






使用urllib.request.urlopen来请求网页的数据,并用read()去读取数据时报出以下错误。
response = urllib.request.Request(url=url, headers=headers)
response = urllib.request.urlopen(response)
html = response.read().decode('utf-8')
print(html)

经查资料了解到该错误是出现了无法用utf-8格式解析的内容,此时应该从浏览器中获取到该网页的响应头。
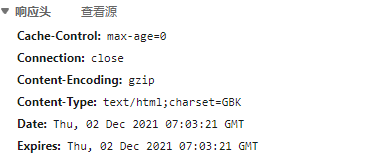
在响应头中找到Content-Type参数,在这个参数的值中找到网页的编码格式,如上图是“GBK”,将代码的解码格式改成对应的格式,就可以解决这个问题。
response = urllib.request.Request(url=url, headers=headers)
response = urllib.request.urlopen(response)
html = response.read().decode('GBK')
print(html)
当然这只是其中的一个解决方法。















 1725
1725











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









