







代码随想录算法训练营四天 | LeetCode24 两两交换链表中的节点 、LeetCode19删除链表的倒数第N个节点 、LeetCode160链表相交、LeetCode142环形链表II
时长:大约4小时
24. Swap Nodes in Pairs
Given a linked list, swap every two adjacent nodes and return its head. You must solve the problem without modifying the values in the list's nodes (i.e., only nodes themselves may be changed.)
Example 1:
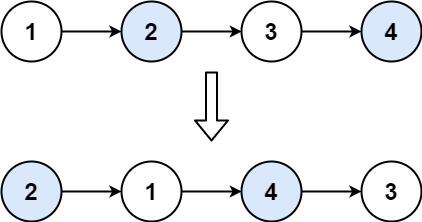
Example 2:
Example 3:
Constraints:
The number of nodes in the list is in the range [0, 100].
0 <= Node.val <= 100
解题思路:
要使用dummyHead统一处理
要交换节点时,需要记录以下信息
prev:要交换的第一个节点的前一个节点
cur:要交换的第一个节点
next:要交换的第二个节点
nnext:要交换的第二个节点的下一个节点
交换步骤:
cur->next = nnext;
prev->next=next;
next->next=cur;
prev = cur;//进入下一次迭代终止条件:
奇数个节点(不包含dummyHead)
prev->next->next == NULL
偶数个节点(不包含dummyHead)
prev->next = NULL
需要注意的要点:
终止条件要理清一下
每次交换涉及四个节点
迭代条件是对prev判断
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* swapPairs(ListNode* head) {
if (head == NULL || head->next == NULL) {
return head;
}
ListNode* dummyHead = new ListNode(0);
dummyHead->next = head;
ListNode* prev = dummyHead;
ListNode* cur;
ListNode* next;
ListNode* nnext;
/*
dummyHead->1--->2---->3----->4
prev------>cur->next->nnext->...
*/
while(prev->next != NULL && prev->next->next != NULL) {
cur = prev->next;
next = cur->next;
nnext = next->next;
cur->next = nnext;
prev->next = next;
next->next = cur;
prev = cur;
}
return dummyHead->next;
}
};160. Intersection of Two Linked Lists
Given the heads of two singly linked-lists headA and headB, return the node at which the two lists intersect . If the two linked lists have no intersection at all, return null.
For example, the following two linked lists begin to intersect at node c1:
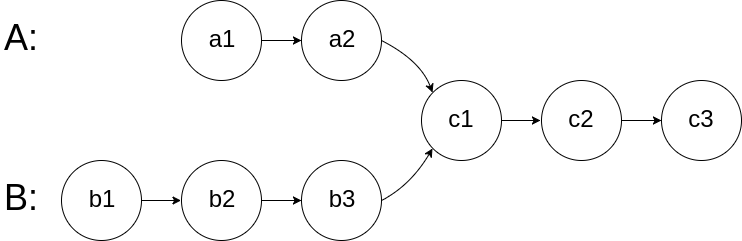
The test cases are generated such that there are no cycles anywhere in the entire linked structure.
Note that the linked lists must retain their original structure after the function returns.
Custom Judge:
The inputs to the judge are given as follows (your program is not given these inputs):
intersectVal - The value of the node where the intersection occurs. This is 0 if there is no intersected node.
listA - The first linked list.
listB - The second linked list.
skipA - The number of nodes to skip ahead in listA (starting from the head) to get to the intersected node.
skipB - The number of nodes to skip ahead in listB (starting from the head) to get to the intersected node.
The judge will then create the linked structure based on these inputs and pass the two heads, headA and headB to your program. If you correctly return the intersected node, then your solution will be accepted .
Example 1:
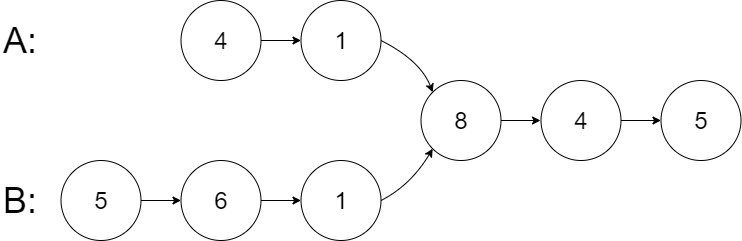
Example 2:
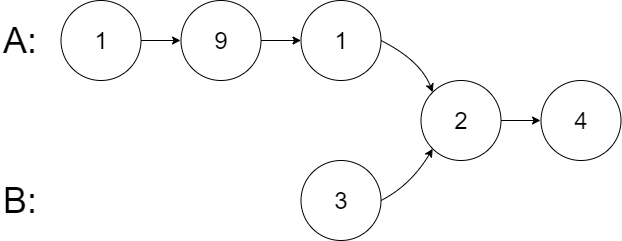
Example 3:
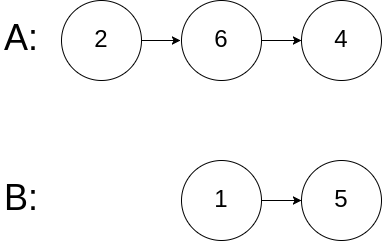
Constraints:
The number of nodes of listA is in the m.
The number of nodes of listB is in the n.
1 <= m, n <= 3 * 10<sup>4</sup>
1 <= Node.val <= 10<sup>5</sup>
0 <= skipA < m
0 <= skipB < n
intersectVal is 0 if listA and listB do not intersect.
intersectVal == listA[skipA] == listB[skipB] if listA and listB intersect.
Follow up: Could you write a solution that runs in O(m + n) time and use only O(1) memory?
解题思路:
1.先遍历计算两个链表的长度
2.把两个链表的末尾对齐(即让长的链表先走几步,直到当前指针到所指向的子链表长度与锻炼相同)
3.两个指针一起走,直到两个指针相同,即为交点
需要注意的要点:
这题思路有点意思,肯定应该是在末尾对齐的时候找
末尾对齐的方法就是扔掉长链表多出来的地方
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
ListNode *getIntersectionNode(ListNode *headA, ListNode *headB) {
ListNode * dummyHeadA = new ListNode(0);
dummyHeadA->next = headA;
ListNode * curA = dummyHeadA->next;
ListNode * dummyHeadB = new ListNode(0);
dummyHeadB->next = headB;
ListNode * curB = dummyHeadB->next;
int LenA = 0;
int LenB = 0;
while(curA != NULL) {
curA = curA->next;
LenA ++;
}
while(curB != NULL) {
curB = curB->next;
LenB ++;
}
curA = dummyHeadA->next;
curB = dummyHeadB->next;
if(LenA > LenB) {
int index = LenA - LenB;
while(index--) {
curA = curA->next;
}
}
else {
int index = LenB - LenA;
while(index--) {
curB = curB->next;
}
}
while(curA != NULL) {
if(curA == curB) {
return curA;
}
curA = curA->next;
curB = curB->next;
}
return NULL;
}
};
19. Remove Nth Node From End of List
Given the head of a linked list, remove the n<sup>th</sup> node from the end of the list and return its head.
Example 1:
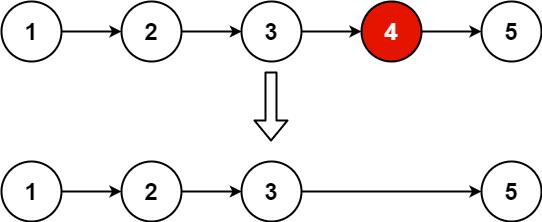
Example 2:
Example 3:
Constraints:
The number of nodes in the list is sz.
1 <= sz <= 30
0 <= Node.val <= 100
1 <= n <= sz
Follow up: Could you do this in one pass?
解题思路:
走两遍:
1.第一遍算链表长度
2.第二遍移除元素
2.走一遍
1.加入dummyHead
2.fast、slow指针都指向dummyHead
3.fast先走N+1步
4. fast,slow一起走,当fast为NULL,此时slow指向倒数第N个节点的前一个节点,进行删除
需要注意的要点:
要删除节点K,一定要指向节点K的前一个节点才行;
快指针先走的时候要注意循环条件判空
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* removeNthFromEnd(ListNode* head, int n) {
ListNode* dummyHead = new ListNode(0);
dummyHead->next = head;
ListNode* fast = dummyHead;
ListNode* slow = dummyHead;
n ++;
while(n -- && fast != NULL) {
fast = fast->next;
}
while(fast != NULL) {
fast = fast->next;
slow = slow->next;
}
ListNode* tmp = slow->next;
slow->next = slow->next->next;
delete tmp;
return dummyHead->next;
}
};142.
Given the head of a linked list, return the node where the cycle begins. If there is no cycle, return null.
There is a cycle in a linked list if there is some node in the list that can be reached again by continuously following the next pointer. Internally, pos is used to denote the index of the node that tail's next pointer is connected to (0-indexed). It is -1 if there is no cycle. Note that pos is not passed as a parameter.
Do not modify the linked list.
Example 1:
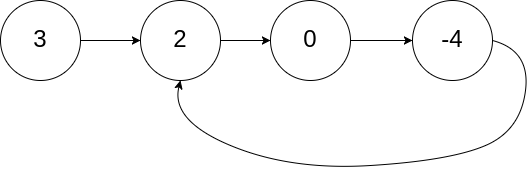
Input: head = [3,2,0,-4], pos = 1
Output: tail connects to node index 1
Explanation: There is a cycle in the linked list, where tail connects to the second node.
Example 2:
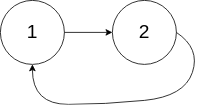
Input: head = [1,2], pos = 0
Output: tail connects to node index 0
Explanation: There is a cycle in the linked list, where tail connects to the first node.
Example 3:

Input: head = [1], pos = -1
Output: no cycle
Explanation: There is no cycle in the linked list.
Constraints:
The number of the nodes in the list is in the range [0, 104].
-105 <= Node.val <= 105
pos is -1 or a valid index in the linked-list.
Follow up: Can you solve it using O(1) (i.e. constant) memory?
142. Linked List Cycle II
Given the head of a linked list, return *the node where the cycle begins. If there is no cycle, return *null.
There is a cycle in a linked list if there is some node in the list that can be reached again by continuously following the next pointer. Internally, pos is used to denote the index of the node that tail's next pointer is connected to ( 0-indexed ). It is -1 if there is no cycle. Note thatposis not passed as a parameter .
Do not modify the linked list.
Example 1:
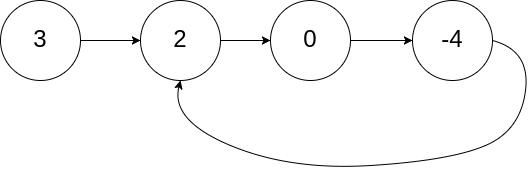
Example 2:
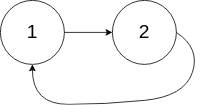
Example 3:

Constraints:
The number of the nodes in the list is in the range [0, 10<sup>4</sup>].
-10<sup>5</sup> <= Node.val <= 10<sup>5</sup>
pos is -1 or a valid index in the linked-list.
Follow up: Can you solve it using O(1) (i.e. constant) memory?
解题思路:
Floyd判圈法:
fast指针一次走两步,slow指针一次走一步
两者第一次相遇,fast恰好比slow多走了n圈
两者第一次相遇:
(x+y)∗2=(y+z)∗n+y+x⟹x=(n−1)(y+z)+z
取n=1,则可知x = z
于是可在fast,slow第一次相遇后,把slow放回起点
slow,fast再次一步一步走
第一次相遇即是入环点
需要注意的要点:
Floyd判圈法,关键在于对数学的推导
理解为什么第一次相遇点的距离z与x相同
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
ListNode *detectCycle(ListNode *head) {
if (head == NULL) {
return NULL;
}
if(head->next == NULL) {
return NULL;
}
ListNode* fast = head;
ListNode* slow = head;
do {
if(fast == NULL || fast->next == NULL) {
return NULL;
}
fast = fast->next->next;
slow = slow->next;
} while(slow != fast);
slow = head;
int pos = 0;
while(slow != fast) {
slow = slow->next;
fast = fast->next;
pos ++;
}
return slow;
}
};
链表总结:
dummyHead技巧
删除链表节点一定要指向待删节点的前一个
终止条件
cur != NULL
cur->next != NULL
要注意判断
*ps:有的时候还要判断:
cur->next->next != NULL
声明:
文章中LeetCode的题目来自LeetCode官网:https://leetcode.cn/problems















 404
404











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









