






英文名为:Regular Expression,我们一般简写为regex、regexp或RE,它是对字符串进行操作检索,替换,验证的一种逻辑公式。下面我们用JavaScript和C#来使用正则表达式,这是我学习到的知识,给大家讲一下我上课的例子
JavaScript对正则表达式的支持有三个标志(flags):g表示全局模式(global);i :表示不区分大小写模式(ignore);m:表示多行模式(multiple)。
expression.test() 检测一个字符串是否匹配某个模式,如果含有相匹配的文本,就返回true否则flase

expression.exec() 检索字符串string 含有直接返回一个数组,否则null
C#正则表达式引用的类主要是
System.Text.RegularExpressions.Regex,常用有4个方法:
*测试:Regex.IsMatch(“被测试字符串”, “正则表达式”, “正则表达式选项/模式”)
bool test = Regex.IsMatch(strTest, “[a‐z]”, RegexOptions.IgnoreCase);
*匹配出第一条结果:Regex.Match(“被匹配字符串”, “正则表达式”, “正则表达式选项/模式”)
Match match = Regex.Match(strTest, “[a‐z]”, RegexOptions.IgnoreCase);
*匹配出所有结果: Regex.matchs(“被匹配字符串”, “正则表达式”, “正则表达式选项/模式”)
MatchCollection matchs = Regex.Matches(strTest, “[a‐z]”, RegexOptions.IgnoreCase);
foreach (Match item in matchs) { //具体处理代码 }
*替换:Regex.matchs(“被匹配字符串”, “正则表达式”, “替换字符”, “正则表达式选项/模式”)
string str2 = Regex.Replace(strTest, “[a‐z]”, “1”);
下面截一个我学习获得的图,给大家提供一个参考,不作任何使用
单个匹配和反义(匹配一个位置的字符)
在中括号中,特殊代码不会被解释成其它意义

重复

表达式默认是贪婪型的,通常的行为是匹配尽可能多的字符, 但是我们更需要懒惰匹配,,也就是匹配尽可能少的字符,只要在前面重复元字符加上?,就可以转换成懒惰匹配

如果查询.或者*,这些特殊代码,就必须使用\
如果要重复字符串就要用{}来指定子表达式(分组),你就可以指定这个子表达式的重复次数了。比如我们要查询ip地址,使用(\d{1,3}.){3}\d{1,3}这个表达式是正确的,但是也可以匹配不存在的ip地址,我们知道ip地址中每个数字中是0-255。所以要匹配正确的ip地址就要使用分组((2[0‐4]\d|25[0‐5]|[01]?\d{1,2}).){3}(2[0‐4]\d|25[0-5]|[01]?\d{1,2})。
后向引用
用于重复搜索前面某个分组匹配的文本。默认情况下,每个分组会自动拥有一个组号,规则是:从左向右,以分组的左括号为标志
我们也可以自己指定子表达式的组名。(?[regExp]) 或者(?‘word’[regExp])
要反向引用这个分组 捕获 的内容,就可以使用 \k 或者 \k’word’
后向引用的原理是:当捕获组(Expression)在匹配成功时,会将子表达式匹配到的内容保存在内存中以一个数字编号或者自己命名为key的组里,这样就可以通过后向引用的方式引用匹配到的内容。
(exp) — 匹配exp,并捕获文本到自动命名的组里
(?exp) — 匹配exp,并捕获文本到名称为name的组里
(?:exp) — 匹配exp,不捕获匹配的文本
([a‐zA‐Z])\1 —\1 代表分组1匹配的文本,匹配连续出现的单词
位置指定和负向位置指定

注释
(?#comment) 不对正则表达式的处理产生任何影响,只是为了提供让人阅读注释,在写好的代码后面可以加上自己的注释,这样可以更好的理解代码。这里打上去你们看不见,因为它支持这种写法,所以只能截图了
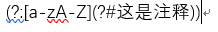
替换 可以使用 $1、$2 等来引用对应分组的值
正则表达式:([a‐zA‐Z])\1
替换字符串 +$1
替换为+x
正则表达式使用一般不会单个元字符匹配,一般都是组合使用。所以上面给大家提供一个我上课的资料作为参考,希望可以帮助大家理解正则表达式,有什么错误的地方请指正!














 5289
5289











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









