







系列文章目录
【Datawhale Ai 夏令营】用户新增预测挑战赛baseline
文章目录
前言
在上一篇文章中分享了baseline,这这篇文章中将会基于模型选择,特征工程方面来改进baseline。
一、模型选择
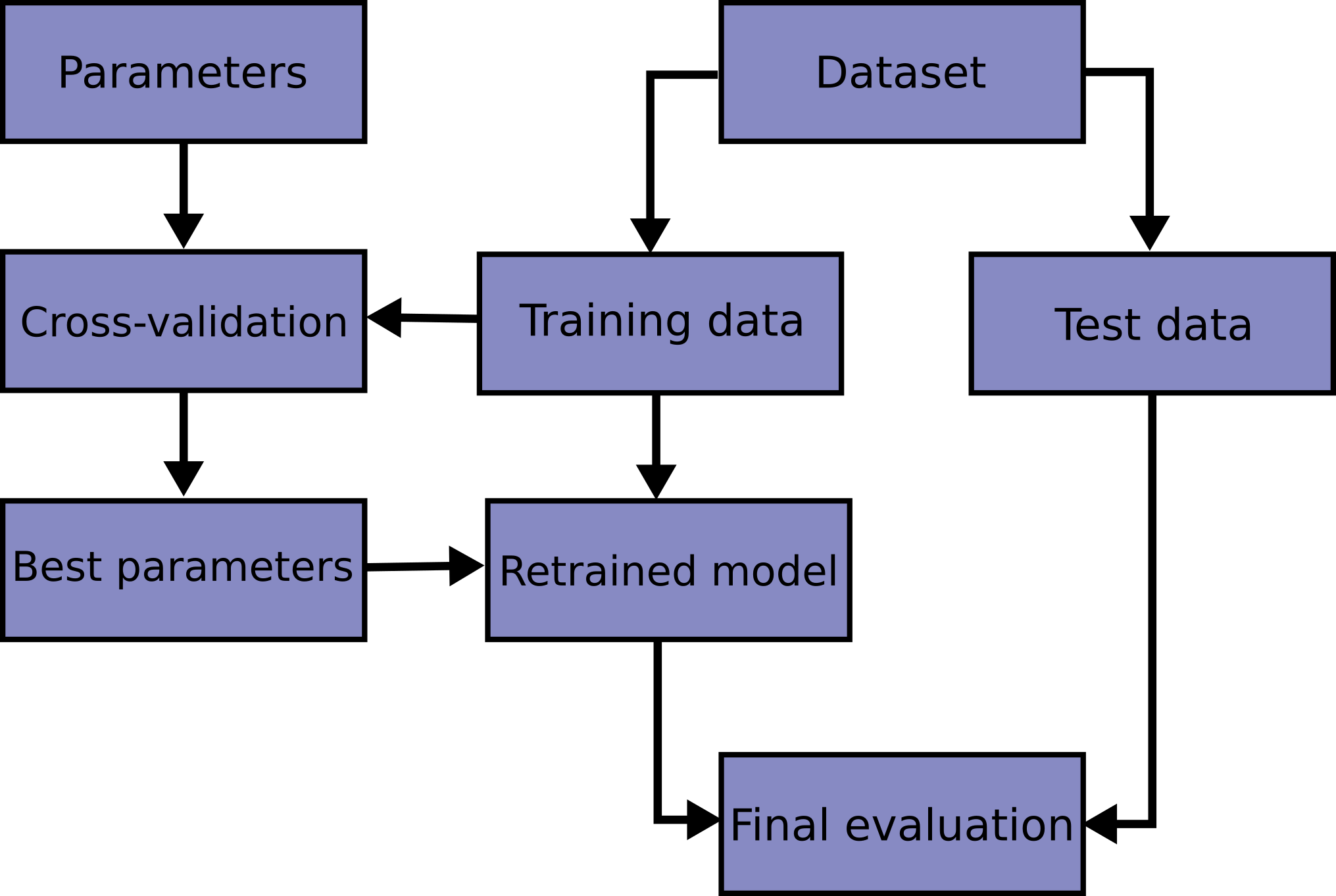
使用交叉验证来评估模型,下图是模型训练中典型交叉验证工作流程的流程图。
1.SGDClassifier
该分类器通过随机梯度下降(SGD)学习实现正则化线性模型:每次估计每个样本的损失梯度,并随着学习率的递减而更新模型。SGD 允许通过该方法进行小批量(在线/核外)学习partial_fit。为了使默认学习率能获得最佳结果,数据应具有零均值和单位方差。
此实现适用于表示为特征的密集或稀疏浮点值数组的数据。其拟合的模型可以通过损失参数来控制;默认情况下,它适合线性支持向量机 (SVM)。
# 训练并验证SGDClassifier
pred = cross_val_predict(
SGDClassifier(max_iter=10),
train_data.drop(['udmap', 'common_ts', 'uuid', 'target'], axis=1),
train_data['target']
)
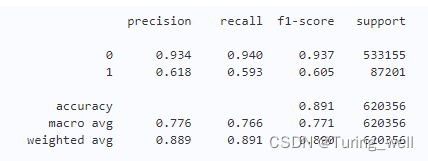
print(classification_report(train_data['target'], pred, digits=3))
结果如下

2.DecisionTreeClassifier
决策树是一种用于分类和回归的非参数监督学习方法。目标是创建一个模型,通过学习从数据特征推断出的简单决策规则来预测目标变量的值。树可以看作是分段常数近似。
决策树的一些优点是:
- 易于理解和解释。树可以被形象化。
- 需要很少的数据准备。其他技术通常需要数据标准化、创建虚拟变量并删除空白值。但请注意,该模块不支持缺失值。
- 使用树(即预测数据)的成本是用于训练树的数据点数量的对数。
- 能够处理数值数据和分类数据。但是,scikit-learn 实现目前不支持分类变量。其他技术通常专门用于分析仅具有一种变量类型的数据集。
- 能够处理多输出问题。
- 使用白盒模型。如果给定的情况在模型中是可观察到的,则该条件的解释很容易通过布尔逻辑来解释。相比之下,在黑盒模型中(例如,在人工神经网络中),结果可能更难以解释。
- 可以使用统计测试来验证模型。这使得可以解释模型的可靠性。
- 即使生成数据的真实模型在某种程度上违反了其假设,也表现良好。
决策树的缺点包括:
- 决策树学习者可以创建过于复杂的树,而这些树不能很好地概括数据。这称为过度拟合。为了避免这个问题,需要采用剪枝、设置叶节点所需的最小样本数或设置树的最大深度等机制。
- 决策树可能不稳定,因为数据的微小变化可能会导致生成完全不同的树。
- 决策树的预测既不是平滑的也不是连续的,而是分段常数近似。因此,他们不擅长推断。
- 已知学习最优决策树的问题在最优性的几个方面甚至对于简单的概念来说都是 NP 完全的。因此,实用的决策树学习算法基于启发式算法,例如贪婪算法,其中在每个节点做出局部最优决策。此类算法不能保证返回全局最优决策树。这可以通过在集成学习器中训练多个树来缓解,其中特征和样本是通过替换随机采样的。
- 有些概念很难学习,因为决策树不容易表达它们,例如异或、奇偶校验或多路复用器问题。
- 如果某些类占主导地位,决策树学习器会创建有偏差的树。因此,建议在拟合决策树之前平衡数据集。
# 训练并验证DecisionTreeClassifier
pred = cross_val_predict(
DecisionTreeClassifier(),
train_data.drop(['udmap', 'common_ts', 'uuid', 'target'], axis=1),
train_data['target']
)
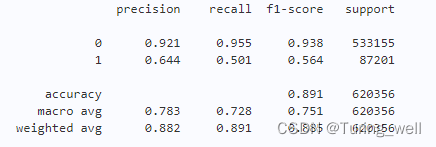
print(classification_report(train_data['target'], pred, digits=3))
结果如下
3.MultinomialNB
用于多项模型的朴素贝叶斯分类器。
多项式朴素贝叶斯分类器适用于具有离散特征的分类(例如,用于文本分类的字数统计)。多项分布通常需要整数特征计数。然而,在实践中,诸如 tf-idf 之类的分数计数也可能有效。
# 训练并验证MultinomialNB
pred = cross_val_predict(
MultinomialNB(),
train_data.drop(['udmap', 'common_ts', 'uuid', 'target'], axis=1),
train_data['target']
)
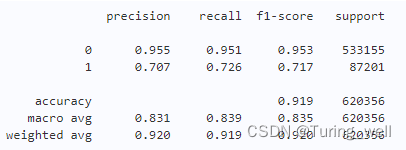
print(classification_report(train_data['target'], pred, digits=3))
结果如下

4.RandomForestClassifier
随机森林是一种元估计器,它在数据集的各个子样本上拟合多个决策树分类器,并使用平均来提高预测准确性并控制过度拟合。子样本大小由max_samples参数 if bootstrap=True(默认)控制,否则使用整个数据集来构建每棵树。
# 训练并验证RandomForestClassifier
pred = cross_val_predict(
RandomForestClassifier(n_estimators=5),
train_data.drop(['udmap', 'common_ts', 'uuid', 'target'], axis=1),
train_data['target']
)
print(classification_report(train_data['target'], pred, digits=3))
结果如下
二、特征工程
- common_ts_day 特征:从时间戳 common_ts 中提取出日期部分的天数,以创建一个新的特征表示访问日期。
- x1_freq 和 x1_mean 特征:计算特征 x1 在训练集中的频次(出现次数)以及在训练集中对应的目标列 target 的均值。这些特征可以捕捉 x1 特征的重要性和与目标的关系。
- 类似地,对于其他 x2、x3、x4、x6、x7 和 x8 特征,进行了类似的操作,分别计算它们在训练集中的频次和均值。
train_data['common_ts_day'] = train_data['common_ts'].dt.day
test_data['common_ts_day'] = test_data['common_ts'].dt.day
train_data['x1_freq'] = train_data['x1'].map(train_data['x1'].value_counts())
test_data['x1_freq'] = test_data['x1'].map(train_data['x1'].value_counts())
train_data['x1_mean'] = train_data['x1'].map(train_data.groupby('x1')['target'].mean())
test_data['x1_mean'] = test_data['x1'].map(train_data.groupby('x1')['target'].mean())
train_data['x2_freq'] = train_data['x2'].map(train_data['x2'].value_counts())
test_data['x2_freq'] = test_data['x2'].map(train_data['x2'].value_counts())
train_data['x2_mean'] = train_data['x2'].map(train_data.groupby('x2')['target'].mean())
test_data['x2_mean'] = test_data['x2'].map(train_data.groupby('x2')['target'].mean())
train_data['x3_freq'] = train_data['x3'].map(train_data['x3'].value_counts())
test_data['x3_freq'] = test_data['x3'].map(train_data['x3'].value_counts())
train_data['x3_mean'] = train_data['x3'].map(train_data.groupby('x3')['target'].mean())
test_data['x3_mean'] = test_data['x3'].map(train_data.groupby('x3')['target'].mean())
train_data['x4_freq'] = train_data['x4'].map(train_data['x4'].value_counts())
test_data['x4_freq'] = test_data['x4'].map(train_data['x4'].value_counts())
train_data['x4_mean'] = train_data['x4'].map(train_data.groupby('x4')['target'].mean())
test_data['x4_mean'] = test_data['x4'].map(train_data.groupby('x4')['target'].mean())
train_data['x6_freq'] = train_data['x6'].map(train_data['x6'].value_counts())
test_data['x6_freq'] = test_data['x6'].map(train_data['x6'].value_counts())
train_data['x6_mean'] = train_data['x6'].map(train_data.groupby('x6')['target'].mean())
test_data['x6_mean'] = test_data['x6'].map(train_data.groupby('x6')['target'].mean())
train_data['x7_freq'] = train_data['x7'].map(train_data['x7'].value_counts())
test_data['x7_freq'] = test_data['x7'].map(train_data['x7'].value_counts())
train_data['x7_mean'] = train_data['x7'].map(train_data.groupby('x7')['target'].mean())
test_data['x7_mean'] = test_data['x7'].map(train_data.groupby('x7')['target'].mean())
train_data['x8_freq'] = train_data['x8'].map(train_data['x8'].value_counts())
test_data['x8_freq'] = test_data['x8'].map(train_data['x8'].value_counts())
train_data['x8_mean'] = train_data['x8'].map(train_data.groupby('x8')['target'].mean())
test_data['x8_mean'] = test_data['x8'].map(train_data.groupby('x8')['target'].mean())
增加特征后个分类器交叉验证分数如下
SGDClassifier :

DecisionTreeClassifier :
MultinomialNB :
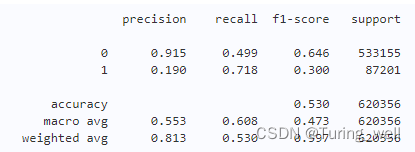
RandomForestClassifier :

总结
本文在上次baseline的基础上,通过修改分类器,增加特征工程,对模型进行改进















 68
68











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









