









ElasticSearch学习
Lucene概念
Lucene是apache软件基金会 jakarta项目组的一个子项目,是一个开放源代码的全文检索引擎工具包,但它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎(英文与德文两种西方语言)。Lucene的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者是以此为基础建立起完整的全文检索引擎。Lucene是一套用于全文检索和搜寻的开源程式库,由Apache软件基金会支持和提供。Lucene提供了一个简单却强大的应用程式接口,能够做全文索引和搜寻。在Java开发环境里Lucene是一个成熟的免费开源工具。就其本身而言,Lucene是当前以及最近几年最受欢迎的免费Java信息检索程序库。人们经常提到信息检索程序库,虽然与搜索引擎有关,但不应该将信息检索程序库与搜索引擎相混淆。
大数据就两个问题:存储 + 计算!
Lucene是一套信息检索工具包,jar包,不包含搜索引擎。
包含的:索引结构,读写索引的工具,排序,搜索规则,工具类等。
Lucene是一套信息检索工具包,并不包含搜索引擎系统,它包含了索引结构、读写索引工具、相关性工具、排序等功能,因此在使用Lucene时仍需要关注搜索引擎系统,例如数据获取、解析、分词等方面的东西。而solr和elasticsearch都是基于该工具包做的一些封装。
Lucene 和 ElasticSearch关系:
ElasticSearch是基于Lucene做了一些封装和增强。
solr利用zookpper进行分布式管理,而elasticsearch自身带有分布式协调管理功能;
solr比elasticsearch实现更加全面,solr官方提供的功能更多,而elasticsearch本身更注 重于核心功能,高级功能多由第三方插件提供;
solr在传统的搜索应用中表现好于elasticsearch,而elasticsearch在实时搜索应用方面比solr表现好!
ElasticSearch概念
Elasticsearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java语言开发的,并作为Apache许可条款下的开放源码发布,是一种流行的企业级搜索引擎。Elasticsearch用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。官方客户端在Java、.NET(C#)、PHP、Python、Apache Groovy、Ruby和许多其他语言中都是可用的。根据DB-Engines的排名显示,Elasticsearch是最受欢迎的企业搜索引擎,其次是Apache Solr,也是基于Lucene。
用于全文搜索,结构化搜索,分析。
Solr和ElasticSearch的区别




安装ElasticSearch
官网下载 :https://www.elastic.co/cn/downloads/elasticsearch 速度超级慢 建议去中文社区下载


运行
解压之后在bin目录里面打开elasticsearch.bat运行,然后在浏览器输入localhost:9200可以看到成功界面:


可视化界面
下载地址: https://github.com/mobz/elasticsearch-head
前提是有node和npm环境!!

安装皆可:npm install grunt-contrib-jasmine --registry=https://registry.npm.taobao.org
安装完成之后再运行就不会报错了:
启动:
npm install
npm run start


如何解决跨域问题
在elasticsearch的配置文件中
elasticsreach.yml中添加两行参数,如下,重启elasticsearch解决跨域问题
http.cors.enabled: true
http.cors.allow-origin: "*"

创建索引:

这个head可视化工具我们就当做一个数据展示工具,我们后面所以的查询操作都会在kibana中进行
安装Kibana 要和elasticsearch版本一致

下载解压:
解压后的目录:

启动 启动前提:elasticsearch必须开启, 因为有package.json文件 所以这是一个前端项目
旧版本:

新版本:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Rkm7Lu7X-1620805263832)(D:\Markdown\image-20210509151039427.png)]](https://img-blog.csdnimg.cn/20210512154914653.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3dlaXhpbl80NDQ3NTc0MQ==,size_16,color_FFFFFF,t_70)
访问端口:localhost:5601

之后所有的操作都在这里面进行


汉化,我们这个包里面有定义好的国际化,直接拿来用就可以了
D:\JavaService\kibana-7.10.0-windows-x86_64\x-pack\plugins\translations\translations\zh-CN.json
然后在配置文件中更改一下参数就可以了:i18n.locale: “zh-CN”

ES核心概念
索引
字段的类型 mapping
文档即记录
分片–倒排索引



IK分词器插件
使用中文就用IK分词器,这个版本还是要一致。
将下载的包解压到插件目录下就可以了。
重新启动之后可以看到

这说明插件已经被加载了。
用命令查看所有的插件可以看到我们刚按的ik插件。

ik_smart 最少切分 没有重复


ik_max_word 最细粒度划分,穷尽所有的可能 有重复

有一个问题,那就是我们想搜索狂神说这个词,但是在这里他默认的给拆分了,所以我们只能自己把狂神说这个词加到字典里面去。在ik插件中去配置就可以了。


Rest风格说明

关于索引的基本操作
插入操作
- 创建索引 PUT命令是插入的意思
PUT /索引名/类型名(以后不用写)/文档ID
{
请求体
}






以后的type会被阉割,所以我们用_doc来代替就好了



更新操作


关于文档的基本操作 (重点)


GET shi/_search
{
"query":{
"match":{
"name":"雨伞"
}
},
"_source":["name","price"]
}

排序 分页
GET shi/_search
{
"query": {
"match": {
"name": "手"
}
},
"sort": [
{
"price": {
"order": "desc"
}
}
],
"from": 0,
"size": 2
}


# 复杂查询 - 查询 - 排序 - 分页
GET test/_search
{
"query": {
"match": {
"name": "樱木花"
}
},
"_source": ["name","age"],
"sort": [
{
"age": {
"order": "desc"
}
}
],
"from": 0,
"size": 3
}
多条件精确查询 must命令相当于and should命令相当于or




# 加了过滤器的精确多条件查询
GET test/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "樱木"
}
}
],
"filter": [
{
"range": {
"age": {
"gte": 10,
"lte": 20
}
}
}
]
}
}
}
匹配多个条件

精确查询
简单来说一下精确查询的原理:
term query会去倒排索引中寻找确切的term,它并不知道分词器的存在,所以他只能查出当这个字段类型是不可以分词的情况,这种查询适合keyword、numeric、date等明确值的。
而match查询相当于模糊查询,match是知道分词器的存在的,并且每次查询都会进行分词,所以查到的结果会有很多。
因为term不考虑分词所以他查的条件就是字段所有的内容。
term:查询某个字段里含有某个关键词的文档
GET test/_search
{
"query": {
"term": {
"address.keyword": "日本大阪"
}
}
}



它和term区别可以理解为term是精确查询,这边match模糊查询;match会对my ss分词为两个单词,然后term对认为这是一个单词
term是根据倒排索引进行精确查找的。


高亮查询



集成SpringBoot
- 依赖
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.10.0</version>
</dependency>
- 怎么用

注意我们springboot自带的es版本和我们本地的版本不一样会造成预想不到的问题
# 找到自带的版本自定义修改就可以了
<elasticsearch.version>7.9.3</elasticsearch.version>

所有的关于数据库的都在springboot的自动配置包的data包下

编写配置类
package com.shi.config;
import org.apache.http.HttpHost;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class ElasticSearchClientConfig {
@Bean
public RestHighLevelClient restHighLevelClient(){
RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder(
new HttpHost("localhost", 9200, "http")));
return client;
}
}
然后在测试中注入就可以了
@Autowired
private RestHighLevelClient restHighLevelClient;
//名称必须是默认的,否则会报错 否则加注解 @Qualifier("restHighLevelClient")
测试高级客户端API
创建索引
// 创建索引
@Test
void createIndex() throws IOException {
// 创建索引请求
CreateIndexRequest request = new CreateIndexRequest(".shi_1");
// 客户端运行请求,然后响应
CreateIndexResponse createIndexResponse = client.indices().create(request, RequestOptions.DEFAULT);
System.out.println(createIndexResponse.index());
}

获取索引
// 获取索引
@Test
void existIndex() throws IOException {
GetIndexRequest getIndexRequest = new GetIndexRequest(".shi_1");
boolean exists = client.indices().exists(getIndexRequest, RequestOptions.DEFAULT);
System.out.println(exists);
}// 返回true
删除索引
// 删除索引
@Test
void deleteIndex() throws IOException {
DeleteIndexRequest t2 = new DeleteIndexRequest("t2");
AcknowledgedResponse delete = client.indices().delete(t2, RequestOptions.DEFAULT);
System.out.println(delete);
}// 返回true true代表删除成功
添加索引
由于我们的user对象需要转化成json的格式方便存储和读取,所以我们用阿里巴巴的fastjson包来转化
<!-- https://mvnrepository.com/artifact/com.alibaba/fastjson -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.75</version>
</dependency>
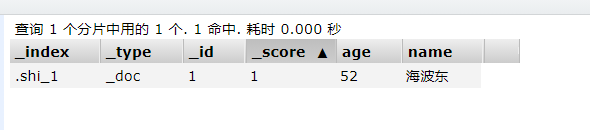
// 添加文档
@Test
void addDocument() throws IOException {
// 创建对象
User user = new User("海波东", 52);
// 创建请求
IndexRequest request = new IndexRequest(".shi_1");
// 规则 put shi/_doc/1
request.id("1");
request.timeout("1s");
//将我们的数据放入请求
request.source(JSON.toJSONString(user), XContentType.JSON);
// 客户端发送请求 获取响应结果
IndexResponse index = client.index(request, RequestOptions.DEFAULT);
System.out.println(index.toString());
System.out.println(index.status());
}

获取文档 查看文档是否存在
// 获取文档 查看文档是否存在
@Test
void existDocument() throws IOException {
GetRequest getRequest = new GetRequest(".shi_1", "1");
//不获取返回的上下文了
getRequest.fetchSourceContext(new FetchSourceContext(false));
getRequest.storedFields("_none_");
boolean exists = client.exists(getRequest, RequestOptions.DEFAULT);
System.out.println(exists);
} // 返回true 表示存在该文档
获取文档信息
// 获取文档信息
@Test
void getDocument() throws IOException{
GetRequest request = new GetRequest(".shi_1", "1");
GetResponse response = client.get(request, RequestOptions.DEFAULT);
// 打印文档键值对
System.out.println(response.getSourceAsString());
// 打印文档所有内容
System.out.println(response);
}
}
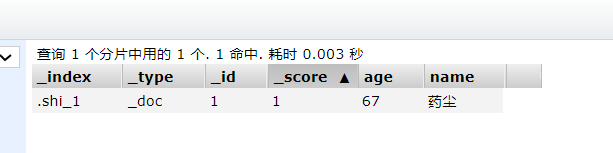
更新文档信息
// 更新文档
@Test
void updateDocument() throws IOException{
UpdateRequest request = new UpdateRequest(".shi_1", "1");
request.timeout("1s");
User user = new User("药尘", 67);
request.doc(JSON.toJSONString(user),XContentType.JSON);
UpdateResponse update = client.update(request, RequestOptions.DEFAULT);
System.out.println(update.status());
} // 返回OK
删除文档信息
// 删除文档信息
@Test
void deleteDocument() throws IOException {
DeleteRequest deleteRequest = new DeleteRequest(".shi_1", "2");
deleteRequest.timeout("1s");
DeleteResponse delete = client.delete(deleteRequest, RequestOptions.DEFAULT);
System.out.println(delete.status());
} // 返回OK 表示删除成功
批量增加文档信息
// 批量增加文档信息
@Test
void addBlukDocument() throws IOException {
BulkRequest bulkRequest = new BulkRequest();
bulkRequest.timeout("10s");
List<User> list = new ArrayList<>();
list.add(new User("千仞雪",20));
list.add(new User("千仞雪1",21));
list.add(new User("千仞雪2",22));
list.add(new User("千仞雪3",22));
list.add(new User("千仞雪4",23));
list.add(new User("千仞雪5",21));
for (int i = 0; i < list.size(); i++) {
bulkRequest.add(
new IndexRequest(".shi_1")
.id(""+(i+1))
.source(JSON.toJSONString(list.get(i)),XContentType.JSON)
);
}
BulkResponse bulk = client.bulk(bulkRequest, RequestOptions.DEFAULT);
System.out.println(bulk.hasFailures());
} // 返回false 这里的false是没有错误的意思

批量插入数据之后会原先id相同的数据。
不指定id就会生成默认的id,大数据环境下一般都是默认生成的id。
复杂查询和显示高亮
// 复杂查询和显示高亮
@Test
void Search() throws IOException{
SearchRequest searchRequest = new SearchRequest(".shi_1");
// 构建查询条件 构造者模式
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
sourceBuilder.highlighter();//高亮
// 查询条件,我们可以使用QueryBuilders工具类实现
// QueryBuilders.termQuery(); // 精确查询
// QueryBuilders.matchAllQuery(); // 匹配所有
TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("name.keyword", "千仞雪");
// MatchQueryBuilder matchQueryBuilder = QueryBuilders.matchQuery("name", "千仞");
sourceBuilder.query(termQueryBuilder);
sourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS)); // 设置查询过期时间 即一定时间内查询不到退出
searchRequest.source(sourceBuilder);
SearchResponse search = client.search(searchRequest, RequestOptions.DEFAULT);
System.out.println(JSON.toJSONString(search.getHits()));
System.out.println("====================");
System.out.println(search.getHits().getTotalHits());
}

注意点:我们在用term精确查询字段的时候,如果字段名的内容是中文的话我们必须给字段名加上.keyword,否则查不到结果,英文的话直接默认字段明就可以了。英文的字段名也可以加.keyword,所以我们一般在字段后面加上.keyword就可以了。


复杂查询改良版
// 复杂查询和显示高亮
@Test
void Search() throws IOException{
SearchRequest searchRequest = new SearchRequest(".shi_1");
// 构建查询条件 构造者模式
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
/*sourceBuilder.highlighter()
.preTags("<p class='key' style='color:red'>")
.postTags("</p>")
.field("name");//高亮*/
// 查询条件,我们可以使用QueryBuilders工具类实现
// QueryBuilders.termQuery(); // 精确查询
// QueryBuilders.matchAllQuery(); // 匹配所有
//TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("name.keyword", "千仞雪");
//sourceBuilder.query(termQueryBuilder);
//MatchQueryBuilder matchQueryBuilder = QueryBuilders.matchQuery("name", "千仞");
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
MatchQueryBuilder m1 = QueryBuilders.matchQuery("name", "千仞雪");
MatchQueryBuilder m2 = QueryBuilders.matchQuery("name", "qianrenxue2");
boolQueryBuilder.should().add(m1);
boolQueryBuilder.should().add(m2);
RangeQueryBuilder age = QueryBuilders.rangeQuery("age").gte(21);
boolQueryBuilder.filter(age);
sourceBuilder.query(boolQueryBuilder);
// sourceBuilder.sort("age", SortOrder.ASC); // 排序
// sourceBuilder.from(0); // 分页查询 从第几个开始
// sourceBuilder.size(2); // 分页查询 显示几个/每页
sourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS)); // 设置查询过期时间 即一定时间内查询不到退出
// 把创建好的条件放入查询
searchRequest.source(sourceBuilder);
// 客户端执行
SearchResponse search = client.search(searchRequest, RequestOptions.DEFAULT);
System.out.println(JSON.toJSONString(search.getHits()));
System.out.println("====================");
Iterator<SearchHit> it = search.getHits().iterator();
while (it.hasNext()){
System.out.println(it.next());
}
System.out.println(search.getHits().getTotalHits());
}

实战京东搜索

爬虫
我们Java想要做爬虫的话一般都会用jsoup包
<!-- https://mvnrepository.com/artifact/org.jsoup/jsoup -->
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.13.1</version>
</dependency>
jsoup包不可以爬取电影和音乐之类的,想要爬取这一些要用tika包
<!-- https://mvnrepository.com/artifact/org.apache.tika/tika-core -->
<dependency>
<groupId>org.apache.tika</groupId>
<artifactId>tika-core</artifactId>
<version>1.24.1</version>
</dependency>
// 好用的io包
<!-- https://mvnrepository.com/artifact/commons-io/commons-io -->
<dependency>
<groupId>commons-io</groupId>
<artifactId>commons-io</artifactId>
<version>2.6</version>
</dependency>
// 将爬取的数据输出到文件中
Element element = document.getElementById("J_goodsList");
File file = new File("e:/好东西/a.html");
FileUtils.writeStringToFile(file,element.html(),"utf-8");
爬虫工具包 以后把这个包日益完善然后导成jar包自己用
package com.shi.utils;
import com.shi.pojo.Content;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import org.springframework.stereotype.Component;
import java.io.IOException;
import java.net.URL;
import java.net.URLDecoder;
import java.net.URLEncoder;
import java.util.ArrayList;
import java.util.List;
/**
* @author Shi Jun Yi
* @version 1.0
* @date 2021/5/10 15:49
*/
@Component
public class HtmlParseUtil {
public static List<Content> parseJD(String keyword) throws IOException{
// 获取请求 https://search.jd.com/Search?keyword=java
// 如果不转义的话对中文的搜索不好 所以必须对地址进行转义
String url = "https://search.jd.com/Search?keyword="+keyword;
// 开始转义
String newurl = URLEncoder.encode(url, "utf-8");
String durl = URLDecoder.decode(newurl, "utf-8");
// 解析网址,三十秒内无响应报错
Document document = Jsoup.parse(new URL(durl), 30000);
// 返回的是js的对象,js的方法都可以用
Element element = document.getElementById("J_goodsList");
// System.out.println(element.html());
// 获取每一个li标签
Elements elements = element.getElementsByTag("li");
List<Content> goodslist = new ArrayList<>();
for (Element el : elements) {
// 获取图片,但是这种多图片的网站都是懒加载,
String img = el.getElementsByTag("img").eq(0).attr("data-lazy-img");
// 获取价格
String price = el.getElementsByClass("p-price").eq(0).text();
// 获取标题
String tittle = el.getElementsByClass("p-name").eq(0).text();
/* System.out.println("==================================");
System.out.println(img);
System.out.println(price);
System.out.println(tittle);*/
goodslist.add(new Content(img,tittle,price));
}
return goodslist;
}
public static void main(String[] args ){
}
}
测试
@Autowired
HtmlParseUtil htmlParseUtil;
@Test
void contextLoads() throws IOException {
List<Content> list = htmlParseUtil.parseJD("纪梵希");
File file = new File("e:/好东西/a.txt");
FileUtils.writeStringToFile(file,list.toString(),"utf-8");
System.out.println("输出成功");
}
结果 成功!!

注意一点:当我们用注解@Autowired 的时候如果想调用类里面的方法,那这个方法不能是static,否则无法由spring托管!!!
编写业务
首先我们需要将爬取到的数据放到es里面,然后我们在地址栏模拟搜索(事实上就是查询es里面存储的爬取的数据),最后分页显示出来
service层的编写,主要是将数据存入es和将数据查询出来
package com.shi.service;
import com.alibaba.fastjson.JSON;
import com.shi.pojo.Content;
import com.shi.utils.HtmlParseUtil;
import org.elasticsearch.action.bulk.BulkRequest;
import org.elasticsearch.action.bulk.BulkResponse;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchRequestBuilder;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.common.text.Text;
import org.elasticsearch.common.unit.TimeValue;
import org.elasticsearch.common.xcontent.XContentType;
import org.elasticsearch.index.query.MatchQueryBuilder;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.index.query.TermQueryBuilder;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import org.elasticsearch.search.fetch.subphase.highlight.HighlightBuilder;
import org.elasticsearch.search.fetch.subphase.highlight.HighlightField;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.stereotype.Service;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
import java.util.concurrent.TimeUnit;
/**
* @author Shi Jun Yi
* @version 1.0
* @date 2021/5/10 17:31
* 业务编写
*/
@Service
public class ContentService {
@Autowired
@Qualifier("restHighLevelClient")
private RestHighLevelClient client;
@Autowired
private HtmlParseUtil htmlParseUtil;
/**
* 解析数据放入索引
* @param keyword
* @return
* @throws IOException
*/
public Boolean parseContext(String keyword) throws IOException{
List<Content> contents = htmlParseUtil.parseJD(keyword);
// 将爬取的数据放到es中
BulkRequest bulkRequest = new BulkRequest();
bulkRequest.timeout("3m");
for (int i = 0; i < contents.size(); i++) {
bulkRequest.add(
new IndexRequest(".jd_index")
.source(JSON.toJSONString(contents.get(i)), XContentType.JSON)
);
System.out.println(contents.get(i));
}
BulkResponse bulk = client.bulk(bulkRequest, RequestOptions.DEFAULT);
return !bulk.hasFailures();
}
/**
* 获取这些数据
*/
public List<Map<String,Object>> searchPage(String keyword,int from,int size) throws IOException{
if (from <= 1){
from = 1;
}
SearchRequest searchRequest = new SearchRequest(".jd_index");
// 创建建造者 之后才能创建条件,因为查询的条件都是由创建者创造的
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
sourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS));
MatchQueryBuilder tittle = QueryBuilders.matchQuery("title", keyword);
sourceBuilder.query(tittle)
.from(from)
.size(size);
// 刚才这一步忘记了,导致怎么查怎么不对
searchRequest.source(sourceBuilder);
List<Map<String,Object>> list = new ArrayList<>();
SearchResponse search = client.search(searchRequest, RequestOptions.DEFAULT);
for (SearchHit documentFields : search.getHits().getHits()) {
list.add(documentFields.getSourceAsMap());
System.out.println(documentFields.getSourceAsString());
}
return list;
}
/**
* 获取这些高亮数据
*/
public List<Map<String,Object>> searchPagehighlighter(String keyword,int from,int size) throws IOException{
if (from <= 1){
from = 1;
}
SearchRequest searchRequest = new SearchRequest(".jd_index");
// 创建建造者 之后才能创建条件,因为查询的条件都是由创建者创造的
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
sourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS));
MatchQueryBuilder tittle = QueryBuilders.matchQuery("title", keyword);
sourceBuilder.query(tittle)
.from(from)
.size(size);
HighlightBuilder highlightBuilder = new HighlightBuilder();
// 相同字段多个高亮
highlightBuilder.requireFieldMatch(false);
// 前缀后缀
highlightBuilder.field("title");
highlightBuilder.preTags("<span style='color:red'>");
highlightBuilder.postTags("</span>");
sourceBuilder.highlighter(highlightBuilder);
// 刚才这一步忘记了,导致怎么查怎么不对
searchRequest.source(sourceBuilder);
List<Map<String,Object>> list = new ArrayList<>();
SearchResponse search = client.search(searchRequest, RequestOptions.DEFAULT);
for (SearchHit documentFields : search.getHits().getHits()) {
// 解析高亮的字段
// 核心思想就像将我们原先输出的字段部分替换成高亮的部分
// 取出高亮字段
Map<String, HighlightField> highlightFields = documentFields.getHighlightFields();
HighlightField title = highlightFields.get("title");
// 取出原来的字段
Map<String, Object> sourceAsMap = documentFields.getSourceAsMap();
if (title != null){
Text[] fragments = title.fragments();
String n_title = "";
for (Text text : fragments) {
n_title += text;
}
// 替换原来的旧字段
sourceAsMap.put("title",n_title);
}
list.add(sourceAsMap);
System.out.println(documentFields.getSourceAsString());
}
return list;
}
}
controller层负责查询和显示数据
package com.shi.controller;
import com.shi.service.ContentService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.ResponseBody;
import java.io.IOException;
import java.util.List;
import java.util.Map;
/**
* @author Shi Jun Yi
* @version 1.0
* @date 2021/5/10 17:32
* 控制层编写
*/
@Controller
public class ContentController {
@Autowired
ContentService contentService;
@GetMapping("/search/{keyword}")
@ResponseBody
public Boolean parse(@PathVariable("keyword") String keyword) throws IOException {
return contentService.parseContext(keyword);
}
@GetMapping("/search/{keyword}/{from}/{size}")
@ResponseBody
public List<Map<String,Object>> search(@PathVariable("keyword") String keyword, @PathVariable("from") int from, @PathVariable("size") int size) throws IOException{
return contentService.searchPagehighlighter(keyword,from,size);
}
}
分页查询–奶茶的前三十个数据

前端页面编写,前后端分离



搜索高亮
<!DOCTYPE html>
<html xmlns:th="http://www.thymeleaf.org">
<head>
<meta charset="utf-8"/>
<title>京西商城</title>
<link rel="stylesheet" th:href="@{/css/style.css}"/>
</head>
<body class="pg">
<div class="page" id="app">
<div id="mallPage" class=" mallist tmall- page-not-market ">
<!-- 头部搜索 -->
<div id="header" class=" header-list-app">
<div class="headerLayout">
<div class="headerCon ">
<!-- Logo-->
<h1 id="mallLogo">
<img th:src="@{/images/jdlogo.png}" alt="">
</h1>
<div class="header-extra">
<!--搜索-->
<div id="mallSearch" class="mall-search">
<form name="searchTop" class="mallSearch-form clearfix">
<fieldset>
<legend>京西搜索</legend>
<div class="mallSearch-input clearfix">
<div class="s-combobox" id="s-combobox-685">
<div class="s-combobox-input-wrap">
<!--双向绑定,将这个搜索框与下面的script绑定-->
<input v-model="keyword" type="text" autocomplete="off" value="" id="mq"
class="s-combobox-input" aria-haspopup="true">
</div>
</div>
<!--新建事件,当点击搜索的时候发生下面script定义的方法-->
<button type="submit" id="searchbtn" @click.prevent="searchkey">搜索</button>
</div>
</fieldset>
</form>
<ul class="relKeyTop">
<li><a>电脑数码</a></li>
<li><a>食品饮料</a></li>
<li><a>京西奢品</a></li>
<li><a>京西时尚</a></li>
<li><a>万件7折</a></li>
<li><a>运动健康</a></li>
<li><a>性爱生活</a></li>
</ul>
</div>
</div>
</div>
</div>
</div>
<!-- 商品详情页面 -->
<div id="content">
<div class="main">
<!-- 品牌分类 -->
<form class="navAttrsForm">
<div class="attrs j_NavAttrs" style="display:block">
<div class="brandAttr j_nav_brand">
<div class="j_Brand attr">
<div class="attrKey">
品牌
</div>
<div class="attrValues">
<ul class="av-collapse row-2">
<li><a href="#"> 小米 </a></li>
<li><a href="#"> 杰士邦 </a></li>
<li><a href="#"> 爱马仕 </a></li>
<li><a href="#"> 古驰 </a></li>
<li><a href="#"> 香奈儿 </a></li>
</ul>
</div>
</div>
</div>
</div>
</form>
<!-- 排序规则 -->
<div class="filter clearfix">
<a class="fSort fSort-cur">综合<i class="f-ico-arrow-d"></i></a>
<a class="fSort">人气<i class="f-ico-arrow-d"></i></a>
<a class="fSort">新品<i class="f-ico-arrow-d"></i></a>
<a class="fSort">销量<i class="f-ico-arrow-d"></i></a>
<a class="fSort">价格<i class="f-ico-triangle-mt"></i><i class="f-ico-triangle-mb"></i></a>
</div>
<!-- 商品详情 -->
<div class="view grid-nosku">
<div class="product" v-for="result in results">
<div class="product-iWrap">
<!--商品封面-->
<div class="productImg-wrap">
<a class="productImg">
<img :src="result.img">
</a>
</div>
<!--价格-->
<p class="productPrice">
<em>{{result.price}}</em>
</p>
<!--标题-->
<p class="productTitle">
<a v-html="result.title"> </a>
</p>
<!-- 店铺名 -->
<div class="productShop">
<span>店铺: 狂神说Java </span>
</div>
<!-- 成交信息 -->
<p class="productStatus">
<span>月成交<em>999笔</em></span>
<span>评价 <a>3</a></span>
</p>
</div>
</div>
</div>
</div>
</div>
</div>
</div>
<!--前端用vue实现前后端分离-->
<script th:src="@{/js/axios.min.js}"></script>
<script th:src="@{/js/vue.min.js}"></script>
<!--把包导入之后我们就可以用了,首先要new一个vue对象-->
<script>
new Vue({
el : '#app', //与整个页面绑定
data: {
keyword : '', // 搜索的关键字
results : [] // 搜索的结果
},
methods : {
searchkey(){
var keyword = this.keyword;
console.log(keyword);
// 在前端的搜索可以使用,直接对接后端的接口就可以了
axios.get('search/'+keyword+"/1/30").then(response=>{
console.log(response.data);
this.results = response.data; // 双向绑定 绑定数据
})
}
}
})
</script>
</body>
</html>
结果:

搜索高亮完成!!















 3808
3808











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









