






第一次写博客,还请大家多多包涵,哪里有问题欢迎指出来😁
在练习豆瓣爬虫时,出现了如下问题

发现出错原因是这行代码:
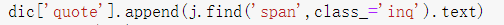
这是在爬取每个电影的引言时出现的问题,虽然去掉.text后就不会报错,但是爬出来的数据不够简洁:

可以看到,引言部分并不是纯文本。出问题的原因是部分电影不存在引言,例如《寄生虫》:

这样在爬取时的返回值为空就会报错。
解决方法:可以再爬取引言时判断一下:

这样爬取时没有引言的电影也会返回‘None’而不是没有值。
最后附上完整的代码:
import re
import pandas as pd
from bs4 import BeautifulSoup
import requests
dic = {'title':[],'year':[],'country':[],'score':[],'type':[],'quote':[],'info':[]}
for i in range(10):
num = i*25
url = 'https://movie.douban.com/top250?start=' + str(num)
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.99 Safari/537.36',
'Cookie':'ll="118137"; bid=Z09uXxe952M; __utmc=30149280; __utmc=223695111; __gads=ID=4b427da7bc5772f5-224845a09fd0000a:T=1644801255:RT=1644801255:S=ALNI_MZjzCF75jIILQN_3fd-u7NP6SRptg; _vwo_uuid_v2=D56A762C89C42FDDA5D9A39180CE666CD|fd78ebaddcae1b97e1ff2dce11ab3848; __yadk_uid=f7iF27VrhvVcZEAghEePO6t5aDK5OY9c; dbcl2="218207941:QJtp/TAsvUU"; ck=M0Jq; __utmz=30149280.1644822630.5.2.utmcsr=accounts.douban.com|utmccn=(referral)|utmcmd=referral|utmcct=/; __utmz=223695111.1644822630.5.2.utmcsr=accounts.douban.com|utmccn=(referral)|utmcmd=referral|utmcct=/; push_noty_num=0; push_doumail_num=0; __utmv=30149280.21820; _pk_ref.100001.4cf6=["","",1644885833,"https://accounts.douban.com/"]; _pk_id.100001.4cf6=b39bea3e15aaef3b.1644800668.7.1644885833.1644828119.; __utma=30149280.1729643724.1644800665.1644828119.1644885833.7; __utma=223695111.307665747.1644800665.1644828119.1644885833.7'
}
rqt = requests.get(url,headers = headers)
bs = BeautifulSoup(rqt.text,'html.parser')
bs = bs.find('ol',class_ = 'grid_view')
for j in bs.find_all('li'):
dic['title'].append(j.find('span',class_ = 'title').text)
dic['year'].append(j.find('div',class_='bd').find('p').text.strip().split('\n')[1].split()[0])
dic['country'].append(j.find('div',class_='bd').find('p').text.strip().split('\n')[1].split()[2])
dic['score'].append(j.find('span',class_ = re.compile('rating_num')).text)
dic['info'].append(j.find('p',class_ = '').text.strip().split('\n')[0].split('\xa0\xa0\xa0'))
dic['type'].append(j.find('div',class_='bd').find('p').text.strip().split('\n')[1].split('/')[2])
if j.find('span',class_='inq'):
dic['quote'].append(j.find('span',class_='inq').text)
else:
dic['quote'].append('None')
df = pd.DataFrame(dic)
最后的结果:

第一次写博客,还请大家多多支持,有什么问题可以一起讨论!















 6377
6377











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









