







 本文介绍了如何通过解析foobar2000官网获取全部插件的下载链接,包括解析插件介绍页网址,再进一步获取下载链接的过程。由于网络问题,实际运行可能无法获取所有链接,但提供了完整的自动化下载代码。
本文介绍了如何通过解析foobar2000官网获取全部插件的下载链接,包括解析插件介绍页网址,再进一步获取下载链接的过程。由于网络问题,实际运行可能无法获取所有链接,但提供了完整的自动化下载代码。
foobar2000是音乐爱好者最喜爱的音频播放器之一。用户可以根据实际需求为它增加插件来增强使用体验。而foobar2000官网提供了上百个插件供用户下载,但是如果要全部下载则需要花费大量时间,所以在这里我提供一种思路来下载foobar2000的全部插件。
基本思路是要获取插件的全部下载链接。
首先解析
http://www.foobar2000.org/components
发现有形似
<a href="/components/view/foo_input_vio2sf">...</a>
这样的代码
而其中
/components/view/foo_input_vio2s
就是我们要的网址
所以首要目标是获取全部这样的地址
import requests
from bs4 import BeautifulSoup
with open(r'foobar2000_components.txt','w',encoding='utf-8') as fp:
url='http://www.foobar2000.org/components'
r=requests.get(url)
soup=BeautifulSoup(r.text,'lxml')
for item in soup.find_all('a'):
k=item.get('href'
fp.write(k+'\n')
获取的文本如下:
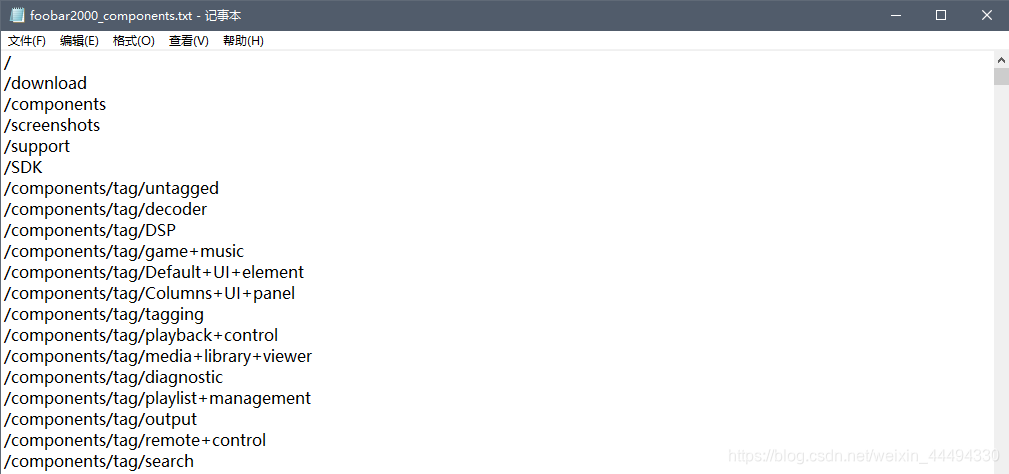 额,好像多了点东西
额,好像多了点东西
加一个判断语句
import requests
from bs4 import BeautifulSoup
with open(r'foobar2000_components.txt','w',encoding='utf-8') as fp:
url='http://www.foobar2000.org/components'
r=requests.get(url)
soup=BeautifulSoup(r.text,'lxml')
components=[]
for item in soup.find_all('a'):
k=item.get('href')
if  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









