







一.基本概念
1.非对称的二元变量:通常认为项在事务中出现比不出现重要
2.支持度计数:包含某个项集的事务的个数
3.支持度和置信度:
支持度:
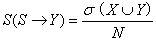
置信度:
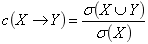
二.问题定义
1.支持度和置信度的作用与区别:
支持度往往反映了关联规则在总事务中出现的频繁程度,因此支持度过低的规则往往作用不大,因为只是偶然出现。
置信度反映的是对于关联规则X->Y,若置信度越高,则Y在包含X的事务中出现的概率越大。
2.关联规则的发现:
找出支持度大于minsup和置信度大于minconf的规则。
所以,关联规则的发现一般分为两个任务:
- 1)找出满足最小支持度阈值的项集,即频繁项集。
- 2)在找出的频繁项集中,提取置信度高的规则,即强规则。
这两个任务都会产生很大的开销,其中任务1)的开销会远大于任务2),对于这两个任务我们都会采取相应的方法减少开销。
**关联分析的大纲就是关于如何执行这两个任务,并尽可能减少两个任务开销而展开的:
其中,任务1)(选出频繁项集)的过程:
Apriori算法:
- 选出候选项集(涉及产生候选项集,剪枝来减少计算开销)
- 从候选项集中选出频繁项集(涉及支持度计数的方法来减少开销)
FP增长算法:
- FP树的产生
- 从FP树中选出频繁项集
任务2)(规则产生)的过程:
Apriori算法规则的产生
参考书籍:数据挖掘导论















 442
442











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









