







1 Linux cat命令:连接文件并打印输出到标准输出设备
cat命令的用途是连接文件或标准输入并打印。这个命令常用来显示文件内容,或者将几个文件连接起来显示,或者从标准输入读取内容并显示,它常与重定向符号配合使用
关于此命令,有人认为写
cat命令的人是因为喜欢猫,因此给起名为cat,其实不然,cat是concatenate(连接、连续)的简写。
cat命令的基本格式如下:
[chen@localhost~]$ cat [option] filename // 显示文件内容
或者
[chen@localhost~]$ cat > filename // 从键盘创建一个文件
或者
[chen@localhost~]$ cat filename1 filename2 > filename3 //
连接合并文件(创建或覆盖filename3文件)
| 选项 | 功能 |
|---|---|
-A | 相当于-VET,用于列出所有隐藏符号 |
-E | 列出每行结尾的回车符$ |
-n | 对输出的所有行进行编号 |
-b | 同-n不同,只对非空行编号 |
-T | 把Tab键显示出来 |
-V | 列出特殊字符 |
-s | 当遇到有连续2行以上空白行时,替换为1行的空白行 |

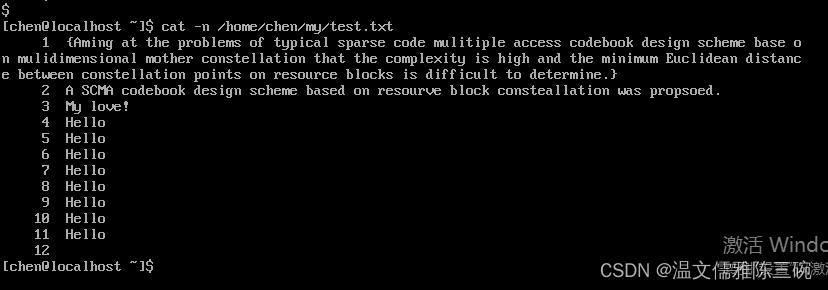
cat命令用于查看文件内容时,不论文件内容有多少,都会一次性显示。如果文件非常大,那么文件的开头内容就看不到了。不过Linux支持Pgup+上箭头组合键向上翻页,但是这种翻页是有限的。
因此,cat命令不太适合查看内容太大的文件。
2 Linux more命令:分页显示文件内容
在讲解cat命令的时候,我们留下了一个疑问,即当使用cat命令查看文件内容时,如果文件过大,以致于使用 pubg+上箭头组合键向上翻页也无法看全文件中的内容,该怎么办呢?这就需要more命令。
more命令可以分页显示文本文件的内容,使用者可以逐页阅读文件内容,more命令的基本格式如下:
[chen@localhost~]$ more [option] filename
| 选项 | 功能 |
|---|---|
-f | 计算行数时,以实际的行数,而不是自动换行过后的行数 |
-p | 不以卷动的方式显示每一页,而是先清除屏幕后再显示内容 |
-c | 先显示内容再清除屏幕 |
-s | 当遇上连续两行以上的空白行时,替换为一行的空白行 |
+n | 从第n行开始显示文件内容,n是数字 |
-n | 一次显示的行数,n是数字 |
more命令的执行会打开一个交互界面,因此有必要了解一些交互命令,如下表所示:
| 交互命令 | 作用 |
|---|---|
h或? | 显示more命令交互命令帮助 |
q或Q | 退出more |
v | 在当前行启动一个编辑器 |
:f | 显示当前文件的文件名和行号 |
!<命令> | 在子Shell里面执行指定命令 |
| 回车键 | 向下移动一行 |
| 空格键 | 向下移动一页 |
= | 显示当前行号 |
/abc | 搜索指定字符串abc |
d | 向下移动半页 |
b | 向上移动一页 |
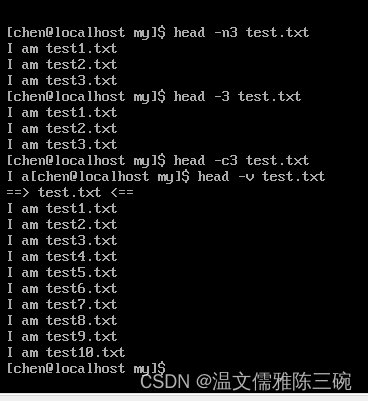
3 Linux head命令:显示文件开头内容
head命令可以显示指定文件前若干行的文件内容,其基本格式如下:
[chen@localhost~]$ head [option] filena
| 选项 | 功能 |
|---|---|
| 默认显示前10行的数据 |
-nK | 这里的K表示行数,显示文件前K行的内容 |
-cK | 这里的K表示字节数,显示文件前K字节的内容 |
-v | 显示文件名 |
4 Linux tail命令:显示文件结尾内容
tail命令的基本格式如下:
[chen@loaclhost~]$ tail [option] filename
| 选项 | 内容 |
|---|---|
-nK | K是行数,显示最后K行 |
-cK | K是字节数,显示最后K字节 |
-f | 监听文件的新增内容 |
tail命令有一种比较有趣的用法,监听文件的新增内容。
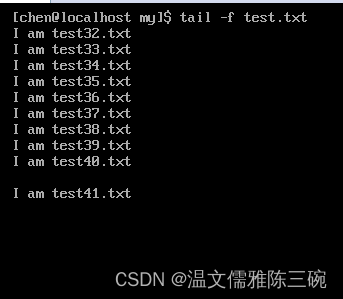
这条命令会显示文件的最后10行内容,且光标不会退出命令,每隔1秒会检查一下文件是否增加新的内容,如果增加就追加到原来的输出结果后并显示。
5 Linux less命令:查看文件内容
less命令的作用和more命令十分类似,都是用来浏览文件中的内容,不同之处在于,使用more命令浏览文件时,只能不断的向后浏览,而使用less命令,既可以向后翻看,也可以向前翻看。
不仅如此,为了方便用户浏览文本内容,less命令还提供了以下几种功能:
- 使用光标键可以在文本文件中前后移动
- 用行号和百分比作为书签浏览文件
- 提供更加友好的检索、高亮显示等操作
- 兼容常用的字处理程序(如Vim,Emacs)的键盘操作等
- 阅读到文件结束时,less命令不会退出
- 屏幕底部的信息提示更容易控制使用,而且提供了更多的信息。
less命令的基本格式如下:
[chen@localhost~]$ less [location] filename
| 选项 | 作用 |
|---|---|
| ` | -N` |
-S | 行过长时将超出部分舍弃 |
-e | 当文件显示结束后,自动离开 |
-g | 只标志最后搜索的关键词 |
-Q | 不使用警告音 |
-i | 忽略搜索时的大小写 |
-m | 显示类似more命令的百分比 |
-f | 强制打开特殊文件,如二进制文件 |
-s | 显示连续空行为单行 |
在使用less命令查看文件内容的过程中,和more命令一样,也会进入交互界面,因此需要掌握一些常用的交互指令。
| 交互指令 | 功能 |
|---|---|
/abc | 向下搜索字符串abc |
?abc | 向上搜索字符串abc |
b | 向上移动一页 |
d | 向下移动半页 |
h或H | 显示帮助页面 |
q或Q | 退出less命令 |
y | 向上移动一行 |
| 空格键 | 向下移动一页 |
| 回车键 | 向下移动一行 |
| Pgdn键 | 向下移动一页 |
| Pgup键 | 向上移动一页 |
6 Linux 重定向
计算机最基础的功能是可以提供输入输出操作。对于Linux系统而言,通常以键盘为默认输入设备,又称标准输入设备;以显示器为默认的输出设备,又称标准输出设备。所谓重定向,就是将原本应该从标准输入设备(键盘)输入的数据,改由其他文件或设备输入,将原本应该输出到标准输出设备(显示器)的内容,改由输出到其他文件或设备上。
【标准输出重定向】
[chen@localhost~]$ Command > filename // 覆盖
[chen@localhost~]$ Command >> filename // 追加
【标准输入重定向】
[chen@localhost~]$ Command < filename
以filename为标准输入
[chen@localhost~]$ Command < filename1 > filename2
以filename1为标准输入,以filename2为标准输出
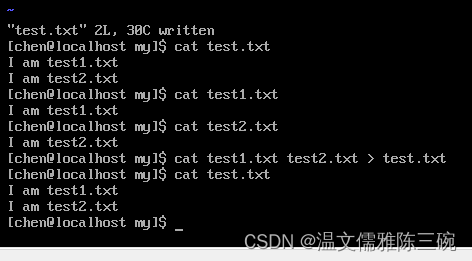
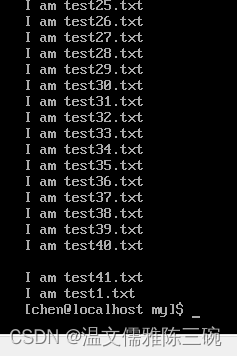
【例1】
[chen@localhost my]$ cat test.txt > test6.txt
[chen@localhost my]$ cat test1.txt >> test6.txt
7 Linux grep(三剑客):查找文件内容
很多时候,我们并不需要列出文件的全部内容,而是从文件中找到包含指定信息的那些行,要实现这个目的,可以使用grep命令。
grep命令可以追溯到UNIX诞生的早期,在UNIX系统中,搜索的模式(patterns)被称为正则表达式(regular expressions),为了要彻底搜索一个文件,有的用户在要搜索的字符串前加上前缀global,一旦找到相匹配的内容,用户就将其输出(print)到屏幕上,而将这一系列操作整合到一起就是 global regular expreesions print,而这也是grep命令的全称。
grep命令能够在一个或多个文件中,搜索某一特定的字符模式(也就是正则表达式),此模式可以是单一的字符、字符串、单词或句子。
正则表达式是描述一组字符串的一个模式。正则表达式的构成模仿了数学表达式,通过使用操作符将较小的表达式组合成一个新的表达式。正则表达式可以是一些纯文本文字,也可以是用来产生模式的一些特殊字符。为了进一步定义一个搜索模式,grep命令支持如下的几种正则表达式的元字符(也就是通配符)。
| 通配符 | 功能 |
|---|---|
c* | 将匹配0个或多个字符c(c为任一字符) |
. | 将匹配任何一个字符,且只能是一个字符 |
[xyz] | 匹配方括号中的任一一个字符 |
[^xyz] | 匹配方括号外的任一一个字符 |
^ | 锁定行的开头 |
$ | 锁定行的结尾 |
需要注意的是,在基本正则表达式中,如通配符*、+、{、|、(等,已经失去了它们本来的含义,若要恢复本来的含义,需要在之前加上反斜杠\。
grep命令用来在每一个文件种搜索特定的模式,当使用grep命令时,包含指定字符模式的每一行内容,都会被打印到屏幕上,但是使用grep命令并不会改变文件中的内容。
grep命令的基本格式:
[chen@localhost~]$ grep [option] mode filename
【mode】:模式
- 字符(串)
- 正则表达式
【option】:选项
| 选项 | 作用 |
|---|---|
-c | 仅列出文件中包含模式的行数 |
-i | 忽略模式中的大小写 |
-l | 列出带有匹配行的文件名 |
-n | 在每一行的最前面列出行号 |
-v | 列出没有匹配模式的行 |
-w | 把表达式作为一个完整的单字符来搜索 |
注意,如果搜索多个文件,
grep命令的搜索结果只显示文件集中发现匹配模式的文件名;而搜索单个文件,则会显示每一个包含匹配模式的行。
【例1】
[chen@localhost my] grep -n test.*.*.txt test.txt

8 Linux sed(三剑客):处理文件内容
sed是非交互式的编辑器。它不会修改文件,除非使用Shell重定向保存结果。默认情况下,所有的输出行都被打印到屏幕上。
sed编辑器逐行处理文件(输入),并将结果发送到屏幕。
具体过程如下:
- 首先
sed把当前正在处理的行保存在一个临时缓存区(模式空间),然后处理临时缓存区中的行,完成后把该行发送到屏幕。 sed处理完一行就将其从临时缓存区删除,然后将下一行读入,进行处理和显示。- 处理完输入文件的最后一行后,sed便结束运行。
sed把每一行都存在临时缓存区,对这个副本进行编辑,所以不会修改到原文件。
sed命令的基本格式如下:
[~]$ sed [option] '[script]' filename
[~]$ sed [option] '[address] [command]' filename
| option | 作用 |
|---|---|
-n | 不输出模式中的内容到屏幕,默认情况下,sed 会在所有的脚本指定执行完毕后,会自动输出处理后的内容 |
-e | 将后跟的脚本命令执行 |
-f | 将后跟的脚本文件执行 |
-r | 支持使用扩展正则表达式 |
-i | 直接修改源文件,需慎用 |
| address | 指定地址范围 |
|---|---|
| 数字 | n,m |
| 正则表达式 | /***/ |
| command | 作用 |
|---|---|
s | 字符替换 |
d | 行删除 |
a | 行追加 |
i | 行插入 |
c | 行替换 |
y | 字符转换 |
p | 行打印 |
w | 行写入 |
r | 文件写入 |
8.1 s 字符替换
's/pattern/replacement/flags'
pattern表示替换前字符(串);replacement表示替换后字符(串);flags表示替换标志。
| flags | 作用 |
|---|---|
n | 1-512间的数字,表示要替换的字符串在第n次出现时才被替换,延迟替换 |
g | 地址范围内全体替换【例1】 |
p | 打印模式匹配行【例1】 |
w file | 写模式匹配行到文件file中【例2】 |
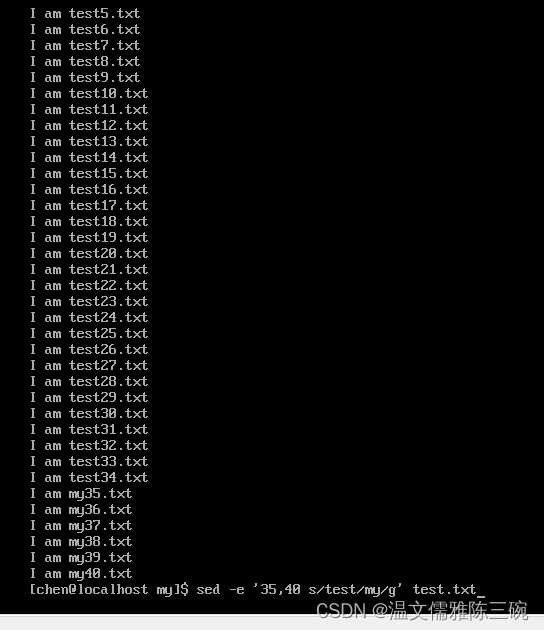
【例1】将/home/chen/my/test.txt文件中第35-40行中的字符串test替换为字符串my。
[chen@localhost my]$ sed -e '35,40 s/test/my/g' test.txt
[chen@localhost my]$ sed -n '35,40 s/test/my/gp' test.txt
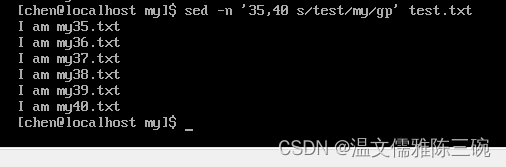
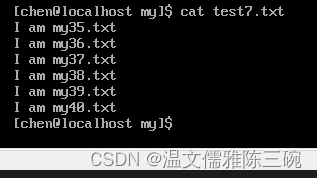
【例2】将/home/chen/my/test.txt文件中第35-40行中的字符串test替换为字符串my,并写入test7.txt文件中。
[my]$ sed -e '35,40 s/test/my/w test7.txt' test.txt
8.2 d 行删除
'd'
如果需要删除文本中的特定行,可以用 d 脚本命令,它会删除指定行中的所有内容。但使用该命令时要特别小心,如果你忘记指定具体行的话,文件中的所有内容都会被删除。
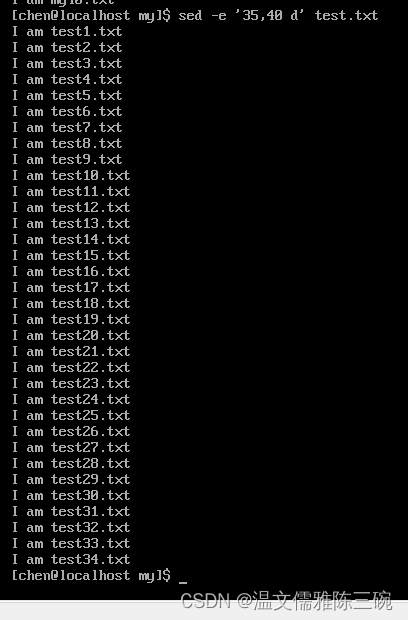
【例1】 删除/home/chen/my/test.txt文件中第35-40行中的内容。
[my]$ sed -e '35,40 d' test.txt
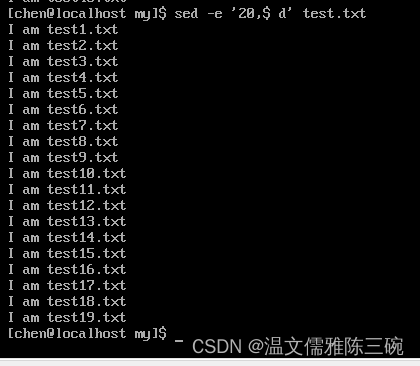
【例2】删除/home/chen/my/test.txt文件中20行之后的内容。
[my]$ sed -e '20,$ d' test.txt
8.3 a 行追加;i 行插入
'a\test'
'i\test'
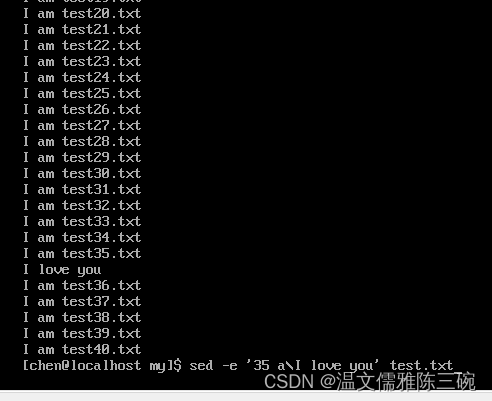
【例1】在/home/chen/my/test.txt文件中第35行后追加内容I love you。
[my]$ sed -e '35 a\I love you' test.txt
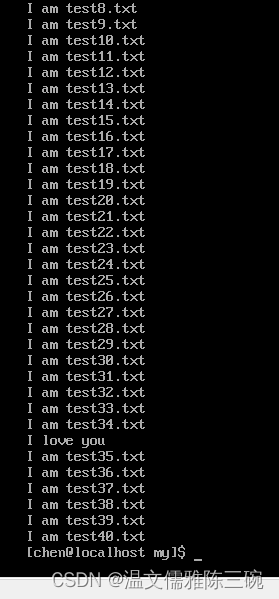
【例2】在/home/chen/my/test.txt文件中第35行前插入内容I love you。
[my]$ sed -e '35 i\I love you' test.txt
8.4 c 行替换
'c\test'
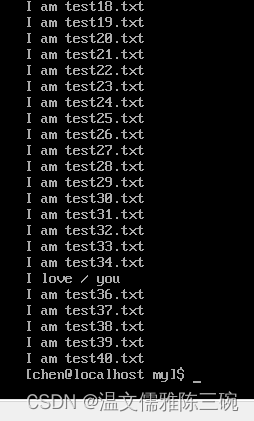
【例1】将/home/chen/my/test.txt文件中第35行内容替换为I love \ you。
[my]$ sed -e '35 c\I love /\ you' test.txt
或
[my]$ sed -e '/test35/ c\I love you' test.txt
8.5 y 字符转换
'y/inchars/outchars/'
y命令是唯一一个处理单个字符的sed脚本命令。
y命令是一个全局命令。也就是说,它会文本行中找到的所有指定字符自动进行转换,而不会考虑它们出现的位置。
转换命令会对 inchars 和 outchars 值进行一对一的映射,即 inchars 中的第一个字符会被转换为 outchars 中的第一个字符,第二个字符会被转换成 outchars 中的第二个字符…这个映射过程会一直持续到处理完指定字符。如果 inchars 和 outchars 的长度不同,则 sed 会产生一条错误消息。
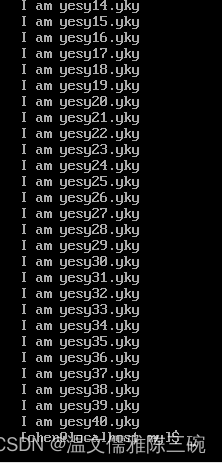
【例1】将/home/chen/my/test.txt文件中t字符转换为y字符,x字符转换为k字符。
[my]$ sed -e 'y/tx/yk/' test.txt
8.6 p 行打印
'p'
【例1】 将/home/chen/my/test.txt文件第一行内容打印到屏幕。
[my]$ sed -n '1 p' test.txt

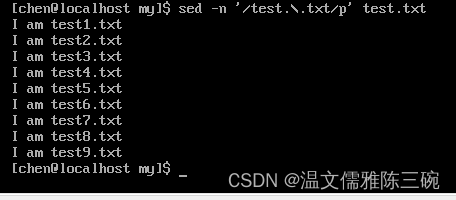
【例2】 将/home/chen/my/test.txt文件匹配正则表达式test.\.txt的行打印到屏幕。
[my]$ sef -n '/test.\.txt/' test.txt
8.7 w 行写入
'w filename'
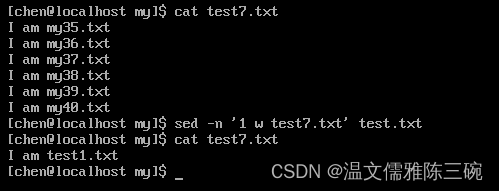
【例1】将/home/chen/my/test.txt文件第1行写入test7.txt文件。
[my]$ sed -n '1 w test7.txt' test.txt
8.8 r 文件插入
'r filename'
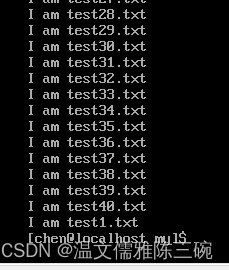
【例1】将test7.txt文件内容插入到/home/chen/my/test.txt文件的最后一行。
[my]$ sed -e '$ r test7.txt' test.txt
9 Linux awk(三剑客):处理文件内容
9.1 sed 与 awk 的区别
awk,sed,grep,俗称Linux下的三剑客。
它们之间有很多的相似点,但同样也有各自的特色,相似的地方是它们都可以匹配文本,其中,sed和awk还可以用于文本编辑,而grep则不具备这个功能。
sed是一种非交互式其面向于字符流的编辑器。
awk是一门模式匹配的编程语言,因为它的主要功能是用于匹配文本并处理,同时它有一些编程语言才有的语法,例如,函数、分支循环语句、变量等。
grep更适合单纯的查找和匹配文本sed更适合编辑匹配到的文本awk更适合格式化位版本,对文本进行复杂格式处理
awk命令与sed命令一样,均是一行一行读取、处理。区别在于sed是一整行的处理,而awk将一行分为若干字段来处理。简单来说awk就是把文件逐行的读入,以空格为默认分隔符将每行切片,切开的部分再进行各种分析处理。
9.2
具体指令会在今后工作需要的时候 进一步整理。否则,仅进行整体把握。















 648
648











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









