







自己学习的心得,如有错误欢迎指正…
简单认识
首先华为DAYU平台中有两套Spark组件,一个是DLI Spark另一个是MRS Spark。
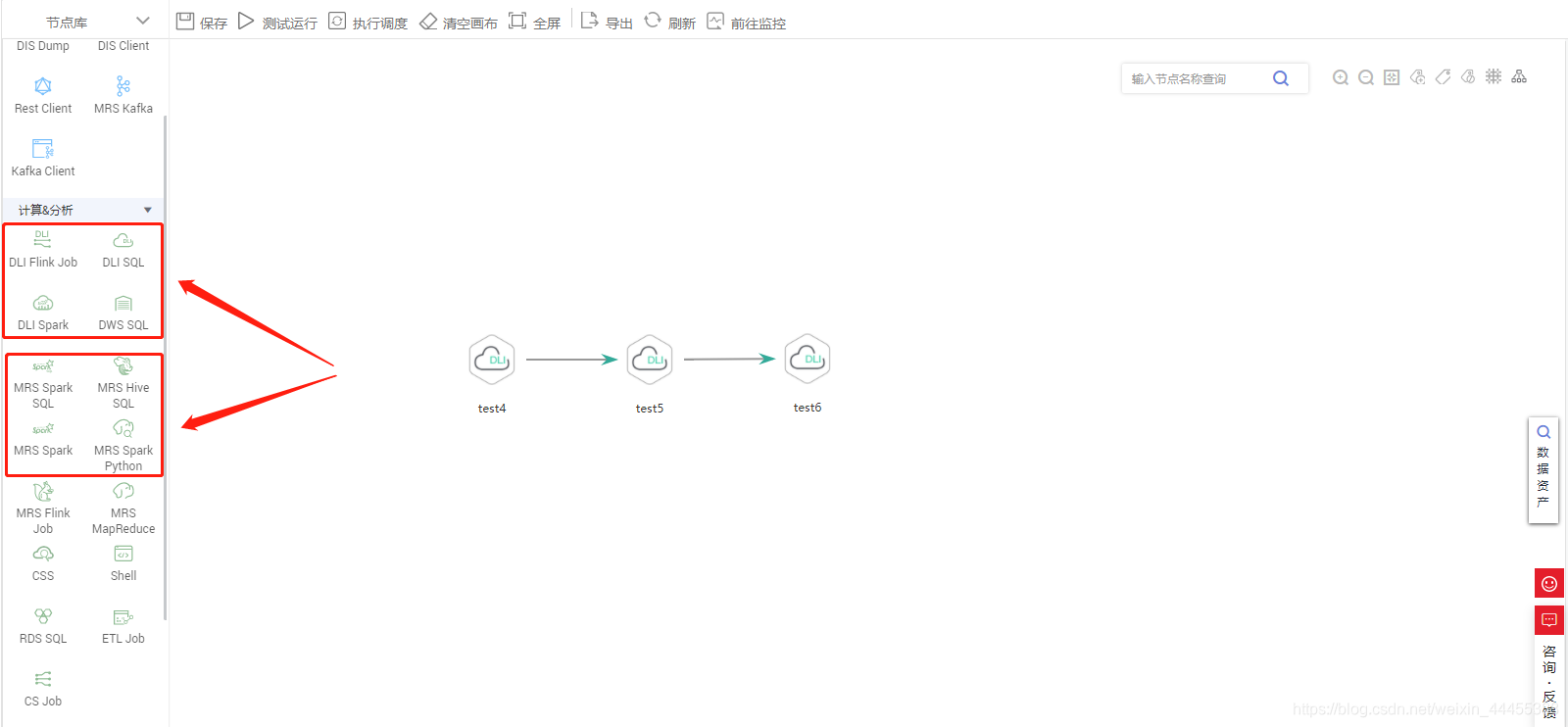
DLI是数据湖探索服务,是完全兼容Apache Spark和Apache Flink生态, 实现批流一体的Serverless大数据计算分析服务。DLI支持多模引擎,企业仅需使用SQL或程序就可轻松完成异构数据源的批处理、流处理、内存计算、机器学习等,挖掘和探索数据价值。
MRS是一个在华为云上部署和管理Hadoop系统的服务,一键即可部署Hadoop集群。MRS提供租户完全可控的一站式企业级大数据集群云服务,完全兼容开源接口,结合华为云计算、存储优势及大数据行业经验,为客户提供高性能、低成本、灵活易用的全栈大数据平台,轻松运行Hadoop、Spark、HBase、Kafka、Storm等大数据组件,并具备在后续根据业务需要进行定制开发的能力,帮助企业快速构建海量数据信息处理系统,并通过对海量信息数据实时与非实时的分析挖掘,发现全新价值点和企业商机。
两套Spark并没有什么大的区别,仅在使用上存在一点差异:
1、使用DLI Spark需要申请相应的队列;使用MRS Spark则需要申请MRS集群;
2、DLI Spark对接DLI数据库(也可以跨源访问DWS\RDS等);MRS Spark我的理解是apache Spark能做到的他都能做到,其实可以理解成就是apache spark的云版本。
数据开发
在开发中,如果数据源是DLI,则首先推荐DLI Spark;如果数据源是MRS集群中的hive,则首先推荐MRS Spark(简单配置数据连接后就可以直接访问hive)。

代码就是hive on spark的写法,无需hive-core.xml文件了:
def main(args: Array[String]): Unit = {
//获取sparkSession
val sparkSession = SparkSession.builder()
.appName(this.getClass.getSimpleName.filter(!_.equals('$')))
.enableHiveSupport()
.getOrCreate()
sparkSession.sparkContext.setLogLevel("WARN")
//sparkSession.sql("use default")
sparkSession.sql("select * from default.zyn_test").createTempView("table1")
sparkSession.sql("select * from default.user2").createTempView("table2")
val frame: DataFrame = sparkSession.sql("select t1.*,t2.clor from table1 t1 join table2 t2 on t1.id=t2.id")
frame.createTempView("result")
sparkSession.sql("create table result1 as select * from result")
}
无论是何种数据源,计算逻辑比较简单的,则完全可以使用相应的SQL解决(DLI SQL和MRS Spark SQL)。
with t1 as (select * from test1),t2 as (select * from test2) select t1.*,t2.age from t1,t2 where t1.name=t2.name;
如是比较复杂的计算逻辑,需要使用spark代码:(理论上也都是通用的,IP能通就可以了)
//读取Oracle
val data: DataFrame = spark.read.format("jdbc")
.option("url", "jdbc:oracle:thin:@//10.212.xxx.xxx:11521/yjdawh")
.option("dbtable", dbtable)
.option("user", "xxx")
.option("password", "xxx#8981")
.option("ssl","false")
.load()
//读取DWS
val data: DataFrame = spark.read.format("jdbc")
.option("url", "jdbc:postgresql://to-dws-xxxxx.datasource.com:8000/postgres")
.option("dbtable", dbtable)
.option("user", "root")
.option("password", "123")
.option("driver", "org.postgresql.Driver")
.load()
//读取hive(JDBC方式)
val properties = new Properties()
properties.put("user","hive2")
properties.put("password","hive2")
val data: DataFrame = spark.read.jdbc("jdbc:hive2://192.168.72.141:10000/default",dbtable,properties)
以上dbtable也都可以写成如下的方式(oracle\DWS\hive均可以,只是SQL的写法和一些函数会有一些不同),首先过滤掉不需要的数据:
val data: DataFrame = spark.read.format("jdbc")
.option("url", "jdbc:hive2://192.168.72.141:10000/default")
.option("dbtable", "(select obj_id,u1,u2,u3 from test2 where data_date=date_sub(current_date(),1)) tmp")
.option("user", "xxx")
.option("password", "xxx")
.load()
数据保存与取数
从上面的数据开发过程来看,一般情况下是数据源属于哪个库,我们就将结果数据保存在哪个库。例如数据源为hive,那我们就使用MRS Spark将结果数据保存到hive中。
结果数据的保存还需要和APIG取数一块儿来考虑,因为一般情况下各网省是不允许前后端程序直接从DAYU平台取数(类似我们以往直接从Oracle/MySQL取数一样),这样会给数据中台带来较大的负载。从中台取数一般使用官方推荐的APIG的方式。
而目前华为APIG取数仅支持四种数据库:DWS、DLI、MySQL、RDS。

所以结果数据保存的最终位置一定是在以上四种数据库中的。

















 8490
8490

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









