







本人用的是Python3.8,工具是pycharm,导入包selenium pycharm就有如下图:

点击file-Settings

点击Project interpreter 点击加号

输入selenium点击install Package,包名变成蓝色下载完成
导入包
from selenium import webdriver # 导入selenium包
from selenium.webdriver.support.select import Select # 用以支持下拉列表对象
from time import sleep # 导入time包
打开浏览器
webdriver.Ie() # 打开IE浏览器
webdriver.Chrome() # 打开Google浏览器
webdriver.Firefox() # 打开火狐浏览器
打开这些浏览器前提是你安装了浏览器
大佬分享的浏览器插件下载网址
上面网站IE,chrome,Firefox都有
将下载好对应版本插件(chromedriver、geckodriver、iedriverserver)
下载Chromedriver的时候要按照自己的Chrome版本进行下载,查看版本如下

点击竖着三点–设置

点击关于Chrome

这就是对应版本,下载插件的对应表中没有意义的版本,只要大版本一直都可以,选择相近的就行
下载Firefox的插件

上面链接中有去GitHub上面的网站,任何下载对应需要的版本就行了
IE是要求看selenium的版本,Windows+R输入cmd,pip list 查看所有下载的包以及版本


然后去下载对应的IE浏览器插件就行了
最后将三个插件全部放到Python文件夹的根目录下

OK了(有些人是默认路径安装的“C:\Users\yww\AppData\Local\Programs\Python”)
打开指定URL以及退出
driver = webdriver.Chrome() # 打开Google浏览器
driver.get("http://10.10.132.117/index.php") # 访问指定URL
sleep(3) # 执行到此命令时等待3秒
driver.implicitly_wait(3) # 隐形等待时间为3秒
driver.quit() # 退出浏览器和浏览器驱动程序
# driver.close() # 退出浏览器
最好是用quit()虽然都是退出浏览器,quit比较彻底
切换框架/窗口
使用switch_to包
定位到当前聚焦的元素上:driver.switch_to.active_element()
切换到alert弹窗:driver.switch_to.alert()
切换到主页面:driver.switch_to.default_content()
切换到某人frame:driver.switch_to.frame(编码或name)
切换到指定的window_name 页签:driver.switch_to.window(window_name)
切换到上一层的frame:driver.switch_to.parent_frame()
定位页面元素
driver.find_element_by_name("login")
driver.find_element_by_id()
driver.find_element_by_xpath()
driver.find_element_by_link_text()
driver.find_element_by_tag_name()
driver.find_element_by_partial_link_text()
driver.find_element_by_class_name()
driver.find_elements_by_name("控件name名")[下标] # 这里是find_elements_by_,可以用下标(索引值去取)
Select(driver.find_element_by_*) # 用于识别下拉列表元素,要导入的包:from selenium.webdriver.support.select import Select
页面元素的属性与方法
driver.title() # 获取网页标题
对象.text # 获取页面元素的文本值 属于属性
对象.get_attribute("属性名") # 获得指定属性的值
Select(对象).select_by_value() # 导入的包是一样的
Select(对象).select_by_index()
Select(对象).select_by_visible_text()
Select(对象).deselect_all() # 取消所有选项
Select(对象).deselect_by_index() # 取消对应index选项
Select(对象).deselect_by_visible_text() # 取消对应文本选项
Select(对象).deselect_by_value() # 取消对应value选项
Select(对象).first_selected_option() # 返回第一个选项
Select(对象).all_selected_options() # 返回所有的选项
页面元素.send_keys("数据") # 用于键盘输入数据
页面元素.click() # 支持单选按钮、复选框、命令按钮
从txt文件导入用户名和密码登录重复登录测试,编写txt文件,用户名密码中间用空格分开

第一列是用户名第二列是密码
我们可以用列表取其中的值,代码如下:
file = open('1.txt', 'r') # 打开1.txt文件
for i in file: # 遍历文件
username = i.split()[0] # 用split切片,每行是一个列表,索引值0也就是第一个值是username
passwrod1 = i.split()[1] # 对应的索引值1也就是password
driver.find_elements_by_class_name('name')[0].send_keys(username)
driver.find_elements_by_class_name('name')[1].send_keys(passwrod1)
file.close()
这里使用open打开文件,我将1.txt和我的源代码放在同一文件夹下面就不用写路径,如果不在同一文件夹下,要填写相应txt文本的路径
遍历文件,split默认是空格切片正好将第一列和第二列放在同一个列表的第一个和第二个对应索引值0和1
在将具体的值传入你要输入的输入框中,就可以做到重复测试
from selenium import webdriver
driver = webdriver.Chrome()
driver.get("http://10.10.132.117/")
file = open('1.txt', 'r')
for i in file:
username = i.split()[0]
passwrod1 = i.split()[1]
driver.find_element_by_link_text("登录").click()
driver.find_elements_by_class_name("gray")[0].send_keys(username)
driver.find_elements_by_class_name("gray")[1].send_keys(passwrod1)
driver.find_element_by_class_name('submit_login').click()
name = driver.find_element_by_class_name('f14')
if username in name.text:
print("登录成功")
driver.find_element_by_xpath('/html/body/div[1]/div[1]/p/a').click()
else:
print('登录失败')
file.close()
driver.quit()
上面就是一个循环登录的代码
如果只是少量数据记事本就可以,如果很多数据就要用到Excel表格
安装pandas
pip install --no-index --find-links=包位置 -r requirements.txt(这个文件中记录着所有需要的依赖包和版本号)
获取数据
data = pandas.read_excel(“xls文件名”.sheet_name = sheet 表编号或名称,names = [新列名列表],dtype={“新列名”:类型})
panda获取数据是字典类型
将字典装换为列表类型:datalist = data.values.tolist()
data = pandas.read_excel("1.xlsx", names=['yum', 'mm'], dtype={"用户名": str, "密码": str})
# 其他参数介绍 header=None,默认是第一行为列名,如果添加header=None表示没有列名
# skiprows=1 从第二行开始输出
#
断言:
assert str1 in str2, 断言失败时的消息文本
assert 表达式1 == 表达式2
self.assertIn(str1, str2) #断言str1是否在str中
self.assertEqual(实际, 预期)
还有很多断言的高级用法,作为菜鸟的我还没有学会


测试函数测试单个函数
suite = unittest.TestSuite()
tests = [类名("测试函数1"), 类名("测试函数2"), ....] # 只执行指定的测试、按照编写的顺序执行测试、多个测试放到列表中、不能省略类名
suite.addTests(tests) # 将测试添加到测试套件中
runner = unittest.TextTestRunner(verbosity=2) # 可以指定测试结果的详细程度
runner.run(suite)
verbosity是一个选项,表示测试结果的信息复杂度,有0、1、2三个值
0 (静默模式): 你只能获得总的测试用例数和总的结果
1 (默认模式): 非常类似静默模式 只是在每个成功的用例前面有个“.” 每个失败的用例前面有个 “F”
2 (详细模式):测试结果会显示每个测试用例的所有相关的信息
–quiet 参数 等效于 verbosity=0
–verbose参数等效于 verbosity=2
默认verbosity=1
import unittest
from unittdenglu1 import DengLu
suite = unittest.TestSuite()
tests = [DengLu('test1open'), DengLu('test2DengLu')] # 将要测试的函数放到列表里,按顺序执行
suite.addTests(tests)
runner = unittest.TextTestRunner(verbosity=2) # verbosity复杂度
runner.run(suite)
执行多个测试文件
tests = unittest.defaultTestLoader.discover("测试模块所在的目录", pattern='test*.py') # 识别所有test开头的py文件为测试用例、按模块名称顺序执行
import unittest
suite = unittest.TestSuite()
tests = unittest.defaultTestLoader.discover('./', pattern='unitt*.py') # './'是当前目录下,pattern='unitt*.py'是指开头是unitt的所有.py文件
suite.addTests(tests)
runner = unittest.TextTestRunner(verbosity=2)
runner.run(suite)
多线程并发执行测试
import unittest
import threading
suite = unittest.TestSuite()
tests = unittest.defaultTestLoader.discover("./", pattern="unitt*.py")
suite.addTests(tests)
runner = unittest.TextTestRunner(verbosity=2)
threads = []
for test in suite:
thread = threading.Thread(target=runner.run, args=(test, ))
threads.append(thread)
for thread in threads:
thread.start()
编写测试报告
import unittest
import threading
import time
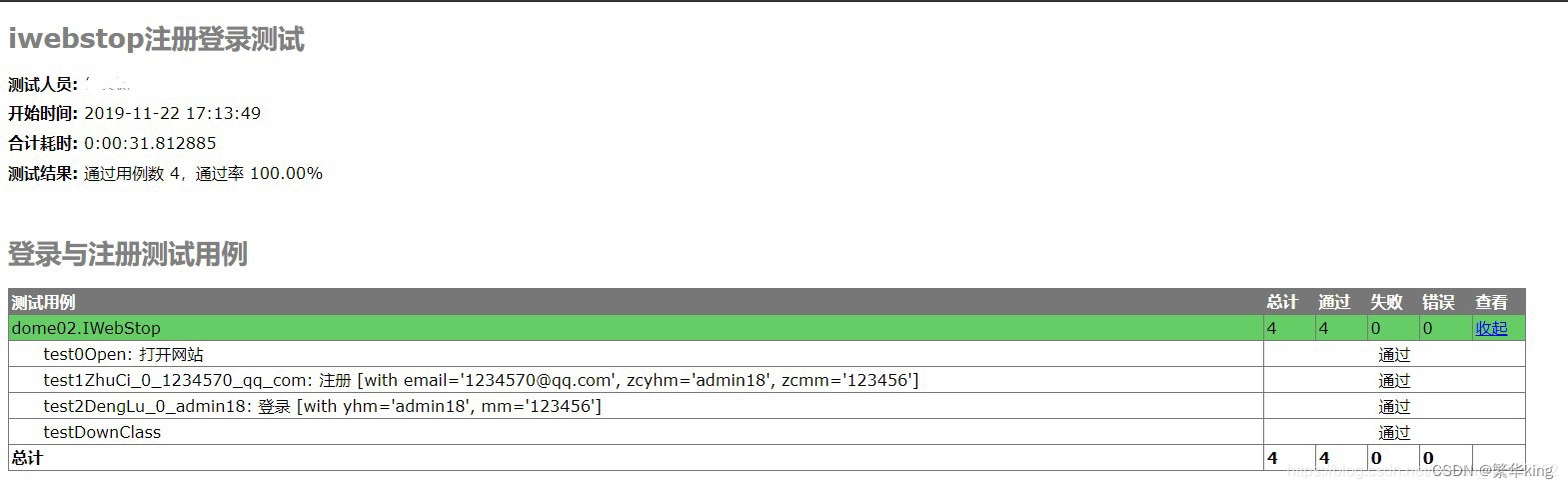
import HTMLTestRunnerZW # 模块是中文的如下图所示
suite = unittest.TestSuite()
tests = unittest.defaultTestLoader.discover("./", pattern="unittC*.py")
suite.addTests(tests)
now = time.strftime("%Y%m%d %H%M%S", time.localtime())
reportFile = "./" + now + "_result.html" # 文件名是由系统时间组成的
fp = open(reportFile, 'wb')
runner = HTMLTestRunnerZW.HTMLTestRunner(stream=fp, title=u'报告标题功能测试报告', description=u'报告的说明与描述', tester=u'测试员姓名') #
runner.run(suite)
fp.close()

这个是英文的测试用例

from selenium import webdriver
import time
import unittest
import HTMLTestRunnerZW
import parameterized
zhuci = []
denglu = []
file1 = open('2.txt', 'r')
for i in file1:
zhuci.append(i.split())
file2 = open('1.txt', 'r')
for j in file2:
denglu.append(j.split())
driver = None
class IWebStop(unittest.TestCase):
@classmethod
def setUpClass(cls):
global driver
driver = webdriver.Chrome()
@classmethod
def testDownClass(cls):
driver.quit()
def test0Open(self):
u'''打开网站'''
driver.get("http://10.10.132.135/iwebshop/")
@parameterized.parameterized.expand(zhuci)
def test1ZhuCi(self, email, zcyhm, zcmm):
u'''注册'''
driver.find_element_by_link_text('免费注册').click()
driver.find_elements_by_class_name('gray')[1].send_keys(email)
driver.find_elements_by_class_name('gray')[2].send_keys(zcyhm)
driver.find_elements_by_class_name('gray')[3].send_keys(zcmm)
driver.find_elements_by_class_name('gray')[4].send_keys(zcmm)
time.sleep(10)
driver.find_element_by_class_name('submit_reg').click()
time.sleep(5)
shiji = driver.find_element_by_class_name('loginfo').text
assert zcyhm in shiji, "实际结果是:" + shiji
driver.find_element_by_link_text('安全退出').click()
@parameterized.parameterized.expand(denglu)
def test2DengLu(self, yhm, mm):
u'''登录'''
driver.find_elements_by_class_name('gray')[0].send_keys(yhm)
driver.find_elements_by_class_name('gray')[1].send_keys(mm)
driver.find_element_by_class_name('submit_login').click()
time.sleep(3)
shiji = driver.find_element_by_class_name('loginfo').text
assert yhm in shiji, "实际结果是:" + shiji
driver.find_element_by_link_text('安全退出').click()
if __name__ == "__main__":
suite = unittest.TestSuite()
tests = unittest.defaultTestLoader.discover("./", pattern="dome02.py")
suite.addTests(tests)
now = time.strftime("%Y%m%d %H%M%S", time.localtime())
reportFile = "./" + now + "_result.html"
fp = open(reportFile, 'wb')
runner = HTMLTestRunnerZW.HTMLTestRunner(stream=fp, title=u'iwebstop注册登录测试', description=u'登录与注册测试用例', tester=u'何文涛')
runner.run(suite)
fp.close()
`over!!!















 1428
1428

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









