






使用注解的方式不能动态创建消费者,而且需要改变原代码,并重启项目,这往往只会增加后期维护成本。如题目所示,动态创建消费者,在现实的应用场景中显得越来越重要。
文章目录
一、创建业务表(可以根据实际业务场景进行字段添加)
CREATE TABLE `dfs_config_kafka` (
`id` int(11) NOT NULL,
`kafka_ip` varchar(255) DEFAULT NULL,
`kafka_port` varchar(255) DEFAULT NULL,
`group_ip` varchar(255) DEFAULT NULL,
`topics` varchar(255) DEFAULT NULL,
`get_info_type` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
二、插入测试数据
INSERT INTO `dfs_config_kafka`(`id`, `kafka_ip`, `kafka_port`, `group_ip`, `topics`, `get_info_type`) VALUES (2, '192.168.101.160', '9092', 'test-consumer-group-zhuangwq33', 'zhuang,topic2', 'latest');
INSERT INTO `dfs_config_kafka`(`id`, `kafka_ip`, `kafka_port`, `group_ip`, `topics`, `get_info_type`) VALUES (3, '192.168.101.160', '9092', 'test-consumer-group-zhuangwq11', 'zhuang,topic2', 'latest');
INSERT INTO `dfs_config_kafka`(`id`, `kafka_ip`, `kafka_port`, `group_ip`, `topics`, `get_info_type`) VALUES (4, '192.168.101.160', '9092', 'test-consumer-group-zhuangwq45', 'zhuang,topic2', 'latest');
INSERT INTO `dfs_config_kafka`(`id`, `kafka_ip`, `kafka_port`, `group_ip`, `topics`, `get_info_type`) VALUES (5, '192.168.101.160', '9092', 'test-consumer-group-zhuangwq13', 'zhuang,topic2', 'latest');
INSERT INTO `dfs_config_kafka`(`id`, `kafka_ip`, `kafka_port`, `group_ip`, `topics`, `get_info_type`) VALUES (8, '192.168.101.160', '9092', 'test-consumer-group-zhuangwqa3', 'zhuang,topic2', 'latest');
三、创建表对应的实体类
@Data
@AllArgsConstructor
@NoArgsConstructor
@Builder
@TableName("dfs_config_kafka")
public class ConfigKafkaEntity {
private static final long serialVersionUID = 1L;
/**
* Id
*/
@TableId(value = "id", type = IdType.AUTO)
private Integer id;
/**
* 单据类型
*/
@TableField(value = "kafka_ip")
private String kafkaIp;
/**
* 关联的单据号
*/
@TableField(value = "kafka_port")
private String kafkaPort;
/**
* 消费者组
*/
@TableField(value = "group_ip")
private String groupIp;
/**
* 关联的单据类型
*/
@TableField(value = "topics")
private String topics;
/**
* 物料对象
*/
@TableField(value = "get_info_type")
private String getInfoType;
}
四、创建kafka核心配置类
/**
* @author zhuang
* @description kafka配置类
*/
@Component(value = "resourceNotifyConsumer")
@Slf4j
public class ResourceNotifyConsumer {
private List<KafkaConsumer<String, String>> consumerList = new ArrayList<>();
public KafkaConsumer<String, String> getConsumer(KafkaConsumer<String, String> consumer) {
return consumer;
}
public void setConsumer(KafkaConsumer<String, String> consumer) {
this.consumerList.add(consumer);
}
public void closeConsumer(KafkaConsumer<String, String> consumer) {
//consumer非线程安全,依靠gc回收
this.consumerList.remove(consumer);
}
public void closeAllConsumer() {
try {
for (KafkaConsumer<String, String> consumer : this.consumerList) {
consumer.unsubscribe();
}
} catch (Exception e) {
// 如果出现异常,则重复执行该方法,确保消费者取消订阅成功
closeAllConsumer();
}
this.consumerList = new ArrayList<>();
}
/**
* 持续监听kafka并消费数据
*/
public void onMessage() {
try {
log.info("===============消费者已重新构建====================");
// 死循环为了能够持续监听kafka数据
while (true) {
if (!CollectionUtils.isEmpty(this.consumerList)) {
for (KafkaConsumer<String, String> kafkaConsumer : this.consumerList) {
List<Map<String, Object>> datas = new ArrayList<>();
// 每100ms取一次数据,取不到则每100ms重复取一次数据,如果取到则直接返回
ConsumerRecords<String, String> records = kafkaConsumer.poll(Duration.ofMillis(100));
// 遍历
for (ConsumerRecord<String, String> record : records) {
Map<String, Object> notifyDto = JSON.parseObject(record.value(), Map.class);
datas.add(notifyDto);
}
// 拿出结果
if (CollectionUtils.isNotEmpty(datas)) {
// 异步处理 资源变更通知,避免阻塞线程
new Thread(() -> log.info("===============数据====================" + datas)).start();
}
}
} else {
break;
}
}
} catch (Throwable e) {
log.error("已创建消费者,但是系统还没分配分区,请稍等", e);
}
}
}
五、创建线程池配置类
定义线程池,防止高并发导致服务器崩溃
@Slf4j
@Configuration
public class AsyncConfiguration implements AsyncConfigurer {
@Bean(name = AsyncExecutionAspectSupport.DEFAULT_TASK_EXECUTOR_BEAN_NAME)
public ThreadPoolTaskExecutor executor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
int corePoolSize = 10;
//核心线程数
executor.setCorePoolSize(corePoolSize);
int maxPoolSize = 50;
//最大线程数
executor.setMaxPoolSize(maxPoolSize);
int queueCapacity = 10;
//队列长度
executor.setQueueCapacity(queueCapacity);
//线程拒绝策略:将任务返还给调用者线程执行
executor.setRejectedExecutionHandler(new ThreadPoolExecutor.CallerRunsPolicy());
String threadNamePrefix = "dfsTaskExecutor-";
//线程名称
executor.setThreadNamePrefix(threadNamePrefix);
// 1、告诉线程池,在销毁之前执行shutdown方法
// 2、设置线程池中任务的等待时间,如果超过这个时候还没有销毁就强制销毁,以确保应用最后能够被关闭,而不是阻塞住
executor.setWaitForTasksToCompleteOnShutdown(true);
int awaitTerminationSeconds = 60;
executor.setAwaitTerminationSeconds(awaitTerminationSeconds);
executor.initialize();
return executor;
}
@Override
public Executor getAsyncExecutor() {
return executor();
}
@Override
public AsyncUncaughtExceptionHandler getAsyncUncaughtExceptionHandler() {
return (ex, method, params) -> log.error("执行异步任务{}", method,ex);
}
}
六、编写业务接口,动态配置kafka
该方法只需在自己创建的service实现类里添加即可
@Override
public void saveKafkaConfig() {
// 获取数据库中的kafka配置
List<ConfigKafkaEntity> configKafkaEntities = configKafkaService.list();
if (CollectionUtils.isEmpty(configKafkaEntities)) {
return;
}
// 关闭已有的所有消费者对象
resourceNotifyConsumer.closeAllConsumer();
// 重新新增消费者
for (ConfigKafkaEntity configKafkaEntity : configKafkaEntities) {
this.createConsumer(configKafkaEntity);
}
AsyncConfiguration configuration = SpringUtil.getBean(AsyncConfiguration.class);
ThreadPoolTaskExecutor threadPoolTaskExecutor = configuration.executor();
// 持续监听kafka并消费数据
threadPoolTaskExecutor.execute(() -> resourceNotifyConsumer.onMessage());
}
/**
* 创建消费者
*/
private void createConsumer(ConfigKafkaEntity configKafkaEntity) {
Properties props = new Properties();
props.setProperty("bootstrap.servers", configKafkaEntity.getKafkaIp() + ":" + configKafkaEntity.getKafkaPort());
// key反序列化
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
// value反序列化
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
// 每个消费者都必须属于某一个消费组,所以必须指定group.id
props.put("group.id", configKafkaEntity.getGroupIp());
props.put("auto.offset.reset", configKafkaEntity.getGetInfoType());
props.put("enable.auto.commit", true);
props.put("auto.commit.interval", 100);
props.put("max.poll.records", 100);
KafkaConsumer<String, String> consumerObj;
// 构造消费者对象
List<String> topics = Arrays.stream(configKafkaEntity.getTopics().split(Constant.SEP)).collect(Collectors.toList());
try {
consumerObj = new KafkaConsumer<>(props);
consumerObj.subscribe(topics);
resourceNotifyConsumer.setConsumer(consumerObj);
} catch (Exception e) {
log.error("创建消费者失败", e);
}
}
七、创建controller层,用于接口调用
@Slf4j
@RestController
@AllArgsConstructor
@RequestMapping("/kafka")
public class kafkaController extends BaseController {
private KafkaServicekafkaService;
@PostMapping("/config")
public ResponseData kafka() {
kafkaService.saveKafkaConfig();
return success();
}
}
八、使用postman测试效果
通过postman调用接口,动态配置kafka消费者
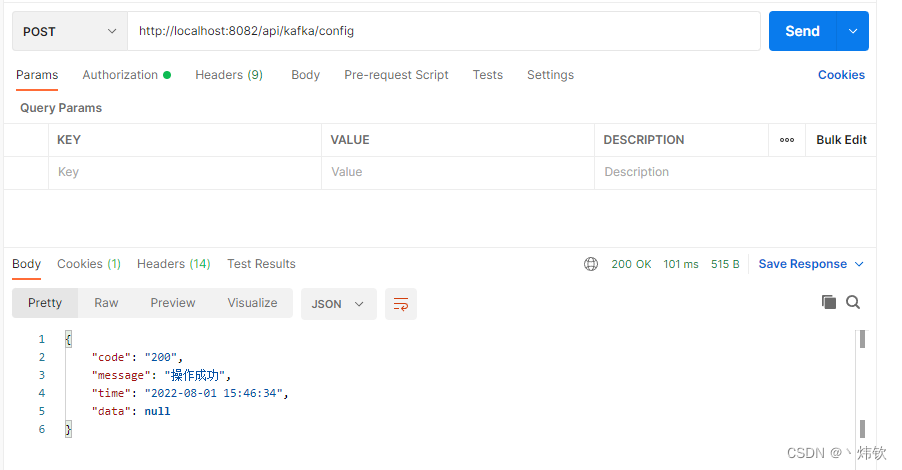
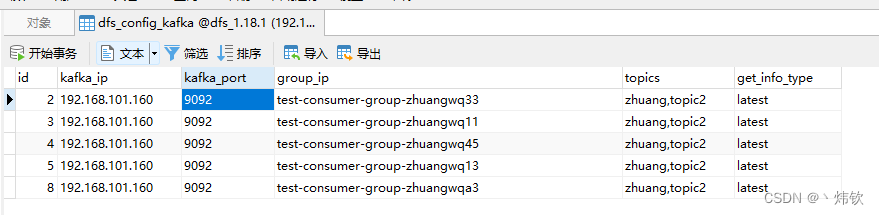
数据库中的配置数据如下图所示
往kafka丢一条数据看看效果
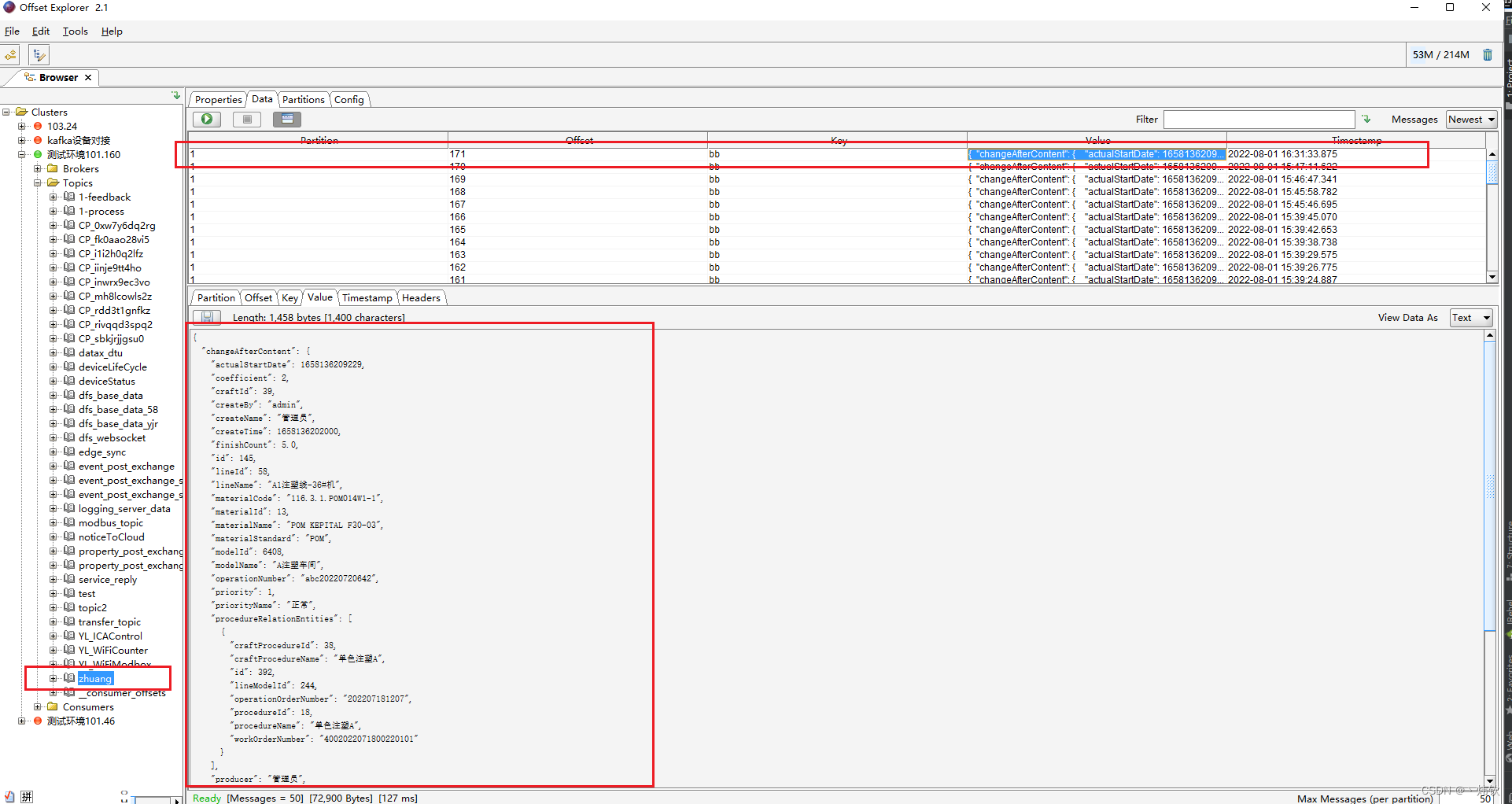
通过调用接口发现,每个消费者都对数据进行了消费,测试成功。

九、科普一下代码中涉及到的知识点
KafkaConsumer消费者订阅时的subscribe()和assign() 的区别
通过 subscribe() 方法订阅主题具有消费者自动再均衡的功能,在多个消费者的情况下可以根据分区分配策略来自动分配各个消费者与分区的关系。当消费组内的消费者增加或减少时,分区分配关系会自动调整,以实现消费负载均衡及故障自动转移。而通过 assign() 方法订阅分区时,是不具备消费者自动均衡的功能的,其实这一点从 assign() 方法的参数中就可以看出端倪 作者:同和杂拌通 https://www.bilibili.com/read/cv5867810 出处:bilibili
十、调试代码中可能需要的问题
1、如果消费者没有订阅任何主题或分区,那么再继续执行消费程序的时候会报出 IllegalStateException 异常: Consumer is not subscribed to any topics or assigned any partitions ,此时需要确保消费者成功订阅消息,或者在删除消费者的时候,需要确保消费者成功取消订阅。
2、报错:java.util.ConcurrentModificationException: KafkaConsumer is not safe for multi-threaded access, 通过递归删除消费者即可解决。














 658
658











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









