






点击上方“Java基基”,选择“设为星标”
做积极的人,而不是积极废人!
每天 14:00 更新文章,每天掉亿点点头发...
源码精品专栏
一:背景
测试反馈dev环境服务不稳定经常报错,查看没有具体业务报错,很是奇怪,于是看了下机器指标,发现内存使用率极高。
基于 Spring Boot + MyBatis Plus + Vue & Element 实现的后台管理系统 + 用户小程序,支持 RBAC 动态权限、多租户、数据权限、工作流、三方登录、支付、短信、商城等功能
项目地址:https://github.com/YunaiV/ruoyi-vue-pro
视频教程:https://doc.iocoder.cn/video/
二:猜想
会不会是因为频换fullgc导致线程卡顿,服务暂停????,带着这个疑问继续分析。
基于 Spring Cloud Alibaba + Gateway + Nacos + RocketMQ + Vue & Element 实现的后台管理系统 + 用户小程序,支持 RBAC 动态权限、多租户、数据权限、工作流、三方登录、支付、短信、商城等功能
项目地址:https://github.com/YunaiV/yudao-cloud
视频教程:https://doc.iocoder.cn/video/
三:验证猜想
拿到具体的报错traceId 看大部分都是超时,去查看机器日志也没有业务异常。
查看机器指标是否异常
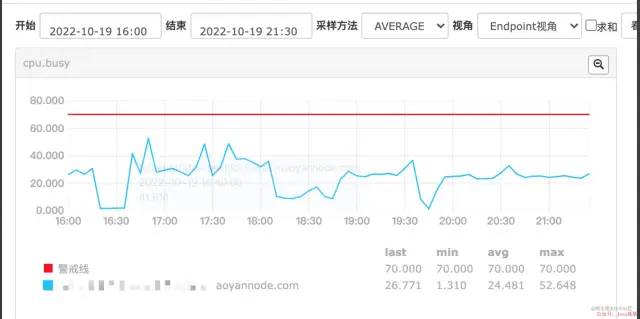
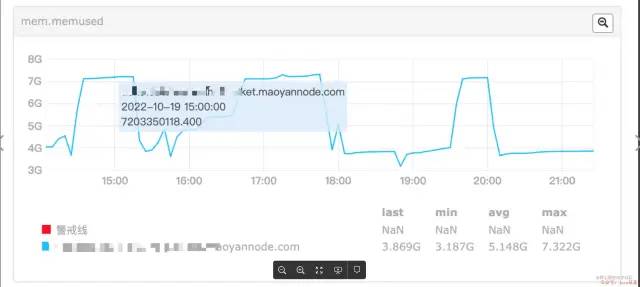
从上边看到 机器在某个时候 内存使用量飙升,内存时不时会高起来很多,基本上内存快使用完了。
登陆机器查看相应GC指标
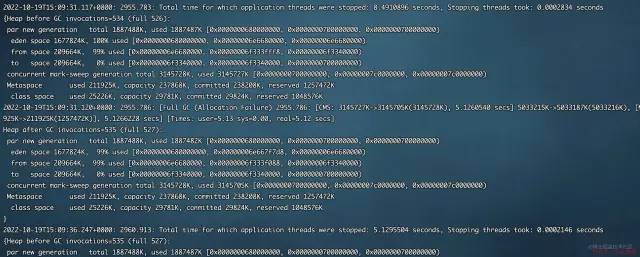
可以看到基本上每5 s 一次full gc(从526到527 )可以看出这是stop the world过于频繁导致,特别值得注意的是,GC前eden的占用是100%,s0的占用是99%,此时还有Allocation Failure说明old区也满了。eden和s0的对象都无法,通过Full GC回收,年轻代对象继续向old区晋升, 但是old区也满了,导致 Allocation Failure 触发Full GC,而且耗时5.12 secs,这可是STW啊,整个系统都暂停响应了。再看GC后的情况 ,eden和s0的占用量 都还是99% 。说明有大对象还在一直占用着引用,full gc 都回收不掉。
使用 jmap -histo:live pid | more 查看存活的类 ,只有如下信息(当时没有截图,下图是个实例,也看不来具体大对象)
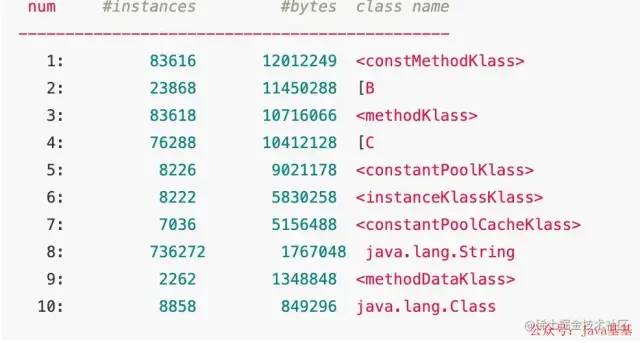
后来也没发现什么眉目。
不挣扎了,由于没有发生OOM,所有在内存使用率较高的时候自己手动dump下来看下吧
jmap -dump:format=b,file=文件名 [pid]dump文件比较大,如果要下载下来可以先 压缩
tar -czvf dump.hprof.zip dump.hprof获取到dump文件到本地 解压(6g多),使用MAT工具打开。
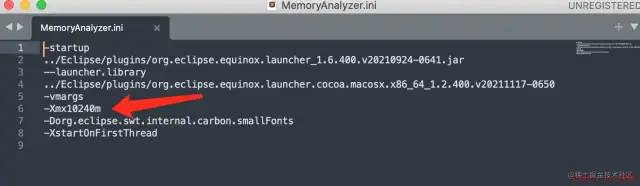
有时候线上产生的堆dump文件较大,如果你的hprof文件没有问题的话,使用MAT打开的时候总是抛出 Java Heap Error. 可能是默认的1024m内存不够用了,按照下图调大即可。
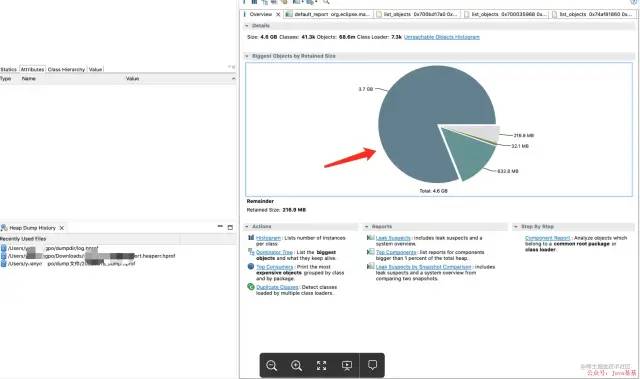
具体分析
机器配置是参数:
JVM_HEAP="-XX:NewSize=2048m -XX:MaxNewSize=2048m -XX:SurvivorRatio=8 -XX:+HeapDumpOnOutOfMemoryError -XX:ReservedCodeCacheSize=128m -XX:MetaspaceSize=256m -XX:MaxMetaspaceSize=512m
-XX:InitialCodeCacheSize=128m -XX:NativeMemoryTracking=summary"
JVM_SIZE="-Xmx5g -Xms5g -Xss512k"可以看到heap的总的大小是5G,年轻代分了2G,但是图中显示已经使用了4.6G,其中还有一个3.7G 的大对象,具体场景可能还涉及项目场次copy的时候,如果copy的还是原先的那个场次(blocktype 100W➕,剩余的内存肯定不够),这个后边会说,这是具体抽象业务。
一般在上边那个图中我们大致可以先 Leak Suspects 入手,这边里会给你提示系统现有存在的问题,其他列功能,可以自行了解。
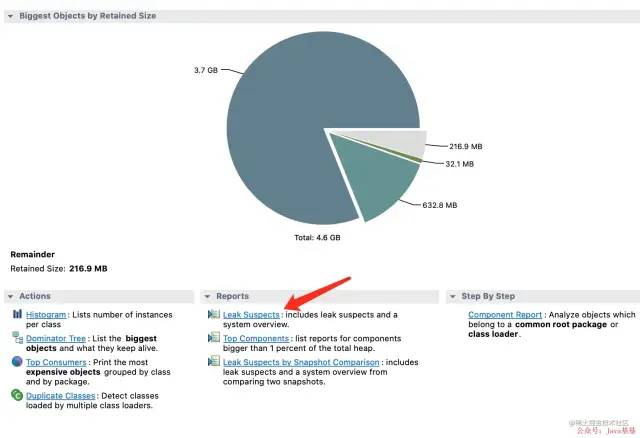
进去后如下图,看到PerformanceCopyThread-1 线程占用了 81% 的内存 大概就是上边看到的3.7G
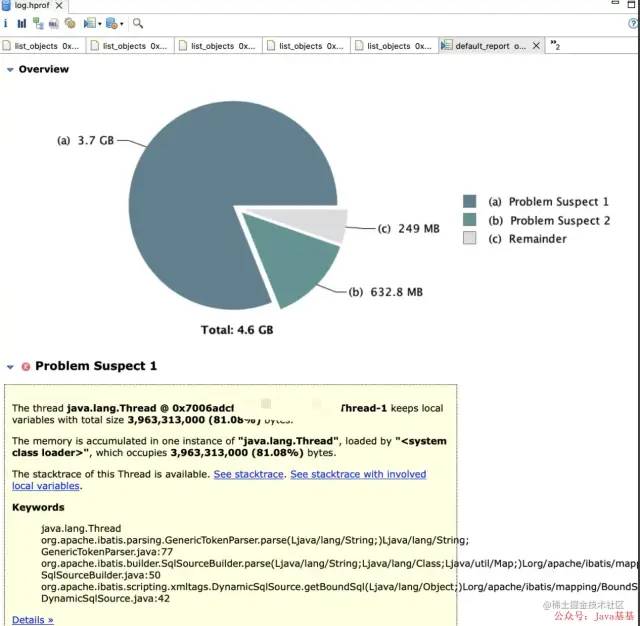
点开 查看线程堆栈详情以及具体Details ,都指向blocktype(具体业务类)

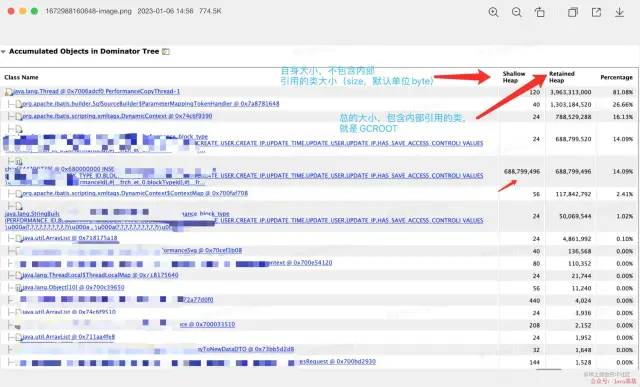
一个对象的shallow heap的大小指的是该对象在没有引用其他对象的情况下本身占用的内存大小
retained heap是指对象自己本身的shallow heap的大小加上对象所引用的对象的大小。
换句话说retained heap的大小是指该对象被回收时垃圾回收器应该回收的内存的大小。这时候只是定位到是一个copy 业务 有问题,但是具体什么为什么占用这么多内存还是理解,具体深入找线索,查看相应 Dominator Tree ,发现数量很多,不太对为什么copy 一个业务 会生成怎么多blocktype。

再次查看 All Accumulated Objects by Class 的内容 (按照顺序显示其引用的对象)
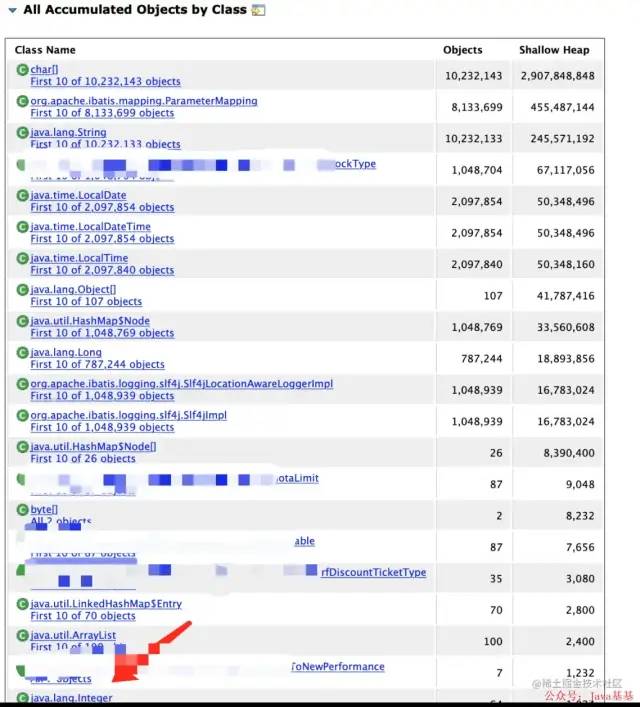
可以看出当前线程 操作了7个 场次copy ,点开查看就比较直观了
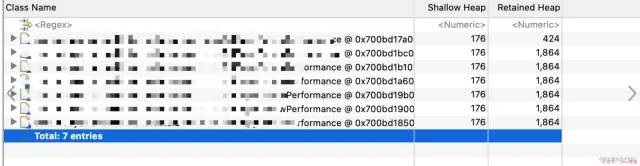
打来发现所有的 copy的都是 项目统一业务id 下有 19240 条数据,同时排除了代码中是否所有重复放blocktype的可能性,考虑线程中使用了ThreadLocal ,是否存在copy完一个业务后, 这个场次的相关数据没有清除,直接被第二个copy出来的使用,如果业务过多一直循环下去。
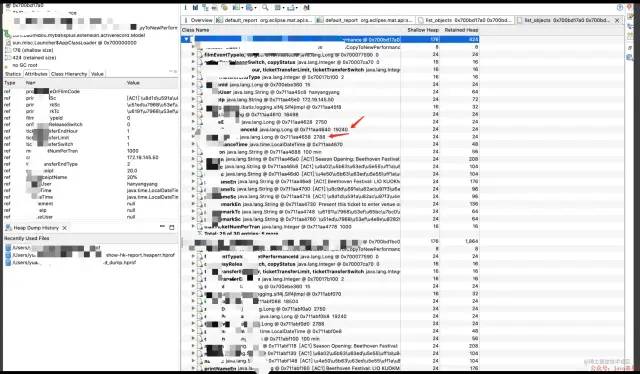
这里已经能看到具体copy的原始数据了,那原始数据会不会有问题,带着疑问去查下业务Id 2788 下的 19240 业务的的blocktype。发现数据量为 1048577条,问题答案水落石出,这么多数据放到内存里,批量生成插入语句,就会有前边那个堆栈爆出 来问题,同时这么多数据也是在内存里存储,直到所在代码块执行完。
后续又仔细过了下代码,发现问题
分析:BlockType 的copy 传入的是原业务Id,方法里拿着原业务id当作目标场次的id,所以copy的具体业务 插入的永远是原场次的blocktype数据,如果copy的场次比较多就会指数级增加,最后导致oom
解决方式 blocktype 表加上唯一键限制。
四:总结
此问题最最终的原因就是业务中有大量脏数据,加上相应业务代码用错业务id,导致原先大量的脏数据,被加载到内存中,并且是到一定量的时候才会提交,所以一直会在内存中累加,如果脏数据尽可能多后续就会产生oom。每个公司都有自己的业务,这里只是提供一个排查问题的思路。
欢迎加入我的知识星球,一起探讨架构,交流源码。加入方式,长按下方二维码噢:

已在知识星球更新源码解析如下:




最近更新《芋道 SpringBoot 2.X 入门》系列,已经 101 余篇,覆盖了 MyBatis、Redis、MongoDB、ES、分库分表、读写分离、SpringMVC、Webflux、权限、WebSocket、Dubbo、RabbitMQ、RocketMQ、Kafka、性能测试等等内容。
提供近 3W 行代码的 SpringBoot 示例,以及超 6W 行代码的电商微服务项目。
获取方式:点“在看”,关注公众号并回复 666 领取,更多内容陆续奉上。
文章有帮助的话,在看,转发吧。
谢谢支持哟 (*^__^*)














 464
464











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









