






正则表达式
可以当做为通配符的增强版,帮我们去匹配指定规则的字符串
限定符:操作的对象都是一个字符
?:代表前面这个字符需要出现0次或者1次,就是前面这个字符可有可无
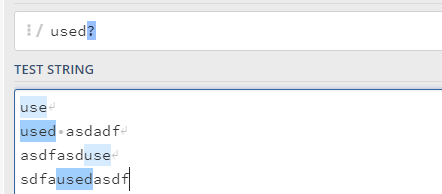
可以看到既可以匹配单词use也可以匹配单词used
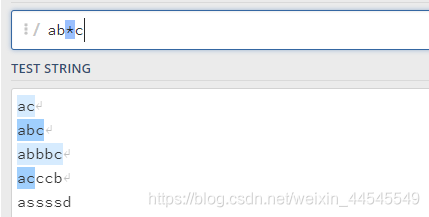
*:匹配0个或者多个字符,代表前面的字符可以没有,也可以有很多或者一个
+:匹配出现一次以上的字符
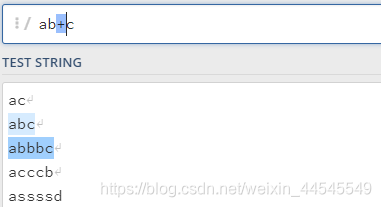
可以看到之前*匹配的两个ac都消失了,因为b需要出现一次以上
{}:需要指定匹配次数
指定b出现的次数为5次
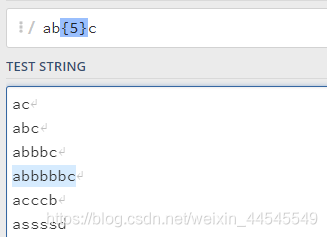
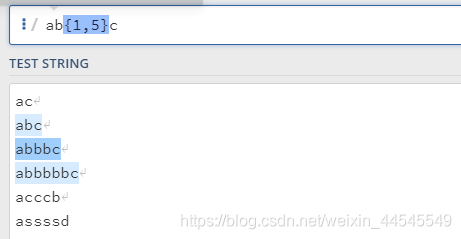
指定b出现的次数为1,5之间
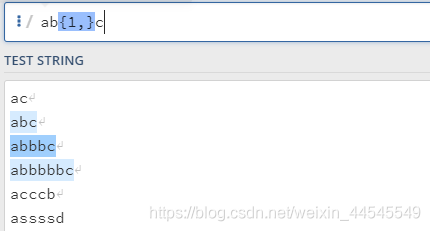
指定b出现的次数为1次以上
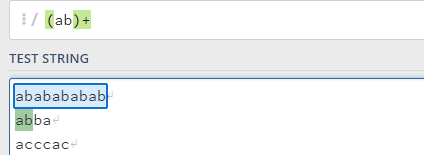
():对多个字符进行限定操作,有点像分组,一组一组的
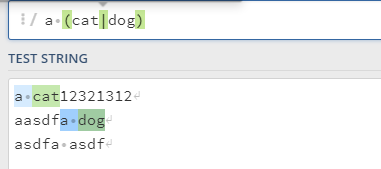
“或”运算
|:就是左右两边的二选一,分别去匹配
这里的括号是必不可少的,否则会变成a cat 或者 dog 而不是 a cat 或者 a dog
字符类
[]:要求匹配的字符只能取自方括号中的内容,也可以指定字符的范围,方括号里面没有先后顺序
想要匹配由字母a b c构成的单词
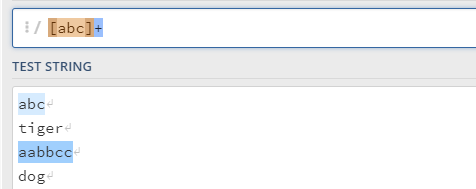
a-z代表由小写字母组成
A-Z代表由大写字母组成
0-9代表由数组组成
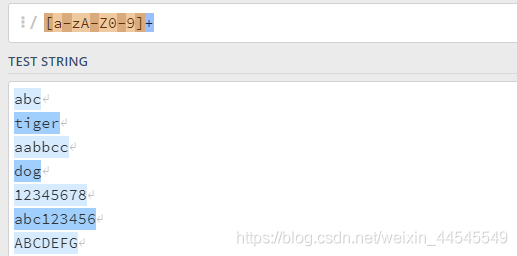
^:要求匹配除尖号后面列出的以外的字符
代表所有非数字字符

元字符
\d:代表数字字符
\D:代表非数字字符
\w:代表单词字符
\W:代表非单词字符
\s:代表空白符
\S:代表非空白符
.:代表任意字符,不包含换行符
^:匹配行首
$:匹配行尾
贪婪与懒惰匹配
之前的 * + {} 在匹配字符串的时候。默认会去匹配尽可能多的字符
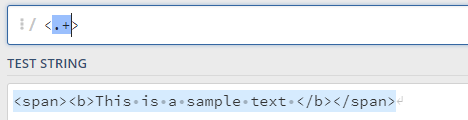
如果只想匹配html标签中的span和b,那个这么写的话,因为.+会尽可能的匹配多的字符,所以全部都匹配上了
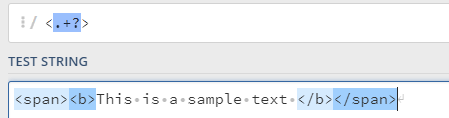
加个?就解决了,会将正则表达式中默认的贪婪匹配切换为懒惰匹配

















 1552
1552

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









