







 本文介绍了如何使用Python的pandas和openpyxl库读取Excel文件中的特定列数据,包括按列读取和数据格式转换,以及处理可能出现的警告。
本文介绍了如何使用Python的pandas和openpyxl库读取Excel文件中的特定列数据,包括按列读取和数据格式转换,以及处理可能出现的警告。
最近在处理项目时,遇到了一个问题,需要读出一个Excel中的某几列有效数据然后进行后续处理,
表格数据举例如下:
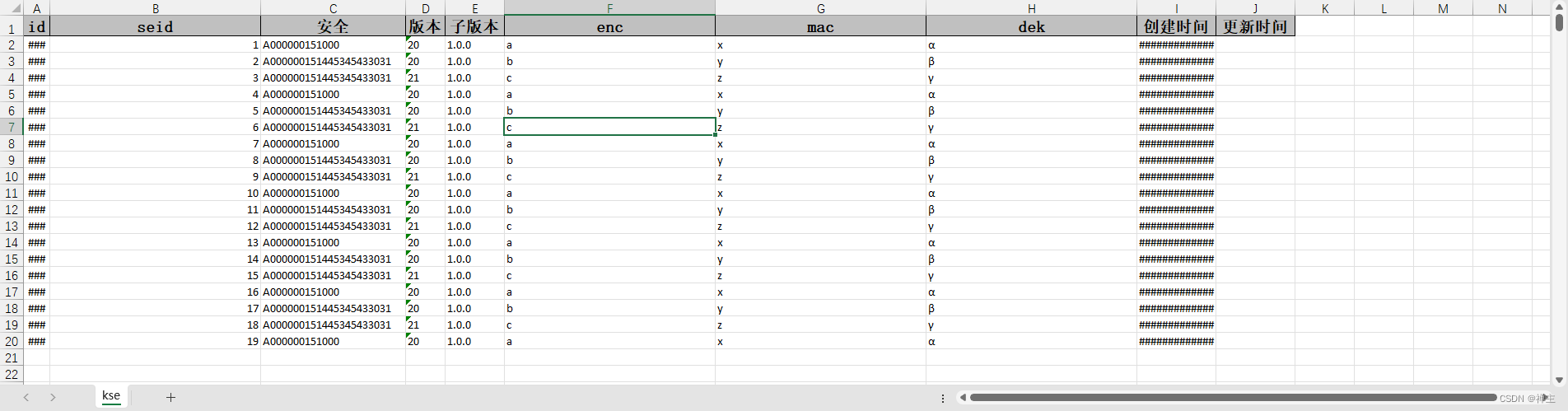
以下代码运行环境:
Windows 11 Pro x64
Python 3.9.12
pandas 1.4.2
openpyxl 3.0.10
给出代码如下:
import pandas as pd
file_path = 'path/to/your/a.xlsx' # 请将文件路径替换为你的 Excel 文件路径
# 这里以 B F G H 为例,我需要只读取这4列信息,并存入数组中,
# 读取指定列的数据
data = pd.read_excel(file_path, usecols="B,F,G,H")
# 读取数据
# 将数据按3行一组存入列表,这里将三行数据存为一组
grouped_data = [data.iloc[i:i+3].values.tolist() for i in range(0, len(data), 3)]
print(grouped_data)
'''
[[[1, 'a', 'x', 'α'], [2, 'b', 'y', 'β'], [3, 'c', 'z', 'γ']], [[4, 'a', 'x', 'α'], [5, 'b', 'y', 'β'], [6, 'c', 'z', 'γ']], [[7, 'a', 'x', 'α'], [8, 'b', 'y'
, 'β'], [9, 'c', 'z', 'γ']], [[10, 'a', 'x', 'α'], [11, 'b', 'y', 'β'], [12, 'c', 'z', 'γ']], [[13, 'a', 'x', 'α'], [14, 'b', 'y', 'β'], [15, 'c', 'z', 'γ']]
, [[16, 'a', 'x', 'α'], [17, 'b', 'y', 'β'], [18, 'c', 'z', 'γ']], [[19, 'a', 'x', 'α']]]
'''
# 更进一步的,我们可以使用以下的操作 对读取到的数据列表进行扁平处理
grouped_data = [sum(sublist, []) for sublist in grouped_data]
# 可以实现,每3行为一组,一组信息为一个list,然后总体列表由三级嵌套转换为二级嵌套
print(grouped_data)
'''
[[1, 'a', 'x', 'α', 2, 'b', 'y', 'β', 3, 'c', 'z', 'γ'], [4, 'a', 'x', 'α', 5, 'b', 'y', 'β', 6, 'c', 'z', 'γ'], [7, 'a', 'x', 'α', 8, 'b', 'y', 'β', 9, 'c',
'z', 'γ'], [10, 'a', 'x', 'α', 11, 'b', 'y', 'β', 12, 'c', 'z', 'γ'], [13, 'a', 'x', 'α', 14, 'b', 'y', 'β', 15, 'c', 'z', 'γ'], [16, 'a', 'x', 'α', 17, 'b'
, 'y', 'β', 18, 'c', 'z', 'γ'], [19, 'a', 'x', 'α']]
'''
运行可能会存在警告,如下:
UserWarning: Workbook contains no default style, apply openpyxl’s default
warn(“Workbook contains no default style, apply openpyxl’s default”)
这个警告通常不会影响数据的读取,只是指出 Excel 文件中没有默认样式表。你可以通过设置 engine=‘openpyxl’ 来明确指定 pandas.read_excel() 使用 openpyxl 引擎以避免警告。
当然,有人会觉得pandas库过于庞大,我们也可以使用openpyxl库,
我们可以调整一下读取形式,实现另一种读取场景,还是上面的表格,实现按列读取
代码如下:
import openpyxl
file_path = 'path/to/your/a.xlsx' # 请将文件路径替换为你的 Excel 文件路径
wb = openpyxl.load_workbook(file_path)
sheet = wb.active
# 选择 B、F、G 和 H 列
columns = ['B', 'F', 'G', 'H']
data = []
# 读取指定列数据,按照3行为一组存入列表
for col in columns:
col_data = []
# 如果想要跳过首行,则可以使用这行代码,从第2行开始读取
# for row in range(2, sheet.max_row + 1, 3):
for row in range(1, sheet.max_row + 1, 3):
values = [sheet[col + str(row + i)].value for i in range(3) if sheet[col + str(row + i)].value is not None]
if values:
col_data.append(values)
data.append(col_data)
print(data)
'''
[[['seid', 1, 2], [3, 4, 5], [6, 7, 8], [9, 10, 11], [12, 13, 14], [15, 16, 17], [18, 19]], [['encKey', 'a', 'b'], ['c', 'a', 'b'], ['c', 'a', 'b'], ['c', 'a', 'b'],
['c', 'a', 'b'], ['c', 'a', 'b'], ['c', 'a']], [['mackey', 'x', 'y'], ['z', 'x', 'y'], ['z', 'x', 'y'], ['z', 'x', 'y'], ['z', 'x', 'y'], ['z', 'x', 'y'], ['z', 'x'
]], [['dekkey', 'α', 'β'], ['γ', 'α', 'β'], ['γ', 'α', 'β'], ['γ', 'α', 'β'], ['γ', 'α', 'β'], ['γ', 'α', 'β'], ['γ', 'α']]]
'''
# 如果我们想要和上面pandas处理后完全一致的数据格式,
# 则我们可以使用一些简单的列表变换,来实现输出结果的格式转换


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









