






一年多没更新博客了,这一年博主经历了很多,也学到了很多,近期会持续更新文章,主题不固定,哦,对了,博主跟几个朋友一起创建了一个大数据的技术社区,我们每周都会有技术分享以及技术交流的会议,目前社区人数高达800+,感兴趣的朋友可以扫描上方的二维码关注下社区的公众号,同时也可以添加博主的VX,邀你进群咱们一起交流啊!!!!
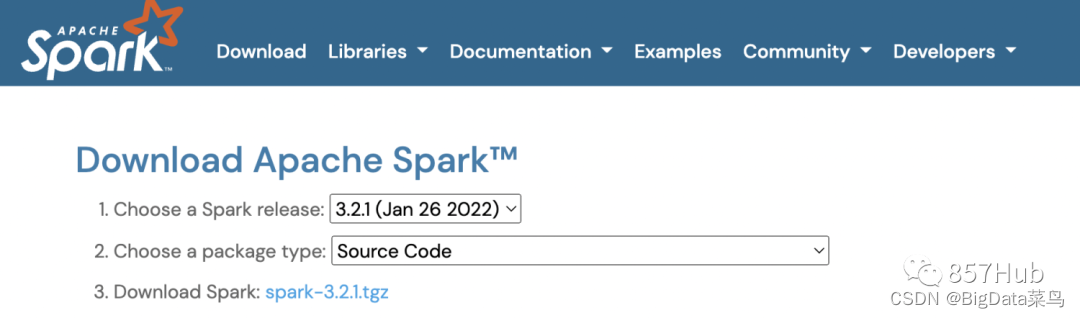
1、官网下载 3.2.1版本
链接:Downloads | Apache Spark
2、将文件上传至服务器解压,并对其dev下 make-distribution.sh做配置
tar -zxvf spark-3.2.1.tgz
进入到 spark-3.2.1目录下的dev目录
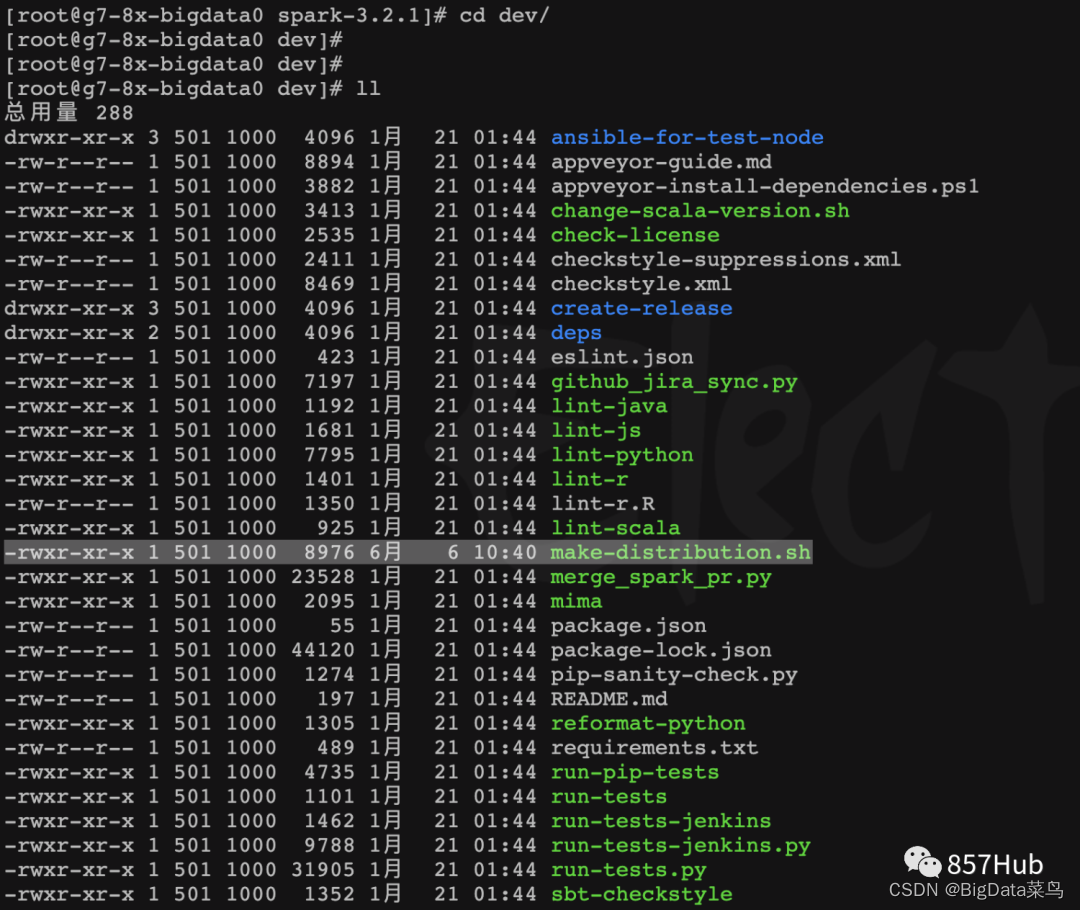
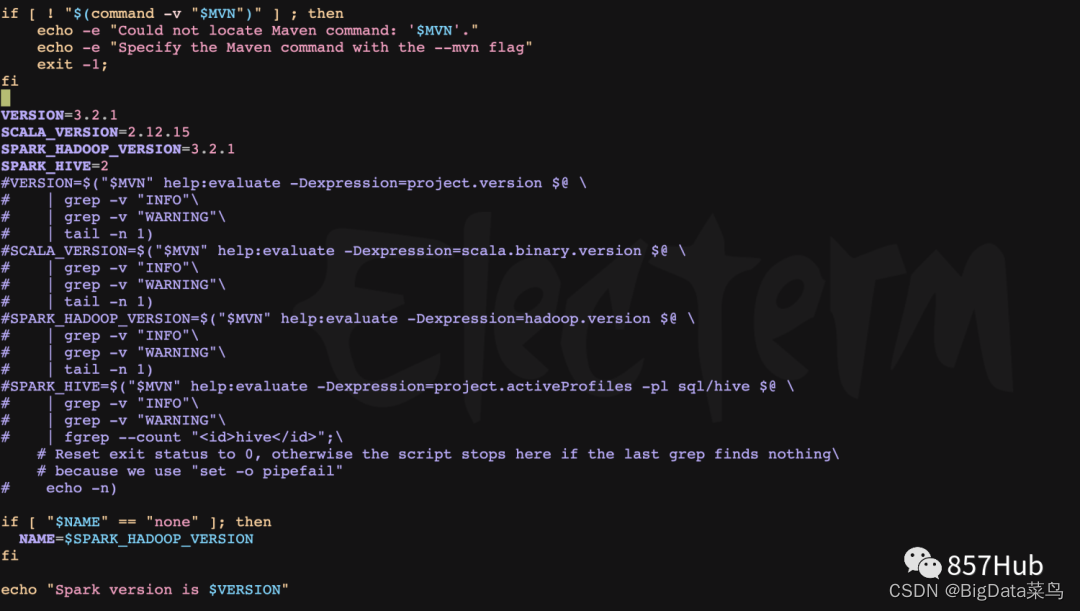
3、对文件 make-distribution.sh 进行配置
vim make-distribution.sh
将版本信息注释掉
自己指定,如下
4、指定scala版本
[root@g7-8x-bigdata0 dev] ./change-scala-version.sh 2.12
5、进行编译
[root@g7-8x-bigdata0 dev] ./dev/make-distribution.sh --name 3.2.1-hadoop3.2.1 --tgz -Phive -Phive-thriftserver -Pyarn -Dhadoop.version=3.2.1 -Dscala.version=2.12.15
注意:命令中对应兼容的hadoop和scala版本号一定要写对哇!
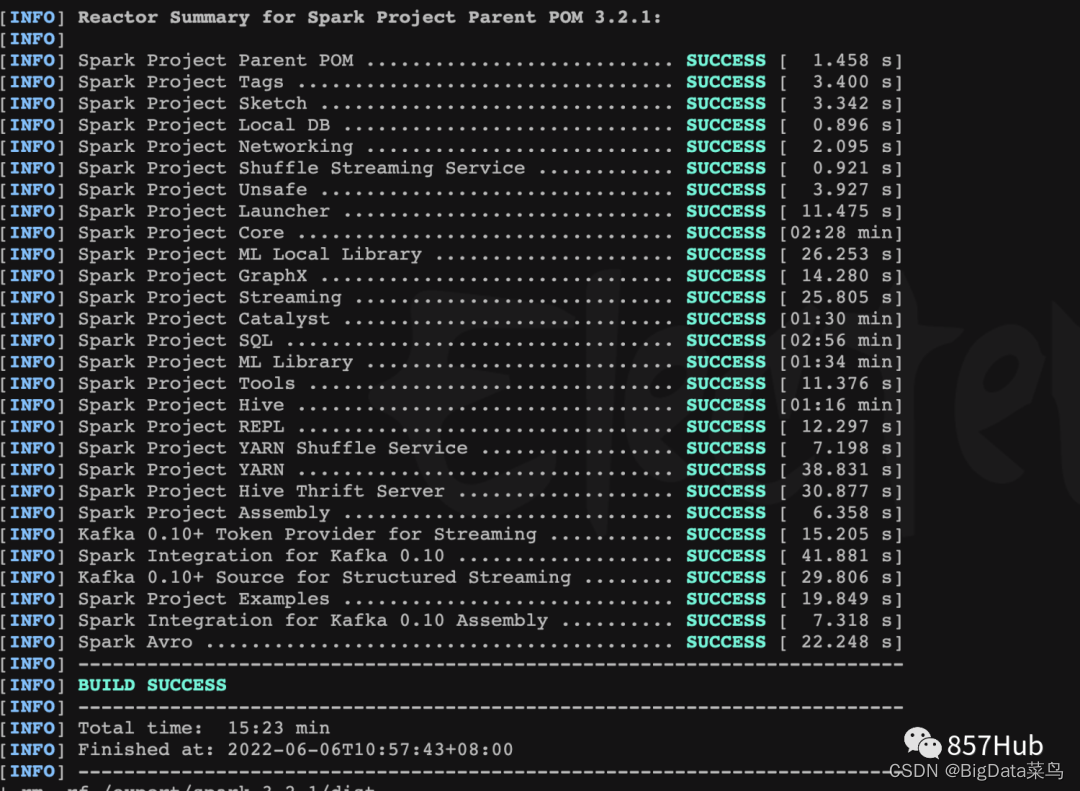
6、编译成功
出现success即可
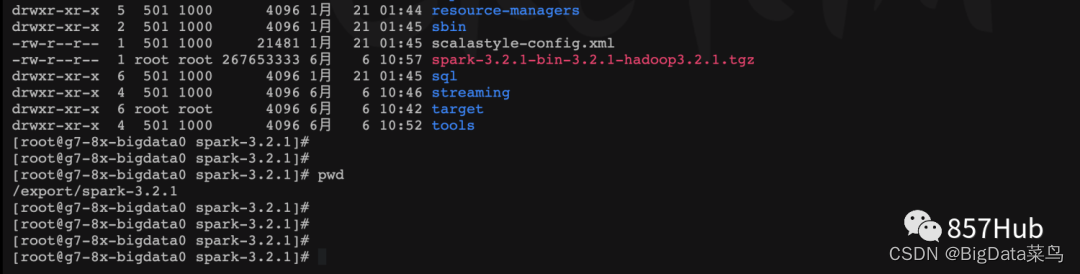
编译完以后进入到目录下可以看到编译好的jar包
7、编译遇到的问题
1)编译所需依赖包下载慢
exec: curl --silent --show-error -L https://downloads.lightbend.com/scala/。。。。
解决办法:
在linux 配置 maven,并且maven镜像要使用阿里云镜像,
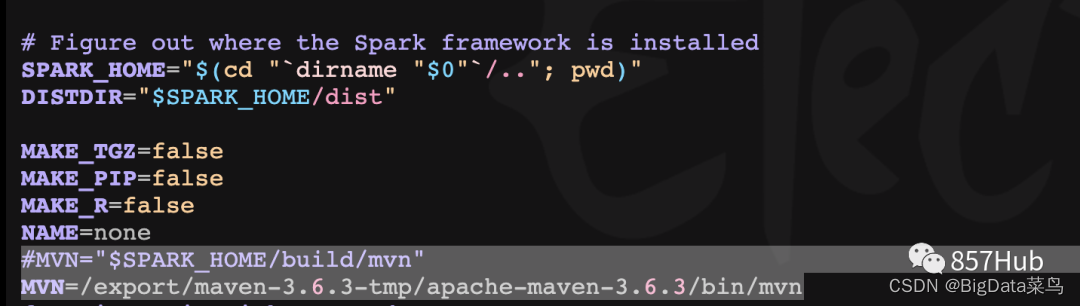
并在 spark家目录下dev下文件make-distribution.sh如下处
指定maven路径,如下:
2)编译时提示内存不足
Java HotSpot(TM) 64-Bit Server VM warning: CodeCache is full. Compiler has been disabled
解决办法:
指定的maven内存—调大
在配置的环境变量中加入:
export MAVEN_OPTS="-Xms1024m -Xmx1024m -Xss1m"
然后source /etc/profile !!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
欢迎各位大佬加入857大数据技术社区!!!!!!联系我即可!!!!
















 143
143











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











