







集成框架 -- Redis
Redis介绍
Redis(Remote Dictionary Server ),即远程字典服务,是一个开源的使用ANSI C语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API。从2010年3月15日起,Redis的开发工作由VMware主持。从2013年5月开始,Redis的开发由Pivotal赞助。
Redis支持数据的持久化,持久化的意思是可以将内存中的数据保存在磁盘中,重启可以再次使用。Redis不仅仅支持key- value类型的数据, 同时还提供了list,set,zset,hash等数据存储结构Redis支持数据备份。Master-slave父子模式的数据备份Redis是cs架构服务器
Redis 的数据类型
Redis 支持五种数据类型:
string(字符串)hash(哈希)list(列表)set(集合)zsetsorted set:(有序集合)。
实际项目中比较常用的是 string,hash
Redis的优势
- 性能比较高。
Redis能读的数据是11万次每秒、写的速度是8万次每秒 - 数据类型支持,
string,lists,hashes,sets以及ordered sets多种数据类型操作 - 原子性,
redis所有操作都是原子性,与事务的原子性相同,要么成功,要么失败
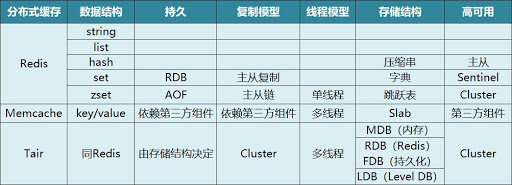
Redis 相比 Memcached区别
Redis 的持久化机制
Redis提供两种持久化机制 RDB 和 AOF 机制:
-
是指用数据集快照的方式半持久化模式)记录
Redis数据库的所有键值对,在某个时间点将数据写入一个临时文件,持久化结束后,用这个临时文件替换上次持久化的文件,达到数据恢复。 -
AOF机制的rewrite模式。AOF文件没被rewrite之前(文件过大时会对命令进行合并重写),可以删除其中的某些命令(比如误操作的 flushall))
一般使用RDB 快照,原因降低性能,15分进行一次快照,但是容灾可能会出现15分数据无法恢复。但是这也是官方建议和默认配置的持久方式 ,如果只是做为存储中间件来用15分钟完全可以,如果用于热点数据,如果服务器性能较高,一般会使用5分钟 在Redis配置里面处理
Redis 的回收策略
- 挑选最近最少使用的key数据淘汰
- 挑选将要过期的key数据淘汰
- 任意选择key数据淘汰
- 禁止驱逐数据
缓存淘汰算法
LRU(least recently used,最近最少使用)
算法根据数据的历史访问记录来进行淘汰数据,其核心思想是“如果数据最近被访问过,那么将来被访问的几率也更高”。
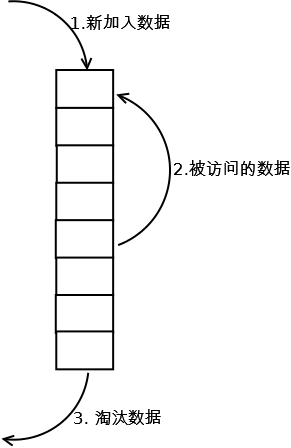
新数据插入到链表头部, 每当缓存命中(即缓存数据被访问),则将数据移到链表头部,当链表满的时候,将链表尾部的数据丢弃。
LRU-K

数据第一次被访问,加入到访问历史列表; 如果数据在访问历史列表里后没有达到K次访问,则按照一定规则(FIFO,LRU)淘汰,当访问历史队列中的数据访问次数达到K次后,将数据索引从历史队列删除,将数据移到缓存队列中,并缓存此数据,缓存队列重新按照时间排序,缓存数据队列中被再次访问后,重新排序;需要淘汰数据时,淘汰缓存队列中排在末尾的数据,即:淘汰“倒数第K次访问离现在最久”的数据。
代码示例 :
public void put(Object key, Object value) {
CacheNode node = nodes.get(key); //缓存节点获取是否有这个值
if (node == null) {
//缓存容器是否已经超过大小.
if (currentSize >= cacheSize) {
if (last != null) //将最少使用的删除 实现逻辑
nodes.remove(last.key);
removeLast();
} else {
currentSize++;
}
node = new CacheNode();
}
node.value = value;
node.key = key;
//将最新使用的节点放到链表头,表示最新使用的.
moveToHead(node);
nodes.put(key, node);
}
Redis 哨兵
哨兵一般是在多节点redis时使用,主要能力是监控集群的主节点是否心跳正常,当心跳失败,记录下来,当其他哨兵都发现没有心跳超过一般,认为redis 主观下线,这时候需要手工选择新的redis主机,如果想避开这一步,需要写一个脚本进行处理。
如果是多个redis实例那么已最先收到的哨兵节点会记录客观下线,如果大于一半以上会要求redis实例进行投票新的主机当选择出新的主机,会通过订阅发布通知其他从节点,修改配置同步数据切换主节点,如果主节点恢复,那么会降价为从节点。

Redis 实践
安装
- 准备
vm虚拟机。本地运行测试。 - 安装系统
centor 7 - 下载
redis启动
下载
-
下载地址 :http://redis.io/download
选择最新稳定的下载。由于不能上图自己找下载量最多的即可 -
运行虚拟机登录,运行管理员sudo命令,如果你是子用户,为了打字方便,我默认为root用户
-
Wget http://download.redis.io/releases/redis-2.8.17这个是你下载的版本.tar.gz
可以用命令直接下载,也可以下载到本地,放在文件夹进行解压 ,如果用docker 可以直接pull redis 指定版本
tar xzf redis-2.8.17.tar.gz
cd redis-2.8.17
make
Make编译完成之后,redis-2.8.17目录下回出现编译后的redis服务程序,redis-server,还有用于测试客户端程序的redis-cli,两个程序都在安装目录下的src目录当中,编译后就能看到
cd src
./ redis-server
这样便启动了redis你可以看到一个大盒子。表示启动成功,这种启动方式,属于默认的启动方式,端口号和配置文件都是默认配置的,就个人而言一般在开发工作当中,我们会配置,redis-conf这个配置文件。所以启动也会通过配置参数进行启动用于指定配置文件启动,方式如下
cd src./redis-server ../redis.conf # 指定的配置文件
config get * ./redis-server ../redis.conf
里面参数也是后面java你想配置的参数,也可以设置auth redis的密码。端口号默认的6379地址正常是本地127.0.0.1地址。如果注释掉本地就是所有连接都可以连接
Redis既然已经启动了,你可以重启一个再启动一个链接,方便操作
./redis-cli
客户端启动,进行操作,你可以进行set put append 这些数据类型的方法,测试一下get set 操作,Redis 有9个库默认是select 0这个库。这个可以了解一下,这样正常的一个liunx环境下的redis就已经装配完成接下来就是我们在开发用java写东西不可能用redis客户端来操作,需要进行连接交互;
jedis 链接
使用的是jedis连接,本文已经声明用jedis进行连接,redis 官网上面有很多种连接方式,大家可以参考,基本连接方式大同小异熟悉一种连接其他的看一下基本就可以了解了;
- 需要准备使用
jedis jar包,导入依赖在pom上面加依赖,具体可参考其他博客我这边无法传图 - 如果你采用
jedis使用连接池需要使用,common-pool jar包 - 其他基础配置开发环境,开发软件,
jdk,maven就不说了 - 影响连接的可能出现的两个因素,
redis配置问题,防火墙问题,关闭防火墙
Redis.conf 里面配置项, bind 127.o.o.1 默认配置,说明只能允许连接本机
Redis.conf 里面配置项,requirepass xxx 设置密码,说明客户端需要带上auth参数,也就是redis密码
配置方式
- 第一种,
spring boot里面在application.yml里面配置参数 - 第二种,
spring application里面在bean配置里面配置参数
redis 常用配置参数解析
Redis数据库索引(默认为0)
spring.redis.database=0
Redis服务器地址
spring.redis.host=192.168.12.43
Redis服务器连接端口
spring.redis.port=6379
Redis服务器连接密码(默认为空)
spring.redis.password=redis
连接池最大连接数(使用负值表示没有限制)
spring.redis.pool.max-active=8
连接池最大阻塞等待时间(使用负值表示没有限制)
spring.redis.pool.max-wait=-1
连接池中的最大空闲连接
spring.redis.pool.max-idle=8
连接池中的最小空闲连接
spring.redis.pool.min-idle=0
连接超时时间(毫秒)
spring.redis.timeout=0
工程连接依赖
<!--集成redis-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-redis</artifactId>
<version>1.4.1.RELEASE</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.3</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
</dependency>
第一种 spring boot 链接
@Configuration
public class RedisConfiguration {
Logger logger = LoggerFactory.getLogger(RedisCacheConfiguration.class);
@Value("${spring.redis.host}")
private String host;
@Value("${spring.redis.port}")
private int port;
@Value("${spring.redis.timeout}")
private int timeout;
@Value("${spring.redis.pool.max-idle}")
private int maxIdle;
@Value("${spring.redis.pool.max-wait}")
private long maxWaitMillis;
@Value("${spring.redis.password}")
private String password;
@Bean
public JedisPool redisPoolFactory()
JedisPoolConfig jedisPoolConfig = new JedisPoolConfig();
jedisPoolConfig.setMaxIdle(maxIdle);
jedisPoolConfig.setMaxWaitMillis(maxWaitMillis);
//你可以把上面需要配置的数学,由于vlue已经指定了application配置的值,所以你可以进行自定义配置
JedisPool jedisPool = new JedisPool(jedisPoolConfig, host, port, timeout, password);
//返回一个jedispool 获取jedis jedis = jedisPool.getResource()即可获得jedis
return jedisPool;
}
}
得到连接池之后,可以通过
jedis = jedisPool.getResource()
获得jedis,考虑到多线程问题,可以在获取方法上加锁,可能会涉及异常问题,进行try catch
最后可以写一个方法,jedis的关闭方法。或者获取jedis之后使用,在try进行,最后进行关闭也可以
第二种,spring 配置
可以定义一个redis.properties 配置文件 基本跟springboot写法差不多
还有一种就是bean配置
<bean id = "jedispoolconfig" class = "redis.clients.jedispoolconfig">
<p:"maxactive" = "600"/>
<p:"maxidil" = "400"/>
<p:"maxwait" = "200"/>
// 这就配置了一个config 可以继续配置property
// 配置连接池
<bean id = "jedispool" class ="redis.clients.jedsi.jedispool" scope="singleton">
<constructor-arg index ="0” ref= “”jedispoolconfig“”>
<constructor-arg index="1">
<list>
<bean class = "redis.clients.jedis.jedisshardinfo">
<constructor-arg name = "host" value = "127.0.01"/>
<constructor-arg name = port value = "6379"/>
<bean/>
</list>
redis SpringBoot自动注入Redis配置原理
配置文件application.yml中redis的配置信息
redis:
host: 127.0.0.1
port: 6379
#连接超时时间(毫秒)
timeout: 2000
pool:
#最大连接数(负数表示没有限制)
max-active: 100
#最大空闲连接
max-idle: 10
#最大阻塞等待时间(负数表示没有限制)
max-wait: 100000
database: 0

配置会找到 配置文件进行注入

会自动注入到jedis 和lettuce 里面,主要看是否配置lettuce线程池

配置文件会进行配置构建出配置文件

自动引入RedisProperties,
@Import({ LettuceConnectionConfiguration.class, JedisConnectionConfiguration.class })
引入配置文件

放到redis模板配置中。

redis 序列化处理
如上图 可以重写redisTemplate 因为加了 conditionOnMissingBean
// 配置@Configuration 重写redis 模板
@Bean
public RedisTemplate<Object, Object> redisTemplate(RedisConnectionFactory factory, RedisSerializer fastJson2JsonRedisSerializer) {
// 照抄加入配置
RedisTemplate<Object, Object> redisTemplate = new RedisTemplate<>();
redisTemplate.setConnectionFactory(factory);
//key采用String序列化方式
StringRedisSerializer stringRedisSerializer = new StringRedisSerializer();
redisTemplate.setKeySerializer(stringRedisSerializer);
redisTemplate.setHashKeySerializer(stringRedisSerializer);
//value采用fast-json序列化方式。
redisTemplate.setValueSerializer(fastJson2JsonRedisSerializer);
redisTemplate.setHashValueSerializer(fastJson2JsonRedisSerializer);
redisTemplate.afterPropertiesSet();
return redisTemplate;
}
缓存的意义架构

redis 与 mysql 一致性处理方案
读取缓存步骤一般没有什么问题,但是一旦涉及到数据更新:数据库和缓存更新,就容易出现缓存和数据库间的数据一致性问题。不管是先写数据库,再删除缓存;还是先删除缓存,再写库,都有可能出现数据不一致的情况。举个例子:
1.如果删除了缓存Redis,还没有来得及写库MySQL,另一个线程就来读取,发现缓存为空,则去数据库中读取数据写入缓存,此时缓存中为脏数据。
2.如果先写了库,在删除缓存前,写库的线程宕机了,没有删除掉缓存,则也会出现数据不一致情况。
因为写和读是并发的,没法保证顺序,就会出现缓存和数据库的数据不一致的问题。如何解决?这里给出两个解决方案,先易后难,结合业务和技术代价选择使用。
一、 延时双删策略
在写库前后都进行redis.del(key)操作,并且设定合理的超时时间。具体步骤是:
-
1)先删除缓存
-
2)再写数据库
-
3)休眠500毫秒(根据具体的业务时间来定)
-
4)再次删除缓存。
那么,这个500毫秒怎么确定的,具体该休眠多久呢?
需要评估自己的项目的读数据业务逻辑的耗时。这么做的目的,就是确保读请求结束,写请求可以删除读请求造成的缓存脏数据。
当然,这种策略还要考虑 redis 和数据库主从同步的耗时。最后的写数据的休眠时间:则在读数据业务逻辑的耗时的基础上,加上几百ms即可。比如:休眠1秒。
二、设置缓存的过期时间
从理论上来说,给缓存设置过期时间,是保证最终一致性的解决方案。所有的写操作以数据库为准,只要到达缓存过期时间,则后面的读请求自然会从数据库中读取新值然后回填缓存
结合双删策略+缓存超时设置,这样最差的情况就是在超时时间内数据存在不一致,而且又增加了写请求的耗时。
三、如何写完数据库后,再次删除缓存成功?
上述的方案有一个缺点,那就是操作完数据库后,由于种种原因删除缓存失败,这时,可能就会出现数据不一致的情况。这里,我们需要提供一个保障重试的方案。
1、方案一具体流程
(1)更新数据库数据;
(2)缓存因为种种问题删除失败;
(3)将需要删除的key发送至消息队列;
(4)自己消费消息,获得需要删除的key;
(5)继续重试删除操作,直到成功。
然而,该方案有一个缺点,对业务线代码造成大量的侵入。于是有了方案二,在方案二中,启动一个订阅程序去订阅数据库的binlog,获得需要操作的数据。在应用程序中,另起一段程序,获得这个订阅程序传来的信息,进行删除缓存操作。
2、方案二具体流程
(1)更新数据库数据;
(2)数据库会将操作信息写入binlog日志当中;
(3)订阅程序提取出所需要的数据以及key;
(4)另起一段非业务代码,获得该信息;
(5)尝试删除缓存操作,发现删除失败;
(6)将这些信息发送至消息队列;
(7)重新从消息队列中获得该数据,重试操作。
以上方案都是在业务中经常会碰到的场景,可以依据业务场景的复杂和对数据一致性的要求来选择具体的方案
redis 分布式锁实现
在系统中修改已有数据时,需要先读取,然后进行修改保存,此时很容易遇到并发问题。由于修改和保存不是原子操作,在并发场景下,部分对数据的操作可能会丢失。在单服务器系统我们常用本地锁来避免并发带来的问题,然而,当服务采用集群方式部署时,本地锁无法在多个服务器之间生效,这时候保证数据的一致性就需要分布式锁来实现。


Redis 锁主要利用 Redis 的 setnx 命令。
加锁命令:SETNX key value,当键不存在时,对键进行设置操作并返回成功,否则返回失败。KEY 是锁的唯一标识,一般按业务来决定命名。
解锁命令:DEL key,通过删除键值对释放锁,以便其他线程可以通过 SETNX 命令来获取锁。
锁超时:EXPIRE key timeout, 设置 key 的超时时间,以保证即使锁没有被显式释放,锁也可以在一定时间后自动释放,避免资源被永远锁住。 一般过期时间3-5秒 基本处理完成服务,如果还没处理就过期,保证其他线程进入。
if (setnx(key, 1) == 1){
expire(key, 30)
try {
//TODO 业务逻辑
} finally {
del(key)
}
}
如果不设置过期时间

在保证其他线程进入的同时,如果确实是服务没有处理成功,而另一个线程又进入处理,那么会造成并发问题,这种问题,可以通过ThreadLocal.withInitial(HashMap::new); 本地线程副本来同步进来几个。
Redis可通过对锁进行重入计数,加锁时加 1,解锁时减 1,当计数归 0 时释放锁。
这样设计可以保证一定的线程可以进入,增加性能如果是增改操作建议延长过期时间,防止并发写入。
这种其实也可以在代码逻辑进行悲观锁处理,这样就可以进行重入锁处理
private static ThreadLocal<Map<String, Integer>> LOCKERS = ThreadLocal.withInitial(HashMap::new);
// 加锁
public boolean lock(String key) {
Map<String, Integer> lockers = LOCKERS.get();
if (lockers.containsKey(key)) {
lockers.put(key, lockers.get(key) + 1);
return true;
} else {
if (SET key uuid NX EX 30) {
lockers.put(key, 1);
return true;
}
}
return false;
}
// 解锁
public void unlock(String key) {
Map<String, Integer> lockers = LOCKERS.get();
if (lockers.getOrDefault(key, 0) <= 1) {
lockers.remove(key);
DEL key
} else {
lockers.put(key, lockers.get(key) - 1);
}
}
本地记录重入次数虽然高效,但如果考虑到过期时间和本地、Redis 一致性的问题,就会增加代码的复杂性。另一种方式是 Redis Map 数据结构来实现分布式锁,既存锁的标识也对重入次数进行计数。Redission 加锁示例:
// 如果 lock_key 不存在
if (redis.call('exists', KEYS[1]) == 0)
then
// 设置 lock_key 线程标识 1 进行加锁
redis.call('hset', KEYS[1], ARGV[2], 1);
// 设置过期时间
redis.call('pexpire', KEYS[1], ARGV[1]);
return nil;
end;
// 如果 lock_key 存在且线程标识是当前欲加锁的线程标识
if (redis.call('hexists', KEYS[1], ARGV[2]) == 1)
// 自增
then redis.call('hincrby', KEYS[1], ARGV[2], 1);
// 重置过期时间
redis.call('pexpire', KEYS[1], ARGV[1]);
return nil;
end;
// 如果加锁失败,返回锁剩余时间
return redis.call('pttl', KEYS[1]);
雪崩穿透
当用户查询的key在redis中不存在,对应的id在数据库也不存在,此时被非法用户进行攻击,大量的请求会直接打在db上,造成宕机,从而影响整个系统,这种现象称之为缓存穿透。
解决方案:把空的数据也缓存起来,比如空字符串,空对象,空数组或list,代码如下
if (object != null ) {
// 存储数据
} else {
redisOperator.set("建", JsonUtils.objectToJson(object , 5*60));
}
Redis缓存雪崩
缓存雪崩:缓存中的数据大批量失效,然后这个使用又要大量的请求进来,但是由于redis中的key全部失效了所有会全部请求到db上,造成宕机
解决方案,过期时间错开,过期时间使用随机生成,并且热点数据的过期时间设置的长一点,非热点数据可以设置短一点
引言
关于redis其实一般来说单机比较少,根据业务不一定非要大体量的集群配置,如果小项目单机完全可以了,如果考虑到高可用,如果是大公司正常已经配置好了,不需要我们去处理,大厂一般会进行购买或自生产比如我目前公司阿里,使用的redis已经可以在阿里云售卖,他已经有完整的高可用集群模式,购买直接使用就可以了,也比较便宜,如果项目有预算且银行项目等,需要自己搭建集群redis集群哨兵监控后面在docker里面再详说,毕竟一台机器用来配置redis不现实,机器很贵··















 969
969











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









