







 本文详细介绍了SQL查询中常见的需求,包括筛选语文成绩低于60的学生、按平均成绩排序、汇总各科成绩统计、排名以及使用临时表进行复杂查询。讲解了多种方法,如casewhen、表连接、开窗函数和子查询的应用。
本文详细介绍了SQL查询中常见的需求,包括筛选语文成绩低于60的学生、按平均成绩排序、汇总各科成绩统计、排名以及使用临时表进行复杂查询。讲解了多种方法,如casewhen、表连接、开窗函数和子查询的应用。
目录
最流行的查询需求分析03
演示数据准备的SQL
需求演示
16、查询 "01"语文课程分数小于60,按分数降序排列的学生信息
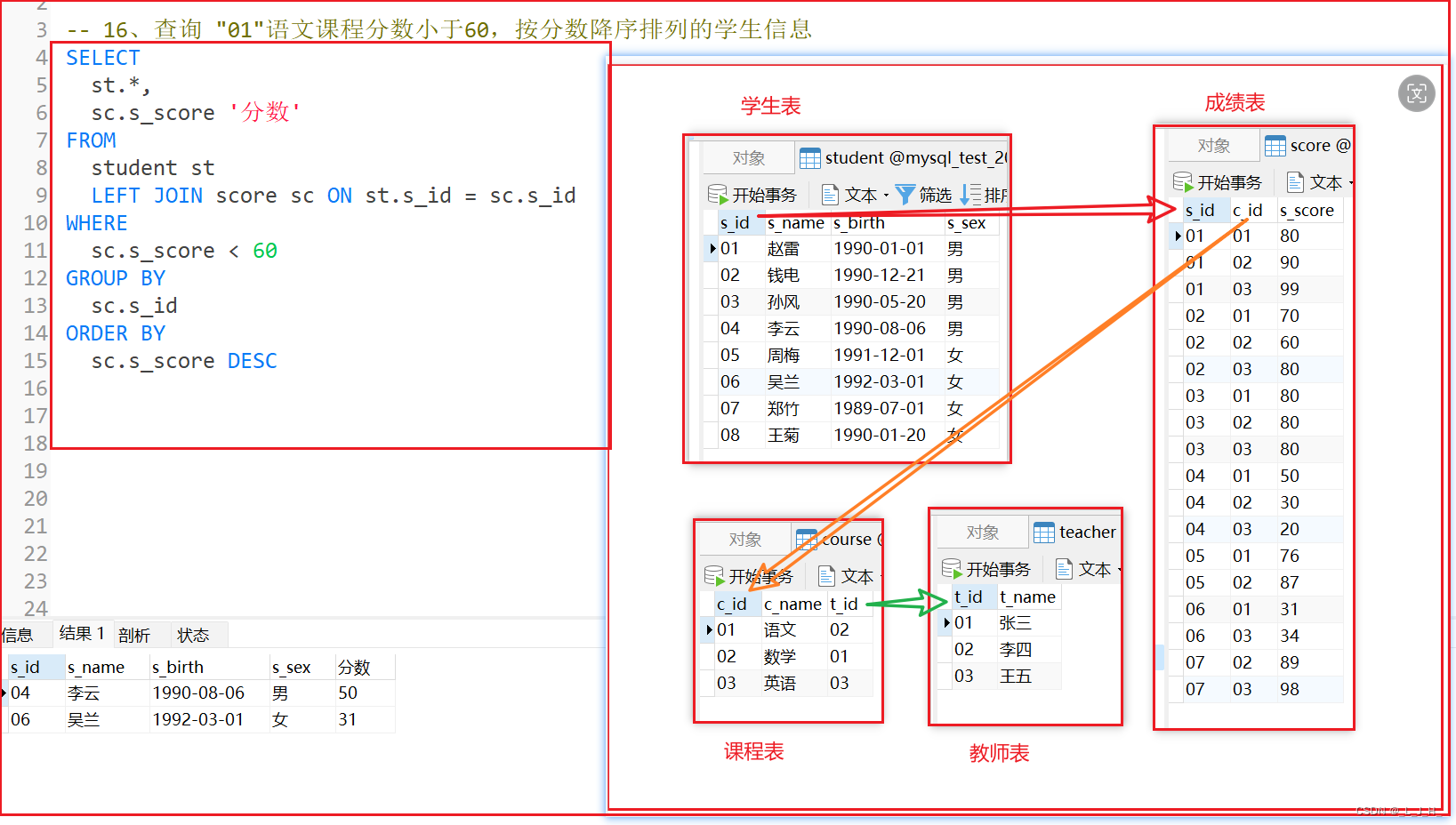
-- 16、查询 "01"语文课程分数小于60,按分数降序排列的学生信息
SELECT
st.*,
sc.s_score '分数'
FROM
student st
LEFT JOIN score sc ON st.s_id = sc.s_id
WHERE
sc.s_score < 60
GROUP BY
sc.s_id
ORDER BY
sc.s_score DESC
17、按平均成绩从高到低显示所有学生的所有课程的成绩以及平均成绩
写法1:使用 case when来把几个课程成绩弄成一行数据
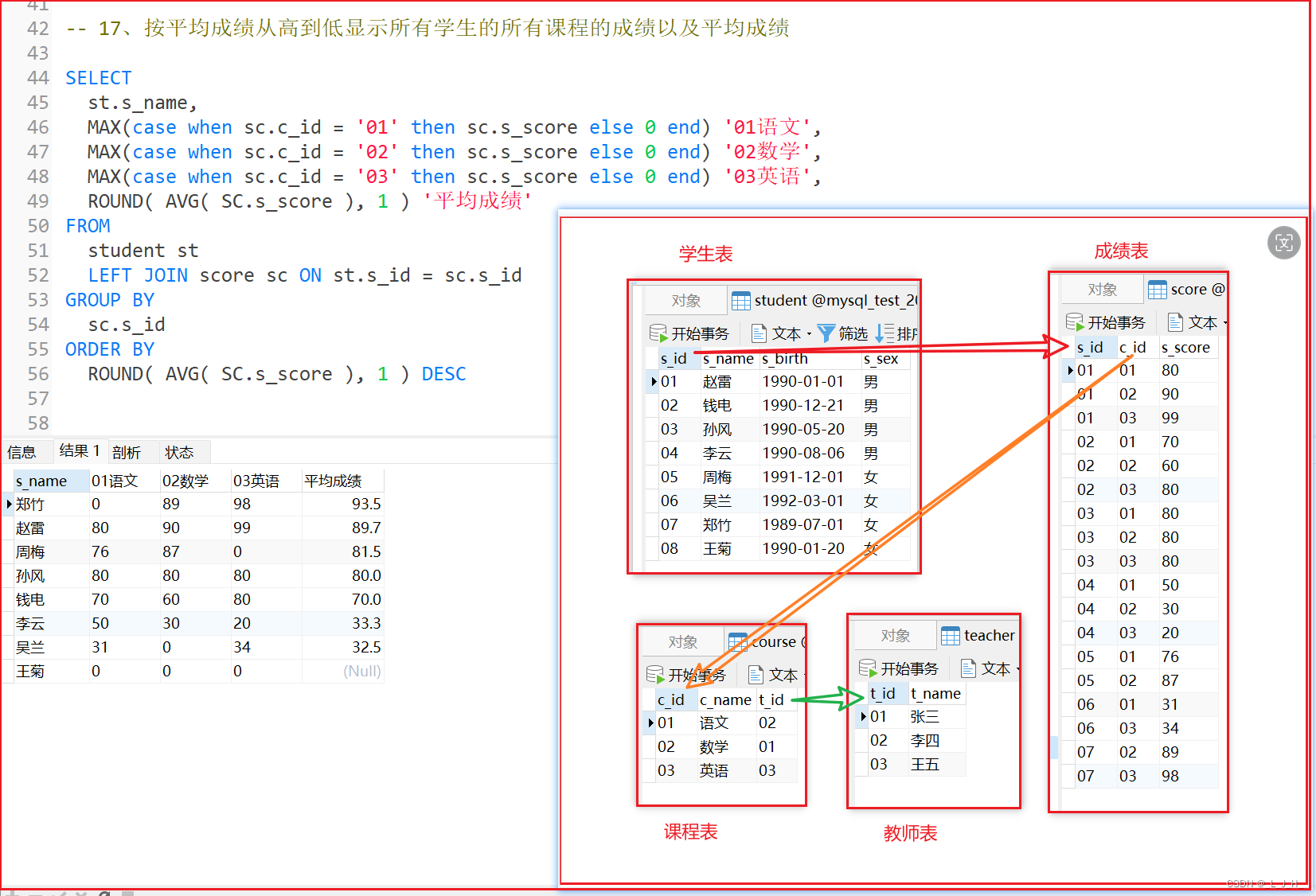
-- 17、按平均成绩从高到低显示所有学生的所有课程的成绩以及平均成绩
-- 写法1:
SELECT
st.s_name,
MAX(case when sc.c_id = '01' then sc.s_score else 0 end) '01语文',
MAX(case when sc.c_id = '02' then sc.s_score else 0 end) '02数学',
MAX(case when sc.c_id = '03' then sc.s_score else 0 end) '03英语',
ROUND( AVG( SC.s_score ), 1 ) '平均成绩'
FROM
student st
LEFT JOIN score sc ON st.s_id = sc.s_id
GROUP BY
sc.s_id
ORDER BY
ROUND( AVG( SC.s_score ), 1 ) DESC
写法2:使用简单的表连接
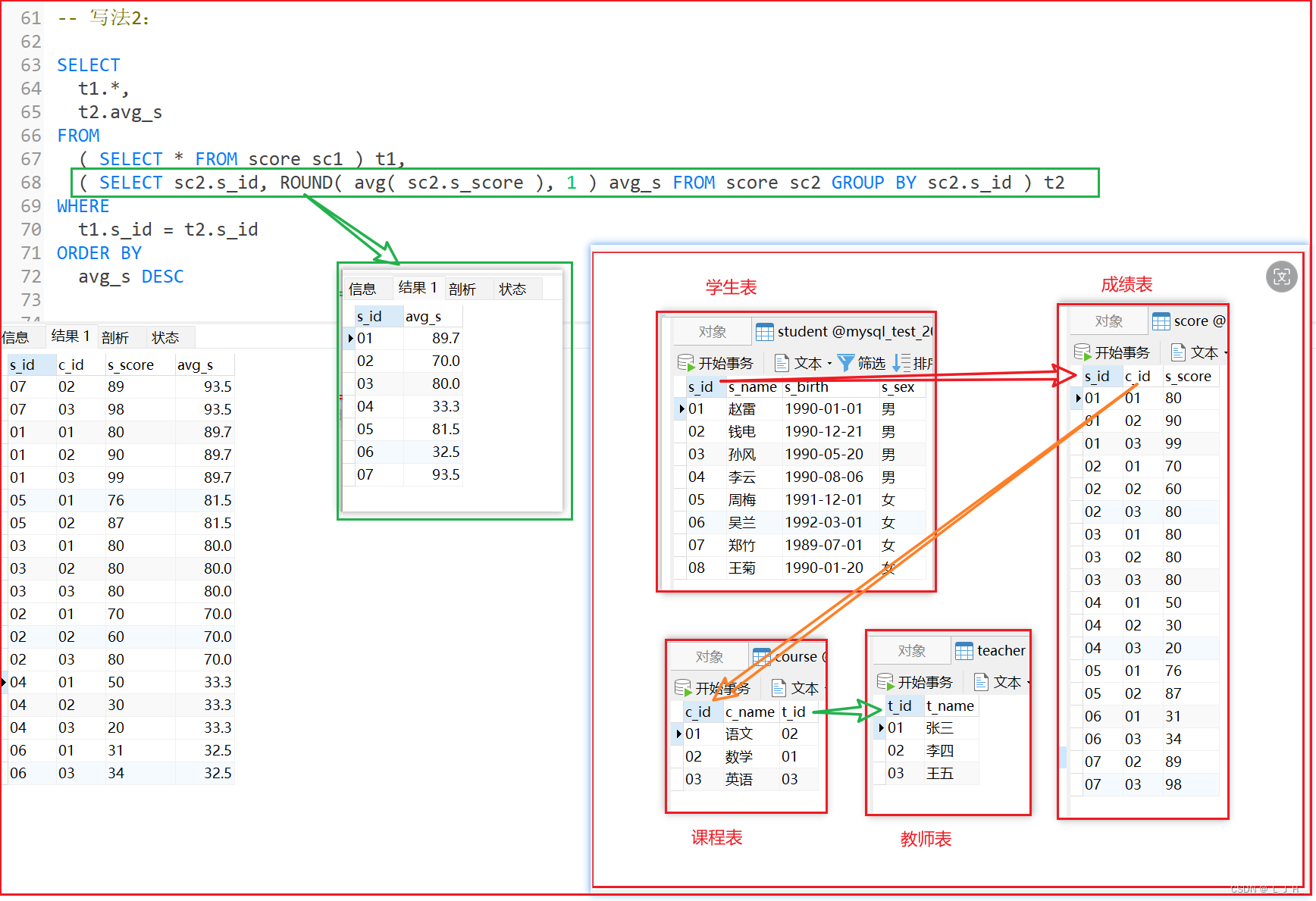
-- 写法2:
SELECT
t1.*,
t2.avg_s
FROM
( SELECT * FROM score sc1 ) t1,
( SELECT sc2.s_id, ROUND( avg( sc2.s_score ), 1 ) avg_s FROM score sc2 GROUP BY sc2.s_id ) t2
WHERE
t1.s_id = t2.s_id
ORDER BY
avg_s DESC
写法3:开窗函数 avg() over(partition by xxxxxxxx) 写法
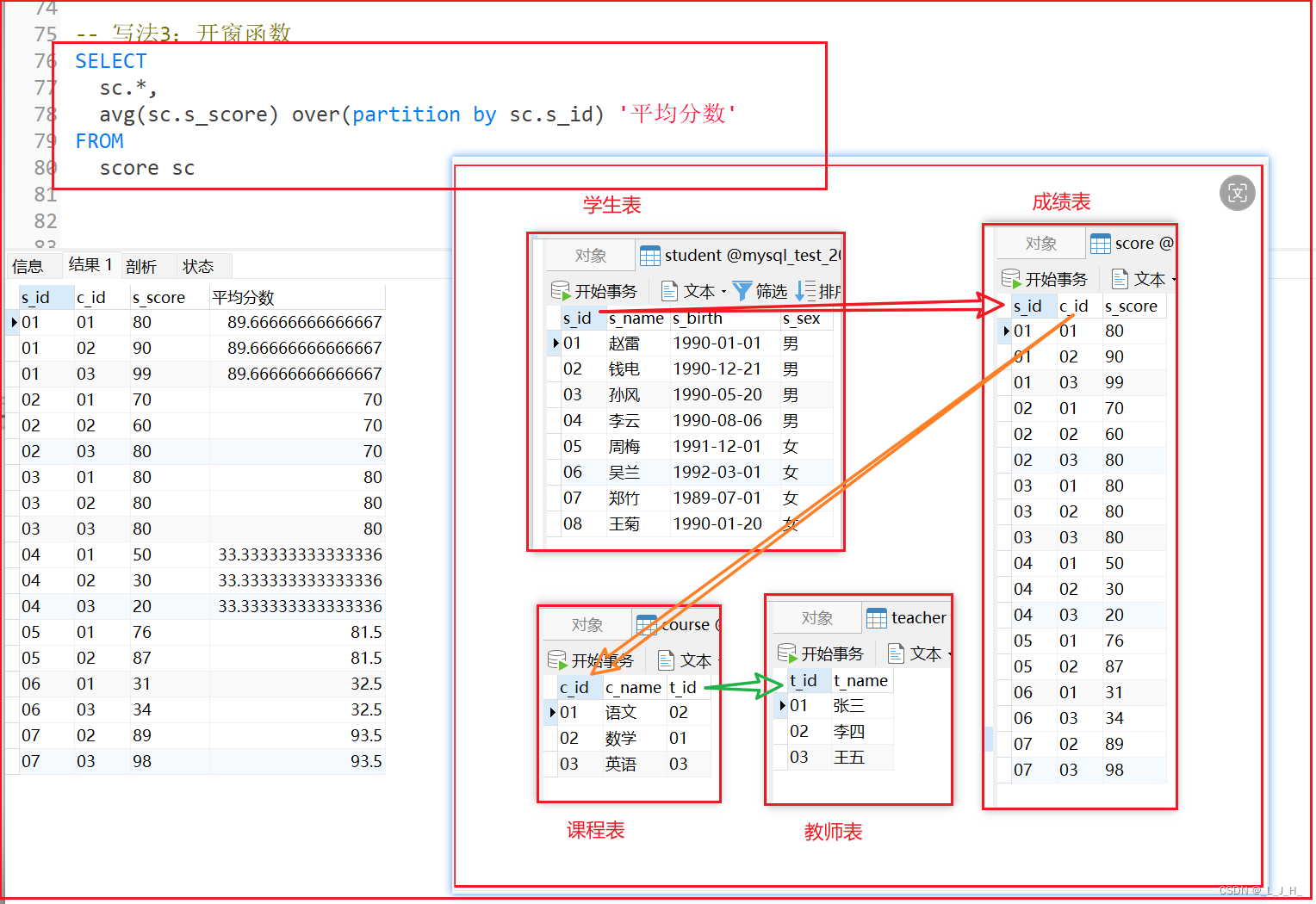
-- 写法3:开窗函数
SELECT
sc.*,
avg(sc.s_score) over(partition by sc.s_id) '平均分数'
FROM
score sc
18、查询各科成绩最高分、最低分和平均分:以如下形式显示:课程ID,课程name,最高分,最低分,平均分、及格率,中等率,优良率,优秀率
D及格为: >= 60 , C中等为:70-80,B优良为:80-90,A优秀为:>=90
使用 round()、max、min、avg、sum、case when 写法
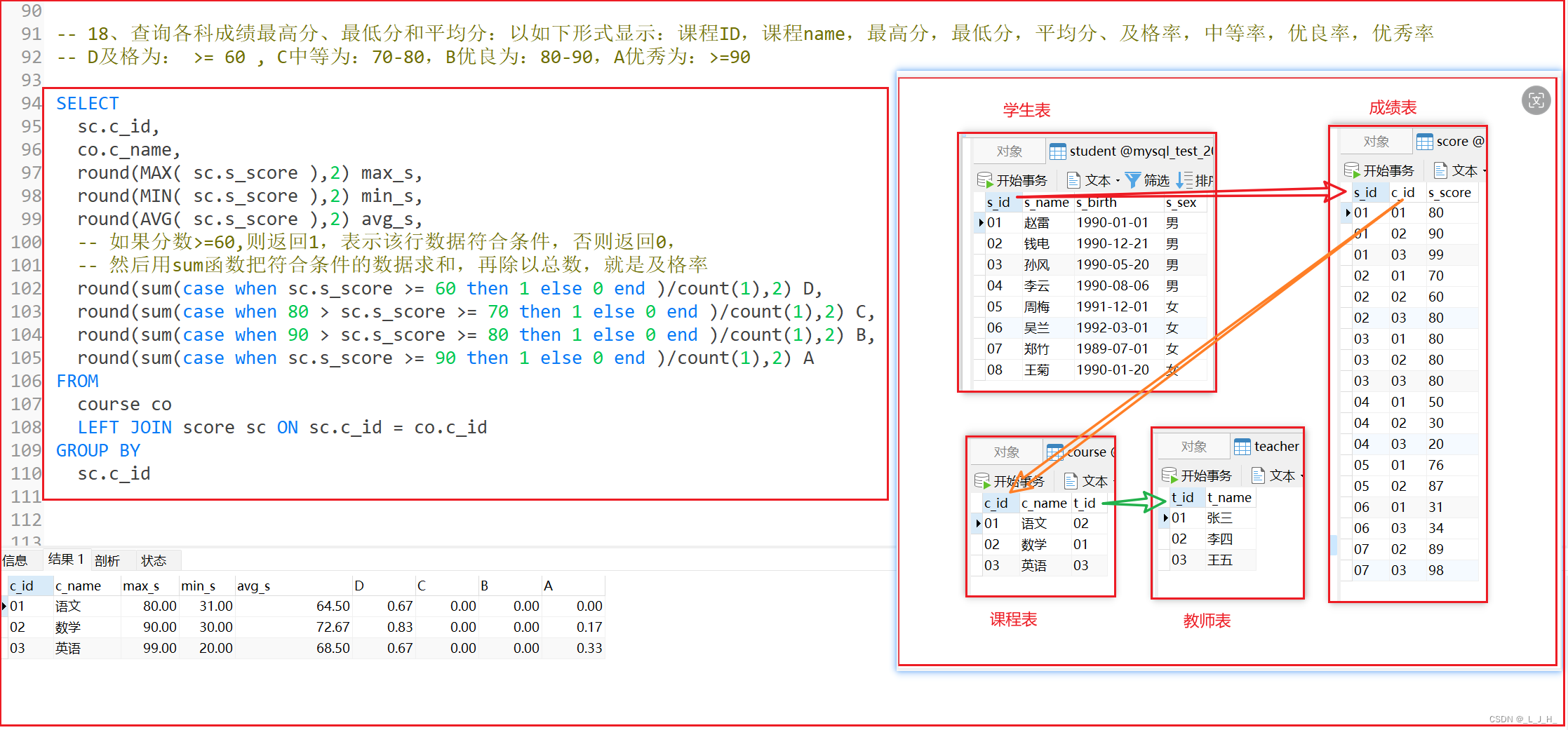
-- 18、查询各科成绩最高分、最低分和平均分:以如下形式显示:课程ID,课程name,最高分,最低分,平均分、及格率,中等率,优良率,优秀率
-- D及格为: >= 60 , C中等为:70-80,B优良为:80-90,A优秀为:>=90
SELECT
sc.c_id,
co.c_name,
round(MAX( sc.s_score ),2) max_s,
round(MIN( sc.s_score ),2) min_s,
round(AVG( sc.s_score ),2) avg_s,
-- 如果分数>=60,则返回1,表示该行数据符合条件,否则返回0,
-- 然后用sum函数把符合条件的数据求和,再除以总数,就是及格率
round(sum(case when sc.s_score >= 60 then 1 else 0 end )/count(1),2) D,
round(sum(case when 80 > sc.s_score >= 70 then 1 else 0 end )/count(1),2) C,
round(sum(case when 90 > sc.s_score >= 80 then 1 else 0 end )/count(1),2) B,
round(sum(case when sc.s_score >= 90 then 1 else 0 end )/count(1),2) A
FROM
course co
LEFT JOIN score sc ON sc.c_id = co.c_id
GROUP BY
sc.c_id
19、按各科成绩进行排序,并显示排名
开窗函数 rank() 和 row_number() 的写法及解释
两个都是用来排序并返回排名,
rank() 是如果有相同值的话,会被赋予相同的排名
row_number() 是如果有相同值的话,依然会按1、2、3、4这样顺序排下去
如图:
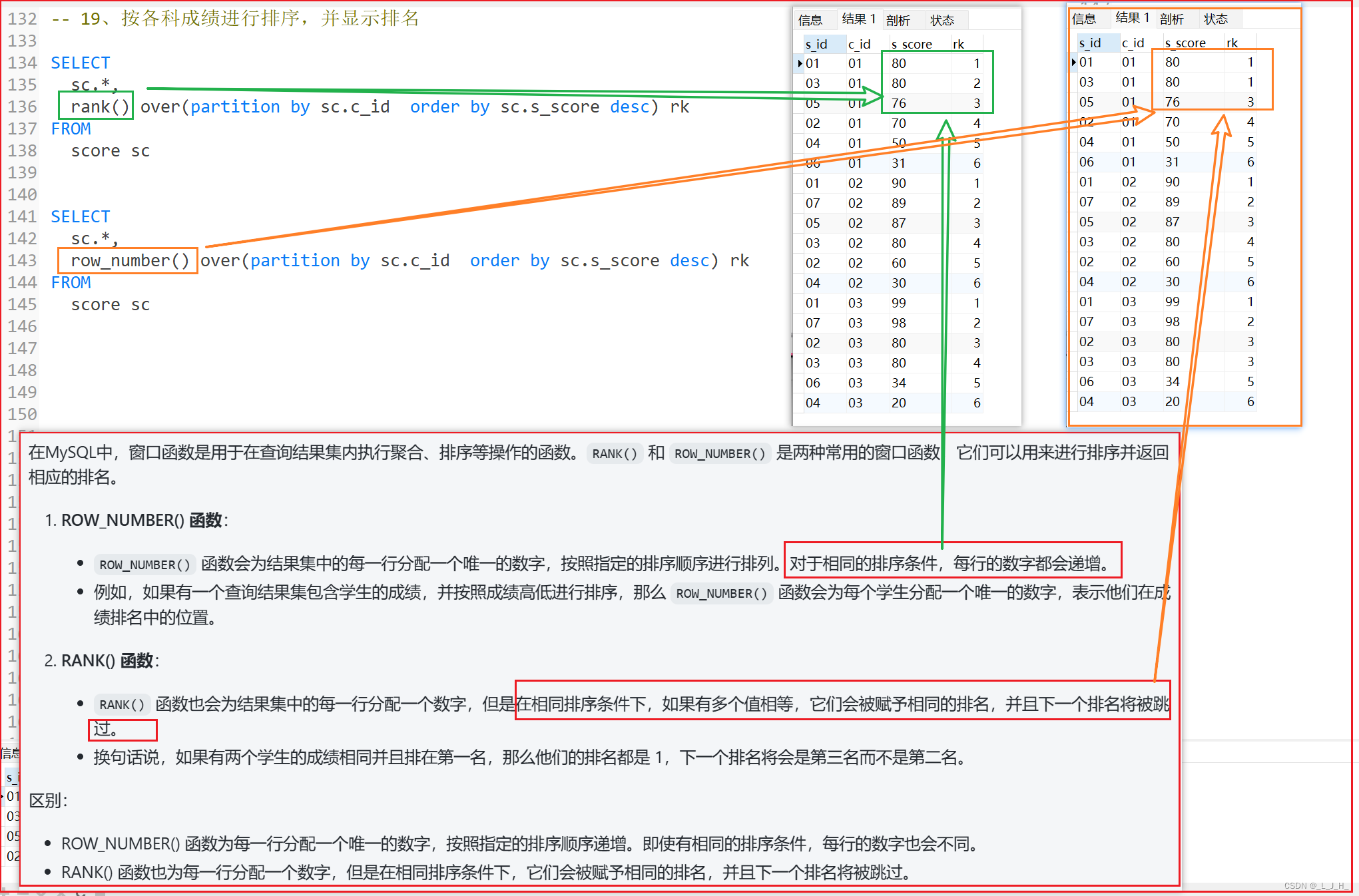
-- 19、按各科成绩进行排序,并显示排名
-- 开窗函数写法
SELECT
sc.*,
rank() over(partition by sc.c_id order by sc.s_score desc) rk
FROM
score sc
-- =====================================================================
SELECT
sc.*,
row_number() over(partition by sc.c_id order by sc.s_score desc) rk
FROM
score sc
子查询的写法
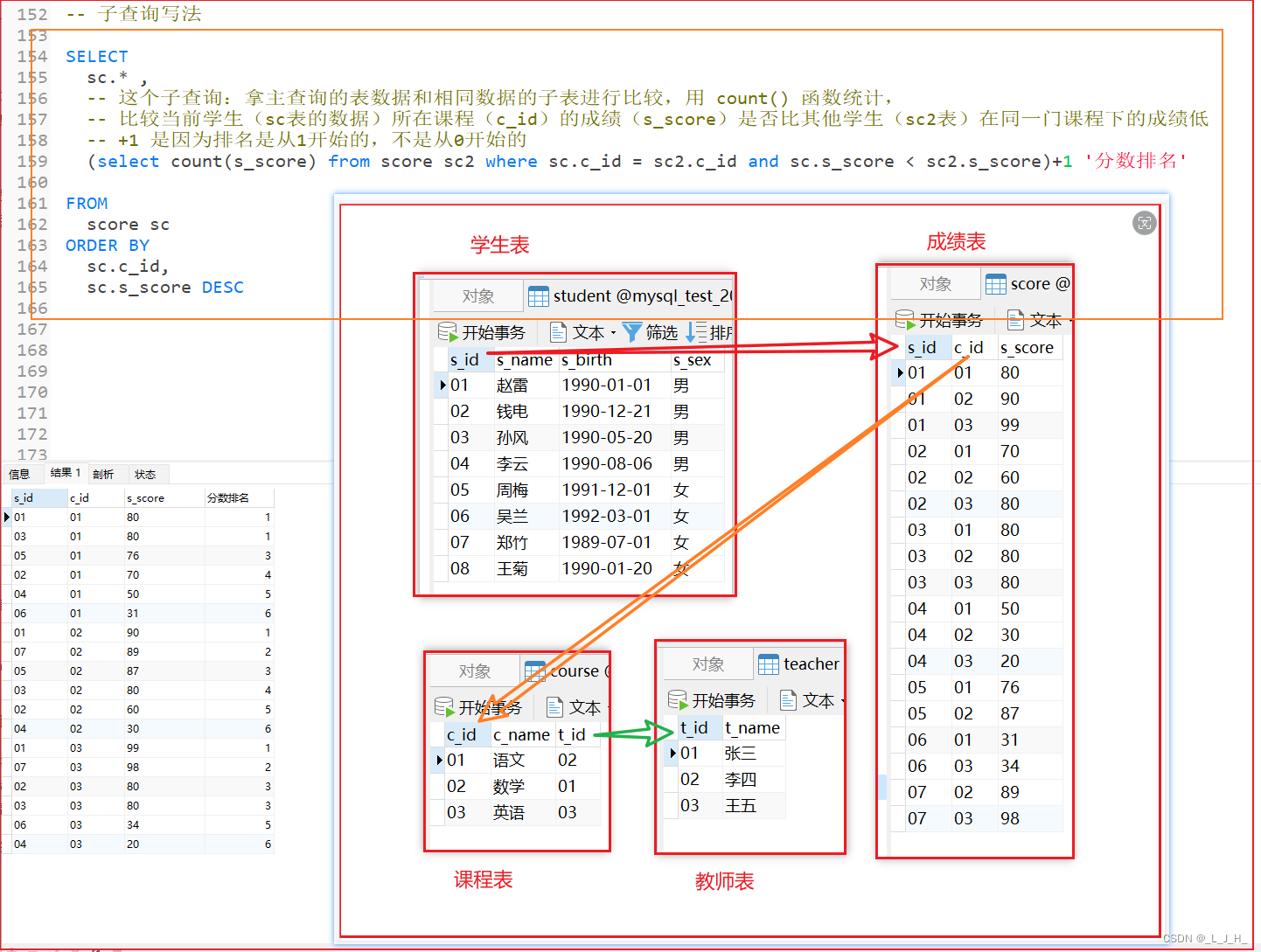
-- 子查询写法
SELECT
sc.* ,
-- 这个子查询:拿主查询的表数据和相同数据的子表进行比较,用 count() 函数统计,
-- 比较当前学生(sc表的数据)所在课程(c_id)的成绩(s_score)是否比其他学生(sc2表)在同一门课程下的成绩低
-- +1 是因为排名是从1开始的,不是从0开始的
(select count(s_score) from score sc2 where sc.c_id = sc2.c_id and sc.s_score < sc2.s_score)+1 '分数排名'
FROM
score sc
ORDER BY
sc.c_id,
sc.s_score DESC
20、查询学生的总成绩并进行排名
开窗函数+子查询的写法
通过 group by 分组,然后用 sum 函数计算每个学生的总成绩。
然后通过 rank() 函数,在 over() 里面只使用 order by 来进行降序排序即可,就可获得总成绩的排名
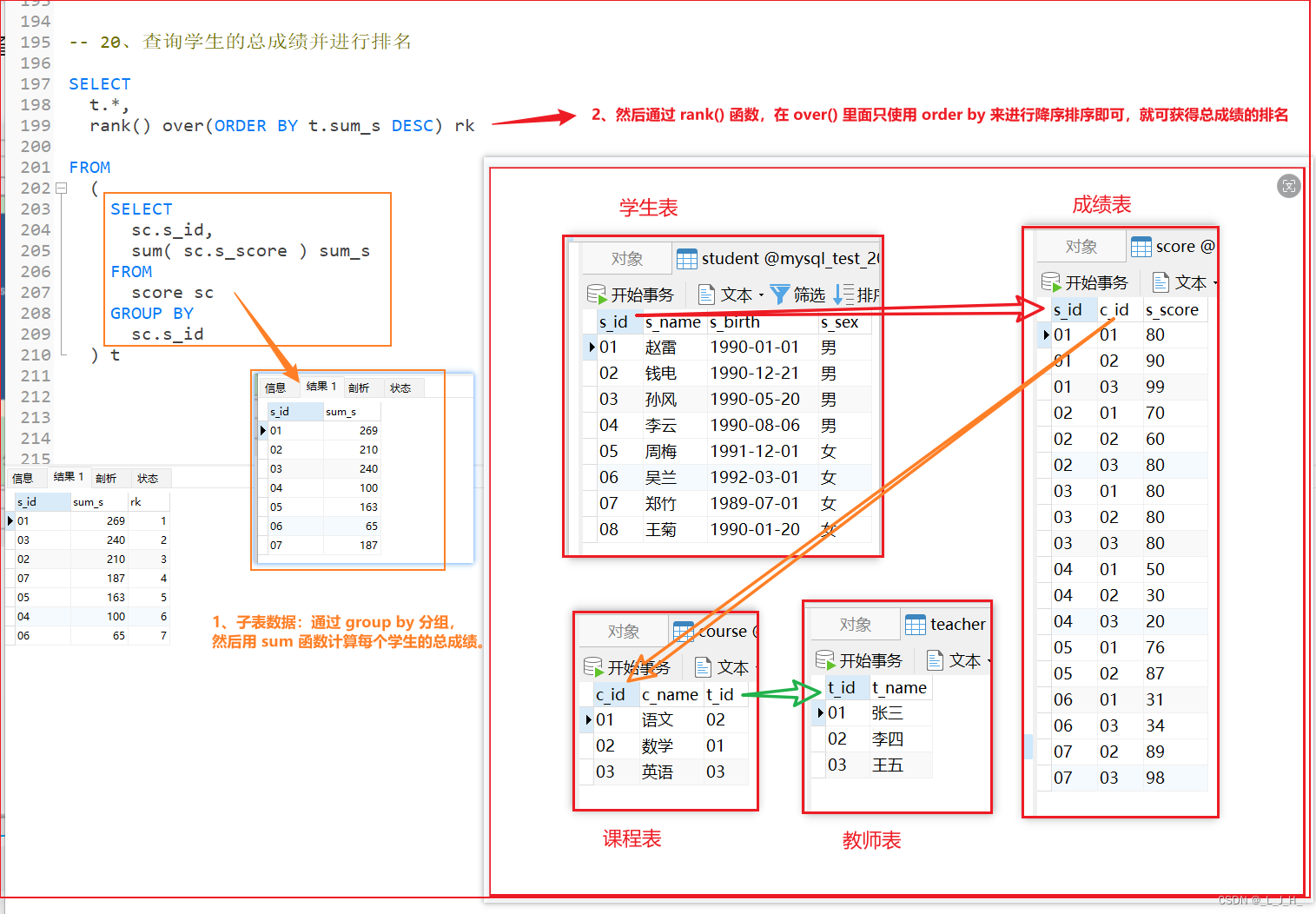
-- 20、查询学生的总成绩并进行排名
SELECT
t.*,
rank() over(ORDER BY t.sum_s DESC) rk
FROM
(
SELECT
sc.s_id,
sum( sc.s_score ) sum_s
FROM
score sc
GROUP BY
sc.s_id
) t
临时表+子查询来实现
具体写法
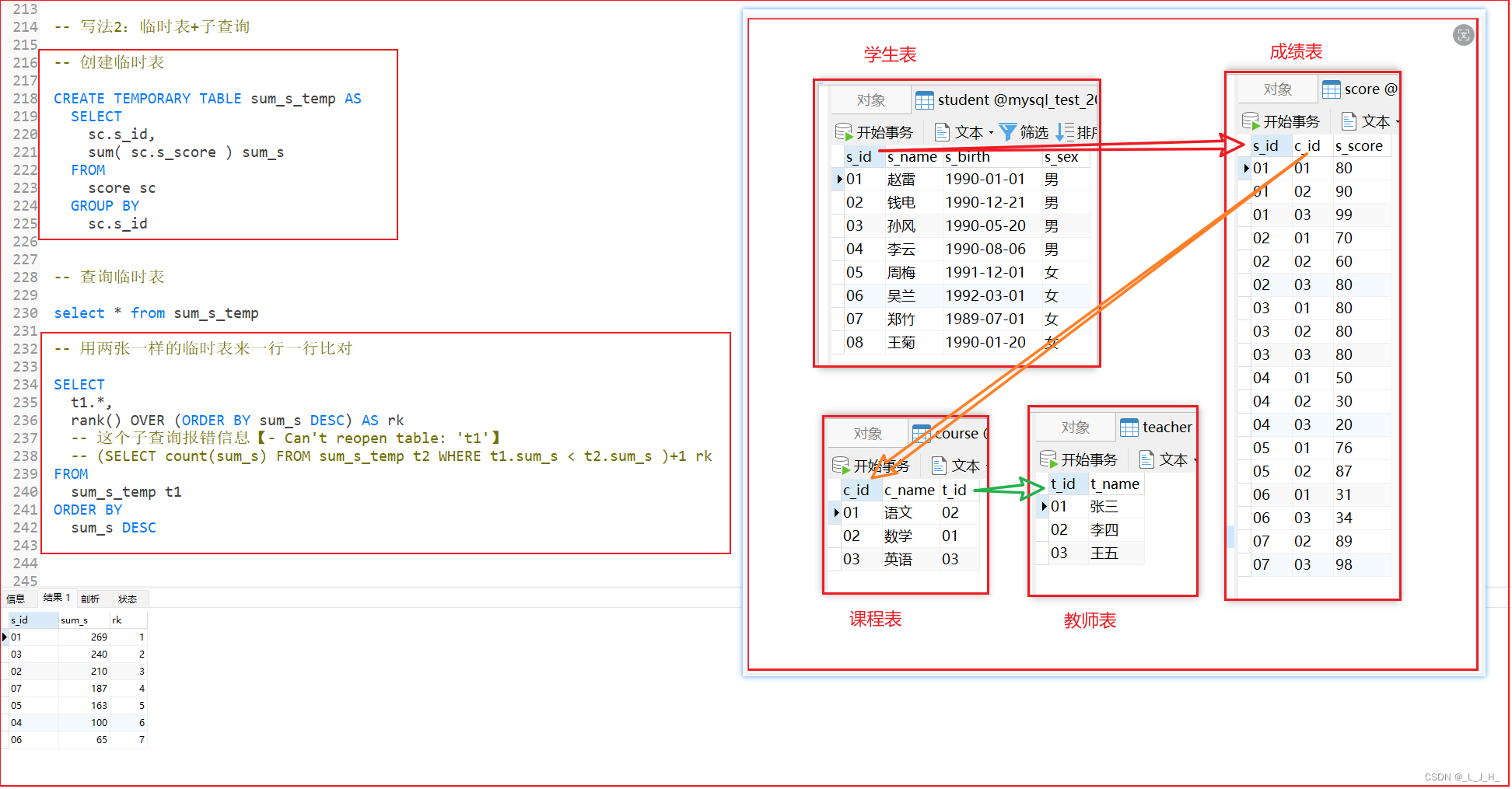
这个子查询报错信息【- Can’t reopen table: ‘t1’】,后续用到再研究,这里用开窗函数 rank() 更方便。
-- 写法2:临时表+子查询
-- 创建临时表
CREATE TEMPORARY TABLE sum_s_temp AS
SELECT
sc.s_id,
sum( sc.s_score ) sum_s
FROM
score sc
GROUP BY
sc.s_id
-- 查询临时表
select * from sum_s_temp
-- 用两张一样的临时表来一行一行比对
SELECT
t1.*,
rank() OVER (ORDER BY sum_s DESC) AS rk
-- 这个子查询报错信息【- Can't reopen table: 't1'】
-- (SELECT count(sum_s) FROM sum_s_temp t2 WHERE t1.sum_s < t2.sum_s )+1 rk
FROM
sum_s_temp t1
ORDER BY
sum_s DESC
创建临时表演示
创建临时表需要用到【TEMPORARY】 这个关键字
临时表 和 常规表 的区别
生命周期: 临时表的生命周期通常是会话级别的,而常规表则是持久化的。这意味着临时表只在当前会话中存在,当会话结束时会被自动删除,而常规表会一直存在于数据库中,直到显式删除。
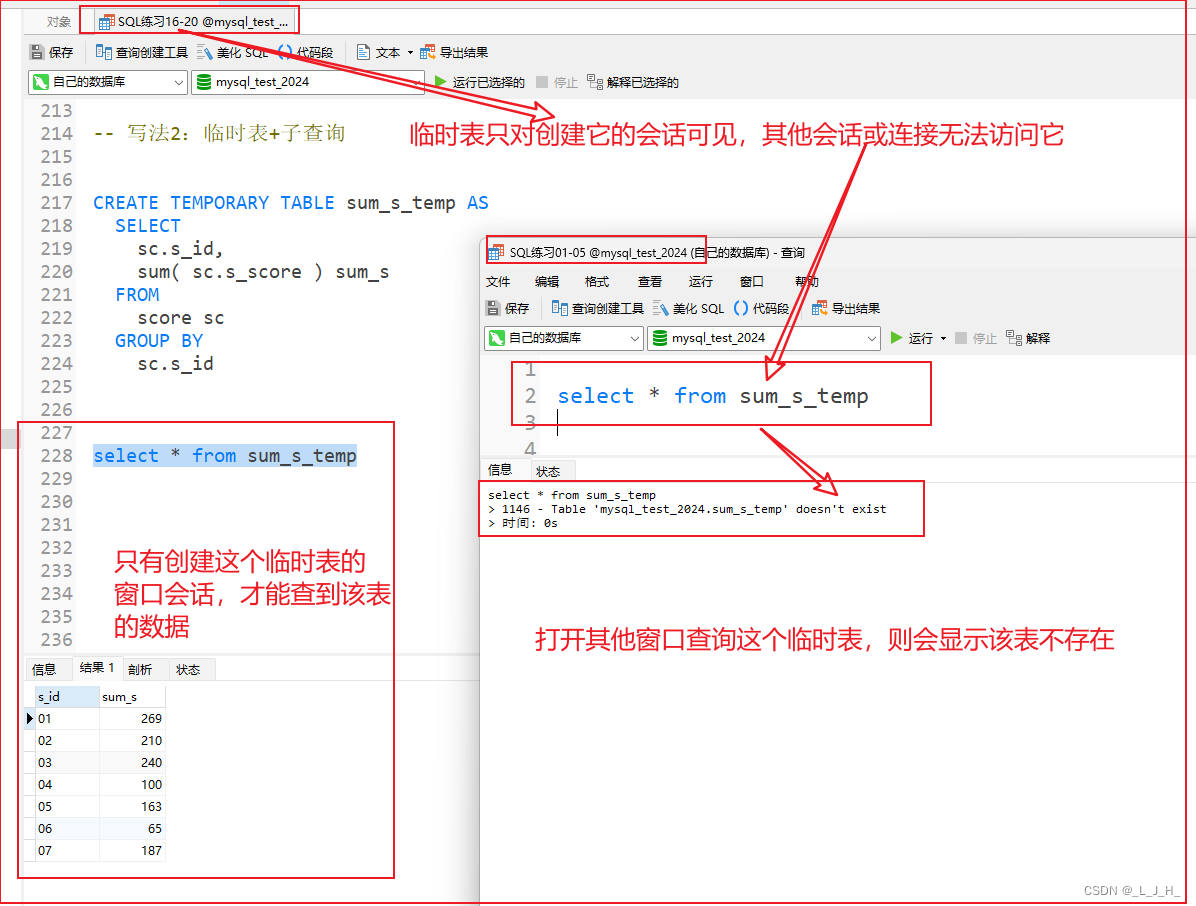
可见性: 临时表只对创建它的会话可见,其他会话或连接无法访问它。常规表则可以被数据库中的所有用户和连接访问。
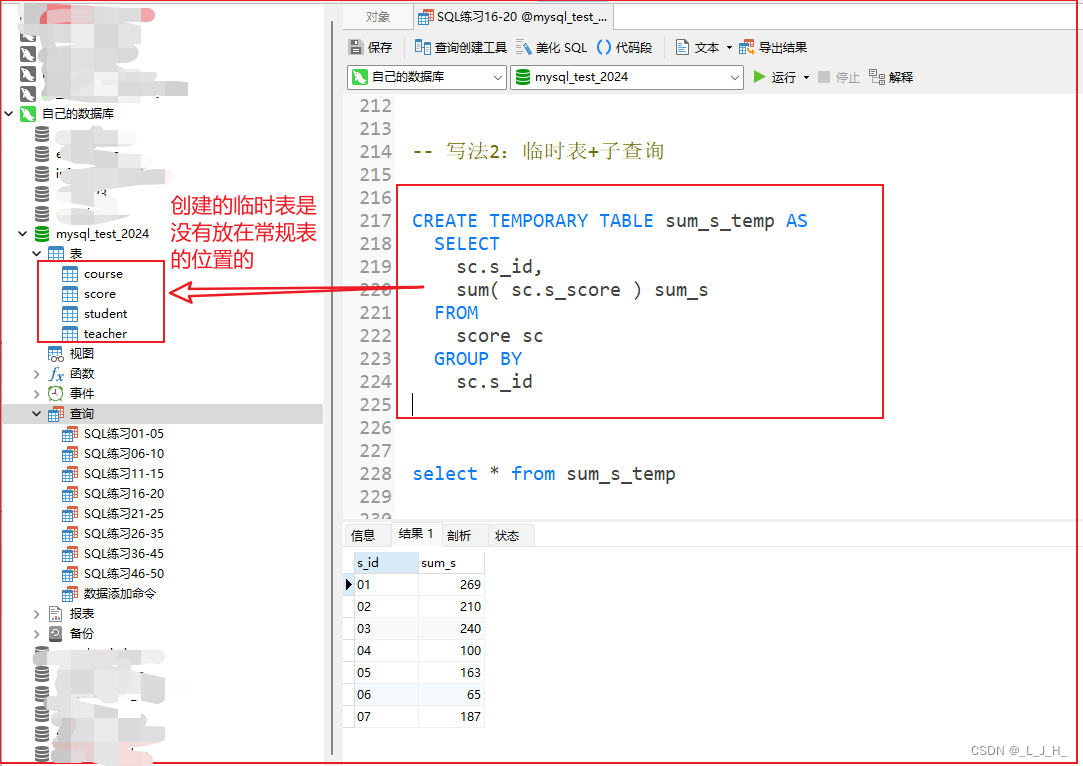
存储空间: 临时表通常存储在临时表空间中,这可能与常规表的存储位置不同。临时表通常用于存储临时性的数据,而常规表则用于长期存储数据。
索引和约束: 在某些数据库管理系统中,临时表可能不支持索引和约束,或者支持的方式有所不同。而常规表通常可以定义各种类型的索引和约束。
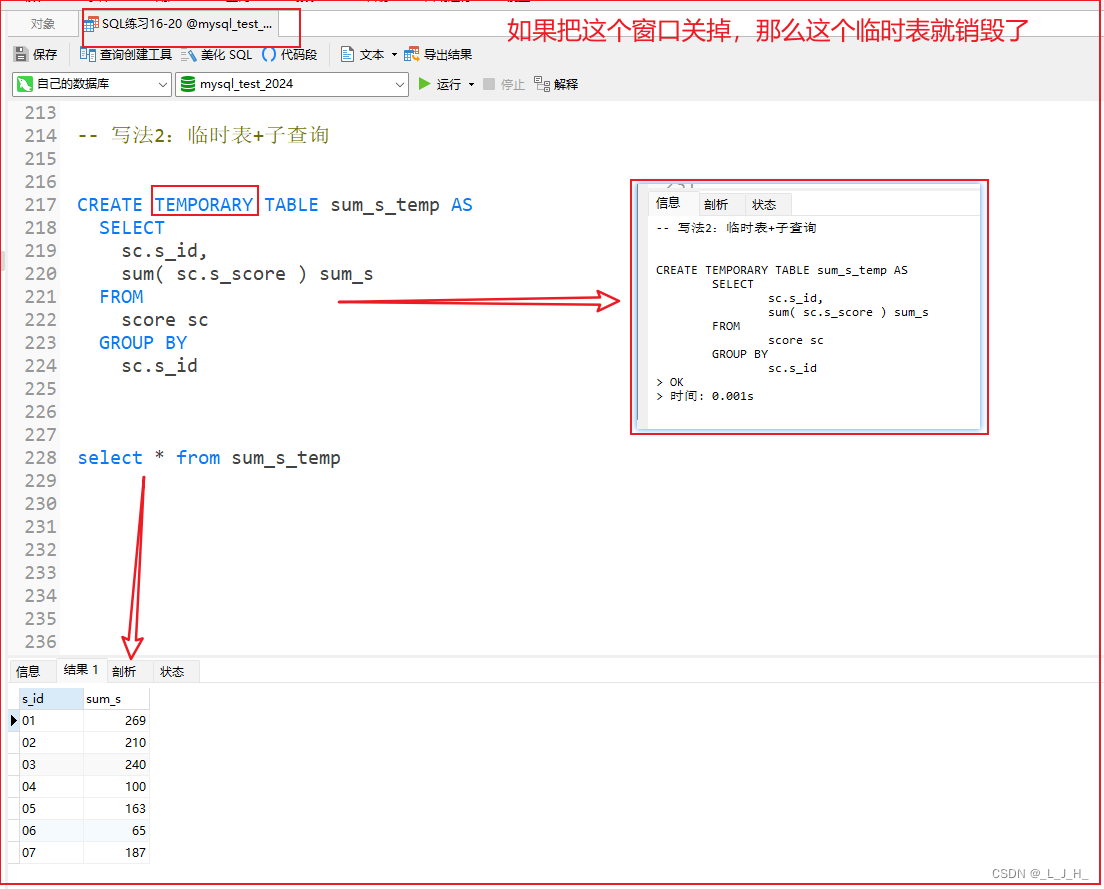
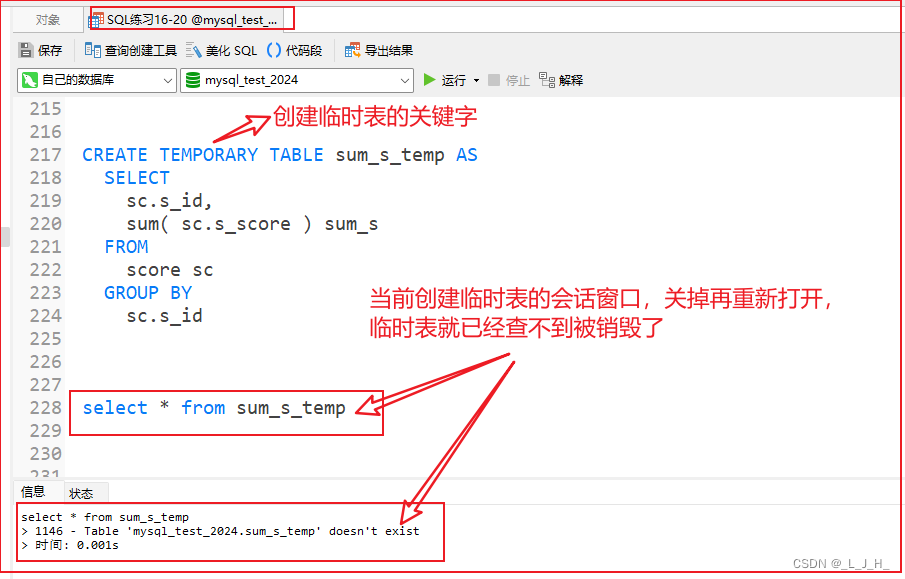
生命周期演示:
临时表的生命周期通常是会话级别的,而常规表则是持久化的。
这意味着临时表只在当前会话中存在,当会话结束时会被自动删除,而常规表会一直存在于数据库中,直到显式删除
当我把这个窗口关掉再查询sum_s_temp 这张临时表时,就会显示该表不存在。
-- 创建临时表
CREATE TEMPORARY TABLE sum_s_temp AS
SELECT
sc.s_id,
sum( sc.s_score ) sum_s
FROM
score sc
GROUP BY
sc.s_id
-- 查询临时表
select * from sum_s_temp
可见性演示:
临时表只对创建它的会话可见,其他会话或连接无法访问它。常规表则可以被数据库中的所有用户和连接访问。
存储空间

















 527
527

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











