






点击上方“Java基基”,选择“设为星标”
做积极的人,而不是积极废人!
每天 14:00 更新文章,每天掉亿点点头发...
源码精品专栏
前言
Linux 三剑客是(grep,sed,awk)三者的简称,熟练使用这三个工具可以提升运维效率。Linux 三剑客以正则表达式作为基础,而在Linux系统中,支持两种正则表达式,分别为“标准正则表达式”和“扩展正则表达式”。在掌握好正则表达式后,将具体讲解三剑客的用法。
基于 Spring Boot + MyBatis Plus + Vue & Element 实现的后台管理系统 + 用户小程序,支持 RBAC 动态权限、多租户、数据权限、工作流、三方登录、支付、短信、商城等功能。
项目地址:https://github.com/YunaiV/ruoyi-vue-pro
一、正则表达式
正则表达式:REGular EXPression, REGEXP。我们通过特定的字符串匹配模板,来获取到所需的内容。熟练掌握好正则表达式是使用Linux三剑客的前提啊。
元字符
.: 匹配任意单个字符;[]: 匹配指定范围内的任意单个字符;[^]:匹配指定范围外的任意单个字符;
字符集合
[[:digit:]]:匹配单个数字;[[:lower:]]:匹配单个小写字母;[[:upper:]]:匹配单个大写字母;[[:punct:]]:匹配单个标点字符;[[:space:]]:匹配单个空白字符;[[:alpha:]]:匹配单个字母;[[:alnum:]]:匹配单个字母或数字;
匹配次数(贪婪模式)
*:匹配其前面的字符任意次?:匹配其前面的字符0次或者1次+:匹配其前面的字符至少1次.*:任意长度的任意字符
位置锚定
^: 锚定行首,此字符后面的任意内容必须出现在行首$: 锚定行尾,此字符前面的任意内容必须出现在行尾^$: 空白行
LInux实际使用
由于linux系统shell解释器的特殊处理,某些元字符在linux下具有展开式等特殊含义,在实际的使用过程中我们需要添加\进行转义。\?:匹配其前面的字符1次或0次;\+:匹配至少一次;\{m,n\}:匹配其前面的字符至少m次,至多n次;\{1,\}:匹配前面的字符至少1次;\{0,3\}:匹配前面的字符0次至3次均可;
备注:至少0次,必须要显示的写出来;
\<或\b:锚定词首,其后面的任意字符必须作为单词首部出现\>或\b:锚定词尾,其前面的任意字符必须作为单词的尾部出现
分组与后向引用
\(\)``\(ab\)*``\1:引用第1个左括号以及与之对应的括号所包括的所有内容;\2:引用第2个左括号以及与之对应的括号所包括的所有内容,以此类推;
基于微服务的思想,构建在 B2C 电商场景下的项目实战。核心技术栈,是 Spring Boot + Dubbo 。未来,会重构成 Spring Cloud Alibaba 。
项目地址:https://github.com/YunaiV/onemall
二、拓展正则表达式
可以看到标准正则表达的使用过程中,许多符号都需要转义,这在工作中带来了一定的不便,因此扩展的正则表达式便出现了。
字符匹配:
.:匹配单个字符;[abc]:包含abc任意一个字符[^abc]:不包含abc任意一个字符
次数匹配(不用再转义):
*:匹配前一个字符任意次;?:匹配其前面的字符1次或0次;+:匹配其前面的字符至少1次;{m,n}:匹配其前面的字符至少m次,至多n次;
位置锚定:
对比使用方式:^ 和 $这里要注意的是对于词首定位和词尾定位,分别是\< 和 \>,依然需要加上反斜杠;
分组(不用再转义):
():分组\1, \2, \3:分别对应第n个括号所匹配的内容;
或运算
|:可以同时取并集;
注意:C|cat表示的是C或cat(表示的是整个部分)
可以看到,使用扩展的正则表达式可以省略很多的转义符号,这尤其在写sed语句时极大的提高了代码的可读性。建议优先使用扩展的正则表达式。
三、grep命令家族
grep相关命令
grep命令家族由grep, egrep, fgrep 三个子命令组成,适用于不同的场景。具体如下:
命令描述
grep 原生的grep命令,使用“标准正则表达式”作为匹配标准。egrep 扩展的grep命令,相当于$(grep -E),使用“扩展正则表达式”作为匹配标准。fgrep 简化版的grep命令,不支持正则表达式,但搜索速度快,系统资源使用率低。
使用方法
语法 grep [options] PATTERN [FILE...]
options部分 -i:忽略大小写--color:高亮匹配上的字符串-v: 显示没有被模式匹配到的行-o:只显示被模式匹配到的字符串-E:使用扩展的正则表达式,egrep=grep -E
PATTERN部分 以字符串的方式给定匹配模板,可以使用普通字符串以及正则表达式(标准&扩展)。
FILE部分 需要查找内容的文件。
四、sed命令
概述
sed全称为Stream EDitor,sed是一个流编辑器,在处理行内容时功能十分强大。
基本语法
sed [option] 'script' [input file]...option部分
-n:不输出模式空间中未匹配上的内容stdout,详情可以看4.3高级用法;-e:可以在sed命令中指定多个script脚本,多点编辑功能;-f:输入sed脚本,脚本中写着编辑命令;-r:支持使用扩展的正则 ;-i:直接编辑源文件;
script部分
script部分包含两个内容,其一是定界,即确定我们要操作的范围。另一个内容是操作,比如替换、插入当前行或在后面插入等操作。
a)定界-空地址
即全文编辑;
b)定界-单地址:
n:指定第n行,对特定行进行编辑;举例:sed -n '1p' passwd 仅输出第一行;/pattern/:指定模式匹配到的那一行,注意这里的pattern不是扩展正则表达式,如果要用扩展的正则表达式,需要在option需要使用-r;举例:sed -n '/sbin/p' passwd 输出能够匹配上sbin的内容行;
c)定界-范围:
n,m:定位从第n行开始至第m行(都是闭区间);n,+k:定位从第n行开始,包括往后的k行;n,/pattern/:定位从第n行开始,至指定模式匹配到的那一行;/pattern1/,/pattern2/:定位从pattern1模式匹配开始,直到pattern2模式匹配之间的范围;
d)定界-步进方式:
1~2:以1为起始行,然后步进2行向下匹配,即所有的奇数行;2~2:以2为起始行,然后步进2行向下匹配,即所有的偶数行;
e)编辑操作:
d:删除整行,d放在定界后面。
举例:sed '/sbin/d' passwd;
p:显示模式空间中的内容, p放在定界后面。一般来说,p操作和-n选项配合使用,筛选出我们匹配的行。若不加-n的话,由于模式空间中未匹配上的行也会输出,我们会发现所有内容都输出并且匹配行会输出2次;
a:在匹配的行后面增加文本,使用\n支持多行追加,a放在定界后面。举例:sed '1a first_line\nsecond_line' passwd 在第1行后面插入两行内容(first_line 和 second_line);
i:在匹配的行前面增加文本,i放在定界后面。举例:sed '3i hello' passwd;c:替换匹配行为指定的文本。举例:sed '/root/c text' passwd 把匹配到的行替换成text;
w:保存模式空间中匹配的内容到指定位置。举例:sed -n '/^[^#]/w /tmp/demo' /etc/fstab 即将/etc/fstab中非#开头的行输出保存到/tmp/demo中。r:读取指定文件的内容添加到当前文件匹配到的行后面,进行文件合并。举例:sed '2r /etc/passwd' 1.txt 即将/etc/passwd文件的内容读取,并插入到1.txt文件的第二行处。!:条件取反。用法:地址定界!编辑命令。s///:条件替换,这里的/可以用其他特殊符号,其替换分隔符的判定标准是s字符后的第一个特殊符号。这在替换文本中涉及特殊符号时特别好使,我们避开需要替换的特殊符号即可。即sed 's@root@me@g' /etc/passwd 等同于 sed 's/root/me/g' /etc/passwd。
替换标记备注:g(全局替换),p(显示替换成功的行) 替换举例:根据输入查找目录,下面输出的是
/var/log/``echo "/var/log/messages" | sed 's@[^/]\+$/\?@@'
sed高级用法
1.模式空间与保持空间
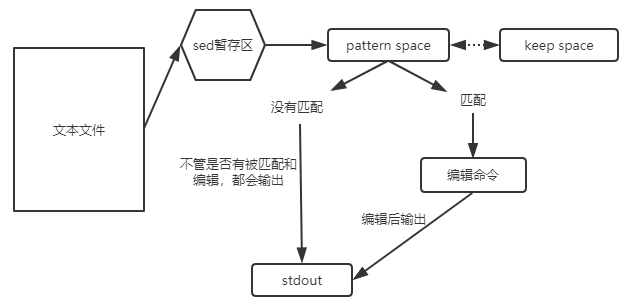
在模式空间中,完成匹配的操作。当没有匹配上的时候,文本行内容会默认输出stdout;当匹配上文本行的时候,会执行编辑命令,执行结果输出到stdout中。保持空间可以理解为一个暂存区,只是用于完成额外的动作。
2.相关参数
h:把模式空间中的内容覆盖至保持空间中;H:把模式空间中的内容追加至保持空间中;g:把保持空间中的内容覆盖至模式空间中;G:把保持空间中的内容追加至模式空间中;x:把模式空间中的内容与保持空间中的内容互换;n:覆盖读取匹配到的行的下一行(改变指向)至模式空间中;N:追加读取匹配到的行的下一行(改变指向)至模式空间中;d:删除模式空间中的行;D:删除多行模式空间中的所有行;
3.举例
sed -n 'n;p' FILE:显示偶数行;sed '1!G;h;$!d' FILE:逆序显示文件的内容;sed '$!d' FILE:取出最后一行;sed '\$!N;$!D' FILE:取出文件后两行;sed '/^$/d;G' FILE:删除原有的所有空白行,而后为所有的非空白行后添加一个空白行;sed 'n;d' FILE:显示奇数行;sed 'G' FILE:在原有的每行后方添加一个空白行;
4.基础面试题举例
面试题1:提取字符串中的指定字符串
/bin/bash
info="hellozimskyshenzhen"
echo $info | sed 's/hello\(\w\+\)shenzhen/\1/g'注意事项:sed中不支持\d,如果要用数字用[0-9],但是支持\w。在一般正则表达式中,sed中的
()要转义,+要转义,<>要使用\转义。如果不想这么麻烦,那就加上-r选项使用扩展正则表达式吧!
面试题2:判断输入是否为整数
#!/bin/bash
if [ -n "$(echo $1 | sed -n '/^[0-9]\+$/p')" ] ; then
echo 'yes'
else
echo 'no'
fi五、awk命令
awk概述
awk是发明该工具三个作者姓名的首字母简称,awk是一个报表生成器,主要用于格式化输出。格式化文本输出器。
基本用法
1.语法
awk [option] 'PATTERN{ACTION STATEMENTS}' FILEawk按照行来读取文档,根据输入分隔符切分成小部分(用內建变量来表示$0,$1,$2等),用ACTION STATEMENTS来处理该行文本。$0表示显示整行。
2.常用选项option
-F:指名输入字段的分隔符;-v:用来实现自定义变量var=value;
3.PATTERN(用于定界)
``:表示处理文件的所有行;/pattern/:表示处理正则匹配对应的行;!/pattern/:表示处理正则不匹配的行;关系表达式:比如NR>2等返回布尔类型的表达式。若结果为真则处理,假则不处理。对于非0非空字符串为真,其余为假。n:表示处理第n行的文本,注意这里不支持直接给出数字的格式,例如1,2{...}。详情请见举例。BEGIN/END模式:BEGIN{}表示仅在开始处理文件中的文本之前执行一次的程序,例如打印表头。END{}表示文本处理完成之后执行一次,例如汇总数据。
举例:
在/etc/passwd文件中,以:为分隔符,筛选出最后一列为/bin/bash的行,并打印第一列和最后一列
awk -F: '$NF=="/bin/bash" {print $1, $NF}' /etc/passwd
awk -F: '$NF!="/bin/bash"{print $1,$NF}' passwd
awk -F: '$3<1000 {print $1, $3}' /etc/passwd
awk -F; '(NR>=2&&NR<=10){print $1}' /etc/passwd 行定界
awk -F: '{printf "%-15s %10s\n", $1, $2}' /etc/passwd4.內建变量(在引用变量时不用加$)
FS :input field seperator:输入字段分隔符,默认空白字符。也可使用-v指定。OFS :输出字段分隔符。使用-v指定。RS :输入时的换行符ORS :输出时的换行符NF :number of field 每一行的字段数量。加上$NF表示最后一列 。NR :number of record 文件的行数,打印出来是打印行号FNR :多个文件中的行数分别计数FILENAME :当前文件的文件名ARGC :参数命令行中参数的个数ARGV :返回数组,命令行中的每个参数 举例:awk 'BEGIN {print ARGV[0]}' /etc/fstab /etc/issue 在这里ARGV[0]是awk,固定为第0个参数。ARGV[1]是/etc/fstab,ARGV[2]是/etc/issue 举例:awk -v FS=':' '{print $1}' -v OFS=':' /etc/passwd 指名冒号作为输入的分隔符。同awk -F: ...
5.自定义变量
方法1:-v var=value (区分字符的大小写) 方法2:在program中定义
举例:awk -v test='hello' 'BEGIN {print test}' awk 'BEGIN {test='hello' print test}'
6.常用的ACTION命令
print 输出格式:print item1,item2 ... 备注:使用逗号作为分隔符;输出item可以是字符串、內建变量、awk表达式;若省略item,则显示$0整行;
printf 格式化输出:printf FORMAT, item1, item2...按位放在format中。注意事项:format必须要给出;如需换行,必须要显示写出;format中需要为后面每个item指定格式符;
Expressions
Control statements:控制语句if,while if(condition){statement} if(condition){statement} else {statements} while(condition) {statements} do {statements} while(condition) for(expr1;expr2;expr3) {statements} break continue delete array[index] delete array删除整个数组 exit 退出语句
Compound statements:组合语句
Input statements:输入语句
Output statements:输出语句格式符 :%c:显示字符的ASCII值 %d:显示十进制整数 %e:科学计数法数值显示 %f:显示为浮点数 %g:以科学计数法显示浮点数 %s:显示字符串 %u:显示无符号整数 %%:显示%自身修饰符 :
#[.#]:第一个数字用于控制显示字符的宽度,第二个数字表示小数的精度(对于浮点数而言);输出默认右对齐%15s,左对齐:%-15s;+:表示带正负符号;操作符 : 算数操作符:+-/* ; +x把字符串转换成数值;-x改成负数; 字符串操作符:字符串连接(没有操作符) 复制操作符:=,+=,-=,/=,++,-- 比较操作符:>,<,<=,!=,==模式匹配符 : ~:左侧的字符串是否被模式匹配 !~:左侧的字符串是否不能被模式匹配逻辑操作符 : &&:与 ||:或 !:非函数调用 : function_name(arg1, arg2, ...)条件表达式 : selector?true_exp:false_exp 和三目运算符一样操作例子
一般来说, 打印无状态内容放在BEGIN和END块中
awk -v begin="hello" -v end="ok" -F: 'BEGIN{print begin}; {print $1, $NF}; END{print end}' /etc/passwdawk高级用法及举例
awk常用内置变量
$1:表示第一列
$NF:表示最后一列
$NR:表示行号常用条件表示
/指定内容/ 这种方式可以匹配到含有“指定内容”的行,在条件中不添加$#所带的项,建议不使用正则,有异常情况。
awk -F: '/nologin/{print $0}' /etc/passwd #匹配到含有nologin关键字的行
seq 100 | awk '/1/{print $1}'$#=/指定内容/ 这种方式指定第#列匹配指定内容
awk -F: '$1=/bin/{print $0}' /etc/passwd$#~/指定内容/ 这种方式用于指定列模糊匹配(正则匹配)指定内容,并获取该行。
awk -F: '$1~/dae/{print $1}' /etc/passwd #正向选择
awk -F: '$1!~/dae/{print $1}' /etc/passwd #反向选择值判断 使用>,<,>=,<=,==,!=来判断指定列的值。
awk -F: '$3>=10{print $1}' /etc/passwd逻辑判断 使用&&,||来进行逻辑判断。
awk -F: '$3>=5 && $3<=10{print $1}' /etc/passwdif条件判断
awk -F: '{if ($NF~/nologin$/){i++}else{j++}}; END{print i, j}' /etc/passwd
#注意if-else条件判断是放在{}中的字典使用 在awk中可以定义数组类型,用于统计。
awk '{ip[$1]++}; END{for (i in ip) {print i, ip[i]}}' access.log
#解析: 将第一列ip设置为字典的key,当出现一次相同的ip时自增1,用于统计所有的ip计数。
#for循环中取到每个字典对应的key,再使用print块打印出来。注意花括号的隔离。
#QQ号 等级 时长
#统计等级(30<=x<=90),相同账号的时长
#1234 12 23
#1234 10 122
#1233 92 4212
#1233 42 4252
#1239 87 2313
#1233 56 1121
#1231 19 45
#1235 45 679
cat data | awk '$2>=30&&$2<=90{dic[$1]+=$3}; END{for (i in dic) {print i, dic[i]}}'欢迎加入我的知识星球,一起探讨架构,交流源码。加入方式,长按下方二维码噢:

已在知识星球更新源码解析如下:




最近更新《芋道 SpringBoot 2.X 入门》系列,已经 101 余篇,覆盖了 MyBatis、Redis、MongoDB、ES、分库分表、读写分离、SpringMVC、Webflux、权限、WebSocket、Dubbo、RabbitMQ、RocketMQ、Kafka、性能测试等等内容。
提供近 3W 行代码的 SpringBoot 示例,以及超 6W 行代码的电商微服务项目。
获取方式:点“在看”,关注公众号并回复 666 领取,更多内容陆续奉上。
文章有帮助的话,在看,转发吧。
谢谢支持哟 (*^__^*)













 104
104











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









