







 本文详细解读了Flink集群启动过程,涉及JobManager、TaskManager、ResourceManager的核心组件,包括它们的职责、启动顺序、服务初始化和心跳机制。重点介绍了StandaloneSessionClusterEntrypoint的启动流程和主要组件的创建与初始化过程。
本文详细解读了Flink集群启动过程,涉及JobManager、TaskManager、ResourceManager的核心组件,包括它们的职责、启动顺序、服务初始化和心跳机制。重点介绍了StandaloneSessionClusterEntrypoint的启动流程和主要组件的创建与初始化过程。
深入理解 Flink 系列文章已完结,总共八篇文章,直达链接:
深入理解 Flink (一)Flink 架构设计原理
深入理解 Flink (二)Flink StateBackend 和 Checkpoint 容错深入分析
深入理解 Flink (三)Flink 内核基础设施源码级原理详解
深入理解 Flink (四)Flink Time+WaterMark+Window 深入分析
深入理解 Flink (五)Flink Standalone 集群启动源码剖析
深入理解 Flink (六)Flink Job 提交和 Flink Graph 详解
深入理解 Flink (七)Flink Slot 管理详解
深入理解 Flink (八)Flink Task 部署初始化和启动详解
前言
Flink 集群的逻辑概念:
JobManager(StandaloneSessionClusterEntrypoint) + TaskManager(TaskManagerRunner)
Flink 集群的物理概念:
ResourceManager(管理集群所有资源,管理集群所有从节点) + TaskExecutor(管理从节点资源,接收 Task 部署执行)
在 Flink 不同的部署模式下(Standalone、YARN、K8S 等)只是最外层的封装略有区别,实际运行的内核并无差异。因此本文以 Standalone 集群为例,剖析 Flink 集群的启动源码。
Flink 集群启动脚本分析
Flink 集群的启动脚本位于 flink-dist 子项目中,flink-bin 下的 bin 目录:
start-cluster.sh
根据具体组件的不同,脚本会按照以下流程执行:
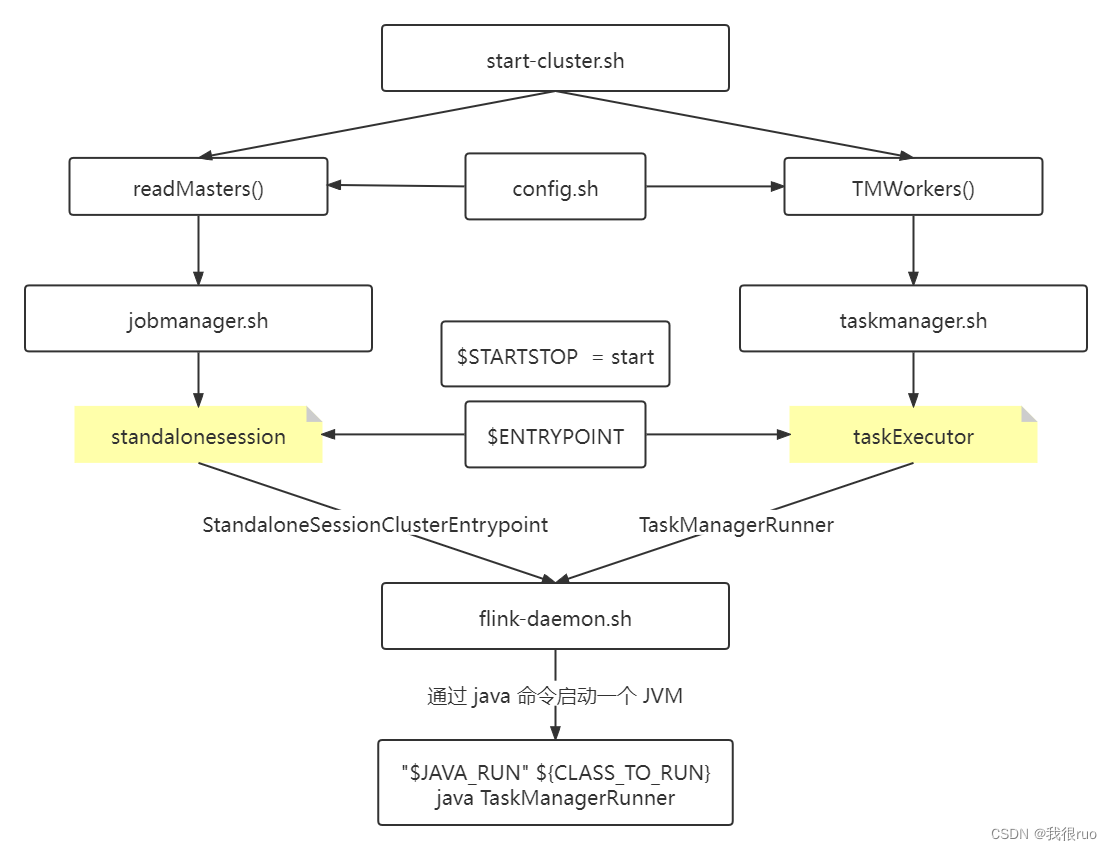
Flink 主节点 StandaloneSessionClusterEntrypoint 启动源码分析
JobManager 是 Flink 集群的主节点,它包含三大重要的组件:
1、ResourceManager
Flink 的集群资源管理器,只有一个,关于 slot 的管理和申请等工作,都由它负责
2、DispatcherRunner
负责接收用户提交的 JobGragh, 然后启动一个 JobMaster, JobMaster 类似于 YARN 集群中的 AppMaster 角色,类似于 Spark Job 中的 Driver 角色。内部有一个持久服务:JobGraghStore,用来存储提交到 JobManager 中的 Job 的信息,也可以用作主节点宕机之后做 job 恢复之用。
3、WebMonitorEndpoint
里面维护了很多很多的 Handler,也还会启动一个 Netty 服务端,用来接收外部的 rest 请求。如果客户端通过 flink run 的方式来提交一个 job 到 flink 集群,最终是由 WebMonitorEndpoint 来接收处理,经过路由解析处理之后决定使用哪一个 Handler 来执行处理。Router 路由器 绑定了一大堆 Handler,例如:submitJob ===> JobSubmitHandler。
这里简单说明一下 Flink 的资源管理架构,后续章节会展开详述:
ResourceManager: 全局资源管理者 => SlotManager
JobMaster: 资源使用者 => SlotPool
TaskExecutor:资源提供者 => TaskSlotTable
以上三者的内部,都有一个专门用来做 slot 管理的一个组件。对应的要启动这三个组件,都有一个对应的 Factory,也就说,如果需要创建这些组件实例,那么都是通过这些 Factory 来创建。而这三个 Facotry 最终都会被封装在一个 ComponentFactory 中。
StandaloneSessionClusterEntrypoint main 方法
// 入口,解析命令行参数 和 配置文件 flink-conf.yaml
StandaloneSessionClusterEntrypoint.main(){
ClusterEntrypoint.runClusterEntrypoint(entrypoint){
// 启动插件组件,配置文件系统实例等
clusterEntrypoint.startCluster(){
runCluster(configuration, pluginManager){
// 第一步:初始化各种服务(8个基础服务)
// 比较重要的:HAService,BlobServer, RpcServices, HeatbeatServices,....
initializeServices(configuration, pluginManager);
// 第二步:创建 DispatcherResourceManagerComponentFactory, 初始化各种组件的工厂实例
// 其实内部包含了三个重要的成员变量:
// 创建 ResourceManager 的工厂实例
// 创建 DispatcherRunner 的工厂实例
// 创建 WebMonitorEndpoint 的工厂实例
createDispatcherResourceManagerComponentFactory(configuration);
// 第三步:创建 集群运行需要的一些组件:WebMonitorEndpoint,DispatcherRunner, ResourceManager 等
// 创建和启动 ResourceManager
// 创建和启动 DispatcherRunner
// 创建和启动 WebMonitorEndpoint
clusterComponent = dispatcherResourceManagerComponentFactory.create(...);
}
}
}
}
基础服务组件初始化
initializeServices(){
// 初始化和启动 AkkaRpcService,内部其实包装了一个 ActorSystem
commonRpcService = AkkaRpcServiceUtils.createRemoteRpcService(...);
// 启动一个 JMXService,用于客户端链接 JobManager JVM 进行监控
JMXService.startInstance(configuration.getString(JMXServerOptions.JMX_SERVER_PORT));
// 初始化一个负责 IO 的线程池, Flink 大量使用了 异步编程。
// 这个线程池的线程的数量,默认是:cpu core 个数 * 4
ioExecutor = Executors.newFixedThreadPool(...);
// 初始化 HA 服务组件,负责 HA 服务的是:ZooKeeperHaServices
haServices = createHaServices(configuration, ioExecutor);
// 初始化 BlobServer 服务端
blobServer = new BlobServer(configuration, haServices.createBlobStore());
blobServer.start();
// 初始化心跳服务组件, heartbeatServices = HeartbeatServices
heartbeatServices = createHeartbeatServices(configuration);
// 启动 metrics(性能监控) 相关的服务,内部也是启动一个 ActorSystem
MetricUtils.startRemoteMetricsRpcService(configuration, commonRpcService.getAddress());
// 初始化一个用来存储 ExecutionGraph 的 Store, 实现是:FileArchivedExecutionGraphStore
archivedExecutionGraphStore = createSerializableExecutionGraphStore(...);
}
重要组件工厂实例初始化
DispatcherRunnerFactory,默认实现:DefaultDispatcherRunnerFactory,生产 DefaultDispatcherRunner
ResourceManagerFactory,默认实现:StandaloneResourceManagerFactory,生产 StandaloneResourceManager
RestEndpointFactory,默认实现:SessionRestEndpointFactory,生产 DispatcherRestEndpoint
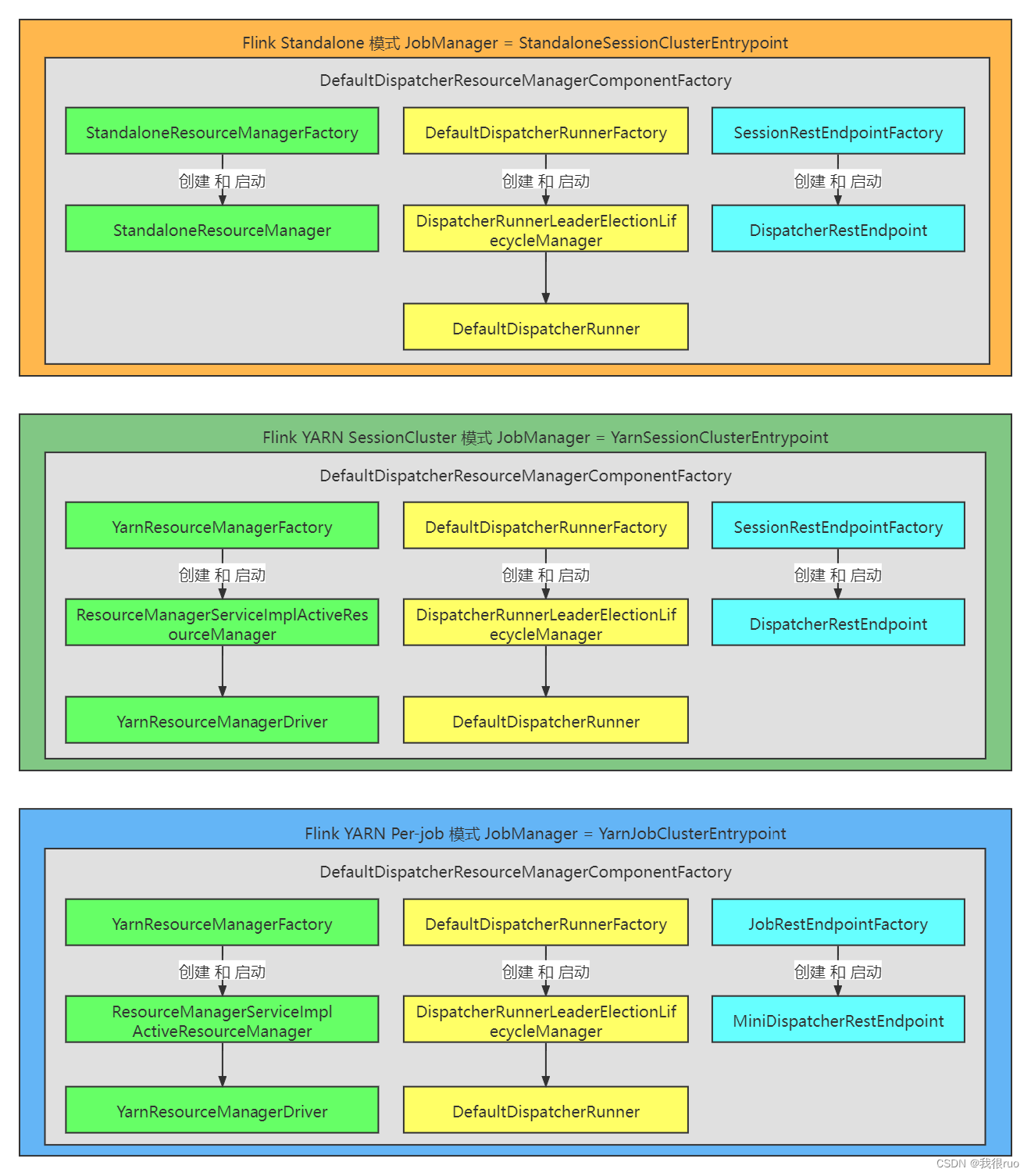
三大重要组件初始化
Flink 源码中,三大重要组件初始化按照一下流程进行:
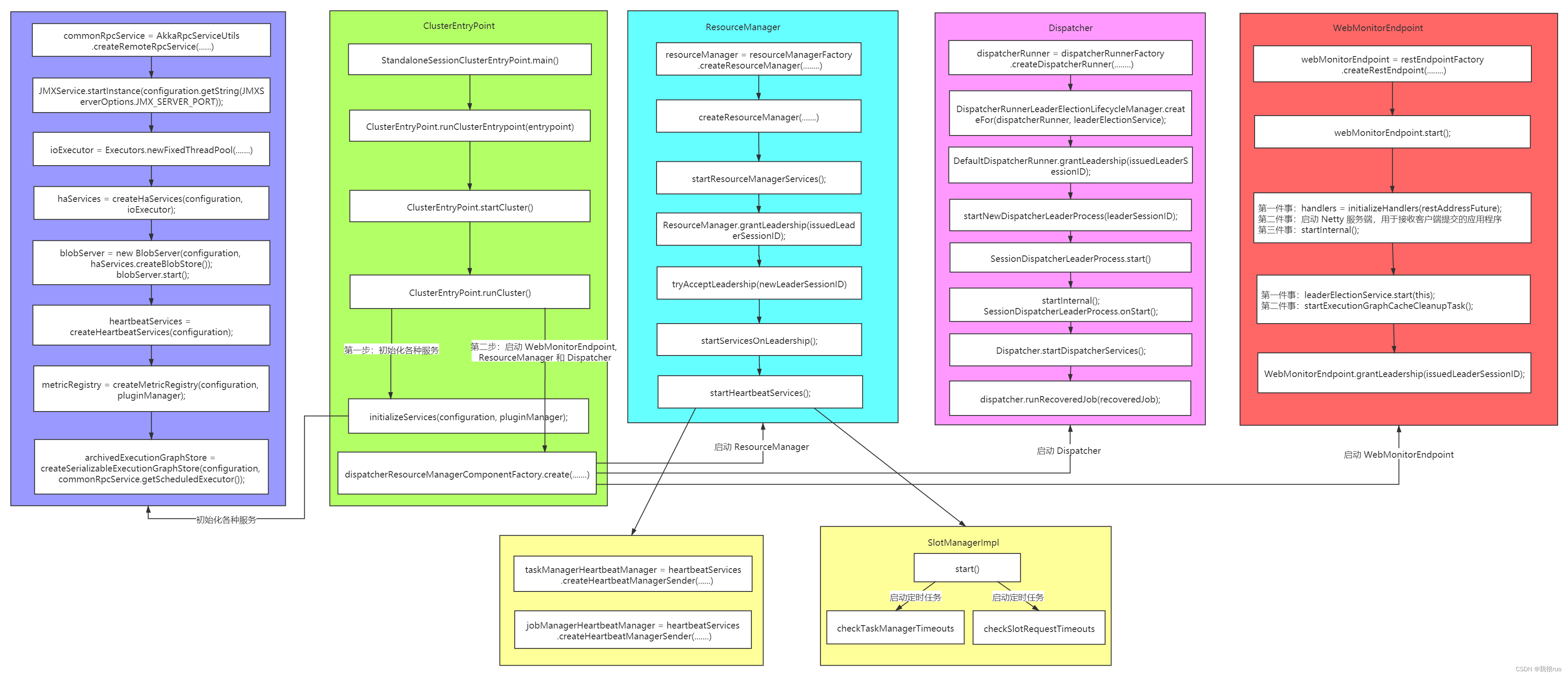
三大重要组件初始化源码解析
WebMonitorEndpoint 启动和初始化源码剖析
核心入口:
DispatcherResourceManagerComponentFactory.create(...)
启动流程:
- 初始化一大堆 Handler 和 一个 Router,并且进行排序去重,之后,再把每个 Handler 注册 到 Router 当中。
- 启动一个 Netty 的服务端。
- 启动内部服务:执行竞选。WebMonitorEndpoint 本身就是一个 LeaderContender 角色。如果竞选成功,则回调 isLeader() 方法。
- 竞选成功,其实就只是把 WebMontiroEndpoint 的 address 以及跟 zookeeper 的 sessionID 写入到 znode 中。
- 启动一个关于 ExecutionGraph 的 Cache 的定时清理任务。
ResourceManager 启动和初始化源码剖析
核心入口:
DispatcherResourceManagerComponentFactory.create(...)
启动流程:
1、ResourceManager 是 RpcEndpoint 的子类,所以在构建 ResourceManager 对象完成之后,肯定会调用 start() 方法来启动这个 RpcEndpoint,然后就跳转到它的 onStart() 方法执行。
2、ResourceManager 是 LeaderContender 的子类,会通过 LeaderElectionService 参加竞选,如果竞选成功,则会回调 isLeader() 方法。
3、启动 ResourceManager 需要的一些服务:
两个心跳服务
ResourceManager 和 TaskExecutor 之间的心跳
ResourceManager 和 JobMaster 之间的心跳
两个定时服务
checkTaskManagerTimeoutsAndRedundancy() 检查 TaskExecutor 的超时
checkSlotRequestTimeouts() 检查 SlotRequest 超时
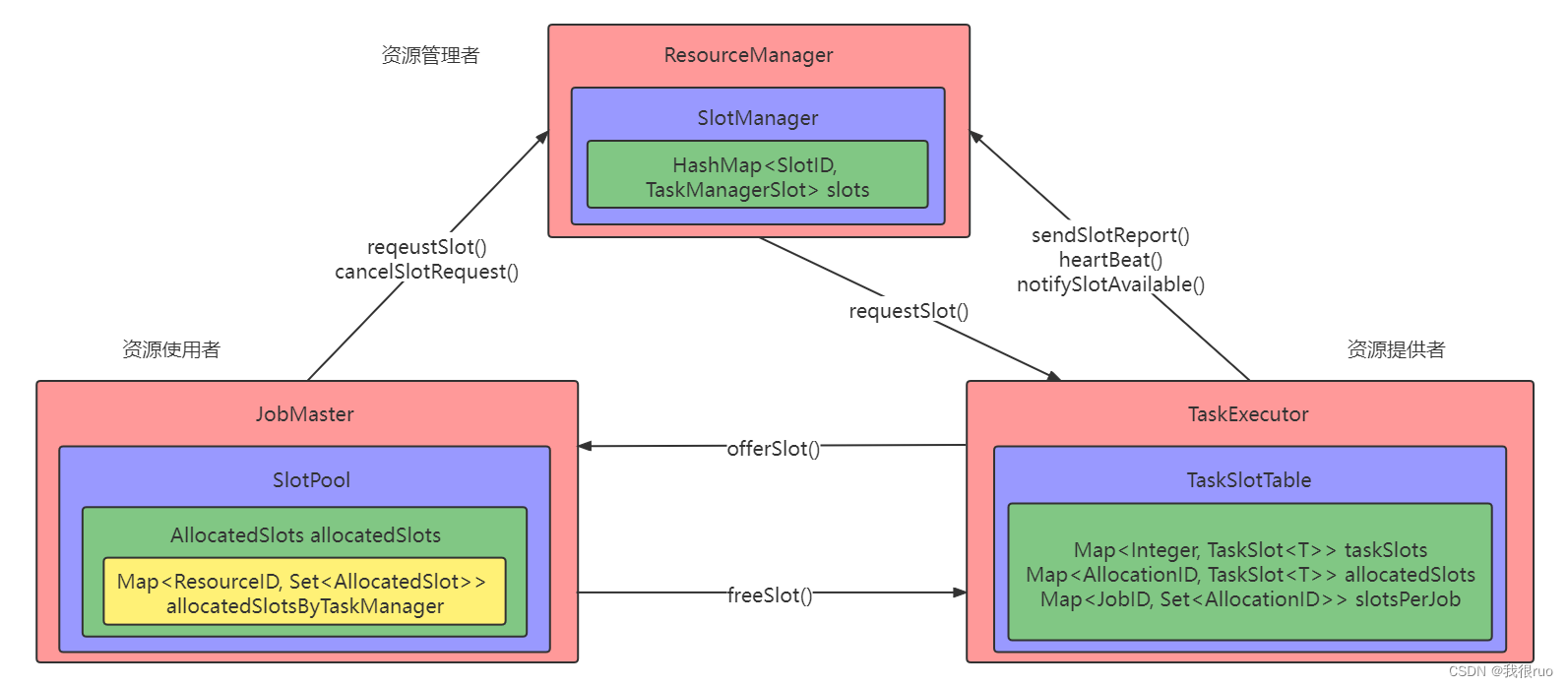
DispatcherRunner 启动和初始化源码剖析
核心入口:
DispatcherResourceManagerComponentFactory.create(...)
启动流程:
1、启动 JobGraphStore 服务
2、从 JobGraphStrore 恢复执行 Job, 要启动 Dispatcher
从节点 TaskManagerRunner 启动源码分析
TaskManager 是 Flink 的 worker 节点,负责 Flink 中本机 slot 资源的管理以及具体 task 的执行。
TaskManager 上的基本资源单位是 slot,一个作业的 task 最终会部署在一个 TaskManager 的 slot 上运行,TaskManager 会负责维护本地的 slot 资源列表,并与 Flink Master 和 JobMaster 通信。
// 核心启动入口
TaskManagerRunner.main(args){
runTaskManagerSecurely(args, ResourceID.generate()){
// 加载配置:解析 args 和 flink-conf.yaml 得到配置信息
Configuration configuration = loadConfiguration(args);
// 启动 TaskManager
// 在Flink 当中,所有的组件(跟资源有关)都有一个 ResourceID
// 后续还会见到很多的类似的ID的概念:AllocationID
runTaskManagerSecurely(configuration, resourceID){
// 启动 TaskManager
// 这个具体实现是:首先初始化 TaskManagerRunner, TaskManager 启动中,要初始化的一些服务,都是在这个构造方法里面!
// 最后,再调用 TaskManagerRunner.start() 来启动,然后跳转到 TaskExecutor 的 onStart() 开启注册。
runTaskManager(configuration, resourceID, pluginManager){
// 第一步:构建 TaskManagerRunner 实例
// 具体实现中也做了两件事:
// 第一件事: 初始化了一个 TaskManagerServices 对象! 其实这个动作就类似于 JobManager 启动的时候的第一件大事(启动8个服务)
// 第二件是: 初始化 TaskExecutor(Standalone 集群中提供资源的角色,ResourceManager 其实就是管理集群中的从节点的管理角色)
// TaskExecutor 它是一个 RpcEndpoint,意味着,当 TaskExecutor 实例构造完毕之后,启动 RPC 服务就会跳转到 onStart() 方法
taskManagerRunner = new TaskManagerRunner(...){
// 初始化一个线程池 ScheduledThreadPoolExecutor 用于处理回调
this.executor = Executors.newScheduledThreadPool(....)
// 获取高可用模式:ZooKeeperHaServices
highAvailabilityServices = HighAvailabilityServicesUtils.createHighAvailabilityServices(...)
// 初始化 JMXServer 服务
JMXService.startInstance(configuration.getString(JMXServerOptions.JMX_SERVER_PORT));
// 创建 RPC 服务
rpcService = createRpcService(configuration, highAvailabilityServices);
// 创建心跳服务
heartbeatServices = HeartbeatServices.fromConfiguration(conf);
// 创建 BlobCacheService,内部会启动两个定时任务:PermanentBlobCleanupTask 和 TransientBlobCleanupTask
blobCacheService = new BlobCacheService(....);
// 创建 TaskExecutorService,内部其实就是创建 TaskExecutor 并且启动,详细内容如下一部分阐述。
taskExecutorService = taskExecutorServiceFactory.createTaskExecutor(....){
// 创建 TaskExecutorToServiceAdapter,内部封装 TaskExecutor,它是 TaskManagerRunner 的成员变量
TaskManagerRunner::createTaskExecutorService;
}
}
// 第二步:启动 TaskManagerRunner,然后跳转到 TaskExecutor 中的 onStart() 方法
taskManagerRunner.start(){
taskExecutor.start();
}
}
}
}
}
TaskManager/TaskExecutor 注册
TaskManager 是一个逻辑抽象,代表一台服务器,这台服务器的启动,必然会包含一些服务,另外再包含一个 TaskExecutor,存在于 TaskManager 的内部,真实的帮助 TaskManager 完成各种核心操作,比如:
1、部署和执行 StreamTask
2、管理和分配 slot
监听和获取 ResourceManager 的地址
核心入口为:resourceManagerLeaderRetriever 的 start() 方法,具体实现方式见前面章节:
https://blog.csdn.net/weixin_44512041/article/details/135493920
在注册监听之后,如果发生了对应的事件,则会收到一个响应,然后回调:
ResourceManagerLeaderListener.notifyLeaderAddress();
内部详细实现:
// 关闭原有的 ResouceManager 的链接
closeResourceManagerConnection(cause);
// 开启注册超时的延时调度任务
startRegistrationTimeout();
// 当前 TaskExecutor 完成和 ResourceManager 的链接
tryConnectToResourceManager();
最重要的是第三步,TaskExecutor 和 ResourceManager 建立连接,会进行注册,心跳,Slot 汇报 三件大事。
TaskExecutor 开始注册
核心入口:
TaskExecutorToResourceManagerConnection.start();
TaskExecutor 注册失败
核心入口:
TaskExecutorToResourceManagerConnection.onRegistrationFailure(failure);
TaskExecutor 注册成功
核心入口:
TaskExecutorToResourceManagerConnection.onRegistrationSuccess(result.f1);
TaskExecutor 进行 Slot 汇报
当注册成功,ResourceManager 会返回 TaskExecutorRegistrationSuccess 对象。然后回调下面的方法,进入到 slot 汇报的过程。
TaskExecutorToResourceManagerConnection.onRegistrationSuccess(TaskExecutorRegistrationSuccess success);
// 继续回调
ResourceManagerRegistrationListener.onRegistrationSuccess(this, success);
// 封装链接对象
establishResourceManagerConnection(resourceManagerGateway, resourceManagerId, taskExecutorRegistrationId, ....);
// 内部实现
resourceManagerGateway.sendSlotReport(
getResourceID(),
taskExecutorRegistrationId,
taskSlotTable.createSlotReport(getResourceID()), taskManagerConfiguration.getTimeout()
);
TaskExecutor 和 ResourceManager 心跳
Flink 中 ResourceManager、JobMaster、TaskExecutor 三者之间存在相互检测的心跳机制,ResourceManager 会主动发送请求探测 JobMaster、TaskExecutor 是否存活,JobMaster 也会主动发送请求探测 TaskExecutor 是否存活,以便进行任务重启或者失败处理。
假定心跳系统中有两种节点:sender 和 receiver。心跳机制是 sender 和 receivers 彼此相互检测。但是检测动作是 Sender 主动发起,即 Sender 主动发送请求探测 receiver 是否存活,因为 Sender 已经发送过来了探测心跳请求,所以这样 receiver 同时也知道 Sender 是存活的,然后 Reciver 给 Sender 回应一个心跳表示自己也是活着的。具体表现:
- Flink Sender 主动发送 Request 请求给 Receiver,要求 Receiver 回应一个心跳;
- Flink Receiver 收到 Request 之后,通过 Receive 函数回应一个心跳请求给 Sender;
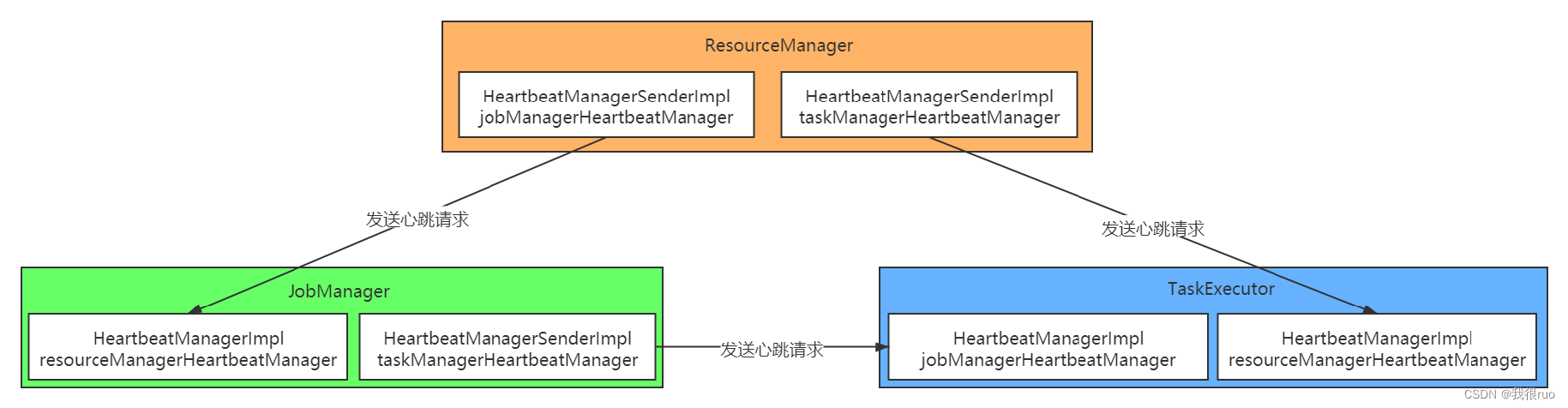
ResourceManager 端心跳服务启动
ResourceManager 在初始化的最后,执行了:
ResourceManager.startHeartbeatServices();
启动了两个心跳服务:
// 维持 TaskExecutor 和 ResourceManager 之间的心跳
taskManagerHeartbeatManager = heartbeatServices.createHeartbeatManagerSender(resourceId, new TaskManagerHeartbeatListener(),
getMainThreadExecutor(), log);
// 维持 JobMaster 和 ResourceManager 之间的心跳
jobManagerHeartbeatManager = heartbeatServices.createHeartbeatManagerSender(resourceId, new JobManagerHeartbeatListener(),
getMainThreadExecutor(), log);
具体是构造了一个 HeartbeatManagerSenderImpl 实例对象,并且调用了:
mainThreadExecutor.schedule(this, 0L, TimeUnit.MILLISECONDS);
heartbeatMonitor 内部封装了一个 heartbeatTarget,对于 ResourceManager 来说,每个注册成功的 TaskExecutor 都会被构建成一个 HeartbeatTarget ,然后构建成一个 heartbeatMonitor。这个可以在 ResourceManager 端完成 TaskExecutor 注册的时候进行验证。
当 ResourceManager 端完成一个 TaskExecutor 的注册的时候,马上调用:
// 维持心跳
taskManagerHeartbeatManager.monitorTarget(taskExecutorResourceId, new HeartbeatTarget<Void>() {
@Override
public void receiveHeartbeat(ResourceID resourceID, Void payload) {
}
@Override
public void requestHeartbeat(ResourceID resourceID, Void payload) {
// 给 TaskExecutor 发送心跳请求
taskExecutorGateway.heartbeatFromResourceManager(resourceID);
}
});
这样子,刚才注册的 TaskExecutor 就先被封装成一个 HeartbeatTarget, 然后被加入到 taskManagerHeartbeatManager 进行管理的时候,变成了 HeartbeatMonitor。当这句代码完成执行的时候,当前 ResourceManager 的心跳目标对象,就多了一个 TaskExecutor,然后当执行:
taskExecutorGateway.heartbeatFromResourceManager(resourceID);
就给 TaskExecutor 发送了一个心跳请求。
TaskExecutor 端心跳处理
当 TaskExecutor 接收到 ResourceManager 的心跳请求之后,进入内部实现:
TaskExecutor.heartbeatFromResourceManager(ResourceID resourceID);
// 内部实现
resourceManagerHeartbeatManager.requestHeartbeat(resourceID, null);
// 内部实现
reportHeartbeat(requestOrigin);
// 第一件事:进行心跳报告
heartbeatMonitor.reportHeartbeat();
// 记录最后一次的心跳时间
lastHeartbeat = System.currentTimeMillis();
// 重设心跳超时相关的 时间 和 延迟调度任务
resetHeartbeatTimeout(heartbeatTimeoutIntervalMs);
// 先取消
cancelTimeout();
// 再重新调度
futureTimeout = scheduledExecutor.schedule(this, heartbeatTimeout, TimeUnit.MILLISECONDS);
// TaskExecutor 进行负载汇报
heartbeatTarget.receiveHeartbeat(.....);
// 给 ResourceManager 回复 TaskExecutor 的负载。
resourceManagerGateway.heartbeatFromTaskManager(resourceID, heartbeatPayload);
如果连续 5 次心跳请求没有收到,也就是说,如果 50s 内都没有收到心跳请求,则执行心跳超时处理。
heartbeatListener.notifyHeartbeatTimeout(resourceID);
超时处理也非常的暴力有效,Flink 认为: 如果 TaskExecutor 收不到 ResourceManager 的心跳请求了,则认为当前 ResourceManager 死掉了。但是 Flink 集群肯定会有一个 active 的 ResourceManager 节点的。而且之前也注册过监听,如果 Flink HA 集群的 Active 节点发生迁移,则 TaskExecutor 也一定已经收到过通知了,然后现在需要做的,只是重新链接到新的 active ResourceManager 即可。
reconnectToResourceManager(
new TaskManagerException(String.format("The heartbeat of ResourceManager with id %s timed out.", resourceId))
);
TaskExecutor 向 ResourceManager 汇报负载
核心入口:HeartBeatManagerImpl 的 requestHeartbeat() 方法的最后一句代码:
heartbeatTarget.receiveHeartbeat(getOwnResourceID(), heartbeatListener.retrievePayload(requestOrigin));















 3702
3702











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









