







windows上利用Python批量下载ERA-20C数据
Python小白一个,以前都是手动下ERA数据的,这次由于要下载ERA-20C不能全选所需要的时间,只能用程序批量下载。试了很多办法都行不通,可能是环境变量不匹配导致的,最终用anaconda实现,分为anaconda安装python、加载ecmwfapi和下载资料三步。
1. 利用anaconda安装python
具体方法参考这篇博文:通过Anaconda安装Python3.7
2. 加载ecmwf
pip install ecmwf-api-client
详情见链接:ECMWF加载ecmwf包
3. 下载资料
(1)在电脑中打开Jupyter Notebook,即弹出界面和网页,在网页右侧点击“New”新建一个py文件备用。


Jupyter Notebook界面:
(2)在官网找到ERA-20C的资料,以surface的ERA-20C数据为例:
选择一个年份,选择所需变量,划至最下方点击左侧按钮View data retrieval request,将弹出来的页面中Python script选项卡中的脚本复制到刚刚在Jupyter Notebook新建的脚本.py中

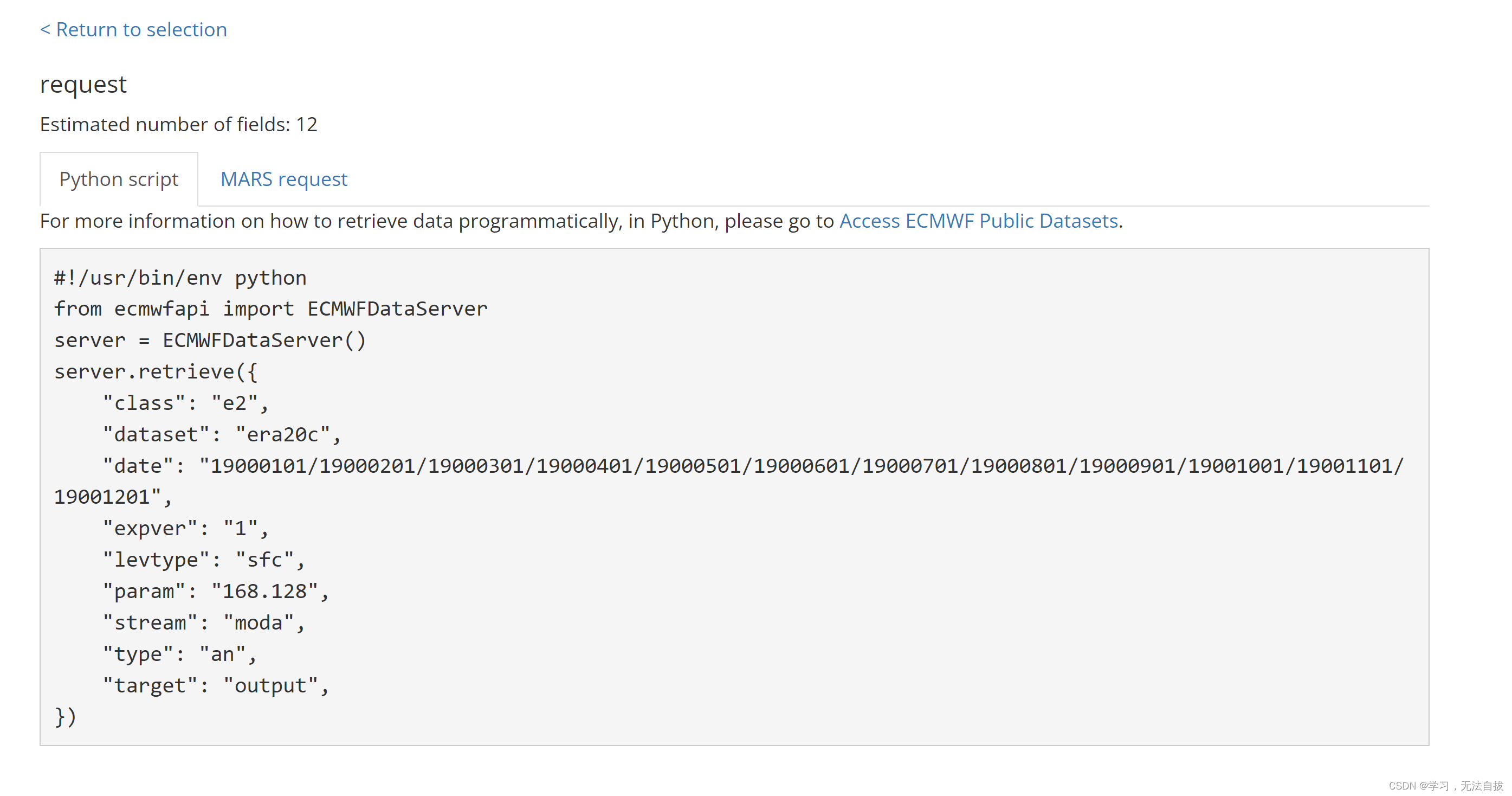
(3)更改代码,批量下载。
最主要的是设置循环,使时间变量可以一直变,并且文件名也要一直变,运用了最简单的方法,代码如下
from ecmwfapi import ECMWFDataServer
for year in range(1950,2010): # 根据需要设置循环年份
time=str(year)
filename=time+"0101/"+time+"0201/"+time+"0301/"+time+"0401/"+time+"0501/"+time+"0601/"+time+"0701/"+time+"0801/"+time+"0901/"+time+"1001/"+time+"1101/"+time+"1201"
target="F:/ERA-20C_surface_"+time+".nc" # 根据需要设置下载的文件储存位置
server = ECMWFDataServer()
server.retrieve({
"class": "e2",
"dataset": "era20c",
"date": "19000101/19000201/19000301/19000401/19000501/19000601/19000701/19000801/19000901/19001001/19001101/19001201",
"expver": "1",
"levtype": "sfc",
"param": "168.128", # 根据需要选择变量名
"stream": "moda",
"type": "an",
"grid": "2.0/2.0", # 根据需要设置分辨率,这里用的是2°的
"format": "netcdf", # 根据需要设置分辨率,这里用的是nc,还可以设为grib
"target": target,
})
然后点击上方的“运行”按钮就开始下载啦:
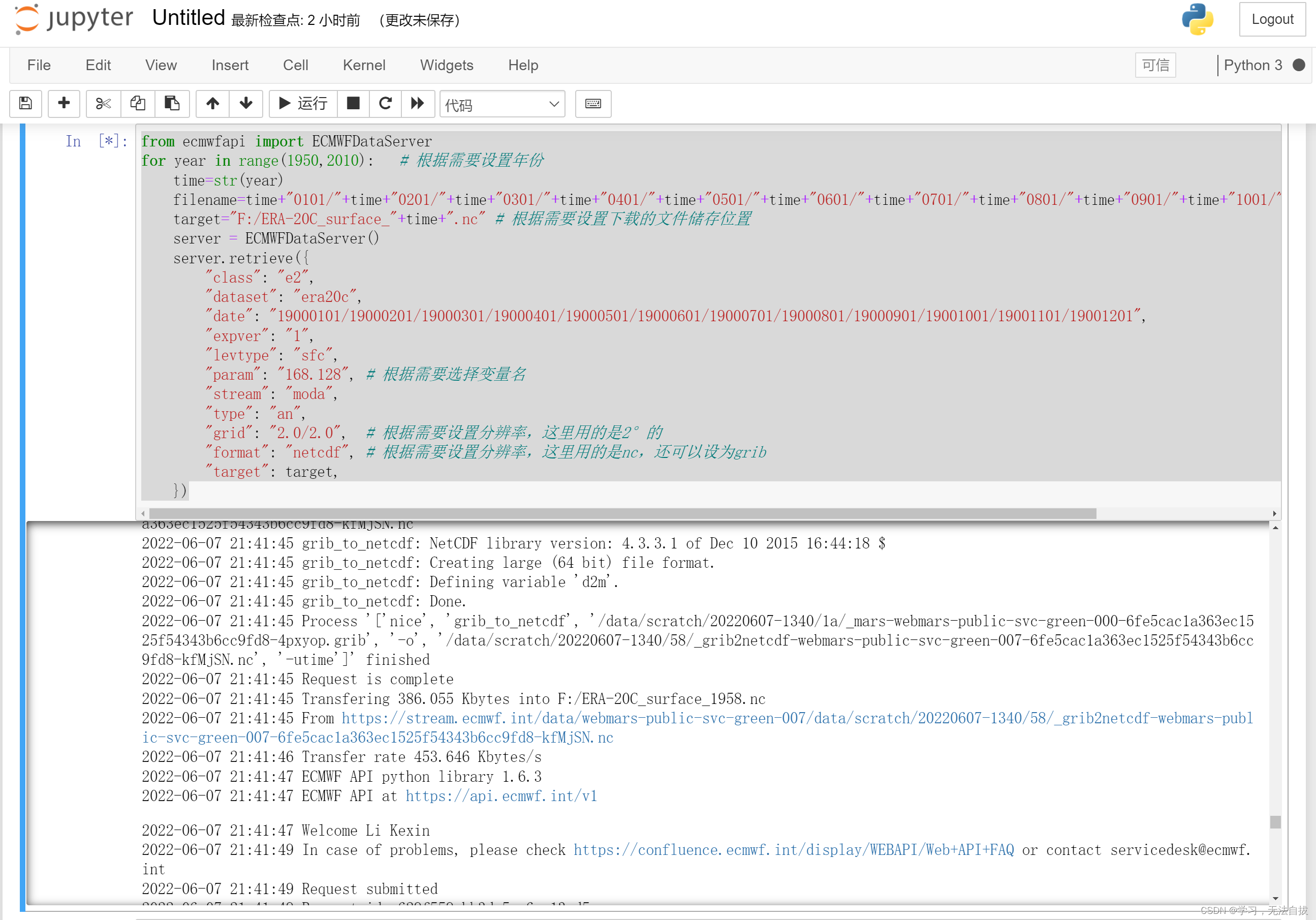
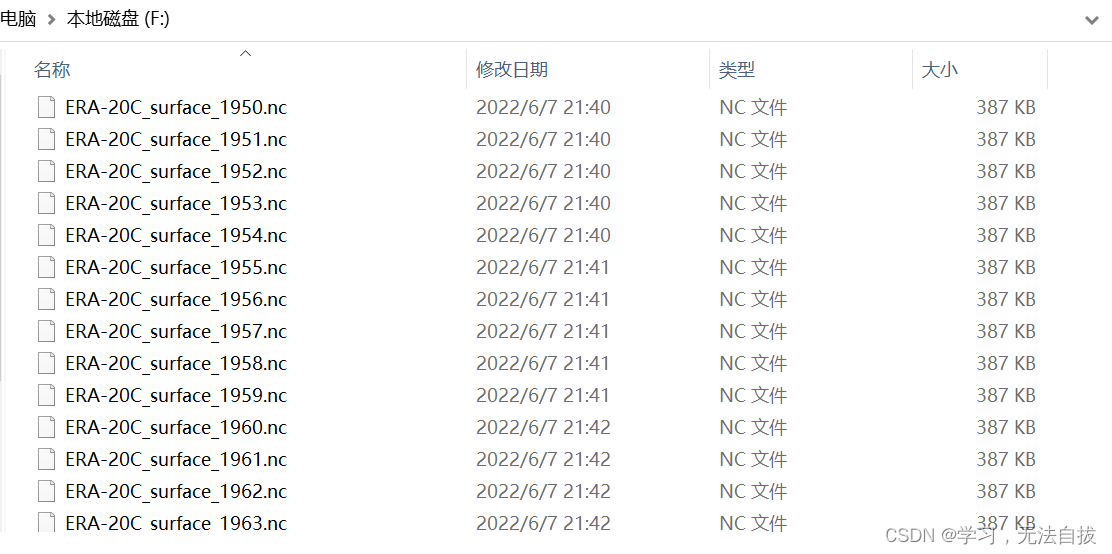
成功!















 763
763











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









