







编码解码问题
在一次请求一个网页的过程中,遇到一个问题,代码如下:
这是解决了问题之后的代码
import urllib.request
headers={'User-Agent':'Mozilla/5.0 (Windows; U; Windows NT 5.1; it; rv:1.8.1.11) Gecko/20071127 Firefox/2.0.0.11'}
request = urllib.request.Request("https://dress.pclady.com.cn/",headers=headers)
response = urllib.request.urlopen(request)
html = response.read().decode(encoding='gbk', errors='ignore')
print (html)
如果将.decode(encoding=‘gbk’, errors=‘ignore’) 改为.decode(‘utf-8’) 就会报如下错误:
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xb7 in position 75: invalid start byte
错误的意思是:UnicodeDecodeError:“utf-8”编解码器无法解码位置75中的字节0xb7:inv
经网上查询了解到这是因为遇到了非法字符——尤其是在某些用C/C++编写的程序中,全角空格往往有多种不同的实现方式,比如\xa3\xa0,或者\xa4\x57,这些字符,看起来都是全角空格,但它们并不是“合法”的全角空格(真正的全角空格是\xa1\xa1),因此在转码的过程中出现了异常。
这样的问题很让人头疼,因为只要字符串中出现了一个非法字符,整篇文章就都无法转码。
改为.decode(encoding=‘gbk’, errors=‘ignore’) 即可解决错误
下面解释一下decode(encoding=‘gbk’, errors=‘ignore’) 这个函数
decode() 方法:
以 encoding 指定的编码格式来解码字符串。默认编码规则是encoding=‘utf-8’
语法: bytes.decode(encoding=‘UTF-8’,errors=‘strict’)
参数:
-
bytes是由编码方法encoding()编码转换过后得到的字符串的字节表示值。
-
encoding – 解码时要使用的编码方案,如"UTF-8"。
-
errors – 设置不同错误的处理方案。默认为 ‘strict’,意为编码错误引起一个代码产生UnicodeError错误,代表遇到非法字符时抛出异常。
其它的值有 ‘ignore’, ‘replace’, ‘xmlcharrefreplace’, ‘backslashreplace’ 以及通过 codecs.register_error() 注册的任何值。
如果设置为ignore,则会忽略非法字符;
如果设置为replace,则会用?取代非法字符;
如果设置为xmlcharrefreplace,则使用XML的字符引用。
str->bytes:encode编码
bytes->str:decode解码
如何查看网页编码格式
在网页按F12,打开开发者工具
在console控制台输入document.charset 然后回车,如图:
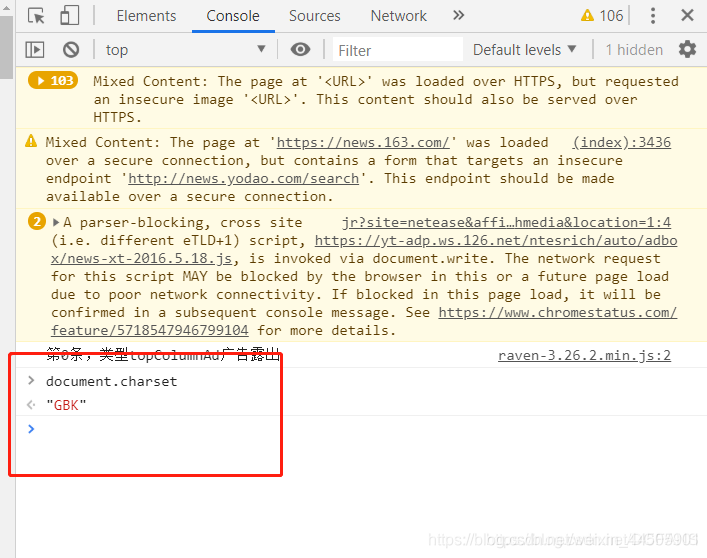
参照博客: https://www.jb51.net/article/16104.htm

















 1265
1265

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









