






 博客围绕Linux公共服务器.cache缓存过大问题展开。介绍了.cache目录用于存储应用程序运行时缓存文件,目的是提升性能,但可能需清理以释放磁盘空间。还给出清理方法,包括进入路径、查看文件、删除对应缓存等。
博客围绕Linux公共服务器.cache缓存过大问题展开。介绍了.cache目录用于存储应用程序运行时缓存文件,目的是提升性能,但可能需清理以释放磁盘空间。还给出清理方法,包括进入路径、查看文件、删除对应缓存等。
【linux】公共服务器如何清理过多的.cache缓存.
【先赞后看养成习惯】求关注+点赞+收藏😀
问题叙述:用的公共服务器,管理员反映.cache缓存过大,让我清理一下
.cache介绍:在Linux系统中,.cache目录通常用于存储应用程序运行时生成的缓存文件。这些文件包括临时文件、预览图像、下载文件等。.cache目录的目的是帮助提高应用程序的性能,因为它们可以避免重复生成或下载相同的数据。但是,.cache目录的大小可能会逐渐增长,因此有时候需要清理其中的内容来释放磁盘空间。由于缓存文件通常可以重新生成,因此删除它们通常不会对系统造成影响。
Linux 的 cache 究竟是怎么一回事
清理方法:
- 进入.cache路径
cd .cache
- 查看缓存文件
du -sh *
- 删除对应缓存文件
rm -r filename
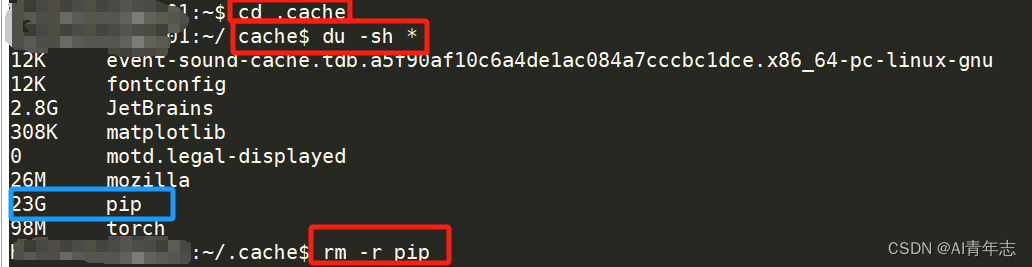
- 删除完我们查看一下,Pip缓存文件已经删除



















 1025
1025

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











