







hash表一致性哈希
哈希表
哈希表(hash)又叫散列表是一种数据结构,可以根据 key 计算 key 在表中的位置;是 key 和其所在存储地址的映射关系(如:Hash(key)=address) 。
哈希表的节点中的 key和value 是存储在一起的;如下所示
struct node {
void *key;
void *val;
struct node *next;
};
哈希表有几个因素:hash函数、负载因子
hash函数
hash函数就是一种地址的映射关系 Hash(key)=address ;
但是hash 函数可能会把两个或两个以上的不同 key 映射到同一地址,这种情况称之为哈希冲突(或者hash 碰撞);
几种经典的hash函数:
murmurhash1,murmurhash2,murmurhash3,siphash( redis6.0当中使用,rust 等大多数语言选用的 siphash 算法来实现 hashmap ),cityhash 都具备强随机分布性;
负载因子
负载因子是描述hash冲突的激烈程度。
负载因子=(数组存储元素的个数 / 数据长度);用来形容散列表的存储密度;
负载因子越小,冲突越小,负载因子越大,冲突越大;
冲突处理
链表法
链表法就是将冲突元素用链表链接起来;这也是常用的处理冲突的方式。
但是可能出现一种极端情况,冲突元素比较多,该冲突链表过长,查找数据时时间复杂度也变高。
这个时候可以将这个链表转换为红黑树、最小堆;由原来链表时间复杂度转换为红黑树时间复杂度 ;
开放寻址法
开放寻址法就是将所有的元素都存放在哈希表的数组中,**不使用额外的数据结构;**一般是使用线性探查的思路解决;
- 当插入新元素的时,使用哈希函数在哈希表中定位元素位置;
- 检查数组中该槽位索引是否存在元素。如果该槽位为空,则插入,否则3;
- 在 第2步检测的槽位索引上加一定步长接着检查; 加一定步长分为以下几种:
i+1,i+2,i+3,i+4, … ,i+n
i- 1 2 {1}^{2} 12,i+ 2 2 {2}^{2} 22 ,i- 3 2 {3}^{2} 32,1+ 4 2 {4}^{2} 42, … 这两种可以暂时解决哈希冲突,但是会导致同类 hash 聚集;也就是近似值它的hash值也近似,那么它的数组槽位也靠近,形成 hash 聚集;第一种同类聚集冲突在前,第二种只是将聚集冲突延后; 可以使用双重哈希来解决上面出现hash聚集现象:
STL中哈希表的应用
在 STL 中 unordered_map 、unordered_set 、unordered_multimap
、unordered_multiset 四种数据结构的底层实现都是哈希表;
与普通哈希表有所不同的是:
普通哈希表:一个哈希值上会有一条链表
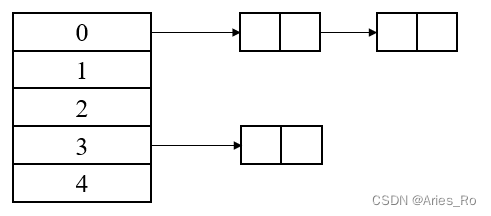
STL中的“哈希表”
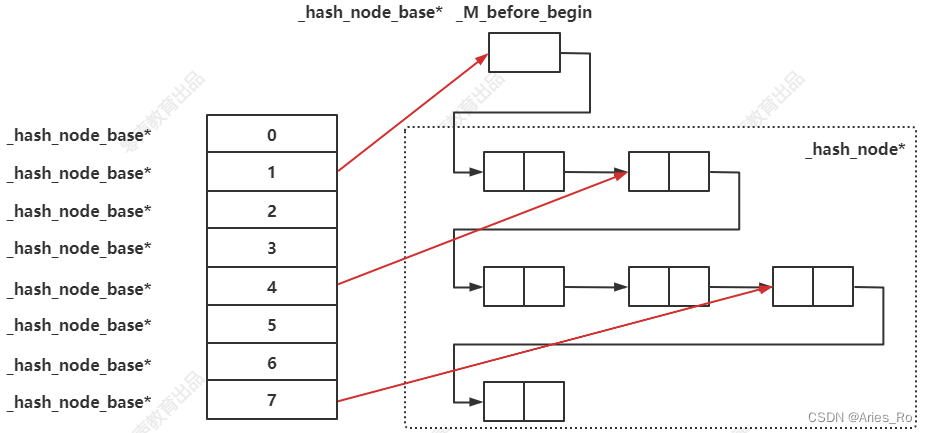
STL中也是采用开链法解决hash冲突,但是并不是一个哈希值一个链表,而是整个hash表是一条链表(应该是为了更好的实现STL中的迭代器,才有这种结构)。插入一个新的数据会采用链表头插法,假如发送哈希冲突了会利用链表插入节点的方法插入数据。
哈希表VS二叉树
哈希表和平衡二叉树都可以从海量数据中查询某个字符串是否存在。
平衡二叉树增删改查时间复杂度为O(logn) ;即100万个节点,最多比较 20 次;10 亿个节点,最多比较 30 次;
平衡的目的是增删改后,保证下次搜索能稳定排除一半的数据;
总结:平衡二叉树通过节点比较,既保证有序,又可以通过每次排除一半的元素达到快速索引的目的;哈希表的查找时间复杂度是O(1),但是不能保证数据的有序性。所以两者各有优劣。
分布式一致性 hash
背景:分布式一致性 hash 算法将哈希空间组织成一个虚拟的圆环,圆环的节点个数是 2 32 {2}^{32} 232;
算法为: hash(ip) % 2 32 {2}^{32} 232,最终会得到一个 [0, 2 32 {2}^{32} 232-1]之间的一个无符号整型,这个整数代表服务器的编号;多个服务器都通过这种方式在 hash 环上映射一个点来标识该服务器的位置;当用户操作某个key,通过同样的算法生成一个值,沿环顺时针定位某个服务器,那么该 key 就在该服务器中。
如图所示:
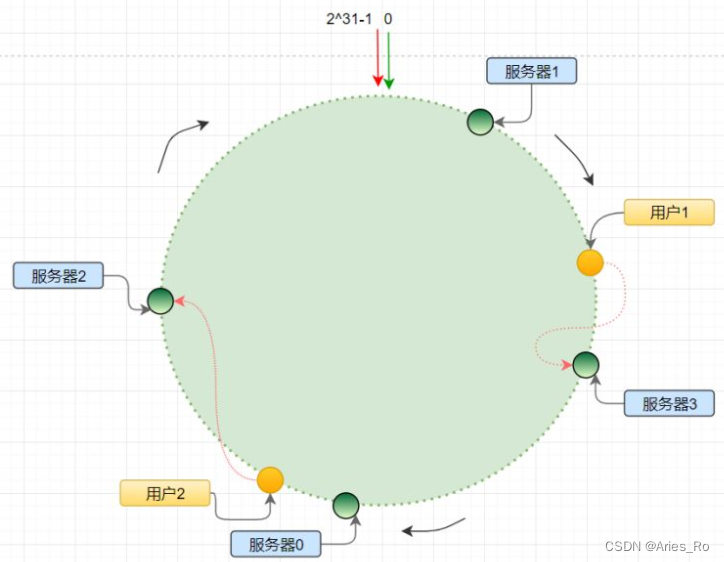
图中首先通过hash(ip) %( 2 32 {2}^{32} 232)计算四台服务器的位置,再通过hash(ip) %( 2 32 {2}^{32} 232)计算用户的位置。例如用户1所在“黄点”,顺时针寻找最近的服务器3,则用户1的key就存在服务器3中。同理用户2存在服务器2中。
应用场景
将数据均衡地分散在不同的服务器当中,来分摊缓存服务器的压力;
解决缓存服务器数量变化尽量不影响缓存失效;
哈希偏移
哈希算法得到的结果是随机的,不能保证服务器节点均匀分布在哈希环上,这就是哈希偏移;
由于分布不均匀会造成请求访问不均匀,导致服务器承受的压力不均匀;如图所示:
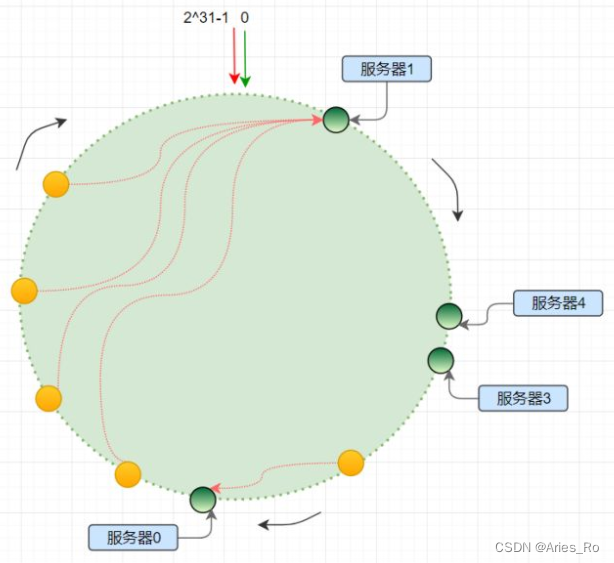
许多用户都保存在服务器1中,服务器1压力巨大。而服务器3可能会比较轻松。
为了解决哈希偏移的问题,引入了虚拟节点的概念。
虚拟节点
理论上,哈希环上节点数越多,数据分布越均衡;为了解决哈希偏移的问题,可以为每个服务节点计算多个哈希节点(新增的哈希节点就是虚拟节点);
通常做法是, hash(“IP:PORT:seqno”)%( 2 32 {2}^{32} 232) ;就是比如把上面的服务器3新增几个虚拟节点(新增的虚拟节点也会随机分布在哈希环上,不一定和服务3相邻),增加服务器3的工作量,从而减轻服务器1的工作量。
删除增加节点
假如删除服务器2,则原来存储在服务器2的用户2,会被取出来重新顺时针寻找到服务器1节点,保存在服务器1中。
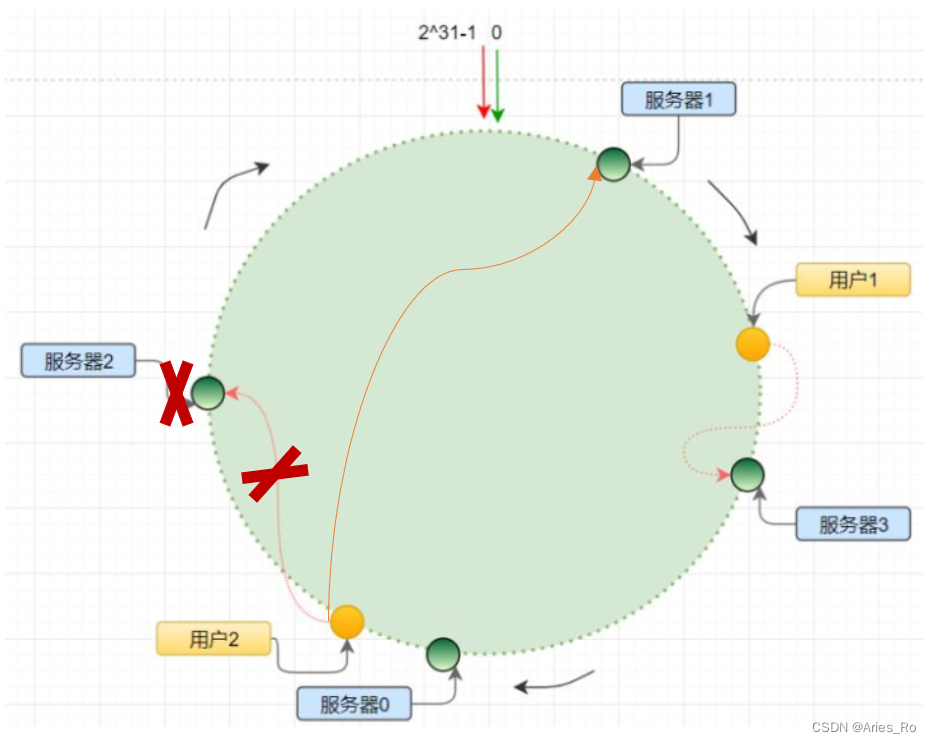
如果增加一个服务器节点的话,会将增加的服务器节点逆时针寻找到前一个服务器之间的所有用户节点保存在这个新增的服务器节点中。















 1420
1420











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











