






关系型数据库设计规则
- 多对多:要表示多对多关系,必须创建第三个表,该表通常称为 联接表 ,它将多对多关系划分为两个一对多关系。将这两个表的主键都插入到第三个表中。
MySQL的root用户密码忘记

SQL规则和规范
- 推荐采用统一的书写规范: 数据库名、表名、表别名、字段名、字段别名等都小写 SQL 关键字、函数名、绑定变量等都大写
- 着重号:我们需要保证表中的字段、表名等没有和保留字、数据库系统或常用方法冲突。如果真的相同,请在 SQL语句中使用一对``(着重号)引起来。
- 单双引号:别名使用双引号,字符串型和日期时间类型的数据使用单引号
非符号类型运算符

- like:模糊匹配运算符 。占位符 % :代表不确定个数(0,1,多个)的字符; 占位符 _ :代表一个不确定的字符;转义字符: \ 。
排序
- 多列排序:排序默认为升序,在多列排序时,只有第一列有相同的值,才会对第二列进行排序。
分页
-
格式: LIMIT [位置偏移量,] 行数
-
分页显式公式: (当前页数-1)*每页条数,每页条数

多表查询
- 书写:在表中有相同列时,必须在列名之前加上表名前缀。但是建议是否重名都加上表名前缀。因此,可以使用别名简化查询;需要注意的是,在查询字段中、过滤条件中就只能使用别名进行代替,不能使用原来的表名,否则会报错。
- 总结:连接 n个表,至少需要n-1个连接条件。
- 非等值连接:

- 自连接:相当于是自己本身连接自己。如下,一张表作为woker,一张作为manager。

- 书写:在表中有相同列时,必须在列名之前加上表名前缀。但是建议是否重名都加上表名前缀。因此,可以使用别名简化查询;需要注意的是,在查询字段中、过滤条件中就只能使用别名进行代替,不能使用原来的表名,否则会报错。
- 总结:连接 n个表,至少需要n-1个连接条件。
- 非等值连接:
- 自连接:相当于是自己本身连接自己。如下,一张表作为woker,一张作为manager。
-
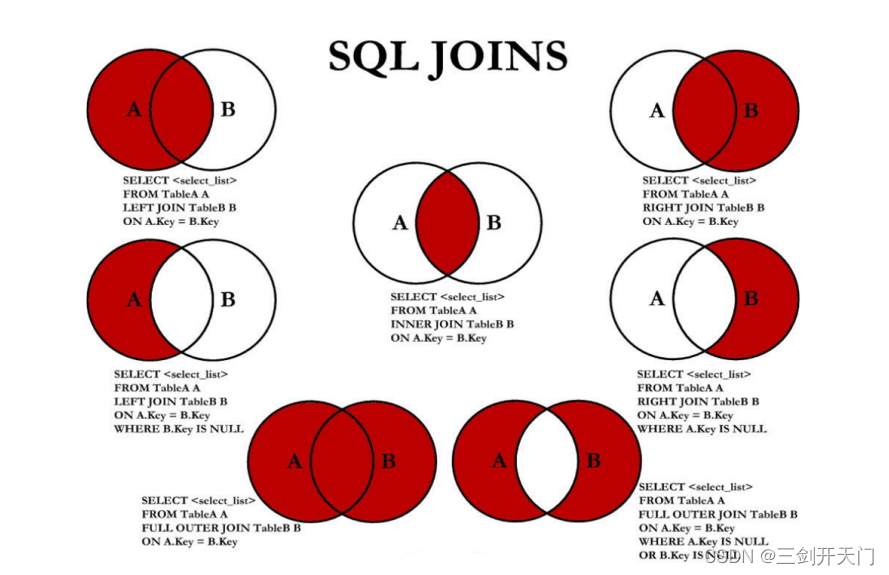
内连接: 合并具有同一列的两个以上的表的行, 结果集中不包含一个表与另一个表不匹配的行
-
外连接: 两个表在连接过程中除了返回满足连接条件的行以外还返回左(或右)表中不满足条件的 行 ,这种连接称为左(或右) 外连接。没有匹配的行时, 结果表中相应的列为空(NULL)。如果是左外连接,则连接条件中左边的表也称为 主表 ,右边的表称为 从表 。如果是右外连接,则连接条件中右边的表也称为 主表 ,左边的表称为 从表 。
-
外连接语法:

- UNION:利用UNION关键字,可以给出多条SELECT语句,并将它们的结果组合成单个结果集。UNION ALL不去重,优先使用这个。

函数
聚合函数
- SUM() :求和函数,需要注意的是会自动过滤值为null的数据。
-
COUNT(): count(*),count(1),count(列名)这三个都是统计数量,前两个统计行数;最后那个统计某一列的数目,会自动过滤null值。
-
AVG(): 求平均值,AVG=SUM/COUNT。
- GROUP BY():在SELECT列表中所有未包含在组函数中的列都应该包含在 GROUP BY子句中,包含在 GROUP BY 子句中的列不必包含在SELECT 列表中。
GROUP BY 放在WHERE后面,ORDER BY 前面。
GROUP BY中使用WITH ROLLUP:记录计算查询出的所有记录的总和,即统计记录数量,但是和 ORDER BY 互斥使用 - HAVING():和 WHERE 一样,用于过滤数据。如果过滤条件中使用了聚合函数,则必须使用HAVING 来替代 WHERE,否则,报错。当过滤条件中没有聚合函数时,过滤条件声明在两者都可,但是建议声明在 WHERE(执行效率更高) 中。
HAVING 必须声明在 GROUP BY 后面。使用 HAVING 的前提是SQL中使用了 GROUP BY。















 2343
2343











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









