







记录添加vm子网失败后的寻找过程,
-
创建微软云虚拟机时会选择cpu内存等参数如下图,可以看出有cpu、内存打开sell all sizes 后可以看到一个列表多了一类型、可挂载磁盘数等信息还是没有我们需要的网卡数据
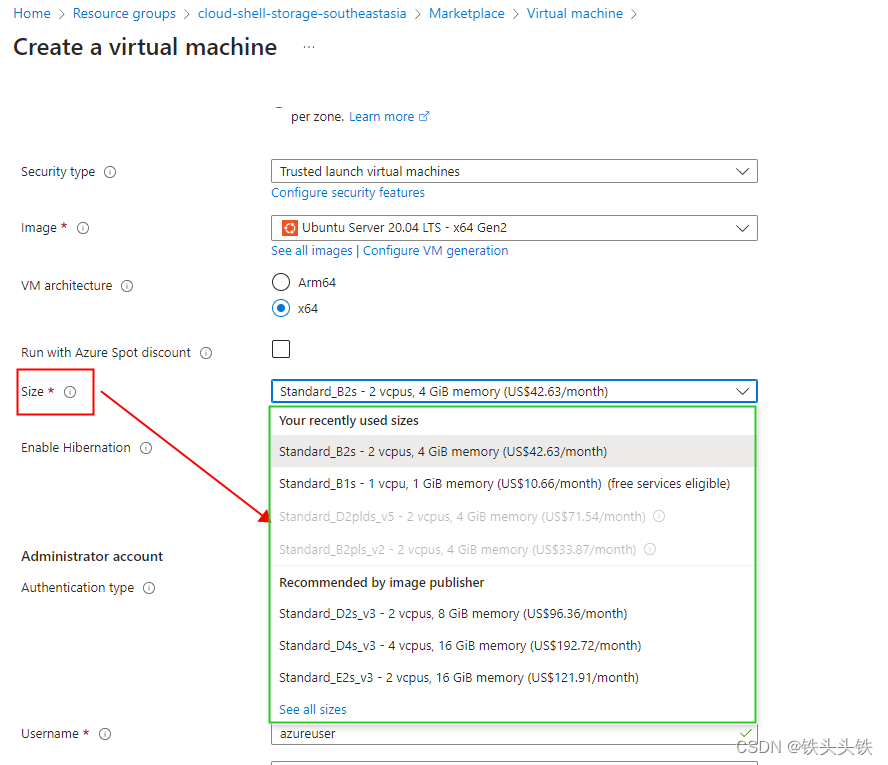
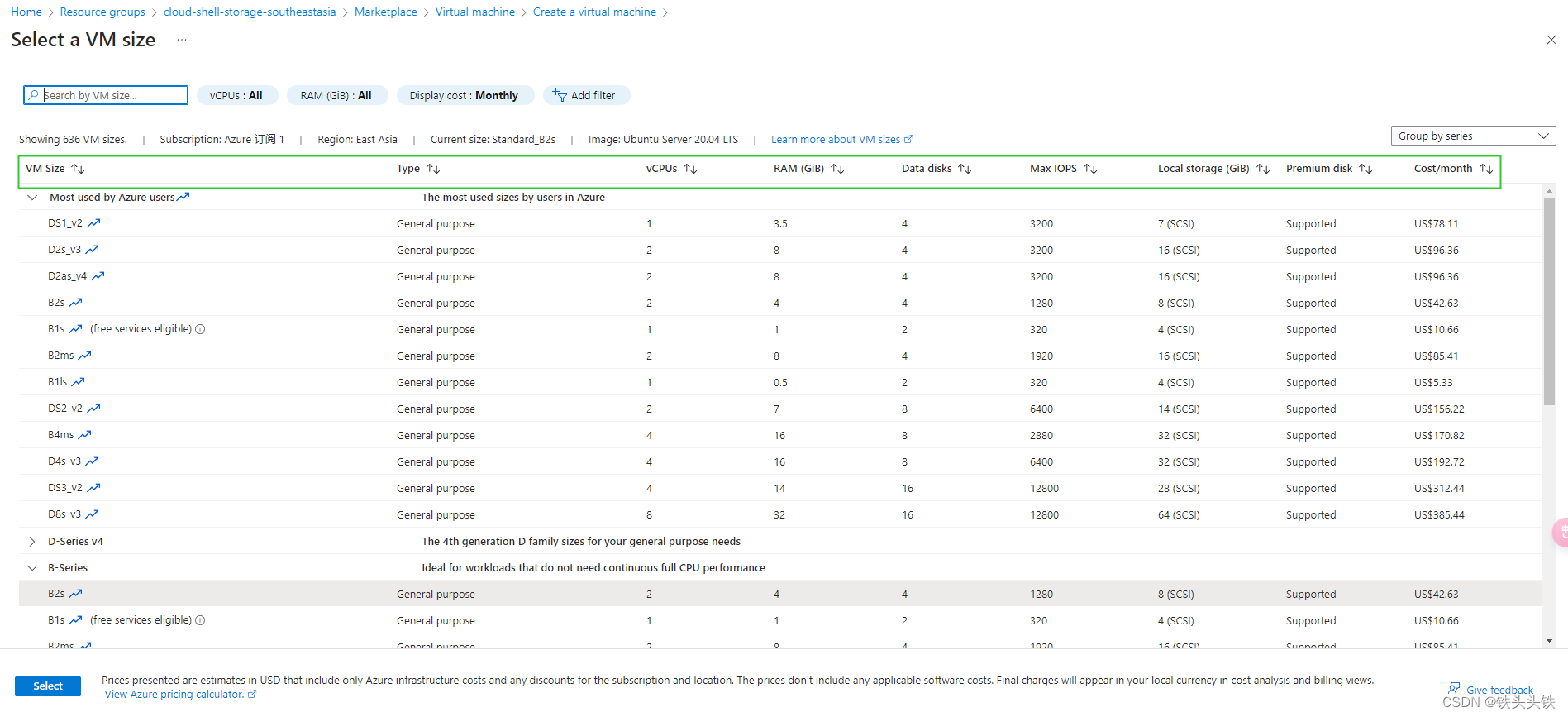
-
要看到网卡数据需要翻找文档
文档内有所有的vmSize数据和对照表,这里有点难受表需要放大后才看得到网卡数一不小心就错过
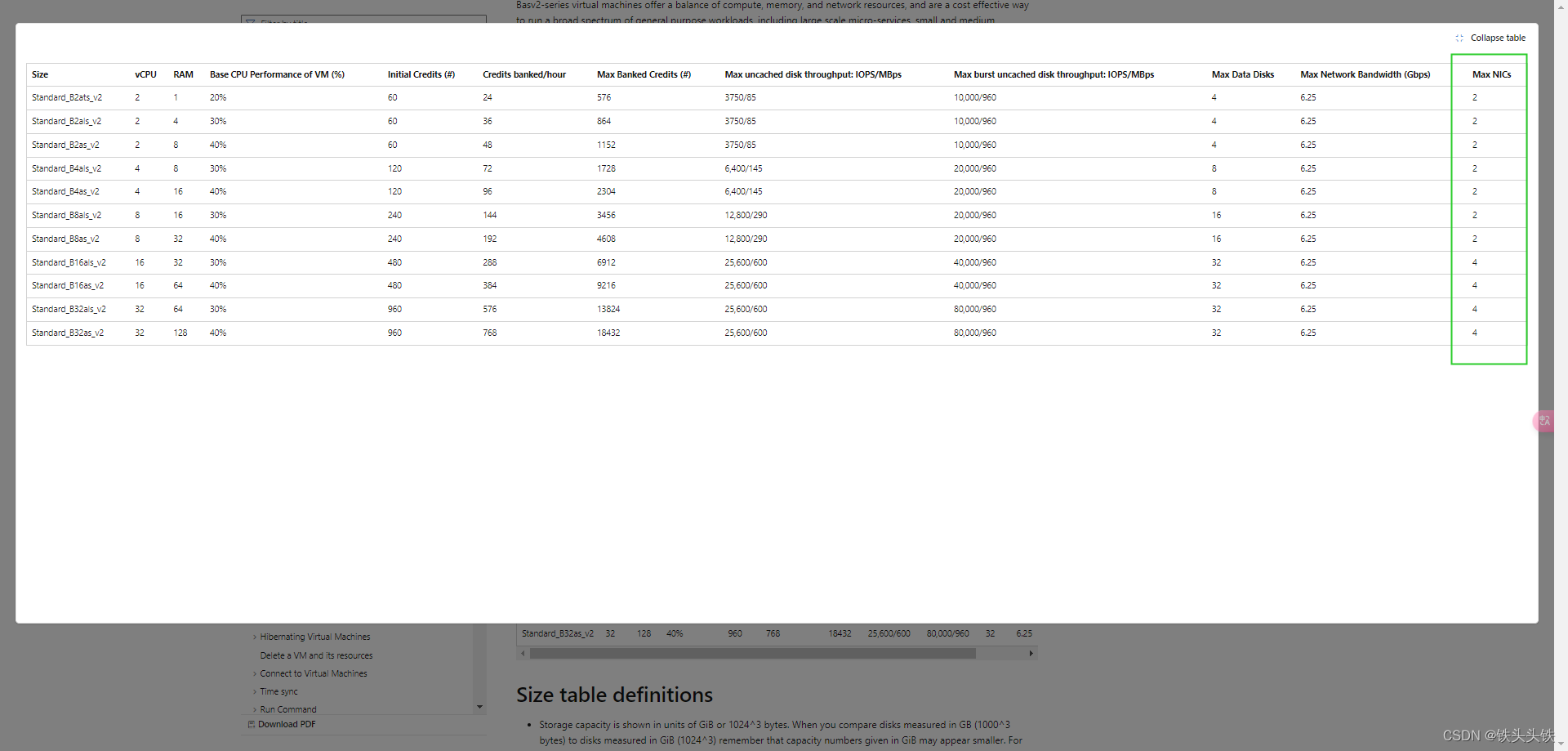
-
代码
当然作为开发人员、这些基础数据还是需要在库中保存一份,可以选择全部同步或者只拿几个常用的。
简单解释下所用方法.getResourceSkus().list();
- 通过AzureJavaSDK知道list中可以放location参数直接拿到 ASIA_EAST(东亚)的所有sku数据,尝试多次均失败并在网络上没有找到相关demo可供参考。
- sku还有其他比如disk数据拿ComputeResourceType.VIRTUALMACHINES过滤一遍,再用地区过滤一遍。
- 官方参考
ArrayList<Map<String,String>> dataMaps = new ArrayList<>(); PagedIterable<ResourceSkuInner> list = azureResourceManager .virtualMachines() .manager() .serviceClient() .getResourceSkus() .list(); // 使用 Set 来存储已经出现过的 sku.name(),保证不重复 Set<String> uniqueNames = new HashSet<>(); for (ResourceSkuInner sku : list) { if (ComputeResourceType.VIRTUALMACHINES.toString().equals(sku.resourceType())) { String name = sku.name(); List<String> locations = sku.locations(); if (!uniqueNames.contains(sku.name()) && (locations.contains(Region.ASIA_EAST.label())||locations.contains(Region.ASIA_EAST.name()))) { // 如果当前 sku.name() 没有出现过,则添加到 uniqueNames 集合中,并保留这个 sku 作为第一个唯一的 sku uniqueNames.add(sku.name()); // 将 capabilities 转换为一个 Map,并直接添加到 dataMap 中 Map<String, String> capabilityMap = sku.capabilities().stream() .collect(Collectors.toMap(ResourceSkuCapabilities::name, ResourceSkuCapabilities::value)); // 添加 name 和 capabilityMap 到 dataMap capabilityMap.put("name",name); dataMaps.add(capabilityMap); } } } return dataMaps;















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









