







Redis
一. Redis安装
1.1使用docker安装redis
需要先把Xterm, VMware, Conten7, docker 和docker-compose安装好
使用如下代码在合适的位置创建yml文件
vi docker-compose.yml
version: '3.1'
services:
redis:
restart: always
image: daocloud.io/library/redis:5.0.7
container_name: redis
environment:
- TZ=Asia/Shanghai
ports:
- 6379:6379
然后使用docker-composr up -d命令,加载redis环境
1.2 连接redis
- 先进入Redis容器的内部
docker exec -it 容器ID bashPS: 使用
docker ps查询目前运行的所有容器
在容器内部.使用命令连接redis
redis-cli
1.3 使用图形化界面:Redis-Desktop-Manager连接Redis
二. Redis常用命令
2.1 Redis存储数据的几种结构
常用五种结构
- key-String: 一个key对应一个值
- key-hash: 一个key对应一个map
- key-list: 一个key对应一个列表
- key-set: 一个key对应一个集合
- key-zset: 一个key对应一个有序的集合
不常用的五种结构
HyperLogLog:
GEO: 地理位置
BIT: 一般存储的也是一个字符串.存储的是一个byte[]
2.2 String常用命令
#1. 添加值
set key value
#2. 取值
get key
#3. 批量添加
mset key value [key value ...]
#4. 批量取值
mget key [key ...]
#5. 自增命令(自增1)
incr key
#6. 自减命令(自减1)
decr key
#7. 自增或自减指定数量
incrby key incerment(数量)
decrby key incerment(数量)
#8. 设置值的同时指定生存时间
setex key second value
#9. 设置值,如果当前key不存在的话,创建,存在则不操作
setnx key value
#10.在value后追加内容
append key value
#11.查看key对应的value的长度
strlen key
2.3 hash常用命令
#1. 存储数据
hset key field value
#2. 获取数据
hget key field
#3. 批量存取
hmset key field value [field value ...]
–
#4. 自增
hincrby key field incerment(数量,可为负)
#5. 设置值,如果(key-field)为空,则创建,不为空不操作
hsetnx key field value
#6. 检查field是否存在
hexists key field
#7, 删除key对应的某一个field
hdel key field
#8. 获取当前hash结构下的全部field和value
hgetall key
#9. 获取此hash下所有的field 不要value
hkeys key
#10. 获取此hash下所有的values 不要field
hvals key
#11. 获取当前hash的field的数量
henl key
2.4 List常用命令
#1. 存储数据(从左侧插入)
lpush key value [value...]
rpush key value [value...]
#2. 存储数据(如果key不存在或者key不是list结构,什么都不做)
lpushx key value [value...]
rpushx key value [value...]
#3.替换指定位置的value
lset key index value
#4. 弹栈方式获取数据(左侧,或者右侧,同时原列表会弹出此元素,就被删除了)
lpop key
rpop key
#5. 获取指定索引范围内的数据,(start从0开始,-1代表最后一个,-2代表倒数第二个)
lrange key start stop
#6. 获取指定索引位置的数据
lindex key index
#7. 获取整个列表的长度
llen key
#8. 删除列表中的数据(count大于0 就从左侧删除count个元素,小于0 就从右侧删除count个元素,==0 删除列表内的全部value元素)
lrem key count value
#9. 保留列表中的数据的(保留指定索引范围内的数据,超过整合索引范围的被移除)
ltrim key start stop
#10.将一个列表的最后一个数据,插入到另外一个列表的头部位置
rpoplpush list1 list2
2.5 Set常用命令
#1. 存储数据
sadd key member [member...]
#2. 获取数据(获取全部数据)
smembers key
#3. 随机获取数据(获取的同时移除数据,默认为一,可指定)
spop key [count]
#4. 交集
sinter set1 set2
#5. 并集
sunion set1 set2 ...
#6. 差集
sdiff set1 set2 ...
#7. 删除数据
srem key member [member ...]
#8. 查看当前的set集合中是否包含这个值
sismember key member
2.6 Zset的常用命令
#1. 添加数据
zadd key score member [socre member...]
#2. 修改member的分数(如果member不存在,则新增)
zincrby key incrment member
#3. 查看指定的member的分数
zsocre key member
#4. 获取zset中的数据的数量
zcard key
#5. 根据score的范围查询member数量
zcount key min max
#6. 删除zset的成员
zrem key member [member...]
#7. 根据分数从小到大排序,获取指定范围内的数据(带分数,或者不带分数)
zrange key start stop [withscores]
#8. 根据分数从大到小排序
zrevrange key start stop [withscores]
#9. 根据分数范围获取数据(从小到大)
zrangebyscores key start stop [withscores] [limit offset count]
#10.根据分数范围获取数据(从大到小)
zrevrangebyscore key start stop [withscore] [limit offset count]
#11. 最大值,最小值
+inf -inf
#(1000 意为<1000
3.7 key常用命令
#1. 查看存在那些key
keys *
#2. 删除key
del key
#3. 查看某一key是否存在
exists key
#4.设置key的生存时间
expire key second
pexpire key milliseconds
#5. 设置key的生存截止时间,设置能活到什么时间
expireat key timestamp
pexpireat key milliseconds
#6. 查看key的剩余生存时间(-2 key不存在,-1key没有设置生存时间)
ttl key
pttl key
#7. 移除key的生存时间,1- 移除成功,0移除不成功, key不存在
persist key
3.8 库的常用操作
#1. 选择操作的库
select 0~15
#2. 移动key到指定的库
move key db
#3. 清空当前操作的库
flushdb
#4. 清空全部数据库
flushall
#5. 查看当前数据库中有多少个key
dbsize
#6. 查看最后一次操作的时间
lastsave
#7. 实时监控redis服务接收到的指令
monitor
JAVA链接redis
使用Java链接redis有两种方式:Jedis和lettuce, 一般推荐使用Jedis
4.1 使用Jedis链接Redis
- 导入依赖
<!-- jdris依赖-->
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>2.9.0</version>
</dependency>
- 测试
Jedis jedis = new Jedis("192.168.0.116", 6379);
jedis.set("username", "zhangsai");
jedis.close();
4.2 Jedis如何存储一个对象到Redis
新建对象实体类,并继承序列化接口
import java.io.Serializable;
@Data
@NoArgsConstructor
@AllArgsConstructor
public class User implements Serializable {
Integer Id;
String name;
}
导入Spring-context的依赖,需要用到其中的序列化工具类
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-context</artifactId>
<version>4.3.18.RELEASE</version>
</dependency>
使用序列化工具类把Key,Value都转化为byte[] 然后存入Redis
@Test
public void test3() {
Jedis jedis = new Jedis("192.168.0.116", 6379);
String key = "user";
User user = new User(1, "zhang");
byte[] byteKey = SerializationUtils.serialize(key);
byte[] byteValue = SerializationUtils.serialize(user);
jedis.set(byteKey, byteValue);
jedis.close();
}
使用序列化工具类,取出Value
@Test
public void test4(){
Jedis jedis = new Jedis("192.168.0.116", 6379);
String key = "user";
byte[] byteKey = SerializationUtils.serialize(key);
byte[] byteValue = jedis.get(byteKey);
User user = (User) SerializationUtils.deserialize(byteValue);
System.out.println(user);
jedis.close();
}
4.3 Jedis存储一个对象到Redis,以String的形式
因为以String的形式存入一个对象,必然要用到Json,那我们需要先导入一个FastJson的依赖
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.54</version>
</dependency>
然后使用FastJson把对象转化为json的字符串,然后存入Redis
@Test
public void test5() {
Jedis jedis = new Jedis("192.168.0.116", 6379);
String key = "StrUser";
User user = new User(1, "zhang");
String jsonUser = JSON.toJSONString(user);
jedis.set(key, jsonUser);
jedis.close();
}
把对象取出
@Test
public void test6() {
Jedis jedis = new Jedis("192.168.0.116", 6379);
String key = "StrUser";
String s = jedis.get(key);
User user = JSON.parseObject(s, User.class);
System.out.println(user);
jedis.close();
}
4.4 Jedis连接池的操作
最简单的使用链接池
@Test
public void test1() {
// 指定IP地址和端口号来获取连接池
JedisPool pool = new JedisPool("192.168.0.116", 6379);
//通过链接池拿到一个jedis链接
Jedis jedis = pool.getResource();
//操作
//.......
//把链接放回连接池
jedis.close();
}
先配置连接池,再创建
@Test
public void test2() {
//设置连接池配置信息
GenericObjectPoolConfig poolConfig = new GenericObjectPoolConfig();
poolConfig.setMaxTotal(100); //最大活跃数
poolConfig.setMaxIdle(10); //最大空闲数
poolConfig.setMinIdle(5); //最小空闲数
poolConfig.setMaxWaitMillis(3000); //当连接池空了,3秒报超时
JedisPool pool = new JedisPool(poolConfig, "199.168.0.116", 6379);
//通过链接池拿到一个jedis链接
Jedis jedis = pool.getResource();
//操作
//.......
//把链接放回连接池
jedis.close();
}
4.5 Redis的管道操作
Jedis默认与Redis通讯是一次一次的,效率比较低,可以使用管道操作,使其大幅度提升效率
//常规操作
@Test
public void test3() {
long l = System.currentTimeMillis();
//1.创建连接池
JedisPool pool = new JedisPool("192.168.0.116", 6379);
//2.获取链接对象
Jedis jedis = pool.getResource();
//3.操作100000次
for (int i = 0; i < 100000; i++) {
jedis.incr("a");
}
//4.释放对象
jedis.close();
System.out.println("无管道耗时:"+(System.currentTimeMillis() - l));//无管道耗时:64986
}
//管道操作
@Test
public void test4(){
long l = System.currentTimeMillis();
//1.创建连接池
JedisPool pool = new JedisPool("192.168.0.116", 6379);
//2.获取链接对象
Jedis jedis = pool.getResource();
Pipeline pipelined = jedis.pipelined();
//3.操作100000次
for (int i = 0; i < 100000; i++) {
pipelined.incr("a");
}
//执行所有命令
pipelined.syncAndReturnAll();
//4.释放对象
jedis.close();
System.out.println("有管道耗时:"+(System.currentTimeMillis() - l)); //有管道耗时:395
}
五.Redis其他配置及集群
修改yml文件,以方便后期修改redis配置信息
version: '3.1'
services:
redis:
restart: always
image: daocloud.io/library/redis:5.0.7
container_name: redis
environment:
- TZ=Asia/Shanghai
ports:
- 6379:6379
volumes:
- ./conf/redis.conf:/usr/local/redis/redis.conf
command: ["redis-server","/usr/local/redis/redis.conf"]
5.1 Redis的AUTH
新建./conf/redis.conf 文件,该文件为redis的配置文件
# 登录密码
requirepass xxx
指令操作时,需要先验证密码
# 验证密码
AUTH xxx
使用Java代码链接数据库时,链接时没有问题,如果需要执行指令,需要先验证身份
//未使用连接池的情况下,可以直接验证密码
jedis.auth("xxx");
//使用链接池的话,可以在初始化连接池的时候,指定好密码
//1.创建连接池
GenericObjectPoolConfig poolConfig = new GenericObjectPoolConfig();
poolConfig.setMaxTotal(100); //最大活跃数
poolConfig.setMaxIdle(10); //最大空闲数
poolConfig.setMinIdle(5); //最小空闲数
//poolConfig.setMaxWaitMillis(3000); //当连接池空了,3秒报超时
JedisPool pool = new JedisPool(poolConfig, "192.168.0.116", 6379, 3000, "xxx");
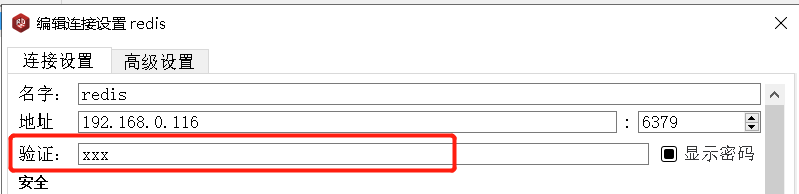
图形化界面,需要先修改链接
5.2 Redis的事物
Redis的事物不像sql那样具有原子性,开启事物后,他会吧后续的命令打包,统一发送给容器去执行,然后该成功的成功,该失败的失败,不会互相影响
- 开始事物: multi
- 输入要执行的命令 会被放在一个队列之中
- 执行事物:exec 会将队列中的事物统一执行
- 取消事物: discard 会将队列中的事物全部取消
Redis的事物如果想要发挥真正的事务管理功能的话,需要配置监听机制
在开启事物之前,先用watch命令监听一个或者多个key 如果有其他客户端修改了我监听的key,事务将自动取消操作.后续执行了事务或者取消了事务, 会自动取消监听
- 开启监听: watch key [key …]
- 关闭监听: unwatch
5.3 Redis持久化机制
默认:RDB
RDB是Redis的默认持久化机制
- RDB持久化文件,速度比较快,存储的是一个二进制文件,传输比较方便
- RDB持久化的时机
save 900 1 # 900秒内有1条key发生改变 save 300 10 # 300秒内有10条key发生改变 save 60 10000 # 69秒内有10000条key发生改变
- RDB无法保证数据的绝对安全
实现持久化:
更改配置文件的信息
# 持久化时机 save 900 1 save 300 10 save 60 10000 # 开启持久化 rdbcompression yes # 默认持久化文件名 dbfilename dump.rdb在docker-compose.yml中增加数据卷映射(可选)
volumes: - ./conf/redis.conf:/usr/local/redis/redis.conf - ./data:/data重启Redis
docker-compose down # 关闭Redis docker-compose up -d # 启动Redis shutdown save # 在Redis内执行,关闭Redis,并持久化数据
AOF:
AOF持久化机制默认是关闭的,redis官方推荐同时开启rdb和AOF,更安全,防止数据丢失
AOF持久化的速度相对RDB比较慢,存储的是一个文本文件,到了后期文件比较大,传输困难
AOF持久化时机:
appendfsync always # 没执行一个写操作,立即持久化到aof文件中 appendfsync everysec # 每秒执行一次持久化 appendfsync no # 会根据操作系统的不同,在一定时间内执行一次持久化AOF相对RDB更安全,推荐同时开启
同时开启RDB和AOF的注意事项
如果同时开启了AOF和RDB持久化,那么在Redis宕机重启后,优先使用AOF的持久化文件
如果先开启了RDB 再开启AOF 如果RDB执行了持久化,那么RDB中的内容会被AOF覆盖掉
5.4 Redis的主从架构
单机版Redis存在读写瓶颈的问题
读:11W/s
写:8.1W/s
主从架构特点:
- 写数据由主节点负责,所有的从节点都可以读取数据,但是不能写入数据
- 存在主节点单点故障的时候,就只能读不能写了
- 所有的从节点都与主节点通讯,互相之间不能通讯
version: '3.1'
services:
redis1:
image: daocloud.io/library/redis:5.0.7
restart: always
container_name: redis1
environment:
- TZ=Asia/Shanghai
ports:
- 7001:6379
volumes:
- ./conf/redis1.conf:/usr/local/redis/redis.conf
- ./data:/data
command: ["redis-server","/usr/local/redis/redis.conf"]
redis2:
image: daocloud.io/library/redis:5.0.7
restart: always
container_name: redis2
environment:
- TZ=Asia/Shanghai
ports:
- 7002:6379
volumes:
- ./conf/redis2.conf:/usr/local/redis/redis.conf
- ./data:/data
links:
- redis1:master
command: ["redis-server","/usr/local/redis/redis.conf"]
redis3:
image: daocloud.io/library/redis:5.0.7
restart: always
container_name: redis3
environment:
- TZ=Asia/Shanghai
ports:
- 7003:6379
volumes:
- ./conf/redis3.conf:/usr/local/redis/redis.conf
- ./data:/data
links:
- redis1:master
command: ["redis-server","/usr/local/redis/redis.conf"]
#从节点配置 ./conf/redis2.conf redis3.conf
relicaof master 6379
主从配置好之后,启动容器会自动搭建主从
5.5 哨兵
先修改docker-compose.yml的内容
version: '3.1'
services:
redis1:
image: daocloud.io/library/redis:5.0.7
restart: always
container_name: redis1
environment:
- TZ=Asia/Shanghai
ports:
- 7001:6379
volumes:
- ./conf/redis1.conf:/usr/local/redis/redis.conf
- ./conf/sentinel1.conf:/data/sentinel.conf #映射哨兵配置
command: ["redis-server","/usr/local/redis/redis.conf"]
redis2:
image: daocloud.io/library/redis:5.0.7
restart: always
container_name: redis2
environment:
- TZ=Asia/Shanghai
ports:
- 7002:6379
volumes:
- ./conf/redis2.conf:/usr/local/redis/redis.conf
- ./conf/sentinel2.conf:/data/sentinel.conf #映射哨兵配置
links:
- redis1:master
command: ["redis-server","/usr/local/redis/redis.conf"]
redis3:
image: daocloud.io/library/redis:5.0.7
restart: always
container_name: redis3
environment:
- TZ=Asia/Shanghai
ports:
- 7003:6379
volumes:
- ./conf/redis3.conf:/usr/local/redis/redis.conf
- ./conf/sentinel3.conf:/data/sentinel.conf #映射哨兵配置
links:
- redis1:master
哨兵可以解决主从架构的单点故障问题
# 哨兵需要后台启动
daemonize yes
# 指定Master节点的IP和端口(从)
sentinel monitor master master 6379 2
# 指定Master节点的IP和端口(主)
sentinel monitor master localhost 6379 2
#每隔多久监听一次myster是否正常
sentinel down-after-milliseconds mymaster 30000
启用哨兵
docker exec -it 8d bash #进入容器
redis-sentinel sentinel.conf #通过哨兵的配置文件,启动哨兵
redis-cli #进入Redis
5.6 集群
redis集群在保证主从加哨兵基本功能外,能提高redis存储效率的能力
Redis特点:
- Redis集群是无中心的
- Redis集群有一个ping-pang机制(有去要有回)
- 投票机制,Redis集群必须是2N+1个,否则没有办法有效投票
- Redis集群中默认分配了16384个hash槽,在存储数据是,就会将key进行crc16的算法,并且对16384取余,来确定此Key应该存储在哪个节点中
- 每一个节点都在维护着一定数量的hash槽
- 为了保障数据的安全性,每个集群的节点至少要跟着一个从节点,这个从节点,只负责数据的备份,如果主节点挂掉了,从节点就变成主节点
- Redis集群中如果有超过半数的节点宕机之后,Redis集群就瘫痪了
集群的搭建
# Docker-compose.yml
version: "3.1"
services:
redis1:
image: daocloud.io/library/redis:5.0.7
restart: always
container_name: redis1
environment:
- TZ=Asia/Shanghai
ports:
- 7001:7001
- 17001:17001
volumes:
- ./conf/redis1.conf:/usr/local/redis/redis.conf
command: ["redis-server","/usr/local/redis/redis.conf"]
redis2:
image: daocloud.io/library/redis:5.0.7
restart: always
container_name: redis2
environment:
- TZ=Asia/Shanghai
ports:
- 7002:7002
- 17002:17002
volumes:
- ./conf/redis2.conf:/usr/local/redis/redis.conf
command: ["redis-server","/usr/local/redis/redis.conf"]
redis3:
image: daocloud.io/library/redis:5.0.7
restart: always
container_name: redis3
environment:
- TZ=Asia/Shanghai
ports:
- 7003:7003
- 17003:17003
volumes:
- ./conf/redis3.conf:/usr/local/redis/redis.conf
command: ["redis-server","/usr/local/redis/redis.conf"]
redis4:
image: daocloud.io/library/redis:5.0.7
restart: always
container_name: redis4
environment:
- TZ=Asia/Shanghai
ports:
- 7004:7004
- 17004:17004
volumes:
- ./conf/redis4.conf:/usr/local/redis/redis.conf
command: ["redis-server","/usr/local/redis/redis.conf"]
redis5:
image: daocloud.io/library/redis:5.0.7
restart: always
container_name: redis5
environment:
- TZ=Asia/Shanghai
ports:
- 7005:7005
- 17005:17005
volumes:
- ./conf/redis5.conf:/usr/local/redis/redis.conf
command: ["redis-server","/usr/local/redis/redis.conf"]
redis6:
image: daocloud.io/library/redis:5.0.7
restart: always
container_name: redis6
environment:
- TZ=Asia/Shanghai
ports:
- 7006:7006
- 17006:17006
volumes:
- ./conf/redis6.conf:/usr/local/redis/redis.conf
command: ["redis-server","/usr/local/redis/redis.conf"]
#redis.conf
# 指定Redis的端口号
port 7001
#开启Redis集群
cluster-enabled yes
#集群信息的文件
cluster-config-file nodes-7001.conf
# 集群的对外IP:
cluster-announce-ip 192.168.0.116
# 集群对外的端口号
cluster-announce-port 7001
#集群总线的端口
cluster-announce-bus-port 17001
启动集群
redis-cli --cluster create 192.168.0.116:7001 192.168.0.116:7002 192.168.0.116:7003 192.168.0.116:7004 192.168.0.116:7005 192.168.0.116:7006 --cluster-replicas 1
# 启动集群 ,创建根据IP:端口号 后面跟着每台后面跟着几台从节点

使用集群:
redis-cli -h 192.168.0.116 -p 7001 -c
# 进入节点 -c 是为了让它自动选择操作的集群节点
注意事项:
- Redis集群启动前必须保证Redis的运行环境是干净的,不能有数据
5.7 Java链接Redis集群
Jedis有一个集群类JedisCluster 这个类的构造方法是要传入一个Set集合,集合内存储了HostAndPort类,也就是集群的Ip和端口信息,所以我们首先要创建一个set集合,把IP和端口号信息添加进去,然后在用set集合创建集群对象
Set<HostAndPort> nodes = new HashSet<>();
nodes.add(new HostAndPort("192.168.0.116", 7001));
nodes.add(new HostAndPort("192.168.0.116", 7002));
nodes.add(new HostAndPort("192.168.0.116", 7003));
nodes.add(new HostAndPort("192.168.0.116", 7004));
nodes.add(new HostAndPort("192.168.0.116", 7005));
nodes.add(new HostAndPort("192.168.0.116", 7006));
JedisCluster jedisCluster = new JedisCluster(nodes);
//存:
jedisCluster.set("key","value");
//取:
String value = JedisCluster.set("key");
六. Redis的常见问题
6.1 Key的生存时间到了,Redis会立即删除这个key吗?
不会:Redis的删除机制:
定期删除:
Redis每隔一段时间就回去查看Redis设置了过期时间的key,一百毫秒查看3个key
惰性删除
如果当你查询一个已经过了生存时间的key时,Redis回先查看当前kkey的生存时间是否已经到了,如果到了的话,就会直接删除
6.2 Redis的淘汰机制
在Redis内存已经满的时候,如果还需要添加数据,则会执行淘汰机制
指定淘汰机制的方式:
maxmemory-policy 具体策略设置Redis的最大内存:
maxmemoty <bytes>
八种淘汰机制:
volatile-lru:
在内存不足时,Redis会再设置过了生存时间的key中,删除一个最近最少使用的key
allkeys-lru:
在内存不足时,在所有key中,删除一个最近最少使用的key
volatile-lfu:
在内存不足是,在设置过了生存时间的key中,删除一个最近最少频次使用的key
allkeys-lfu
在内存不足时,在所有key中删除一个最近最少频次使用的key
volatile-random:
在内存不足是,在设置过了生存时间的key中,随机删除一个key
allkeys-random:
在内存不足时,在所有key中随机删除一个key
volatile-ttl:
在内存不足时,在设置了生存时间的key中,删除一个生存时间最少的key
noeviction:(默认):
在内存不足时,报错
6.3 缓存问题
-
缓存穿透
客户端通过Tomcat发送查询数据,会首先经过Redis数据库查询,如果Redis数据库中没有,会去后台的数据库中查询,如果后台的数据库也没有,就会返回查询失败,但是如果同时有非常多的请求同时做了这种查询,可能会导致Redis和后台数据库全部宕机,这种情况称之为缓存穿透
如何解决?
- 把数据库中的数据,允许被查询到的,整个范围区间映射到Redis,等于告诉他,只有这里面有的我服务器才有,这里面没有的你就不用来问了,这样,如果再次接到这种大批量的非法查询的时候,Redis就可以把这种请求拒之门外
- 举例:如果是数字整形的话,就可以直接设定一个范围,如果不是整形,就可以创建一个set集合
- 再一个,获取用户端的IP地址,然后将IP地址添加访问限制
-
缓存击穿
当缓存中的热点数据突然到期了,造成了大量的请求都去访问数据库了,造成数据库宕机,这种情况称之为缓存击穿
如何解决?
- 在访问缓存中,发现没有的时候,为请求添加一把锁,只允许几个请求去访问数据库,避免数据库宕机(后面会有分布式锁)
- (不推荐)去掉热点数据的生存时间
-
缓存雪崩
当大量缓存同时到期,造成大量的请求同时去访问数据库,导致数据库宕机,这种情况称之为缓存雪崩
如何解决?
- 将缓存中的数据的生存时间 ,设置为30-60分钟的一个随机值,确保不会同时全部到期
-
缓存倾斜
热点数据放在了Redis的一个节点上,导致单独节点无法承受大量的请求,导致宕机,称之为缓存倾斜
如何解决?
- 扩展主从架构,搭建大量的从节点,缓解Redis的压力
- 可以在Tomcat中做JVM缓存,在查询Redis之前,先去查询Tomcat中的缓存
ey
volatile-random:
在内存不足是,在设置过了生存时间的key中,随机删除一个key
allkeys-random:
在内存不足时,在所有key中随机删除一个key
volatile-ttl:
在内存不足时,在设置了生存时间的key中,删除一个生存时间最少的key
noeviction:(默认):
在内存不足时,报错
6.3 缓存问题
-
缓存穿透
客户端通过Tomcat发送查询数据,会首先经过Redis数据库查询,如果Redis数据库中没有,会去后台的数据库中查询,如果后台的数据库也没有,就会返回查询失败,但是如果同时有非常多的请求同时做了这种查询,可能会导致Redis和后台数据库全部宕机,这种情况称之为缓存穿透
如何解决?
- 把数据库中的数据,允许被查询到的,整个范围区间映射到Redis,等于告诉他,只有这里面有的我服务器才有,这里面没有的你就不用来问了,这样,如果再次接到这种大批量的非法查询的时候,Redis就可以把这种请求拒之门外
- 举例:如果是数字整形的话,就可以直接设定一个范围,如果不是整形,就可以创建一个set集合
- 再一个,获取用户端的IP地址,然后将IP地址添加访问限制
-
缓存击穿
当缓存中的热点数据突然到期了,造成了大量的请求都去访问数据库了,造成数据库宕机,这种情况称之为缓存击穿
如何解决?
- 在访问缓存中,发现没有的时候,为请求添加一把锁,只允许几个请求去访问数据库,避免数据库宕机(后面会有分布式锁)
- (不推荐)去掉热点数据的生存时间
-
缓存雪崩
当大量缓存同时到期,造成大量的请求同时去访问数据库,导致数据库宕机,这种情况称之为缓存雪崩
如何解决?
- 将缓存中的数据的生存时间 ,设置为30-60分钟的一个随机值,确保不会同时全部到期
-
缓存倾斜
热点数据放在了Redis的一个节点上,导致单独节点无法承受大量的请求,导致宕机,称之为缓存倾斜
如何解决?
- 扩展主从架构,搭建大量的从节点,缓解Redis的压力
- 可以在Tomcat中做JVM缓存,在查询Redis之前,先去查询Tomcat中的缓存














 66
66











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









