







一. sparkstreaming流式处理中也分为有状态计算及无状态计算
无状态是指: 数据不保留之前批次计算的结果,每次的结算结果不相互依赖。
有状态是指:当前批次的处理结果和之前批次处理进行更新或汇集。
主要讲算子updateStateByKey
先看方法:
` def updateStateByKey[S: ClassTag](
updateFunc: (Seq[V], Option[S]) => Option[S]
): DStream[(K, S)] = ssc.withScope {
updateStateByKey(updateFunc, defaultPartitioner())
}`
由此可以看到这个算子的入参是一个函数:
updateFunc: (Seq[V], Option[S]) => Option[S]
分析:
首先我们可以根据算子的命名了解到xxxxbyKey,就知道这个算字是针对于key-value的Dsteam,同时也是已经byKey了就需要知道入参是针对于value进行更新的。
好,我门直接上代码:
package com.brd.sparkengine
import com.brd.util.FunctionTest
import org.apache.spark.streaming.dstream.ReceiverInputDStream
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.{SparkConf, SparkContext}
object StreamingTest {
/**
* 功能描述: 通过本地安装nc并执行:nc -l 9999,模拟流式数据
* @Param:
* @Return:
* @Author: brandonxian
* @Date: 2021-10-27 21:35
*/
def main(args: Array[String]): Unit = {
//初始化sparkstreaming核心抽象
val conf=new SparkConf()
.setAppName("StreamingTest")
.setMaster("local[*]")
val sc=new SparkContext(conf)
sc.setCheckpointDir("/Users/brandonxian/Desktop/Transfer/interview/ck/")
//设置日志打印级别 :Set("ALL", "DEBUG", "ERROR", "FATAL", "INFO", "OFF", "TRACE", "WARN")
sc.setLogLevel("ERROR")
val ssc=new StreamingContext(sc,Seconds(5))
//使用socket方式接入输入流
val dstream: ReceiverInputDStream[String] =ssc.socketTextStream("localhost",9999)
//3.流式数据处理
val wdcount = dstream
.flatMap(line => line.split("\t"))
.map(word => (word,1))
.reduceByKey((a,b)=> a + b)
//.map(line=>{
// (line._1,line)
//})
// 测试update,测试结果=> 会记录之前的记录次数,合并当前batch的状态进行累加
val updState=FunctionTest.updStatByKeyTest(wdcount)
//4.数据输出
updState.print()
//5.开启程序
ssc.start()
ssc.awaitTermination() //如果上一个批次没有处理完成,后面的批次处于阻塞状态
}
}
------------------------------------------------------
def updStatByKeyTest(ds: DStream[(String, Int)]): DStream[(String, Int)] = {
def updateFunc(newValues: Seq[Int], oldStatus: Option[Int]): Option[Int] = {
val newValu: Int = newValues.sum
val od: Int = oldStatus.getOrElse(0)
Some(newValu + od)
}
ds.updateStateByKey(updateFunc)
}
我们以一个简单的wordcount进行测试(注意我们的窗口滑动时间是5s):
结果:
输入:
:~ brandonxian$ nc -l 9999
-------------in 5s------------
aaa
aaa
-------------after 5s------------
aaa
-------------after another 5s------------
什么也不输入。。。。。
结果: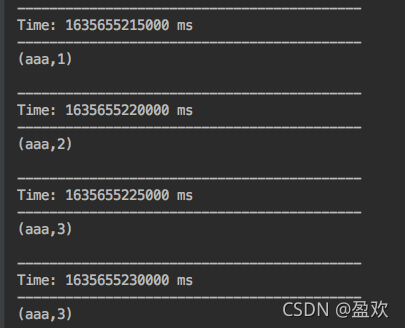
可以看到对于word count进行了状态保留,对于不同的时间窗口,我们依然能对之前批次的状态保留并计算。
根据如上的代码核心的就是理解:
def updStatByKeyTest(ds: DStream[(String, Int)]): DStream[(String, Int)] = {
def updateFunc(newValues: Seq[Int], oldStatus: Option[Int]): Option[Int] = {
val newValu: Int = newValues.sum
val od: Int = oldStatus.getOrElse(0)
Some(newValu + od)
}
ds.updateStateByKey(updateFunc)
}```
/**
* 1。所有的参数,方法都是针对于key-value对中的value进行的操作,因为算子会xxxByKey
* 2。newValues 是指当前批次的所有的新值,注意只是针对当前一个批次并且 是一个seq列表
* 3。oldStatus 是指对旧的状态的保留 是一个option的类型参数
* 实现方法:
* wordcount中对所有的新的值进行累加,并将结果和旧值进行累加,就得到当前批次和上一个状态值的聚合状态
*/














 697
697











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









