







实体作为条件构造器构造方法的参数
- 修改实体加condition:别的地方如果想用等于也是可以的,就是写法要不一样。在实体中加的这个condition。只是实体作为条件构造器的构造函数的参数的时候才会生效,其他地方你可以把name等于直接用条件构造器构造,通过构造函数创建条件构造器时不传实体。
- 多表联查,使用自定义的sql语句即可,sql后面可以加
${ew.customSqlSegment}这样就可以使用条件构造器,
例如sql语句为:select u.* from user u inner join role r on u.role_id = r.role_id ${ew.customSqlSegment}
//条件构造器wrapper中的条件记得加表别名,例如wrapper.eq("u.name","王明");这样就能进行过滤了
-
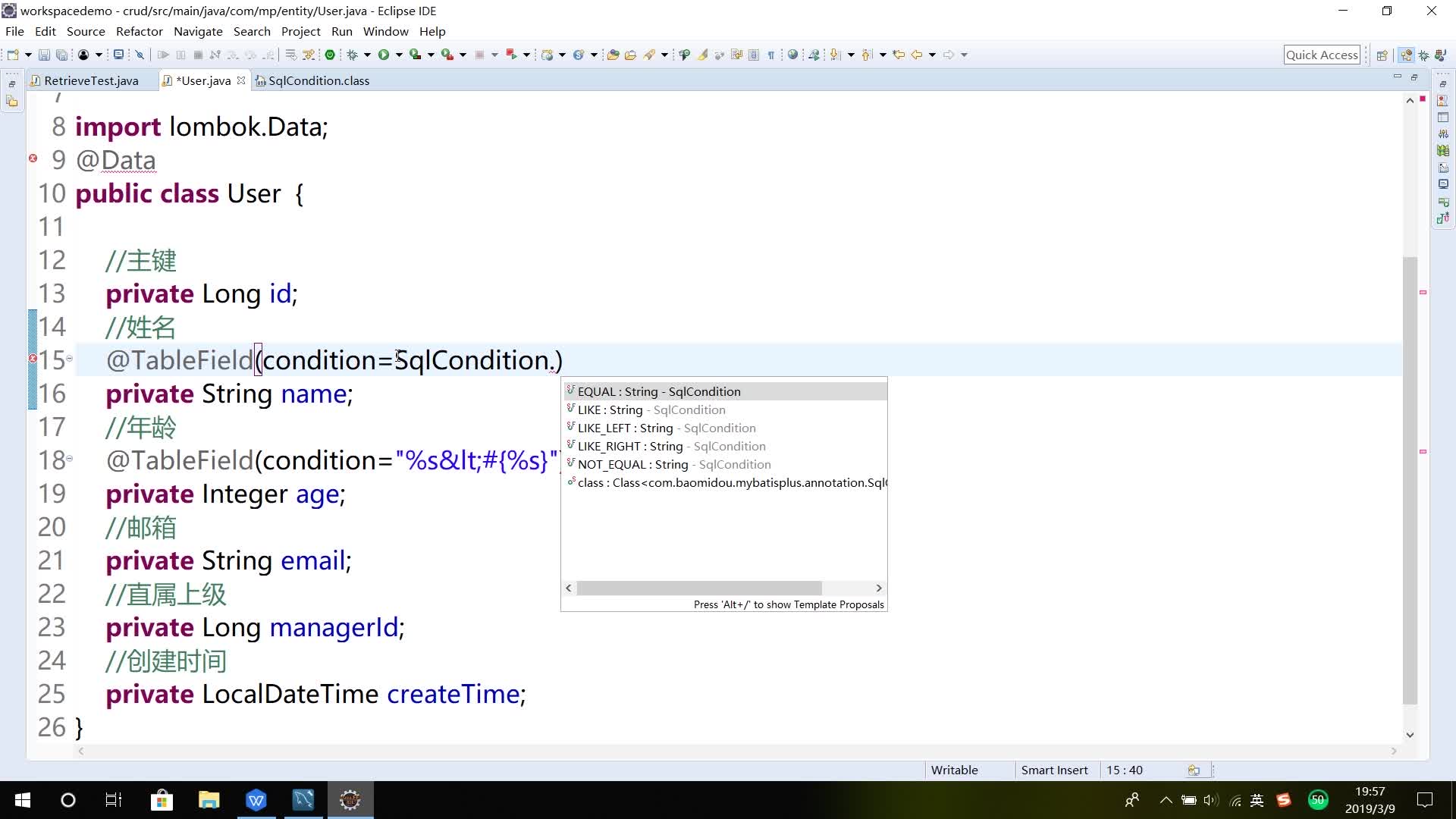
实体中的属属性加注解中的condition属性
-
条件构造器使用allEq
//以前我也没用过lambdaQuery调用带过滤参数的allEq,不带过滤参数的那种挺优雅的。类似上面的需求,我做了一种折中实
//现方式,不太优雅。给你列出代码看看,有时间我再研究研究,如果有答案,我会答复你。
User user = new User();
user.setAge(25);
user.setRealName("王");
Map<SFunction<User, ?>, Object> params = new HashMap<>();
//防误写
params.put(User::getRealName, user.getRealName());
params.put(User::getAge, user.getAge());
List<User> userList = userMapper.selectList(Wrappers.<User>lambdaQuery().allEq(true,
(k, v) -> k.apply(user).equals(user.getRealName()), params, true));
-
忽略如果键为name时的查询参数
@Test public void selectByWrapperAllEq(){ QueryWrapper<User> queryWrapper=new QueryWrapper<User>(); Map<String,Object> params =new HashMap<String,Object>(); params.put("name","王天风"); params.put("age",null); //allEq第二个参数设定false,值为null的忽略掉 //queryWrapper.allEq(params,false); queryWrapper.allEql(k,v)->!k.equals("name").paramst:List<User> userList=userMapper.selectList(queryWrapper); userList.forEach(System.out:println); }
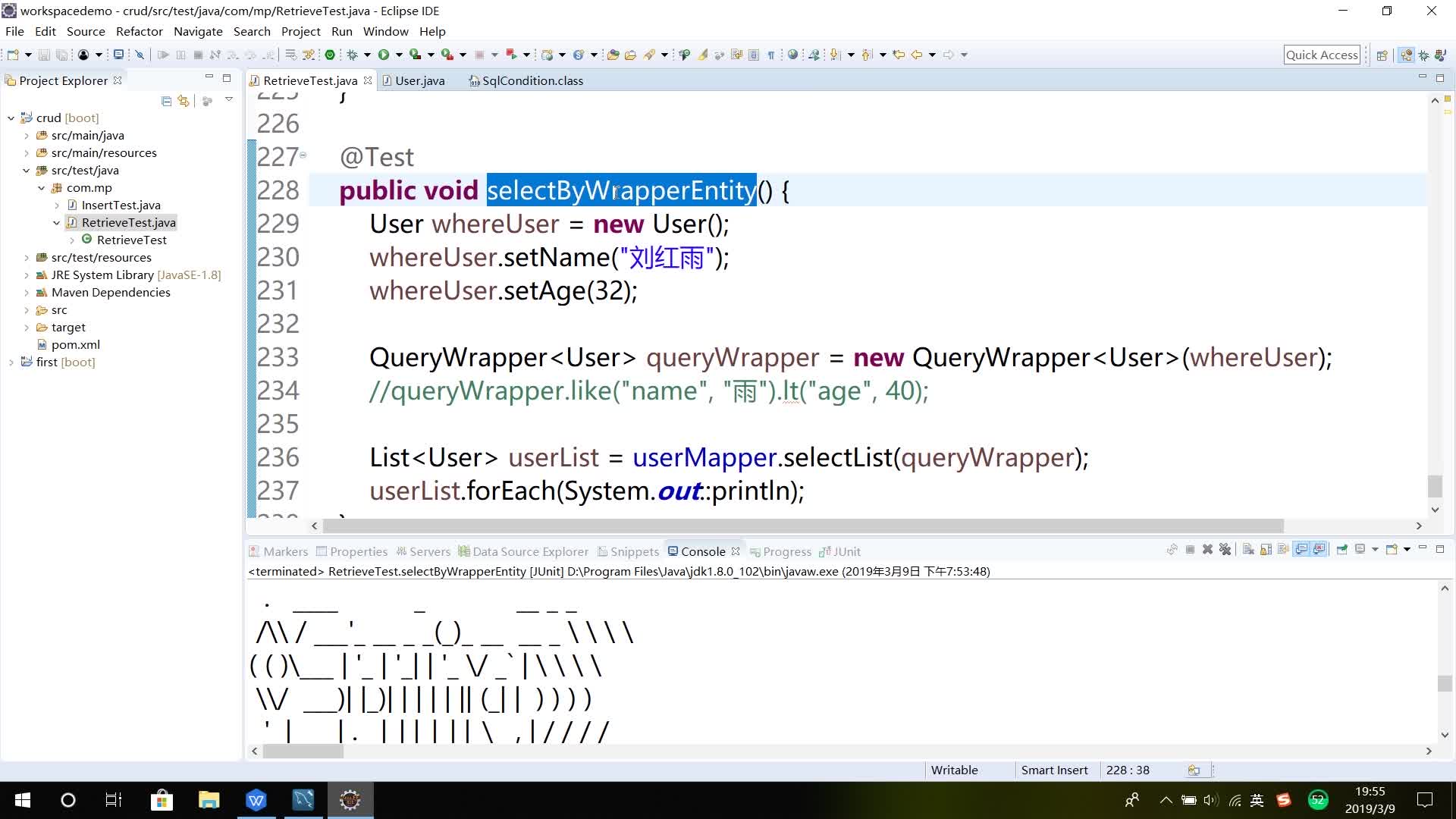
其他使用条件构造器的方法,比如selectMaps()
-
为什么实体类的字段类型采用包装器类的类型:
基本数据类型如int、long作为成员变量,如果没有赋初始值,那么默认是0。而包装类作为成员变量,没有赋初始值的话,默认为null。如果你使用基本类型,某个对象的某些基本数据类型成员变量没有设置值,你用insert方法插入,给你插入了0,可能跟你要的预期效果不一样,导致业务逻辑错误。
-
selectOne只能查返回数据中仅一条的
-
selectCount的用法返回记录数
//按照直属上级分组,查询每组的平均年龄、最大年龄、最小年龄。并且
//只取年龄总和小于500的组
//select avg(age) avg_age,min(age) min_age,max(age) max_age from user group by manager_id having //sum(age) < 500
queryWrapper.select("avg(age) avg_age","min(age) min_age","max(age) max_age")groupBy("manager_id").having("sum(age)<{0}",500);
List<Map<String,Object>> userList = userMapper.selectMaps(queryWrapper);
lambda条件构造器
- 使用lambda如何只查询某几个字段
LambdaQueryWrapper<User> lambdaQuery = Wrappers.<User>lambdaQuery();
lambdaQuery.select(User::getId,User::getUsername);
- MP自带的CRUD操作是针对单表操作的,如果要操作多表,可以写自定义sql。
- 条件构造器的多表sql例子,可以写在xml中或注解中,下面的是用xml的写法:
<select id="mySelectList" resultType="User">
select u.*,r.role_name from user u inner join role r on u.role_id = r.role_id ${ew.customSqlSegment}
</select>
对应的Mapper接口中的方法定义:
List<User> mySelectList(@Param(Constants.WRAPPER) Wrapper<User> wrapper);
返回值可以是VO。也可以是实体类,但要要记住,如果用实体类接返回值,实体中非该实体对应表的数据库字段的 属性上要标注@TableField(exist = false),如果使用了条件构造器,条件构造器的字段名别忘了带别名。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gbteH5R7-1586744164677)(image\image-20200210172305074.png)]
自定义sql
-
自定义SQL的两种方式:
第一种: 使用自定义注解 的方式实现,在 dao 层的方法上使用@Select (“sql 语句”)的方式编写 sql 语句,会自动映射到数据库表中
第二章: 使用创建 mapper.xml 的方式来创建 配置文件,通过在配置文件中 创建 sql 语句,并配置 namespace 名称空间,指向有效的 dao 层,从而实现数据的映射
-
通用Mapper](https://img2.mukewang.com/5d6d40210001685619201080.jpg)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-KRYtrr7W-1586744164680)(image\image-20200210184030582.png)]
上图是把sql写进.xml文件的application.xml文件的配置
分页查询
-
springboot中推荐用配置类这种配置方式,就跟原来spring使用xml配置bean是一个效果。还有PaginationInterceptor本质上是mybatis过滤器
@Configuration @MapperScan("edu.zsc.greenhouse.mapper") public class MybatisPlusConfig { /** * 分页插件 */ @Bean public PaginationInterceptor paginationInterceptor() { return new PaginationInterceptor(); } } -
配置类放在configuration文件夹中,启动类启动时,@SpringBootApplication中的@ComponentScan会默认扫
启动类同级包及子包,因此就可以扫到@Configurtion注解的类MybatisPlusConfig
-
使用mp的分页插件实现分页,如果是单表查询,并且不是自定义的sql,用mp提供的方法,是不用写sql的,直接用就可以了。实现分页的话,一般是需要发出两条sql语句的,一条查询符合当前条件的总记录数,一条查询当前页的记录(List类型的),如果不用分页插件,你要写两条sql的。而且不同数据库的分页语法是不一样的,有的数据库的分页语法比较麻烦,例如oracle。 所以一般情况下,还是用mp的分页插件比较方便。
-
,你在idea中看到的源码其实是class文件反编译后得到的,class文件中不能保存注释信息。 你可以点击你那张截图界面右上角的Download Sources下载源码。或者在Project视窗选择项目,右键->Maven->Download Sources下载所有依赖的源码。
-
springboot启动类的机制,配置类和组件类默认需要在启动类所在包或其子包下才能扫描到,当然你也可以通过注解@ComponentScans或者@ComponentScan指定扫描的包。
-
通过自定义方法可以实现多表情况下还使用条件构造器,我举个使用注解的例子,sql写在xml中也可以。
@Select(“select a.,b. from table1 a inner join table2 b on a.id = b.id ${ew.customSqlSegment}”)
List getAll(@Param(Constants.WRAPPER) Wrapper wrapper);
要注意,条件构造器中的条件名参数需要加表名或表别名,要不容易出错。例如 wrapper.eq(“a.name”,“张良”) -
查询总记录数:
在new Page<>()的第三个参数,如果不查总记录数,第三个参数为false
类似今日头条那种下拉 不需要总条数量做分页展示
-
如果有不全或者写错的地方,请指正谅解,谢谢
分页查询步骤:
1:创建并完善配置类MybatisPlusConfig.java
2.实例化Page对象
2.1: Page对象构造函数参数:1:当前页
2:一页的数量3.分页总数
4:是否需要查询总条数(false:不查,true:查,少发出一条sql) 3.1 使用selectPage 或 selectMapsPage(区别:前者封装进实体类中,后者封装进Map对象中) 3.2 如果为多表查询,则需要进行自定义方法,此时需要配置UserMapper接口文件,返回值为IPage类型注:切记不可返回Page类型,否者代码运行无报错,也能看到sql查询,但是在获取getRecords时无数据
3.2.1 IPage selectAllByPage(Page page, @Param(Constants.WRAPPER) Wrapper wrapper);3.2.2 配置@select注解 或者 配置xml文件
@select注解附:@Select("select * from User ${ew.customSqlSegment}")xml配置附:
``select * from User ${ew.customSqlSegment}4.传入参数Page对象和QueryWrapper对象
4.1: 使用getTotal获取总条数4.2: 使用getPages获取总页数
更新方法
-
${ew.customSqlSegment} 不是必须写的。当你自定义方法还想用条件构造器的时候,才需要这样写。可以使用mybatis原生的方式。
-
UpdateWrapper<User> updateWrapper = new UpdateWrapper<User>(); updateWrapper.eq("name","李艺伟").eq("age",29).set("age",30); int rows = userMapper.update(null,updateWrapper);
AR模式
- AR模式是一种操作数据的设计模式
- 一是实体需要继承Model类,二是必须存在对应的原始mapper并继承baseMapper并且可以使用的前提下,才能使用此 AR 模式。
- AR模式。 1、实体类继承model 2、AR模式下的CRUD。直接用实体对象调用CRUD方法就好。回去可以做一哈测试。
- 操作数据库既可以通过mapper来操作也可以使实体类继承model类来操作(AR模式)
主键策略
-
有的项目由于适用场景或其他的原因,不采取依赖数据库的自增主键,就得采取其他主键策略,这时MP给你提供的多种主键策略就可能派上用场了。
-
Mysql支持主键自增,主键自增是依赖于数据库的机制,所以数据库中也要进行设置。有些数据库没有自增的主键,例如oracle,如果要实现主键自增依赖于sequence序列。
雪花算法是MP默认的主键策略,是通过Java程序生成的自增主键,不依赖于数据库。如果想使用数据库的自增,除了在MP中将主键策略设为自增,还要在数据库中进行设置。
-
非主键可以是使用雪花算法自动填充吗?有个办法,使用MP的自动填充功能,你要填充的实体类属性上增加@TableField注解,注解中fill属性,设置填充的类型。然后在自己重写的继承MetaObjectHandler的类中,编写字段填充逻辑。在自动填充逻辑中,就可以调用雪花算法的类生成数字串的方法,然后填充进你要填充的字段。自动填充功能可以参考官方文档,地址:https://mybatis.plus/guide/auto-fill-metainfo.html
-
Mybatis - Plus 的 主键策略:
◆MP支持的主键策略介绍
◆局部主键策略实现
◆全局主键策略实现 -
mysql的主键策略。 全局的。在yml. 配置属性:globle.config:db. config:type-id:值 局部的。直接在实体类的id上注解@tableid. (值)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-UWeruJh4-1586744164681)(image\image-20200211180749253.png)]
- 主键策略 常用 雪花算法ID UUID
通用Service
- 同学你好,这个问题可能没有标准答案,我说说我的看法,使用MP,你的service可以继承mp的通用service。在通用service中已经把操作本实体的mapper给你注入进来了。你可以在service中实现一个根据年龄查询用户的方法。如果其他service要用,有一种方式是把这个service注入到另一个service中,直接调用,但这种使用方式有争议,有的单位不让这么干,因为同层依赖了。
方式二,你这个查询可以写在Mapper中,就是原生的Mybatis怎么写,你就怎么写,然后哪个service使用,就把这个Mapper注入到哪个service中。
方式三,你的这个需求很简单,一句就能解决,我感觉多次编写也无伤大雅,可以重复编写。
-
如果你整合springboot,数据库的连接是连接池给你维护的。分层的目的是为了逻辑清晰,易于扩展和维护。单表查询可以在业务层继承mp的通用service。它自己注入了dao层的mapper接口。两张表连接确实只能自己写sql。
-
Service批量处理
么写,你就怎么写,然后哪个service使用,就把这个Mapper注入到哪个service中。
方式三,你的这个需求很简单,一句就能解决,我感觉多次编写也无伤大雅,可以重复编写。
-
如果你整合springboot,数据库的连接是连接池给你维护的。分层的目的是为了逻辑清晰,易于扩展和维护。单表查询可以在业务层继承mp的通用service。它自己注入了dao层的mapper接口。两张表连接确实只能自己写sql。
-
Service批量处理
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-zv4v6wej-1586744164684)(image\image-20200211201040014.png)]














 1680
1680











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}
{kind=link}