







1.Redis简介
Redis的全程是Remote Dictionary Server(远程字典服务),是一个使用C语言编写的支持网络、可基于内存亦可持久化的日志型、NoSQL开源内存数据库。其提供多种语言的API。
Redis之所以称之为字典服务,是因为Redis是一个key-value存储系统。支持存储的value类型很多,包括String(字符串)、List(链表)、Set(集合)、Zset(sorted set-有序集合)和Hash(哈希类型)等。
特征:
- 键值(key-value)型,value支持多种不同数据结构,功能丰富
- 单线程,每个命令具备原子性(对网络部分支持多线程,其核心还是单线程)
- 低延迟,速度快(基于内存、IO多路复用、良好的编码)
- 支持数据持久化
- 支持主从集群、分片集群
- 支持多语言客户端
2.Redis的命令
1.通用命令
通用命令是部分数据类型的,都可以使用的命令,常见的有:
- keys:查看符合模板的所有key(后面可以跟上通配符,可以模糊查询),但是不建议在生产环境设备上使用,因为单线程,所以性能会降低
- del:删除指定的key,传入多个key即删除多个
- exists:判断key是否存在
- expire:给一个key设置有效期,有效期到期时该key会被自动删除
- ttl:查看一个key的剩余有效期(正常返回数据时就是表示多少秒,返回-1表示永久有效,返回-2表示该key不存在了)
2.String类型
String类型,也就是字符串类型,是Redis中最简单的存储类型。
其value是字符串,不过根据字符串的格式不同,又可以分为三类:
- string:普通字符串
- int:整数类型,可以做自增、自减操作
- float:浮点类型,可以做自增、自减操作
String类型常见的命令有:
- set:添加或者修改已存在的一个String类型的键值对
- get:根据key获取String类型的value
- mset:批量添加多个String类型的键值对
- mget:根据多个key获取多个String类型的value
- incr:让一个整型的key自增1
- incrby:让一个整型的key自增并指定步长,例如:incrby num 2(让num值自增2)
- incrbyfloat:让一个浮点类型的数字自增并指定步长
- setnx:添加一个String类型的键值对,前提是这个key不存在,否则不执行
- setex:添加一个String类型的键值对,并且指定有效期
3.Hash类型
Hash类型,也叫散列,其value是一个无序字典,类似于Java中的HashMap结构。
对比String类型:

如果需要对对象中的某个字段进行修改,则使用hashmap可以单独对某个值进行修改。
Hash类型的常见命令:
- hset key filed value:添加或者修改hash类型key的field的值
- hget key field:获取一个hash类型key的field的值
- hmset:批量添加多个hash类型key的field的值
- hmget:批量获取多个hash类型key的field的值
- hgetall:获取一个hash类型的key中所有的field和value
- hkeys:获取一个hash类型的key中的所有的field
- hvals:获取一个hash类型的key中所有的value
- hincrby:让一个hash类型key的字段值自增并指定步长
- hsetnx:添加一个hash类型的key的field值,前提是这个field不存在,否则不执行
4.List类型
redis中的List类型与Java中的LinkedList类似,可以看作是一个双向链表结构。既可以支持正向检索也可以支持反向检索。
特征也与LinkedList类似:
- 有序
- 元素可以重复
- 插入和删除快
- 查询速度一般
List类型的常见命令:
- lpush/rpush key element ...:向列表左/右侧插入一个或多个元素
- lpop/rpop key:移除并返回列表左/右侧的第一个元素,没有则返回nil
- lrange key star end:返回一段角标范围内的所有元素
- blpop/brpop:与lpop/rpop类似,只不过在没有元素时等待指定时间,而不是直接返回nil(b对应block,阻塞的)
5.Set类型
redis的Set结构与Java中的HashSet类似,可以看作是一个value为null的HashMap。因为也是一个hash表,因此具备与HashSet类似的特征:
- 无序
- 元素不可重复
- 查找快
- 支持交集、并集、差集等功能
Set类型的常见命令有:
- sadd key member ...:向set中添加一个或多个元素
- srem key member ...:移除set中的指定元素
- scard key:返回set中元素的个数
- sismember key member:判断一个元素是否存在于set中
- smembers:获取set中的所有元素
- sinter key1 key2 ...:求key1与key2的交集
- sdiff key1 key2 ...:求key1与key2的差集
- sunion key1 key2 ...:求key1和key2的并集
6.SortedSet
redis的SortedSet是一个可排序的set集合,与Java中的TreeSet有些类似,但底层数据结构却差别很大。SortedSet中的每一个元素都带有一个score属性,可以基于score属性对元素排序,底层的实现是一个跳表(SkipList)加Hash表。SortedSet具备下列特性:
- 可排序
- 元素不重复
- 查询速度快
因为SortedSet的可排序特性,经常被用来实现排行榜这样的功能。
SortedSet类型的常见命令:
- zadd key score member:添加一个或多个元素到sortedset,如果已存在则更新其score值
- zrem key member:删除sortedset中的一个指定元素
- zscore key member:获取sortedset中的指定元素的score值
- zrank key member:获取sortedset中指定元素的排名
- zcard key:获取sortedset中的元素个数
- zcount key min max:统计score值在给定范围内的所有元素的个数
- zincreby key increment member:让sortedset中的指定元素自增,步长为指定的increment值
- zrange key min max:按照score排序后,获取指定排名范围内的元素
- zrangebyscore key min max:按照score排序后,获取指定score范围内的元素
- zdiff、zinter、zunion:求差集、交集、并集
注意:所有的排名默认都是升序,如果要降序则在命令的z后面添加rev即可。
3.key的结构
redis的key允许有多个单词形成层级结构,多个单词之间用“:”隔开,格式如下:
项目名:业务名:类型:id
这个格式并非固定,也可以根据自己的需求来删除或添加词条。
4.Jedis的使用
1.引入依赖

2.建立连接

如果是springboot项目直接在springboot的配置文件中设置也可以
3.使用jedis

使用jedis的set和get方法即可完成redis的存和取数据。
4.释放资源

直接调用jedis的close方法即可。
5.Jedis的连接池
Jedis本身是线程不安全的,并且频繁的创建和销毁连接有性能损耗,因此我们推荐大家使用Jedis连接池代替Jedis的直连方式。代码如下:

6.SpringDataRedis
SpringDataRedis中提供了RedisTemplate工具类,其中封装了各种对Redis的操作。并且将不同数据类型的操作API封装到了不同的类型中。
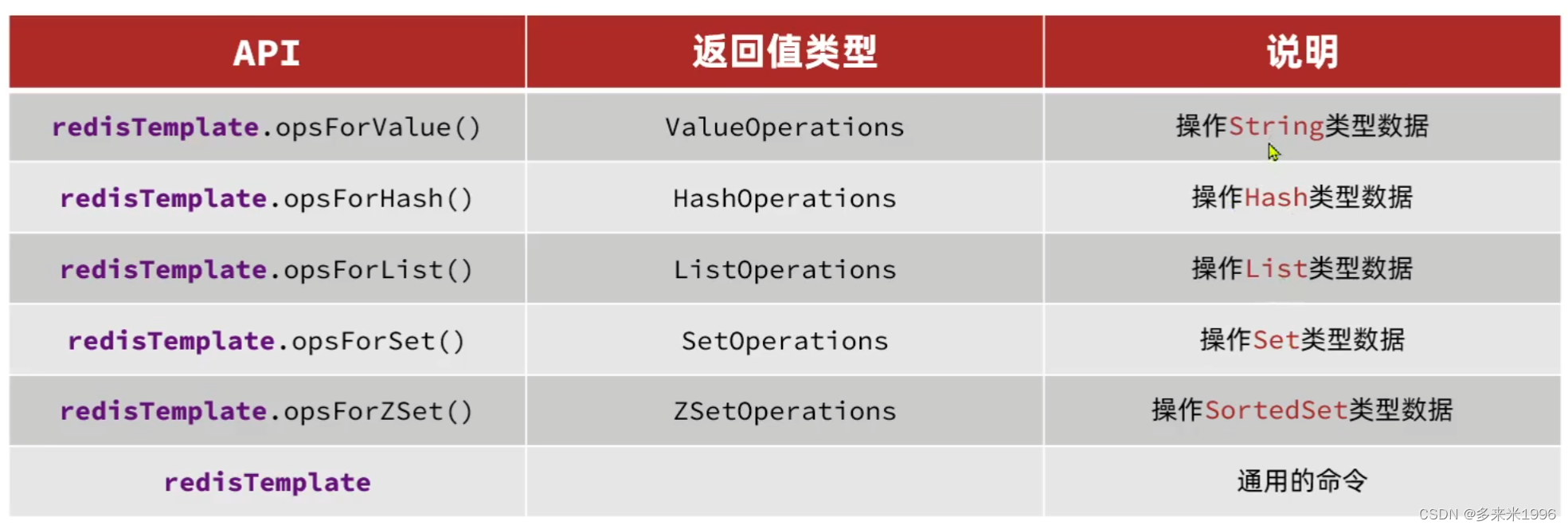
7.SpringBoot整合SpingDataRedis
1.引入依赖

这里需要引入redis的依赖和连接池的依赖。
2.配置文件
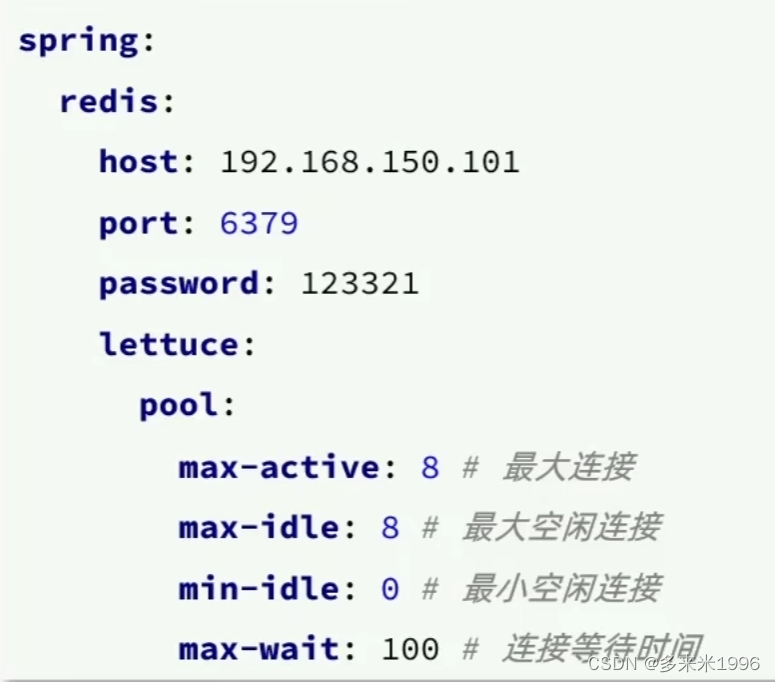
底层的默认的连接池使用的是lettuce的,如果想要使用jedis的,徐娅在pom文件中额外配置。
lettuce的连接池属性写上后,连接池才会生效。
3.注入RedisTemplate

4.使用

8.StringRedisTemplate的优化
为了在反序列化时知道对象的类型,JSON序列化器会将类的class类型json结果中,存入redis,会带来额外的内存开销。
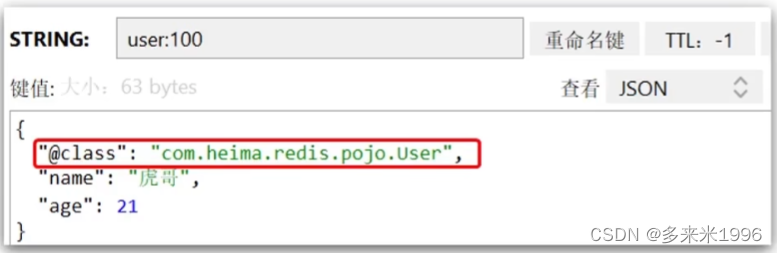
为了节省内存空间,我们并不会使用JSON序列化器来处理value,而是统一使用String序列化器,要求只能存储String类型的key和value。当需要存储Java对象时,手动完成对象的序列化和反序列化。
Spring提供了一个StringRedisTemplate类,它的key和value的序列化方式默认就是String方式。省去了我们自定义RedisTemplate的过程。
9.缓存穿透
缓存穿透是指客户端请求的数据在缓存中和数据库中都不存在,这样缓存永远不会生效,这些请求都会打到数据库。
常见的解决方案有两种:
- 缓存空对象
- 优点:实现简单,维护方便
- 缺点:
- 额外的内存消耗
- 可能造成短期的不一致
- 布隆过滤
- 优点:内存占用较少,没有多余key
- 缺点:
- 实现复杂
- 存在误判可能
10.缓存雪崩
缓存雪崩是指在同一时段大量的缓存key同时失效或者redis服务宕机,导致大量请求到达数据库,带来巨大压力。
解决方案:
- 给不同的ket的ttl添加随机值
- 利用redis集群提高服务的可用性
- 给缓存业务添加降级限流策略
- 给业务添加多级缓存
11.缓存击穿
缓存击穿问题也叫热点key问题,就是一个高并发访问并且缓存重建业务较复杂的key突然失效了,无数的请求访问会在瞬间给数据库带来巨大的冲击。
常见的解决方案有两种:
- 互斥锁
- 优点:
- 没有额外消耗
- 保证一致性
- 实现简单
- 缺点:
- 线程需要等待,性能受影响
- 可能有死锁风险
- 优点:
- 逻辑过期
- 优点:线程无需等待,性能较好
- 缺点:
- 不保证一致性
- 有额外内存消耗
- 实现复杂
12.封装Redis工具类
1.设置真实过期时间和设置逻辑过期时间(解决缓存击穿)

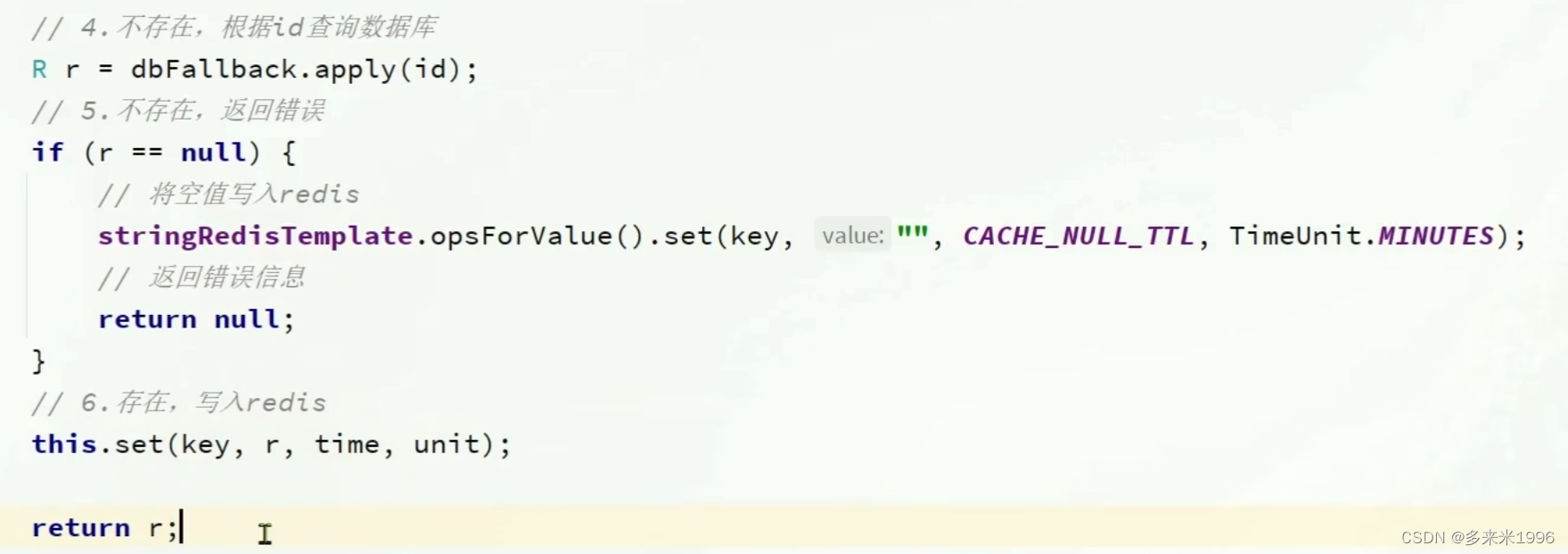
2.解决缓存穿透(保存空字符串)
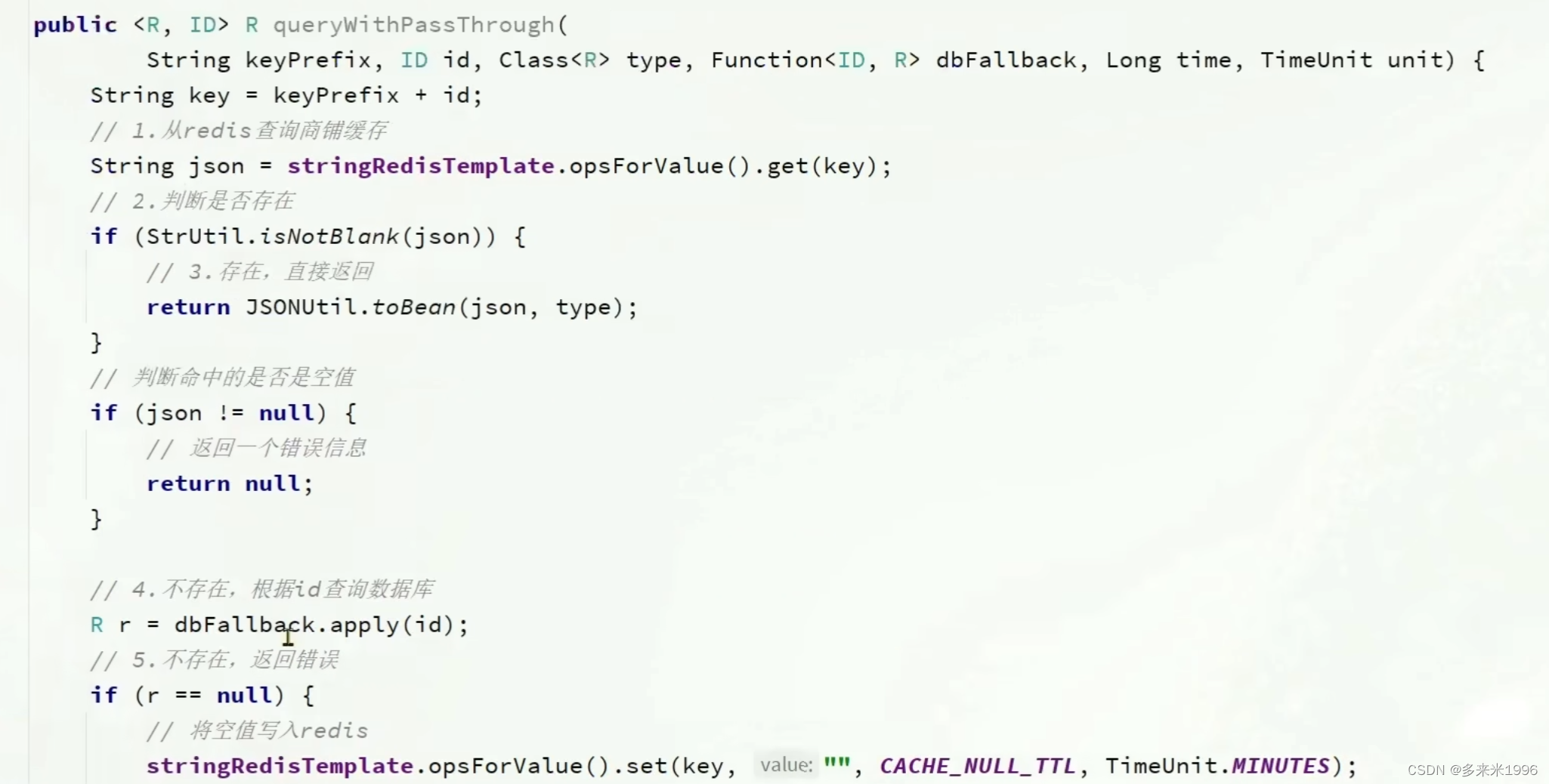















 383
383











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









