







文章目录
前言
【读书笔记】【WebKit 技术内 幕(一)】浏览器架构与浏览器内核;chromium、webkit和blink的渲染过程;chromium、webkit的架构与代码结构;webkit2架构
Something great
- parser: 解析器
- AST :(Abstract Syntax Tree,抽象语法树)
- openGL :(Open Graphics Library,开放图形库);一个大部分平台都支持的 底层图形库的 API 标准。
- DirectX:(Direct eXtension,简称DX)微软的多媒体API。
- 沙箱(sandBox):操作系统对 进程的可访问的内存地址所做的限制。
- 渲染进程被 Sandbox 隔离,网页 web 代码内容必须通过 IPC 通道才能与浏览器内核进程通信,通信过程会进行安全的检查。
- 沙箱运行:渲染器在单独的进程中运行,通过沙箱限制其对系统资源(文件、网络、显示、击键)的访问,而须通过父浏览器进程访问
- 插件:浏览器的插件用于显示网页特定内容
- 扩展:浏览器的扩展用于增加浏览器新功能的软件或压缩包
- inspector:(web inspector,调试页面))
- DOM:(Document Object Model,文档对象模型)
- XSS(cross site security)
- CSS:(cascading style sheet,级联样式表)
第4章 资源加载和网络栈
- 使用网络栈,下载网页和网页中的资源是渲染引擎工作的第一步。
Webkit 资源加载
- HTML支持的资源主要包括:HTML、js、css、图片、SVG、 CSS Shader、视频、音频和字幕、字体文件、XSL样式表等。
- webkit 将上述资源用不同的类来表示,其公共基类为
CachedResource类。HTML文本类型为MainResource类,对应的资源类为CachedRawResource。- 其中
cached是因为 引入的缓存机制,以提高资源使用效率。- 缓存机制 : 即访问资源时,先在缓存中查找相应资源
- 如果找到了,Webkit 就取出使用;
- 如果没找到,Webkit 就创建一个新的
CachedResource子类对象(根据不同资源),并向服务器发送请求,获取资源后将其设置到该资源类对象中,以便缓存后下次使用。
- 缓存机制 : 即访问资源时,先在缓存中查找相应资源
- 其中
- 缓存有涉及到资源的生命周期和失效机制。
- Webkit 有三种类型的加载器:
- 针对每种资源类型的特定加载器。仅加载某一种资源,如
ImageLoader、FontLoader。 - 缓存机制的资源加载器。属于HTML的文档对象。
CacheResourceLoader类,所有特定加载器都共享它来查找并插入缓存资源。 - 通用资源加载器,
ResourceLoader类,从网络、文件系统中只负责获得资源的数据。被所有特定资源加载器共享,属于CacheResource类。 - 资源加载过程:
- 解析HTML到特定资源(URL)元素的属性时,Webkit 创建一个
ImageLoader对象来加载该资源。 -

- 网络加载资源时,通常是异步执行的,以防止阻碍当前Webkit 的渲染过程。
- 但是JS资源会阻碍渲染过程,这时Webkit 会启动另一个线程遍历后面的HTML 网页,收集需要的资源URL,然后再发起请求,避免阻塞。
- 解析HTML到特定资源(URL)元素的属性时,Webkit 创建一个
- 针对每种资源类型的特定加载器。仅加载某一种资源,如
- webkit 将上述资源用不同的类来表示,其公共基类为
- 资源的生命周期:
- 缓存中的资源采用LRU算法替换。【C++】【缓存替换策略】【LRU】【LFU 】【FIFO】LRU算法C++实现,并测试;
- 当资源被加载,通常会被放入缓存中,然后有其他资源被替换掉。
- Webkit 采用发送消息确认资源是否需要被更新,不需要更新就使用缓存中资源,需要更新就重新获取资源。
- HTTP请求发给服务器后,服务器根据信息判断,如果没有更新就回送状态码304,表示不需要更新。
- 否则Webkit 申请下载最新资源。
- 可以在浏览器的开发者工具中,打开/关闭缓存:
Disable Cache,然后可以看到对应资源的状态码(200或者304)【学习笔记】【计算机网络】【HTTP 学习】HTTP 的版本区别;帧结构;瓶颈与解决方案; - 设置取消缓存的调用栈:

- 可以在浏览器的开发者工具中,打开/关闭缓存:
- 缓存中的资源采用LRU算法替换。【C++】【缓存替换策略】【LRU】【LFU 】【FIFO】LRU算法C++实现,并测试;
Chromium多进程资源加载
- 不同移植对获取资源有不同的实现,Chromium采用多进程的资源加载机制。
-

- 其中renderer进程在网页加载过程中需要获取资源。
- 出于安全性(沙箱模型事,renderer进程没有权限获取资源)和效率的考量,资源获取实际上是交给browser 进程完成的。
- renderer 通过IPC 将任务交给browser 进程,browser 进程有权利从网络或本地获取资源。
- browser 进程中,如图所示,有
ResourceMessageFilter用于过滤renderer进程消息。- 将消息给
ResourceDispatcherHostImpl,由其创建ResourceLoader。 ResourceLoader是chrmoium 浏览器的实际资源加载类,负责向网络发起请求、接收认证请求、请求的恢复管理等工作。- 这些工作有专门的类负责,
ResourceLoader用于统一管理。 URLRequest类负责从网络或本地文件读取信息,负责建立网络连接、发送请求数据、接受回复数据等。
- 这些工作有专门的类负责,
- 将消息给
- 出于安全性(沙箱模型事,renderer进程没有权限获取资源)和效率的考量,资源获取实际上是交给browser 进程完成的。
-
- 资源共享:
- 资源统一交给 browser 进程处理,使得网页间的资源共享容易。
- 多个renderer进程、renderer进程的请求多,使得browser进程需要调度器,即chromium中的
ResourceScheduler。ResourceScheduler根据URLRequest的标记和优先级来调度,URLRequest中有ID来识别是哪个renderer进程。
- 多个renderer进程、renderer进程的请求多,使得browser进程需要调度器,即chromium中的
- 资源统一交给 browser 进程处理,使得网页间的资源共享容易。
Chromium 网络栈
- webkit 的资源加载交给移植部分实现,只有一部分的HTTP 消息头、MIME消息、状态码等信息的描述和处理。
- chromium 的
src/net中包括了其网络栈主要部分 ,例如HTTP协议、DNS解析、SPDY、QUIC等。 - 网络栈调用过程:
URLRequest到 Socket 类的调用过程:
- 这里chromium使用了工厂模式,用于支持自定义的
scheme处理。
- 套接字的建立:
- chromium 的套接字是
SteamSocket抽象类,在POSIX 和windows系统上有着不同的实现。 SteamSocket有个子类SSLSocket用于支持SSL机制。-

- chromium 的套接字是
- DNS部分具体调用的是
HostResolvverImpl类的getaddrinfo()函数,该函数是个阻塞式函数,chromium 使用单独线程处理它。
- 磁盘本地缓存:
- 资源是有时效性的,需要有相应退出机制解决这个问题。
- chromium 主要有两个类:
Backend、Entry。-
Backend表示整个磁盘缓存,表示的是缓存表。Entry表示的是表项。 -
每个项由URL作为关键字唯一确定。
-

-
索引地址表保存各个表项对应索引地址。该索引文件直接将文件映射到内存地址。
-
chromium 使用LRU算法回收表项。
-
- cookie 机制:
- cookie 包括关键字和值,基于安全性考虑,一个网页的cookie 只能被该网页访问。
- cookie 分为会话型cookie和持续性cookie。
- 前者浏览器退出时清楚在内存中的cookie,不设置失效时间。
- 后者浏览器退出时仍然保留cookie 内容,需要设置失效时间,有效期内每次访问cookie所属域,都需要将cookie发送给服务器,让服务器有效追踪用户行为。
- chromium的cookie 中
CookieMonster作为cookie管理者用于实现CookieStore接口、报高各种cookie 事件、作为cookie对象的集合。SQLitePersistentCookieStore负责实际的存储动作。
- cookie 分为会话型cookie和持续性cookie。
- cookie 包括关键字和值,基于安全性考虑,一个网页的cookie 只能被该网页访问。


- 安全机制:chromium 支持一种新标准:HSTS(HTTP Strict transport security)
- 该协议让网络服务器生命他只支持HTTPS,所以浏览器发送基于HTTPS 的连接和请求。
- 高性能网络栈:
- DNS预取和TCP预连接:基于chromium 的 Pridictor 机制实现。
- DNS 需要60~120ms,TCP握手也几十毫秒。
- DNS预取:
- 提前解析网页中的超链接、输出地址匹配时,DNS预取已经解析了。
- 通过使用OS的DNS机制,不阻碍当前网络栈的工作,每个域名用一个线程处理。
- TCP预连接:
- 和DNS预取一致,预测要点击的超链接和输入的地址(当候选项和输入地址很匹配),也开始尝试TCP连接。
- HTTP 管线化:
- 通过将多个HTTP请求一次性提交给服务器,无需等待服务器回复,因为可能将多个HTTP请求填充在一个TCP数据包中。
- 因为传输较少的TCP包,减少了网络负载。
- 需要服务器的支持。管线机制需要通过永久连接完成。
- SPDY:
- SPDY 协议是一种新的会话层协议,定义在HTTP 和TCP协议之间.
- 核心思想是多路复用,用一个连接传输一个网页中众多资源。
- 提高了TCP连接利用率,减少了TCP连接维护成本。
- SPDY可以调整资源请求的优先级,如JS优先级高,优先回复。
- 服务器端只需要插入SPDY协议的解释层,从SPDY 消息头中获取各个资源的HTTP头即可。
-

- SPDY 协议是一种新的会话层协议,定义在HTTP 和TCP协议之间.
- QUIC:
- 用于改进UDP 数据协议的能力,解决传输层传输效率问题,并提供数据加密。
- SPDY可以运行在QUIC之上。
chrome://net-internals/#events可以看到chromium 提供用户友好的网络信息工具。
- DNS预取和TCP预连接:基于chromium 的 Pridictor 机制实现。
第5章 HTML解释器和DOM模型
DOM模型 & DOM树
- HTML 解释器:将从网络或本地文件获取的字节流,转成内部表示结构:DOM树。
- DOM标准: 文档对象模型)
- DOM定义的是一组与平台、语言无关的接口。
- 使用DOM表示的文档被描述成一个树形结构。
- DOM以面向对象的方式描述文档。
- 使用JS 可以访问、创建、删除、修改DOM结构,目的是动态的改变HTML文档结构。
- DOM规范对文档具体表示方法没有限制,只是定义了应用程序编程接口。
- DOM树状表示为普遍的方式。
- DOM定义的是一组与平台、语言无关的接口。
- DOM树结构模型:
- DOM结构构成的基本要素是节点,文档的DOM结构由层次化的节点组成。
- 整个文档是一个节点,为文档节点
- HTML 标记(tag)也是一种节点,为元素节点。还有如属性节点等。。
- DOM结构构成的基本要素是节点,文档的DOM结构由层次化的节点组成。
- DOM树:
- DOM节点和子节点被定义后,将节点按照树结构组织起来表示一个文档。
HTML解释器 —— ***
- HTML解释器:将网络或本地获取的HTML网页和资源从字节流解释成DOM树结构
- 解释过程:
-

-
字节流经过解码后为字符流,通过词法分析器解释成词语(token),经过语法分析器构建成节点,最后节点被组建成一颗DOM树。
-

-

- 词法分析:
- 词法分析前,解释器通过检查网页内容使用的编码格式,选择合适的解码器,将字节流转换成特定格式的字符串。
- 词法分析由
HTMLTokenizer类完成,他是个状态机,输入字符串,输出一个个的词语。
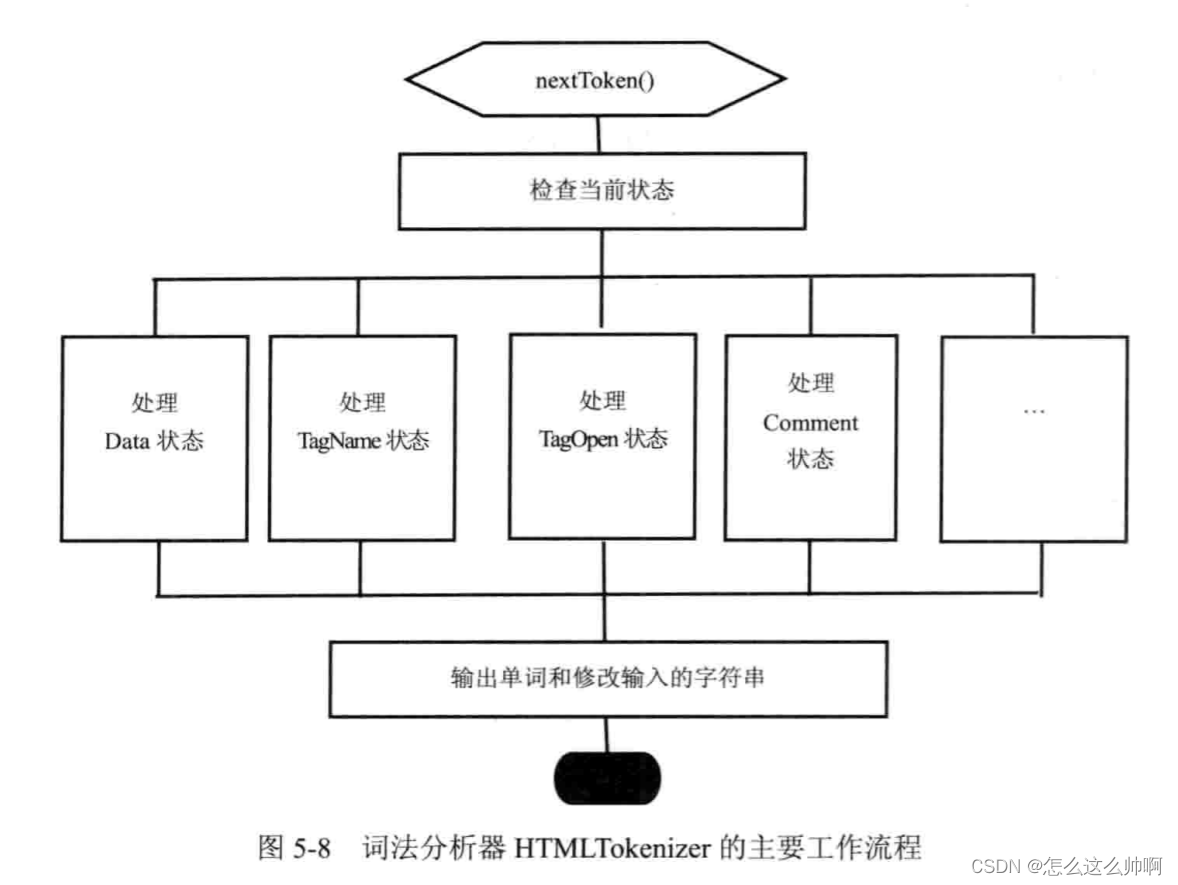
- XSSAuditor 验证词语:
- 词语生成后,经过XSSAuditor 验证词语流(token stream),XSS(cross site security)
- 对于XSS的安全机制,被解析的词语可能阻碍某些内容进一步执行,XSSAuditor 类负责过滤这些被阻止的内容,只有通过的词语才会作后面的处理。
- 词语到节点:
- 经过词法分析器解释之后的词语随之被XSSAuditor 过滤, 没有被阻止的词语被webkit用来构建DOM节点。
- 由
HTMLTreeBuilder类的constructTree函数实现。
- 节点到DOM树:
- ```HTMLConstructSite` 类完成从节点到DOM树的构建。
- 因为HTML文档的tag有开始和结束标记,所以可以用栈来构建。
- Node类是其他类的基础,元素和文档对应的类是
HTMLElement、HTMLDocument。 
- 网络基础设施:(杂、没看懂)
- 下图描述了webkit 中用于表示网页的一些基础设施类。

- webcore 类是不同webkit移植所共享的。
- 移植部分是移植实现使用的接口类。webview和webframe作为chromium表示网页和网页框的接口类。
- 线程化解释器:
- chrmoium 的renderer 进程使用单独的线程,用于处理HTML 文档的解释任务。
- 因为DOM树只能在渲染线程上创建和访问,但是将字符串到词语这个阶段可以交给单独线程来做。
- chrmoium 的renderer 进程使用单独的线程,用于处理HTML 文档的解释任务。
- JS 的执行:
- HTML解释器工作时,可能有JS代码需要执行,发生在将字符串解释成词语之后,创建节点时。
- webkit 将DOM树创建过程需要执行的JS代码交给
HTMLScriptRunner类实现,利用JS引擎执行Node 节点中包含的代码。- 因为JS代码可能调用
document.write()修改文档结构,所以JSdiamagnetic执行会阻碍后面节点的创建,也会阻止后续资源下载。如下图所示,通过两种改进 可缓解。 
- webkit可能使用预扫描、预加载机制实现资源的并发下载,而不被JS执行所阻碍。
- 因为JS代码可能调用
DOM的事件机制 —— ***
- 事件的处理机制很重要。
- 事件在工作时,使用两个主体:事件、事件目标。
- 每个事件都有属性标记该事件的事件目标,当事件到达事件目标(如一个元素节点),就会触发调用这个目标上注册的监听者。
- DOM定义了
EventTarget接口,包括注册、移除监听者,分发事件等。
- DOM定义了
- 事件处理最重要的是事件捕获、事件冒泡。
- 当渲染引擎接收到一个事件,会通过
HitTest检查哪个元素是直接的事件目标。事件会经过自顶向下和自底向上的两个过程。- 事件的捕获是自顶向下的。 事件可以在这传递过程中被捕获,只需要在注册监听者是设置相应参数即可。
- 事件的冒泡过程是从下向上的顺序。

- 当渲染引擎接收到一个事件,会通过
- webkit 事件处理机制:
- DOM的事件分很多种,和用户相关的是UIEvent。
- 基于webkit 的浏览器事件处理过程,首先做HitText,查找事件发生处的元素,检测该元素有无监听者。
- 当发现有监听者,浏览器将事件传给webkit,最后调用JS引擎触发监听者函数。(中断回调)
- DOM的事件分很多种,和用户相关的是UIEvent。
- 示例代码中,单机网页中图片时,浏览器在控制台输出:“onBoby”、“onImg”和“onDiv”

影子(Shadow)DOM
- 影子(Shadow)DOM:
- 当使用HTML开发的控件,将其组成一颗DOM树的子树,这样的一个HTML控件可以到处被使用。
- 这样使得每个使用控件的地方都知道这个子树结构,暴露出来就会被无意修改。
- 于是将其内部节点信息封装起来,又能将这些节点渲染出来,就是影子DOM。
- 下述结构对应DOM树和
div元素包含的一个影子DOM子树。
- 使用JS 访问HTML文档和DOM树,不能直接访问到影子DOM子树的节点,只能通过特殊的接口方式。
- HTML5 支持的很多特性,如视频、音频等,也是由很复杂的控制界面组成,也是HTML编写。但是无法找到对应节点,也是使用的影子DOM的思想。
- 影子DOM子树在整个网页DOM树中不可见,事件的处理:事件需要包含事件目标,这个目标不是不可见的DOM节点,是包含影子DOM子树的节点对象。 事件的捕获逻辑并没有变。
- 下述结构对应DOM树和
- 下属代码展示了影子DOM如何被使用。

- 网页包含了
div元素。JS代码使用该元素创建了一个影子DOM子树的根节点。- 在该根节点下加入了两个子女,图片元素 和 包含文本的
div元素
- 在该根节点下加入了两个子女,图片元素 和 包含文本的
- 网页包含了
第6章 CSS解释器和样式布局
- CSS 为了将网页的内容和内容的展示方式分离。
CSS基本功能
- CSS可以采用内部样式表、外部样式表( 通过link引用)。
- 样式来源有三种类型:网页开发者编写的样式信息、网页读者设置的样式信息、浏览器内在默认样式。
- 这里使用了绝对定位、背景与字体的设置。
- 样式来源有三种类型:网页开发者编写的样式信息、网页读者设置的样式信息、浏览器内在默认样式。

- 样式规则:
- 通常CSS文档包含一系列的样式规则:

- 这里包括了规则头、规则体。
- 规则头由一个或多个选择器组成。
- 规则体由一个或多个样式声明组成。每个样式声明由样式名和样式值构成。
- 这里包括了规则头、规则体。
- 元素通常匹配优先级更高的规则
- 选择器描述越具体,优先级越高。
- 通过选择器,CSS能精确控制 HTML页面中任意一个或多个元素的样式属性
- 选择器由多种,包括了标签选择器、类型选择器、ID选择器等等。
- 标准有两个JS接口
QuerySelector、QuerySelectorAll,用于将CSS的选择器输入,获得对应DOM节点。
- 框模型:
- 框模型包括四个部分:外边距
margin、边框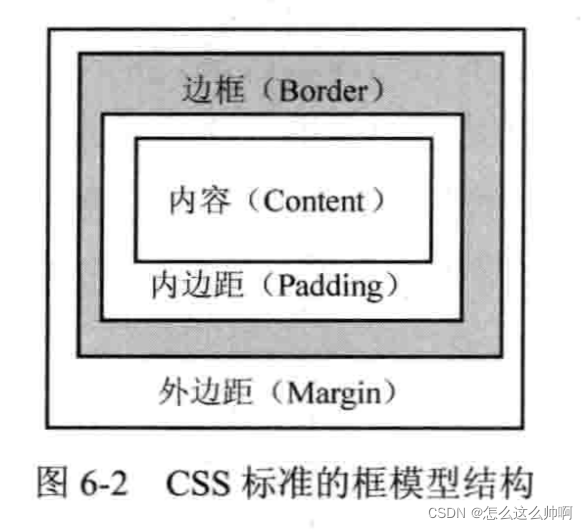 border、内边距padding、内容content。- HTML网页中,可视元素布局都是按照框模型设计。
-


- 框模型包括四个部分:外边距
- 包含块(Containing Block)模型:
- webkit 计算元素箱子位置和大小时,需要计算该元素和另一个矩形区域的相对位置。 该矩形区域为该元素的包含块。
- 根元素包含块为初始包含块,大小为可视区域。
- 对于其他位置属性为
static、relative的元素,其包含块为最近祖先 箱子模型中的内容(content)。 - 位置属性为
fixed,脱离HTML文档,固定于特定位置。 absolute,其包含块由最近含有属性absolute、relative、fixed的祖先决定。
- 实例中的包含块就是其父亲的内容区域,其框模型就是该区域上进行计算产生的。
- webkit 计算元素箱子位置和大小时,需要计算该元素和另一个矩形区域的相对位置。 该矩形区域为该元素的包含块。
- CSS样式属性:
- 主要包括:背景、文本、字体、列表、表格、定位。
- CSSOM(CSS Object Model):
- CSSOM :在DOM一些节点接口中,加入获取CSS属性的JS接口。让JS动态操作CSS样式。
- DOM提供了接口让JS修改HTML文档,CSSOM提供接口让JS 获得和修改CSS设置的样式信息。
- 接口为
CSSStyleSheet。
- CSSOM :在DOM一些节点接口中,加入获取CSS属性的JS接口。让JS动态操作CSS样式。

- CSS设置中,选择器越具体优先越高
- 控制台通过JS:
document.styleSheets可以查看两个CSSStyleSheet对象,可以看到其属性和属性值。 - 还可以 :
document.styleSheets[0].disabled = true关闭对应样式表等操作。
- 控制台通过JS:
- CSS设置中,选择器越具体优先越高
CSS解释器和规则匹配 —— ***
-
样式的WebKit表示类 :
- 无论内嵌、外部CSS,web看i他都是用
CSSStyleSheet类表示。 
- 这些类的继承关系
- 无论内嵌、外部CSS,web看i他都是用
-
解释过程 :
- CSS解释:从CSS字符串到渲染引擎的内部规则表示。

- 由
CSSParser负责,解释工作由CSSGrammer.y.in完成,其时Bison 的输入文件,Bison 是一个生成解释器的工具。- webkit渲染引擎会为每个网页设置一个默认样式。
-
样式规则匹配:
- DOM节点建立后,Webkit 会为其中一些节点选择合适的样式信息。
StyleResolver为DOM元素节点匹配样式,根据元素信息(签名、类别等),从样式规则中查找最匹配的规则,将样式信息保存到新建的RenderStyle对象中。RenderStyle对象被RenderObject类管理和使用。-

- 最后webkit 对规则排序,从高优先级规则中选取。
- DOM节点建立后,Webkit 会为其中一些节点选择合适的样式信息。
-
样式匹配实践:
- chrome 开发者工具的
element,选择对应元素, 可以在style总看到对应元素匹配结果样式(computed style)。- 可以直接修改属性,影响布局。
- 不同属性可能来自不同规则。
- 被划线的部分主要因为:属性设置错误、被更高优先级的规则属性覆盖。
- chrome 开发者工具的
-
JavaScript 设置样式:
- 使用CSSOM接口更改属性。webkit 中需要JS引擎和渲染引擎协同完成。
- JS引擎调用设置属性值加粗样式的公共处理函数,然后该函数调用属性值解析函数。 (如CSS的JS 绑定函数)。
- 然后Webkit 将解析后信息设置到元素属性的样式中。 然后设置标记标明元素需要重新计算样式,触发重新布局。
- 使用CSSOM接口更改属性。webkit 中需要JS引擎和渲染引擎协同完成。

WebKit布局
-
webkit 创建
RenderObject对象之后,每个对象不知道自己的位置、大小等信息,Webkit 根据框模型计算他们的位置、大小等信息。这个过程叫布局计算或排版。- 主要包括
Frame类,用于表示网页的框结构,每个框都有一个FrameView类,用于表示框 的视图结构。layout用于计算布局。-

- 布局计算分为对整个
RenderObject树的计算、对RenderObject树的某个子树的计算。
- 主要包括
-
布局计算:
- 布局计算是个递归计算 子节点位置、大小等信息的过程。
- 主要逻辑由
RenderObject类的layout函数完成。 -
- 如果页面元素所确定宽高超过了布局容器包含块做能提供的宽高,且overflow 属性为 visible或auto,webkit 会提供滚动条保证显示内容。
- 主要逻辑由
- CSS 布局计算 是以包含块、框模型为基础,CSS也规定行布局形式,即内联元素。
- 布局计算是个递归计算 子节点位置、大小等信息的过程。

第7章 渲染基础
RenderObject树
- Webkit 的布局计算,使用RenderObject 树,并将计算结果保存到RenderObject 树中。
- RenderObject 基础类:
- 下图代码,对应的DOM树和RenderObject树 如右边所示。
- 下图代码中,
canvas为HTML5元素,其中JS代码为canvas创建一个WebGL (3D绘图技术)的上下文对象(Context)。类似OpenL或OpendGLES的上下文概念。
- 下图代码中,
- 下图代码,对应的DOM树和RenderObject树 如右边所示。

- DOM树中,某些节点用户不可见,为 “非可视化节点”,如上述代码中 ”script“、“head”等。
- 其他的例如“”body 、“div”、“canvas” 等,这些节点可以显示一块区域,如文字、图片等,称为 “可视节点”。
- 对于 “可视节点”, webkit 为其绘制到最终网页结果中,会建立对应的RenderObject对象,RenderObjec对象保存了为了绘制DOM节所需的信息,如样式布局信息等。
- webkit 不为 “非可视化节点” 创建RenderObject节点。
- 某些情况webkit需要建立匿名RenderObject 节点,如匿名RenderBlock节点,是webkit 处理上的需要。
- 影子DOM虽然无法被JS代码访问,但是webkit 需要创建并渲染 RenderObject。
- DOM树中,元素节点包含很多类型;RenderObject 树中节点也有很多类型。图中描述了RenderObject 类和他的主要子类。
- RenderObject 类包含了RenderObject 的主要虚函数。如 白能力和修改、计算布局和获取布局相关信息等函数。
- RenderBoxModelObject 类是描述所有跟CSS中框模型相关联类 的基类。
- RenderBlock 类用来表示块元素。

- RenderObject 类包含了RenderObject 的主要虚函数。如 白能力和修改、计算布局和获取布局相关信息等函数。
- DOM树中,某些节点用户不可见,为 “非可视化节点”,如上述代码中 ”script“、“head”等。
- RenderObject 树:
- RenderObject 树由
NodeRenderingContext类负责,下图描述了webkit 如何创建RenderObject 对象 并构建RenderObject 树的。 
- 首先webkit 检查该DOM 节点是否需要创建RenderObject 对象,。
- 需要的话,首先获取一个创建RenderObject 对象的
NodeRenderingContext对象,NodeRenderingContext对象会分析需要创建的renderObject 对象的父亲节点、兄弟节点等,设置这些信息后,完成插入树的动作。
- 需要的话,首先获取一个创建RenderObject 对象的
- 首先webkit 检查该DOM 节点是否需要创建RenderObject 对象,。
- RenderObject 树由
网页层次和RenderLayer树
- 网页可以分层:为了方便开发网页设置网页层次、为了简化渲染逻辑
- webkit 会为网页层次创建相应的 RenderLayer 对象。
- 但某些节点或具有某些CSS样式的RenderObject 节点出现时。
- 如:DOM树的Document节点对应的 RenderView 节点、RenderBlock节点、显示指定CSS位置的RenderObject 节点、有透明效果的RenderObject 节点等。
- RenderLayer 节点和RenderObject 不是一对一的关系,而是一对多的关系。
- 每个RenderLayer 节点包含的是一颗RenderObject 子树。
- 但某些节点或具有某些CSS样式的RenderObject 节点出现时。
- RenderLayer 节点可以有效减少网页结构的复杂程度,减少重新渲染的开销。(只渲染对应层?)
- RenderLayer 类没有子类,表示的是网页的一个层次,没有子层次一说。
- webkit 会为网页层次创建相应的 RenderLayer 对象。
- RenderLayer树 :
- 示例代码7-1 的 RenderLayer 树包含三个RenderLayer 节点。

- 下图表示了RenderObject树、RenderLayer 树和布局信息中的大小和位置信息。

- 第一个RenderLayer 节点对应的DOM树中的Document 节点。
- 第二个layer 包含了HTML 绝大部分元素。
- 首先“head” 不是可视元素
- “”canvas“ 虽然是RenderBody 节点的子女,但是并不在第二layer中,而在第三个layer中。
- 该层包含一个匿名(Anonymous) RenderBlock 节点,包含了RenderText 、RenderInline等子节点。
- 三个层次的创建时间:
- 创建DOM树之后,webkit 紧接着创建第一个和第二个layer 层。
- webkit 检查出JS代码 为“canvas” 创建了3D绘图上下文,才创建了第三个layer 层。
渲染方式
- 绘图上下文:
- webkit 的绘图操作被定义了一个抽象层,就是绘图上下文(Graphics Context),所有绘图操作在该上下文中进行的。
- 绘图上下文分为:2D绘图上下文、3D绘图上下文。这两个都是抽象基类,用于提供接口,具体绘制由不同移植提供。
- 2D绘图上下文:提供 基本绘图单元 的 绘制接口,以及设置绘图样式。
- 绘图接口:画点、画线、画图片、画多边形、画文字等。
- 绘图样式:颜色、线宽、字号大小、渐变等。
- RenderObject 对象知道自己要画什么,调用对应绘图上下文绘制实际的显示结果。
- 2D绘图上下文:提供 基本绘图单元 的 绘制接口,以及设置绘图样式。
- 对于2D绘图上下文,可以使用CPU完成2D相关操作,也可以使用3D图形接口(OpenGL)完成2D相关操作。
- 对于3D绘图上下位,因为性能问题,webkit移植通常使用3D图形接口(OpenGL、Direct3D)实现。
- 绘图上下文分为:2D绘图上下文、3D绘图上下文。这两个都是抽象基类,用于提供接口,具体绘制由不同移植提供。
- webkit 的绘图操作被定义了一个抽象层,就是绘图上下文(Graphics Context),所有绘图操作在该上下文中进行的。
- 渲染方式:
-
webkit 通过构建渲染的内部表示,使用图形库将这些模型绘制出来。
- 主要渲染方式包括:软件渲染、硬件加速渲染、混合模式。
- 每个RenderLayer 对象被想象成图像的一个层,各个层一同构成一个图像。
- 绘图操作:每个层对应网页中一个或读个可视元素,这些元素都绘制内容到该层上。
- 每个层都有个绘制存储区域,保存绘图结果,将这些层的内容合并到一个图像中,叫合成,使用合成技术的渲染叫合成化渲染。
- 构建好RenderObject、RenderLayer 两个树后,webkit 将内部模型转换成可视结果分为两个阶段:
- 每层内容绘图工作、将绘图结果合成图像。
- 对于软件绘制:
- webkit 需要用CPU绘制每层内容,但是软件渲染机制没有合成阶段,因为软件渲染通常结果就是一个位图,绘制每层都用这个位图,区别在于绘制位置可能不一样,不需要分层。
- 三种渲染方式:

- 软件渲染中网页使用一个位图,实际上就一块CPU使用的内存空间。
- 第二种和第三种都使用了合成化的渲染技术。 使用GPU硬件加速合成这些网页 ,由GPU负责合成,即硬件加速合成。 只是第二种有些层使用CPU绘图,然后将其传输到GPU内存中。
-
对于2D绘图操作: GPU绘图不一定比使用CPU绘图性能上有优势,因为CPU使用缓存机制减少了重复绘制开销,且并不需要GPU的并行性,
-
三种渲染方式的特点:
- 软件渲染:
- 只能处理2D方面操作。 对HTML5 新技术能力不足、性能不好。
- 和硬件加速渲染的区别为:对更新区域处理的不同:网页中小型区域的请求时,软件渲染可能只需要计算一个区域,硬件需要重新绘制一个或多个层,使得硬件渲染代价较大。
- 硬件加速合成化渲染:
- 每个层的绘制及所有层的合成使用GPU硬件完成。 对3D绘图操作合适。
- 这种方式,在RenderLayer树之后,需要建立更多的内部表示来支持硬件加速机制。如GraphicsLayer树、合成器中的层(如chromium 的CCLayer)
- 对于更新某个层的区域,硬件加速渲染只需要重新绘制更新发生的层次。(这种情况硬件更有效)
- 软件绘图的合成化渲染:
- 结合前两者的优点,因为网页一般包含了HTML、HTML5新功能。使用CPU、GPU分别绘制某些层,效果可能更好。
- 硬件是对更新层更有效,软件是对更新整个图的一个区域更有效。
- 软件渲染:
-

WebKit软件渲染技术 —— ***
- 软件渲染过程:
- webit 遍历 RenderLayer
- 对于每个 RenderObject ,有三个阶段绘制自己:
- 绘制该层所有背景和边框
- 绘制浮动内容
- 绘制前景(内容部分、轮廓等)
- 内嵌元素的背景、边框、前景等都在第三个阶段绘制。
- 对于每个 RenderObject ,有三个阶段绘制自己:
- webkit 第一次绘制网页时,绘制区域等同可视区域大小。
- 在这之后,每次只是先计算需要更新的区域,然后绘制同这些区域有交集的RenderObject 节点。
- 即如果更新区域和某个 RenderLayer 节点有交集, webkit 会查找RenderLayer树中包含RenderObject 子树中特定一个或一些节点,而不是绘制整个RenderLayer对应的RenderObject 子树。
- webkit 软件渲染结果的存储方式,都是CPU内存的一块区域,基本是个位图。
- 至于其如何处理,如何合并、显示,都和webkit 不同移植有关。
- webit 遍历 RenderLayer
- Chromium的多进程软件渲染技术 :
- chromium 将渲染结果从Renderer进程传递到Browser 进程显示。
- 重新绘制触发:
- 前端请求:从Browser 进程发起的请求。如用户操作网页引起变化
- 后端请求:页面自身逻辑引起更新部分区域的请求,如JS代码更新网页样式。
- chromium 将渲染结果从Renderer进程传递到Browser 进程显示。
- 可以使用
about:tacing工具:chrome://tracing分析chrome多进程软件渲染过程。


















 710
710

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









