [right,error]=testtree(tree,test,right,error)
%right代表测试集中判断正确类别的个数
%error代表测试集中判断错误类别的个数
attribute=tree.value(1);
value=tree.value(2);
test_left=test(find(test(:,attribute)<=value),:);
test_right=test(find(test(:,attribute)>value),:);
if isstruct(tree.left)
[right,error]=testtree(tree.left,test_left,right,error);
else
[m,n]=size(test_left);
for i=1:m
if test_left(i,n)==tree.left(1)
right=right+1;
else
error=error+1;
end
end
end
if isstruct(tree.right)
[right,error]=testtree(tree.right,test_right,right,error);
else
[m,n]=size(test_right);
for i=1:m
if test_right(i,n)==tree.right(1)
right=right+1;
else
error=error+1;
end
end
end
end
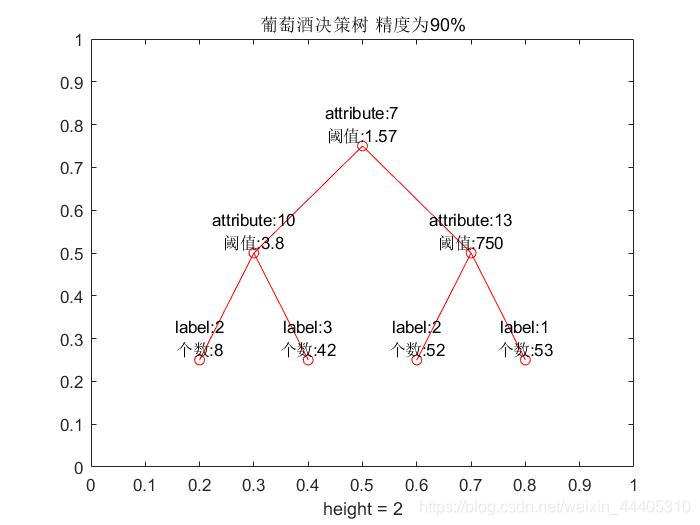
测试集平均准确率为95.5556%














 1004
1004











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









