







第三章 数据库结构设计
- 数据库概念设计
主要解决数据需求,即如何准确的理解数据需求- 概念设计的任务
(1)定义和描述应用领域涉及的数据范围。
(2)获取应用领域或问题域的信息模型。
(3)描述清楚数据的属性特征。
(4)描述清楚数据之间的关系。
(5)定义和描述数据的约束。
(6)说明数据的安全性要求。
(7)支持用户的各种数据处理需求。
(8)保证信息模型方便地转换成数据库的逻辑结构(数据库模式),同时也便于为用户
理解。
- 概念设计的依据及过程
- 概念设计的依据
是需求分析阶段的文档,包括需求说明胡素、功能模型(DFD或者IDEF0图)以及在需求分析阶段收集到的应用领域或问题域中的各类报表等
- 概念设计的过程
1. 明确建模目标
2. 定义实体集
3. 定义联系
用于描述实体集之间的联系关系—方法:实体集/联系矩阵
4. 建立信息模型
5. 确定实体集属性
6. 对信息模型进行集成与优化
- 概念设计的依据
- 数据建模方法
- ER(Entity Relationship) 建模方法
实体联系(ER)方法面向数据存储需求建模,将现实世界中需要处理的数据抽象组织成某种信息结构。这种不依赖于具体的计算机系统,仅从存储需求描述数据的属性特征及数据之间的关系。- 几个相关概念
- (1) 实体或实例(Instance)。实体指客观存在并可相互区分的事物(也称为实体集实例或实例)。实体可以是一个具体的人或物,如张三、一辆汽车等,也可以是抽象的事件或概念,如学生的一次选课、一场演出等。
- (2) 实体集。实体集表示一个现实的和抽象事物的集合,这些事物必须具有相同的属性或特征。例如,学生实休集指全部学生的集合。这个集合中的一个元系就是这个实体集的一个实例(Instance),用矩形框表示
- (3)属性。属性用于描述一个实体集的性质和特征。例如,学生 Student 实体集的属性有学号(Sno)、姓名(Sname),性别(Sex)、出生年月(Birh)等,人们用一组属性来描述一个实体集的属性特征。每个属性的取值范围称为域。用椭圆或圆角矩形框表示
- (4)码。实体集中能唯一标识每一个实例的属性或属性组称为该实体集的码,主码,
- (5) 联系。联系描述现实世界中实物之间的关系。eg:一个学生选了一门课程,一个供应商供应多种零件等。用菱形表示
现实世界事物之间的联系可归纳为三类:
1)一对一联系(1:1),eg:系和系主任
2)一对多联系(1:n),eg:系和学生
3)多对多联系(m:n),eg:学生和课程
- 实体联系(ER)建模方法
- ER方法中用矩形框表示实体集,矩形框内写上实体集的名称

- ER模型用菱形框表示联系,联系名写在菱形框内

- ER模型中,实体集的属性用椭圆或圆角矩形框表示,属性的名字写在椭圆或圆角矩形框中
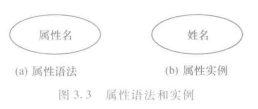
- ER方法中用矩形框表示实体集,矩形框内写上实体集的名称
- 几个相关概念
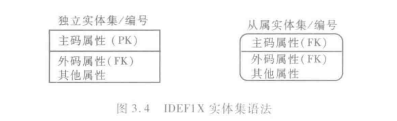
- IDEF1X 建模方法
- 实体集:IDEF1X 用矩形框来表示独立实体集,用加了圆角的矩形框来表示从属实体集。
- 联系
一个“确定型连接联系”(Specific Connection Relationship)或简称“连接联系”,实体集之间的一种连接或关系- 标定型联系(Identifying Relationship)
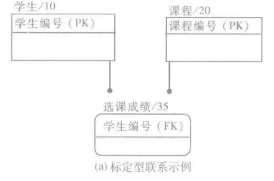
在“确定型连接联系”中,如果子女实体集中的每个实例都是由它与双亲的联系确定的,那么这个联系就被称为是“标定型联系”,父母项实线连接,子女段是线段终点,用实心圆点表示其联系的基数是N
- 非标定型联系(Non-Identifying Relationship)
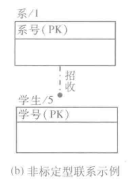
在“确定型连接联系”中,如果子女实体集中的每一个实例都能被唯一地确认而无须了解与之相联系的双亲实体集的实例,则该联系就被称为“非标定型联系”(Non-Identifying Relationship),非标定型联系用一条虚线把它们连接起来,1(父)端是线段的原点,n(子女)端是线段的终点,用一个实心圆点表示联系的基数是n。
- 分类联系(Categorization Relationship)
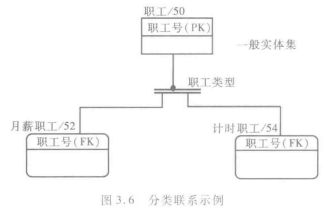
是两个或多个实体集之间的联系,且在这些实体集中存在一个一般实体集(Generi Entity),它的每一个实例都恰好与一个且仅一个分类实体集(Category Entity)的一个实例相联系。一般实体集的每一个实例和与之相关的一个分类实体集实例描述的是现实世界的同一事物,因此它们具有相同的唯一标识符。
- 非确定联系(Not-Specific Relationships)
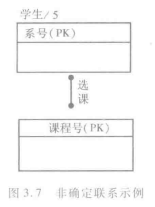
一个非确定联系又称为“多对多关系"(Many to Many Relationship)或m:n联系。在这种联系关联的两个实体集之间,任一实体集的一个实例都将对应另一实体集的0个、1个或多个实例
- 标定型联系(Identifying Relationship)
- 实体集:IDEF1X 用矩形框来表示独立实体集,用加了圆角的矩形框来表示从属实体集。
- ER(Entity Relationship) 建模方法
- 概念设计实例
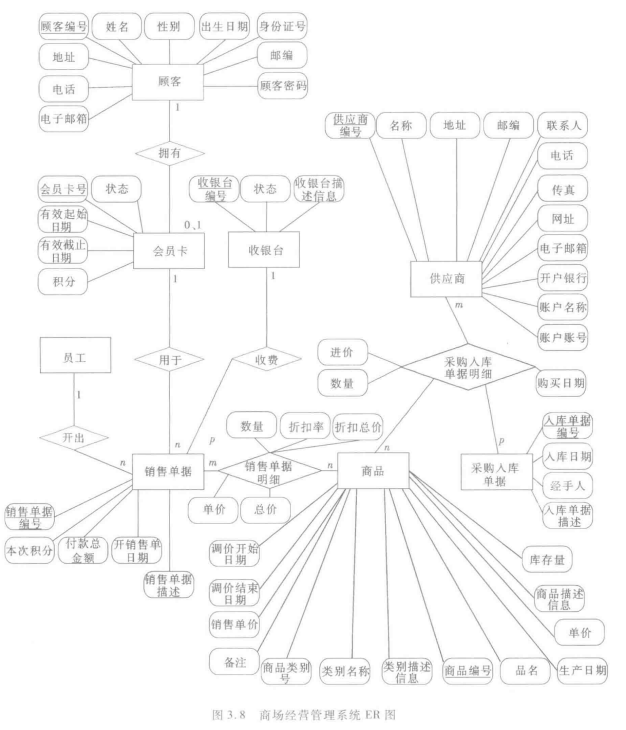
商场建立ER模型
- 概念设计的任务
- 数据库逻辑设计
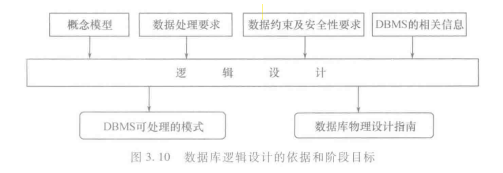
- 数据库逻辑设计的任务是:把数据库概念设计的结果(ER模型),转换为具体的数据库管理系统支持的数据模型
- 数据库逻辑设计的依据是:信息模型和数据库概念设计说明书,也是数据库用户确认数据需求的依据
- 数据库逻辑设计是面向机器世界的,这个阶段将按照具体数据库管理系统支持的数据模型来组织和存储数据,包括定义和描述数据库的全局逻辑结构、数据之间的关系、数据的完整性及安全性要求等。
- 相关概念
- 数据库三级模式
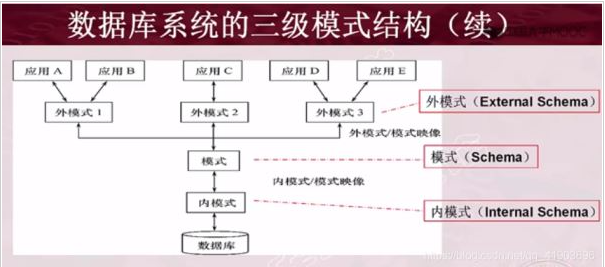
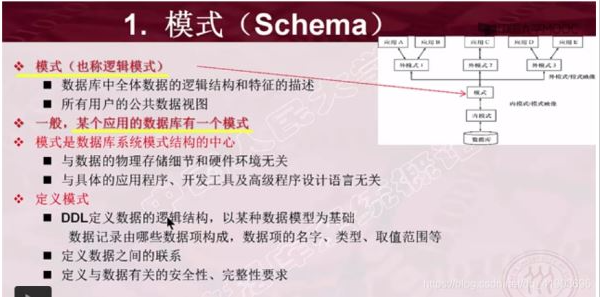
- 模式(逻辑模式或概念模式)
- 外模式(子模式或用户模式)

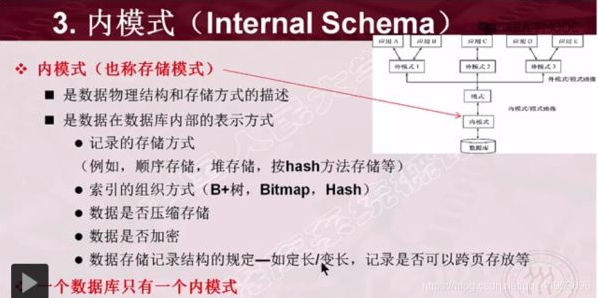
- 内模式(存储模式)
- 外模式/模式之间的映射

- 模式/内模式之间的映射

- 模式(逻辑模式或概念模式)
- 数据库的设计三范式(Normalization)
是关系型数据库设计的一种标准化过程,目的是消除冗余数据,提高数据存储的效率和数据查询的性能- 第一范式(1NF):确保每一列具有原子性,即每一列的数据都是不可分割的。
eg:一个订单表格中,每个订单只能有一个订单号,不能存在一列同时存储多个订单号。
- 第二范式(2NF):确保表格中的每一行数据只与该表格的主键有关系,即非主键列必须完全依赖于主键。
eg:一个订单表格中,每个订单只能对应一个客户,客户信息不应该存储在订单表格中,而应该单独建立一个客户表格。
- 第三范式(3NF):确保非主键列之间没有传递依赖关系,即不存在一个非主键列依赖于另一个非主键列。
eg:一个订单表格中,商品名、商品价格和商品数量应该分别存储在一个商品表格中,而不是存储在订单表格中。
- 巴斯-科德范式(BCNF):3NF基础上,任何主属性不能对主键子集依赖(在3NF基础上消除主属性对主码子集的依赖)。巴斯-科德范式(BCNF)是第三范式(3NF)的一个子集,即满足巴斯-科德范式(BCNF)必须满足第三范式(3NF)。
- 第一范式(1NF):确保每一列具有原子性,即每一列的数据都是不可分割的。
- 数据库函数依赖
数据库函数依赖是指在关系型数据库中,一个函数的返回值依赖于输入参数以及数据库中的数据。
- 数据库三级模式
- 数据库逻辑设计步骤
- 概念模型转化成逻辑模型
将ER图转换为关系模型实际上是将实体集、属性以及联系转换为相应的关系模式。- 将ER图转换成关系模式,一般包含两个步骤
第一个步骤是标识ER模型中的联系
第二个步骤是依次转换与每个联系相关联的实体集及联系
- 实体集的转换规则
概念模型中的一个实体集转换为关系模型中的一个关系,实体的属性就是关系的属性,实体的码就是关系的码,关系的结构是关系模式。- 1:1 (一对一) 联系
方法一:联系转换为独立的关系模式,模式的属性由联系本身的属性及两个实体的键构成,主键由两个实体中的任意一个键构成。
方法二::联系与一端的实体的关系模式合并,即将联系的属性加入到实体的关系模式内,主键不变。
- 1:n (一对多) 联系
方法一:联系转换为独立的关系模式,模式的属性由联系本身的属性及两个实体的键构成;主键由n端实体的键组成。
方法二:与n端的实体的关系模式合并,即将联系的属性加入到实体的关系模式内,主键不变。
- m:n (多对多) 联系
多对多联系转换成新的独立的模式,模式的属性由联系本身的属性及两个实体的键构成,主键由两端实体的键组合而成
- 1:1 (一对一) 联系
- 将ER图转换成关系模式,一般包含两个步骤
- 命名确认
根据项目选定的数据库管理系统支持的命名规则,检查确认关系名和属性名是否符合统命名规则。
- 优化关系模式
应用规范化理论逐一检查每一个关系模式,使之满足3NF。
- 概念模型转化成逻辑模型
- 数据库物理设计
- 物理设计概述
- 数据库物理设计的目的是将数据的逻辑描述转换为实现技术规范,其目标是设计数据存储方案,以便提供足够好的性能并确保数据库数据的完整性、安全性和可恢复性
- 在这个阶段,将根据数据库中存储的数据量、用户对数据库的使用要求和使用方式,选择数据存储方案以加快数据检索速度
- 在物理设计时需要了解不同文件组织方式、索引技术及其使用方法
- 数据库的物理结构
- 数据库中的应用数据是以文件形式存储在外设存储介质(如磁盘)上的,文件在逻辑上被组成记录的序列,每个DB文件可以看作是逻辑记录的集合
- 物理文件可以看作是由存放文件记录的一系列磁盘块组成的,文件的逻辑记录与磁盘块间的映身关系是由操作系统或DBMS来管理的.
- 从数据库物理结构角度需要解决的问题
- 文件的组织。如何将数据库映射到操作系统文件中,也即如何将关系数据库中的关系表映射为数据库文件,以及将关系表中的元组映射到文件的逻辑记录,如何管理这些数据库文件;数据库文件中逻辑记录采用何种格式
- 文件的结构。也称为文件中记录的组织。如何在外设磁盘上安排,存放数据库文件的逻辑记录,也即如何将 DB 文件的逻辑记录映射到物理文件中的磁盘块。
- 文件的存取。对具有某种结构的 DB 文件,如何去查找、插入,删除和修改其中的逻辑记录。文件的存取与文件的结构密切相关,每种文件结构都有与之对应的文件存取方法。
- 索引技术。当数据库中关系表的数目及关系表中的元组数目非常多时,可以利用索引技术提高 DB文件的存取速度
- 索引
索引技术(Indexing)是一种快速数据访问技术,它将一个文件的每个记录在某个或某些域(或称为属性)上的取值与该记录的物理地址直接联系起来,提供了一种根据记录域的取值快速访问文件记录的机制。- 定义:索引技术的关键是建立记录域取值到记录的物理地址间的映射关系,这种映射关系称为索引(Index)。
索引为性能所带来的好处是有代价的.因为索引在数据库中会占用一定的存储空间。
- 索引技术分类
根据索引的实现方式分为:有序索引和散列索引- 有序索引
- 也称为索引文件机制。有序索引技术利用案引文件(Index File)实现记录域取值到记录物理地址间的映射关系。这里的记录域就是查找码。索引文件由索引记录(Index Record)组成,每个记录中记载着一个索引项(Index Entry),索引项记录了某个特定的查找码值和具有该值的数据文件记录的物理地址。查找码也称为排序域。
- 散列索引
- 也称为哈希(Hash)索引机制。散列技术利用一个散列函数(Hash Function)实现记录域取值到记录物理地址间的直接映射关系。这里的记录域就是查找码,也称为散列函数的散列域或排序域。
- 有序索引
- 有序索引
数据文件和索引文件是有序索引技术中的两个主体,数据文件也称为被索引文件(IndexedFile)或主文件- 聚集索引和非聚集索引
对数据文件和它的一个特定的索引文件,如果数据文件中数据记录的排列顺序与索引文件中索引项的排列顺序相一致,或者说索引文件按照其查找码指定的顺序与数据文件中数据记录的排列顺序相一致,则称该索引文件为聚集索引(Clustering Index):否则,称该索引文件为非聚集索引(Non-elustering Index)
在一个数据文件上除了可以建立一个聚集索引外,还可以建立多个非聚集索引
- 稠密索引和稀疏索引
如果数据文件中的每个查找码值在索引文件中都对应一个索引记录,则该索引称为稠密索引(Dense Index)。如果只是一部分查找码的值有对应的索引记录,则该索引称为稀疏索引Sparse Index)
- 主索引和辅索引
在数据文件的主码属性集上建立的索引称为主索引(Primary Index)。在数据文件的非主属性上建立的索引称为辅索引(Secondary Index)
- 唯一索引
唯一索引可以确保索引列不包含重复的值
- 单层索引和多层索引
单层索引也称为线性索引,其特点是索引项根据键值在索引文件中顺序排列,组织成一维线性结构,每个索引项直接指向数据文件中的数据记录
多层索引的典型例子是数据库系统中广泛应用的 B树和 B树案引。
- 聚集索引和非聚集索引
- 定义:索引技术的关键是建立记录域取值到记录的物理地址间的映射关系,这种映射关系称为索引(Index)。
- 数据库物理设计
数据库物理结构设计是在具体的硬件环境、操作系统和 DBMS 约束下,根据数据库逻辑设计结果设计合适的数据库物理结构。其目标是得到存储空间占用少、数据访问效率高和维护代价低的数据库物理模式- 数据库逻辑模式描述。
将与平台无关的描述数据库逻辑结构的关系模式及其视图转换为所选定的具体 DBMS 平台可支持的基本表和视图并利用 DBMS 提供的完整性机制(如触发器)设计定义在基本表上的面向应用的业务规则- (1)面向目标数据库描述基本表和视图
- (2)设计基本表业务规则
- 文件组织与存取设计。
选择或配置基本表的文件组织形式,如堆文件、顺序文件,索引文件,散列文件等;根据实际情况,为基本关系表设计合适的存取方法和存取路径- 下面给出一些为基本表选择合适的文件结构的原则:
- (1) 如果数据库中的一个基本表中的数据量很少,并且插入,删除、更新等操作非常频繁,该基本表可以采用堆文件组织方式。因为堆文件无须建立索引.维护代价非常低。虽然堆文件的数据访问效率较低,但在数据量很少时,定位文件记录的时间非常短。当需要向新创建的基本表批量加载数据时,可将表的文件结构先选为堆文件,向表中加载数据后再重新调整文件结构,如改为数据查询效率更高的 B树文件。
- (2) 顺序文件支持基于查找码的顺序访问,也支持快速的二分查找。如果用户的查询条件定义在查找码上,则顺序文件是比较合适的文件结构。
- (3) 如果用户查询是基于散列域值的等值匹配.特别是如果访问顺序是随机的,则散列文件比较合适。
但散列文件组织不适合下述情况:
基于散列域值的非精确查询(如模糊查询范围查询)。
基于非散列域进行的查询
- (4) B-树和 B+树文件是实际数据库系统中使用非常广泛的索引文件结构,适合于定义在大数据量基本表上、基于查找码的等值查询,范围查询、模糊查询和部分查询。B-树和 B+树属于动态索引.可以随着数据文件的内容变化不断调整,保证数据查询的性能不会恶化。
- (5)如某些频繁执行且需要进行多表连接操作的查询,可以考虑将这些基本表组织为聚集文件,以改善查询效率
- 可根据下述原则决定是否为一个基本表建立索引:
- (1) 对于经常需要进行查询、连接统计操作,且数据量大的基本表可考虑建立索引;而对于经常执行插入删除,更新操作或小数据量的基本表应尽量避免建立索引。
- (2) 一个基本表上除了可以建立一个聚集索引外,还可以建立多个非聚集索引。多个索引为用户提供了根据多个查找码快速访问文件的手段。但是索引越多,对表内数据更新时为维护索引所需的开销就越大。因此,对于一个更新频繁的表应少建或不建索引。
- (3) 索引可以由用户根据需要随时创建或删除,以提高数据查询性能。
- 下面给出一些为基本表选择合适的文件结构的原则:
- 数据分布设计。
根据数据类型、作用和使用频率的不同,将数据库中应用数据、索引、日志,备份数据等不同类型数据合理安排在磁盘、磁带等不同存储介质中;根据实际需要,对分布式数据库系统中的应用数据设计合理的数据副本,通过水平划分或垂直划分分制成不同的数据片断,然后分布存储在各局部数据库中,以提高系统的数据访问效率和数据可靠性;考虑关系模式中派生属性的存储方式.合理调整关系模式的规范化程度,以便在数据存储代价和数据访问效率之间作合理的权衡折中- (1) 不同类型数据的物理分布
数据库系统中不仅有组织为基本表的应用数据,还有索引、日志、数据库备份数据等其他类型数据。
数据库备份数据、日志文件备份数据用于故障恢复,使用频率低,而且数据量很大,可以存储在磁带中。而应用数据、索引和目志则使用频繁,要求的响应时间短,必须放在支持直接存取(Direct Access)的磁盘存储介质上
当系统采用 RAID 等多磁盘存储系统时,可以将基本表和建立在表上的索引分别放在不同的磁盘上。这样在访问基本表时,存放数据和存放索引的磁盘驱动器并行工作,可以得到较快的文件读写速度,类似地,日志文件与数据库对象(表、索引等)也可分别存放在不同磁盘上以改善系统I/0性能。
- (2) 应用数据的划分与分布
根据数据的使用特征划分。
根据时间、地点划分。
分布式数据库系统(Distribued DataBase Svstem,DDBS)中的数据划分- 水平划分将一张基本表划分为多张具有相同属性、结构完全相同的子表,子表包含的元组是基本表中元组的子集。各子表可以有公共元组,也可以分别包含完全不同的元组。如对商品拉照商品的生产年份进行划分就属于水平划分
- 垂直划分则是将一张基本表划分为多张子表,每张子表包含的属性是原基本表的子集。
- (3) 派生属性数据分布
- (4) 关系模式的去规范化
- (1) 不同类型数据的物理分布
- 确定系统配置。
根据应用环境和物理设计结果.合理设置和调整 DBMS 和操作系统的存储分配参数,提供系统软硬件平台的初始配置信息。
- 物理模式评估。
对数据库物理设计结果从时间、空间、维护代价等方面进行评估,从多种可行方案中选择合理的数据库物理结构。
- 数据库逻辑模式描述。
- 物理设计概述















 749
749











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









