







pandas中
1 字符串离散化
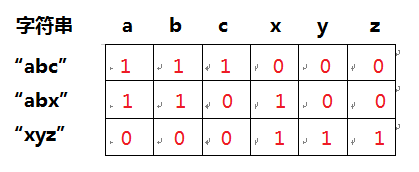
所谓字符串离散化,指的是将字符串转化为向量,例如下面三个字符串的转化示意图
假如电影数据“IMDB-Movie-Data.csv”,我们希望统计电影分类(genre)的情况,并绘制各种类型电影数据的条形图,应该如何处理数据?
# coding=utf-8
import pandas as pd
from matplotlib import pyplot as plt
import numpy as np
file_path = "IMDB-Movie-Data.csv"
df = pd.read_csv(file_path)
print(df["Genre"].head(3))
# 统计分类的列表
temp_list = df["Genre"].str.split(",").tolist() #[[],[],[]]列表嵌套列表
# print(temp_list)
genre_list = list(set([i for j in temp_list for i in j]))
# print(genre_list)
# 构造全为0的数组
zeros_df = pd.DataFrame(np.zeros((df.shape[0],len(genre_list))),columns=genre_list)
# 注意,对DataFrame使用len方法,求的是其列的数量
# columns=genre_list指定了列索引
# print(zeros_df)
# 给每个电影出现分类的位置赋值1
for i in range(df.shape[0]):
# zeros_df.loc[0,["Sci-fi","Mucical"]] = 1
zeros_df.loc[i,temp_list[i]] = 1
# temp_list是大列表嵌套小列表,因此temp_list[i]是小列表
# 小列表里的元素都是字符串,表示的是该电影的类型
# 它们放在loc的第二个位置,表示对多个位置同时赋值
print(zeros_df.head(3))
# 统计每个分类的电影的数量和
genre_count = zeros_df.sum(axis=0) # 指定了折叠方向,返回的结果是Series类型
# print(genre_count)
# print(type(genre_count))
# 排序
genre_count = genre_count.sort_values()
# 因为是Series对象,因此无需指定排序字段,默认升序
_x = genre_count.index
_y = genre_count.values
# 画图
plt.figure(figsize=(20,8),dpi=80)
plt.bar(range(len(_x)),_y,width=0.4,color="orange")
plt.xticks(range(len(_x)),_x)
plt.show()
输出图像

字符串离散化,转化成数据进行统计,这个思路要学会。
2 数据合并
(1)join
默认情况下他是把行索引相同的数据合并到一起

没有数据的地方,用NaN补全
(2)merge
按照指定的列把数据按照一定的方式合并到一起
若t1和t2的数据如下所示

t1.merge(要连接的数据, left_on =左边关键字, right_on =右边关键字, how=连接方式)

可以看到,默认的合并方式为inner,即为交集
如果how为outer,则显示并集

没有数据的地方,用NaN补全
也可以以左边为准,或者右边为准

注意,所有情况都是在并集的基础上进行选择,也就是说,从并集里面选择特定的行显示,因此当以左边为主时,right_on不能省略,右边亦然
如果两个DataFrame对象,都有相同的字段(列),并希望以这相同的字段作为关键字进行连接,那么可以直接用on


on是左右两个数组都有的字段。左边有4列,右边有5列,但最后显示的结果只有8列,因为O已经合并
3 分组聚合
现在有一组关于全球星巴克店铺的统计数据(starbucks_store_worldwide.csv),如果想查看美国和中国的星巴克数量,该如何实现?
用以前学的方法,使用布尔索引
import pandas as pd
import numpy as np
file_path = "starbucks_store_worldwide.csv"
data = pd.read_csv("starbucks_store_worldwide.csv")
# print(data.info())
# print(data.head(1))
# 美国星巴克数量
info_us = data[data["Country"]=="US"]
print(len(info_us))
# 中国星巴克数量
info_cn = data[data["Country"]=="CN"]
print(len(info_cn))
输出
13608
2734
这里我们要介绍另外一种方法——分组聚合 groupby
(1)分组
使用Excel打开数据,可以看到有一个字段是Country,那么我们可以根据这个字段对数据进行分组,然后再筛选中国和美国的数据。
分组方法:df.groupby(by=字段名)
DataFrame对象调用groupby的结果是DataFrameGroupBy对象,它是可遍历的。
DataFrameGroupBy对象的每一个元素都是一个元组,元组里面是(索引(分组的值),分组之后的DataFrame),例如,将数据根据Country分组,那么其索引就是国家名。
Series对象调用groupby的结果是SeriesGroupBy对象,性质与DataFrameGroupBy对象类似,对Series对象进行分组聚合,在“3 复合索引”中会具体介绍。
分组示例:
import pandas as pd
dc = [{"city":"beijing", "brand":"puma", "tel":10086},
{"city":"beijing", "brand":"nike", "tel":10010},
{"city":"beijing", "brand":"addidas", "tel":10087},
{"city":"shanghai", "brand":"puma", "tel":10011},
{"city":"shanghai", "brand":"nike", "tel":10012},
{"city":"shanghai", "brand":"addidas", "tel":10013}]
df = pd.DataFrame(dc)
# 遍历
grouped = df.groupby(by=["city"])
for i,j in grouped:
print(i)
print("-"*50)
print(j,type(j))
print("*"*80)
输出
beijing
--------------------------------------------------
city brand tel
0 beijing puma 10086
1 beijing nike 10010
2 beijing addidas 10087 <class 'pandas.core.frame.DataFrame'>
********************************************************************************
shanghai
--------------------------------------------------
city brand tel
3 shanghai puma 10011
4 shanghai nike 10012
5 shanghai addidas 10013 <class 'pandas.core.frame.DataFrame'>
********************************************************************************
(2)聚合
其实就是调用聚合方法,常用聚合方法如下:

(3)分组聚合
将星巴克店铺统计数据先按国家名(Country)进行分组,然后使用count()方法计算每个国家的数量,代码如下:
import pandas as pd
import numpy as np
file_path = "starbucks_store_worldwide.csv"
df = pd.read_csv(file_path)
grouped = df.groupby(by="Country")
# print(grouped)
# grouped是一个DataFrameGroupBy对象,是可迭代的
# grouped中的每一个元素是一个元组
# 元组里面是(索引(分组的值),分组之后的DataFrame)
# 遍历
# for i,j in grouped: # i是索引,j是分组之后的DataFrame
# print(i)
# print("-"*100)
# print(j,type(j))
# print("*"*100)
# 调用聚合方法
print(grouped.count()) # 统计每一种分类的频数
输出
Brand Store Number Store Name ... Timezone Longitude Latitude
Country ...
AD 1 1 1 ... 1 1 1
AE 144 144 144 ... 144 144 144
AR 108 108 108 ... 108 108 108
AT 18 18 18 ... 18 18 18
AU 22 22 22 ... 22 22 22
... ... ... ... ... ... ... ...
TT 3 3 3 ... 3 3 3
TW 394 394 394 ... 394 394 394
US 13608 13608 13608 ... 13608 13608 13608
VN 25 25 25 ... 25 25 25
ZA 3 3 3 ... 3 3 3
[73 rows x 12 columns]
如果数据没有缺失的话,每一列都是一样的,表示的是“当前分类在本列中出现的次数”,如果有某些数据缺失,则缺失的那一列会与其他列有所不同
也可以对某列调用聚合方法
# 对某列调用聚合方法
print(grouped["Brand"].count())
输出
Country
AD 1
AE 144
AR 108
AT 18
AU 22
...
TT 3
TW 394
US 13608
VN 25
ZA 3
Name: Brand, Length: 73, dtype: int64
数据聚合时若未指定列,则返回DataFrame型,若指定列则返回Series类型。
“分组聚合”(不是分组,也不是聚合,而是 分组+聚合)可以作用于Series和DataFrame,作用于Series则返回Series,作用于DataFrame则返回DataFrame。
print(type(grouped.count()))
print(type(grouped["Brand"].count()))
输出
<class 'pandas.core.frame.DataFrame'>
<class 'pandas.core.series.Series'>
现在使用聚合方法统计中国和美国的星巴克数量
import pandas as pd
import numpy as np
file_path = "starbucks_store_worldwide.csv"
df = pd.read_csv(file_path)
grouped = df.groupby(by="Country")
country_count = grouped["Brand"].count()
# 因为对某一列聚合后,返回的结果是Series类型,索引是国家简称
# 因此使用Series的方法来访问数据
print(country_count["CN"])
print(country_count["US"])
输出
2734
13608
统计中国各个省份的数量
import pandas as pd
import numpy as np
file_path = "starbucks_store_worldwide.csv"
df = pd.read_csv(file_path)
# 先把中国的数据筛选出来
china_data = df[df["Country"] =="CN"]
# print(china_data)
# 以字段 State/Province 作为分类依据,然后筛选字段
grouped = china_data.groupby(by="State/Province").count()["Brand"]
print(grouped)
输出
State/Province
11 236
12 58
13 24
14 8
15 8
21 57
22 13
23 16
31 551
32 354
33 315
34 26
35 75
36 13
37 75
41 21
42 76
43 35
44 333
45 21
46 16
50 41
51 104
52 9
53 24
61 42
62 3
63 3
64 2
91 162
92 13
Name: Brand, dtype: int64
第一列是省份的数字编号
3 复合索引
(1)复合索引的产生
以两个字段作为分类依据,那么就会产生复合索引
如
import pandas as pd
import numpy as np
file_path = "starbucks_store_worldwide.csv"
df = pd.read_csv(file_path)
grouped = df["Brand"].groupby(by=[df["Country"],df["State/Province"]]).count()
# 下面这条语句无法进行分组,因为数据框中就没有"Country","State/Province"这两个字段
# grouped = df["Brand"].groupby(by=["Country","State/Province"]).count()
print(grouped)
print(type(grouped))
输出
Country State/Province
AD 7 1
AE AJ 2
AZ 48
DU 82
FU 2
..
US WV 25
WY 23
VN HN 6
SG 19
ZA GT 3
Name: Brand, Length: 545, dtype: int64
<class 'pandas.core.series.Series'>
上面是先筛选好字段,即只取“Brand”,返回的结果是用两个字段作为分类依据,最后生成的对象仍然为Series类型,只有最后一列才是数据,前两列都是索引
如果不先筛选字段,那么by后面的内容,可以不用加df,但最后得到的是DataFrame对象
import pandas as pd
import numpy as np
file_path = "starbucks_store_worldwide.csv"
df = pd.read_csv(file_path)
grouped = df.groupby(by=["Country","State/Province"]).count()
print(grouped)
print(type(grouped))
输出
Brand Store Number ... Longitude Latitude
Country State/Province ...
AD 7 1 1 ... 1 1
AE AJ 2 2 ... 2 2
AZ 48 48 ... 48 48
DU 82 82 ... 82 82
FU 2 2 ... 2 2
... ... ... ... ... ...
US WV 25 25 ... 25 25
WY 23 23 ... 23 23
VN HN 6 6 ... 6 6
SG 19 19 ... 19 19
ZA GT 3 3 ... 3 3
[545 rows x 11 columns]
<class 'pandas.core.frame.DataFrame'>
注意,若先筛选字段,但使用了两个方框,那么返回的结果是是DataFrame,而非Series,因为在DataFrame取列时,使用两对方括号,结果就是DataFrame
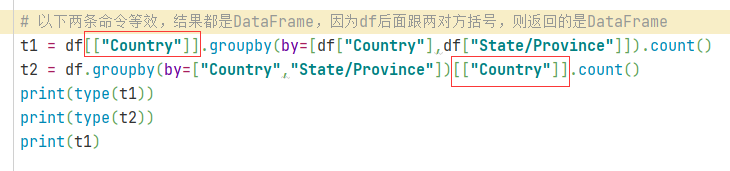
“分组聚合”可以作用于Series和DataFrame,作用于Series则返回Series,作用于DataFrame则返回DataFrame
若对Series使用groupby方法,但分类依据有多个字段,那么必须加df

(2)查看复合索引
获取索引 df.index
import pandas as pd
dc = {"name":["zhangsan", "lisi", "wangwu"],
"age":[25, 26, 27],
"tel":[10086, 10010, 10000],
"score":[90, 89, 95]}
df = pd.DataFrame(dc)
print(df)
print(50 * '*')
data = df.groupby(by=["age", "score"]).sum()
print(data)
print(data.index)
输出
name age tel score
0 zhangsan 25 10086 90
1 lisi 26 10010 89
2 wangwu 27 10000 95
**************************************************
tel
age score
25 90 10086
26 89 10010
27 95 10000
MultiIndex([(25, 90),
(26, 89),
(27, 95)],
names=['age', 'score'])
MultiIndex表示符合索引
若是Series,复合索引同样如此
data = df["tel"].groupby(by=[df["age"], df["score"]]).sum()
print(data)
print(data.index)
输出
**************************************************
age score
25 90 10086
26 89 10010
27 95 10000
Name: tel, dtype: int64
MultiIndex([(25, 90),
(26, 89),
(27, 95)],
names=['age', 'score'])
(3)复合索引取数据
import pandas as pd
dc = [{"city":"beijing", "brand":"puma", "tel":10086},
{"city":"beijing", "brand":"nike", "tel":10010},
{"city":"beijing", "brand":"addidas", "tel":10087},
{"city":"shanghai", "brand":"puma", "tel":10011},
{"city":"shanghai", "brand":"nike", "tel":10012},
{"city":"shanghai", "brand":"addidas", "tel":10013}]
df = pd.DataFrame(dc)
# print(df)
t1 = df.groupby(by=["city", "brand"]).sum()
# print(t1)
# print(type(t1))
t2 = t1["tel"]
# print(t2)
# print(type(t2))
t1是DataFrame对象,数据如下:
tel
city brand
beijing addidas 10087
nike 10010
puma 10086
shanghai addidas 10013
nike 10012
puma 10011
t2是Series对象,数据如下:
city brand
beijing addidas 10087
nike 10010
puma 10086
shanghai addidas 10013
nike 10012
puma 10011
Name: tel, dtype: int64
对于t1,使用loc来提取数据,第一次以外层索引为参数,第二次以内层索引为参数
print(t1.loc["shanghai"])
print('_' * 50)
print(type(t1.loc["shanghai"]))
print('_' * 50)
print(t1.loc["shanghai"].loc["addidas"])
print('_' * 50)
print(type(t1.loc["shanghai"].loc["addidas"]))
输出
tel
brand
addidas 10013
nike 10012
puma 10011
__________________________________________________
<class 'pandas.core.frame.DataFrame'>
__________________________________________________
tel 10013
Name: addidas, dtype: int64
__________________________________________________
<class 'pandas.core.series.Series'>
对于t2,直接使用中括号
print(t2["beijing"])
print('_' * 50)
print(type(t2["beijing"]))
print('*' * 50)
print(t2["beijing", "puma"])
print('+' * 50)
print(type(t2["beijing", "puma"]))
输出
brand
addidas 10087
nike 10010
puma 10086
Name: tel, dtype: int64
__________________________________________________
<class 'pandas.core.series.Series'>
**************************************************
10086
++++++++++++++++++++++++++++++++++++++++++++++++++
<class 'numpy.int64'>
(4)交换内层索引和外层索引
假设t1是DataFrame对象,数据如下:
tel
city brand
beijing addidas 10087
nike 10010
puma 10086
shanghai addidas 10013
nike 10012
puma 10011
t2是Series对象,数据如下:
city brand
beijing addidas 10087
nike 10010
puma 10086
shanghai addidas 10013
nike 10012
puma 10011
Name: tel, dtype: int64
现在只想取“nike”对应的值,该怎么办?
可以先对内外层索引进行交换,然后使用去外层索引的方式取“nike”
交换内外层索引,swaplevel()
s1 = t1.swaplevel()
s2 = t2.swaplevel()
print(s1)
print(50*'*')
print(type(s1))
print(50*'*')
print(s2)
print(50*'*')
print(type(s2)))
输出
tel
brand city
addidas beijing 10087
nike beijing 10010
puma beijing 10086
addidas shanghai 10013
nike shanghai 10012
puma shanghai 10011
**************************************************
<class 'pandas.core.frame.DataFrame'>
**************************************************
brand city
addidas beijing 10087
nike beijing 10010
puma beijing 10086
addidas shanghai 10013
nike shanghai 10012
puma shanghai 10011
Name: tel, dtype: int64
**************************************************
<class 'pandas.core.series.Series'
使用以下命令,即可查看“nike”的值
tel
city
beijing 10010
shanghai 10012
**************************************************
city
beijing 10010
shanghai 10012
Name: tel, dtype: int64
4 索引与字段
(1)查看索引与字段
df.index是查看索引,df.columns是查看字段

(2)修改索引与字段
给df.index和df.columns赋值,就是给索引与字段赋值

(3)按指定索引取行

t2.reindex([“p”, “m”]),p原来没有,m原来就有,所以在新的DataFrame中,p所在行为NaN
相当于从原来的数据框中取行。即该方法表示:原来有的就取出来,原来没有的,就用NaN表示
(4)设置某字段为索引

设置字段a为索引的时候,也可以保留字段a,drop等于True,表示在显示的表格里,保留字段a

以原DataFrame中a所在列为索引,这里需要注意的是,索引是可以重复的,但字段不行
(4)索引和字段重复
index是可迭代对象,也是可以重复的
行索引(索引)可以重复,但列索引(字段)重复会覆盖,如:
import pandas as pd
dc = {"name":["zhangsan", "lisi", "wangwu"],
"age":[25, 26, 27],
"tel":[10086, 10010, 10000],
"score":[90, 89, 95],
"score":[90, 89, 100]}
df = pd.DataFrame(dc)
print(df)
输出
name age tel score
0 zhangsan 25 10086 90
1 lisi 26 10010 89
2 wangwu 27 10000 100
score重复,列索引重复的时候,以最后的为准















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









