




最近一直在研究如何解放双手(好歹咱也做过两年程序员)
进行自动化挖掘(虽然目前能力还欠缺)简单的解放一下双手还是可以的
下面将利用Burp和python来实现自动化
一、安装Burp Suite的Python扩展
遵循官网的(Burp Suite Extensibility - PortSwigger)步骤安装
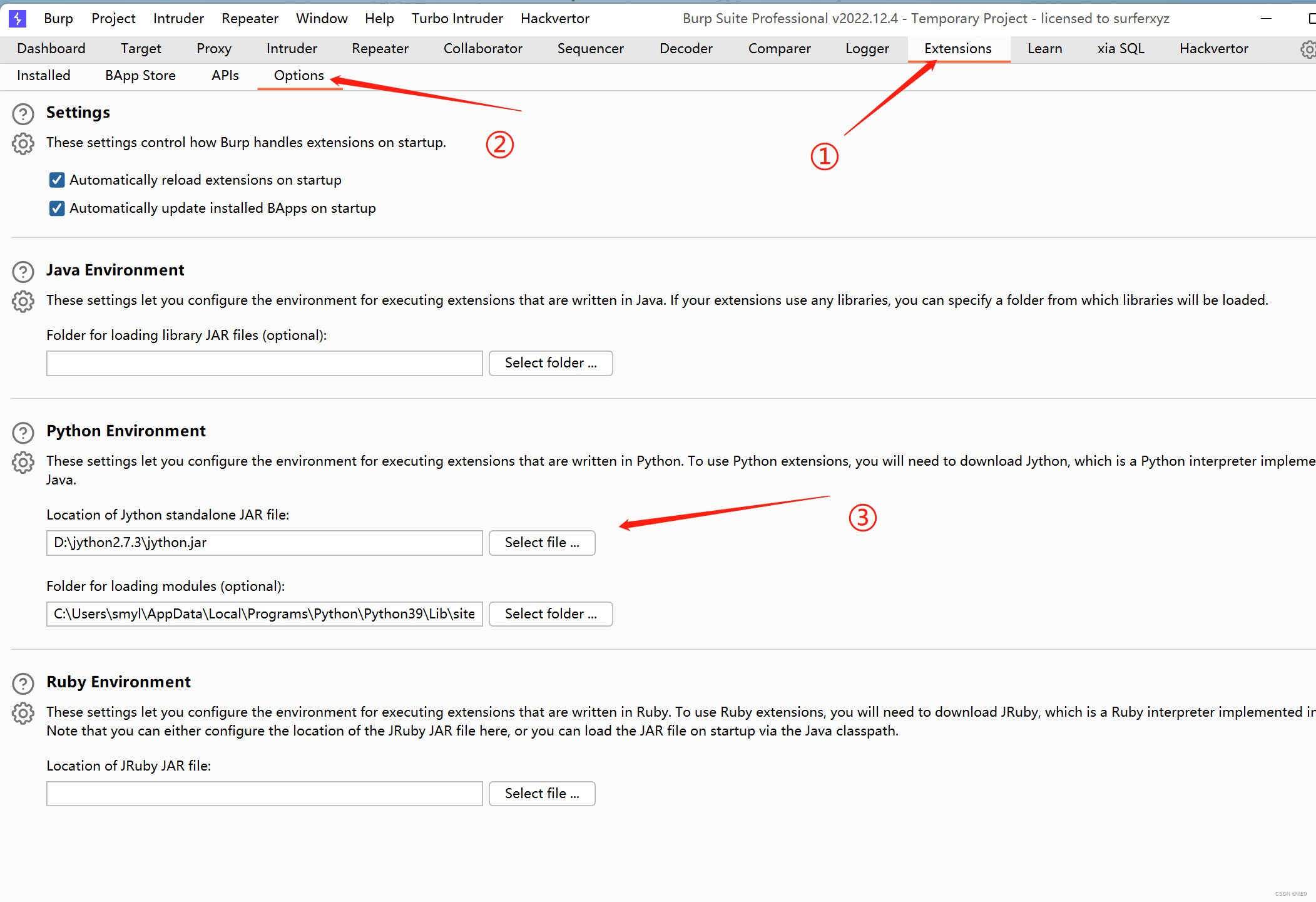
1、先安装Jython运行环境
(https://www.jython.org/)官网下载
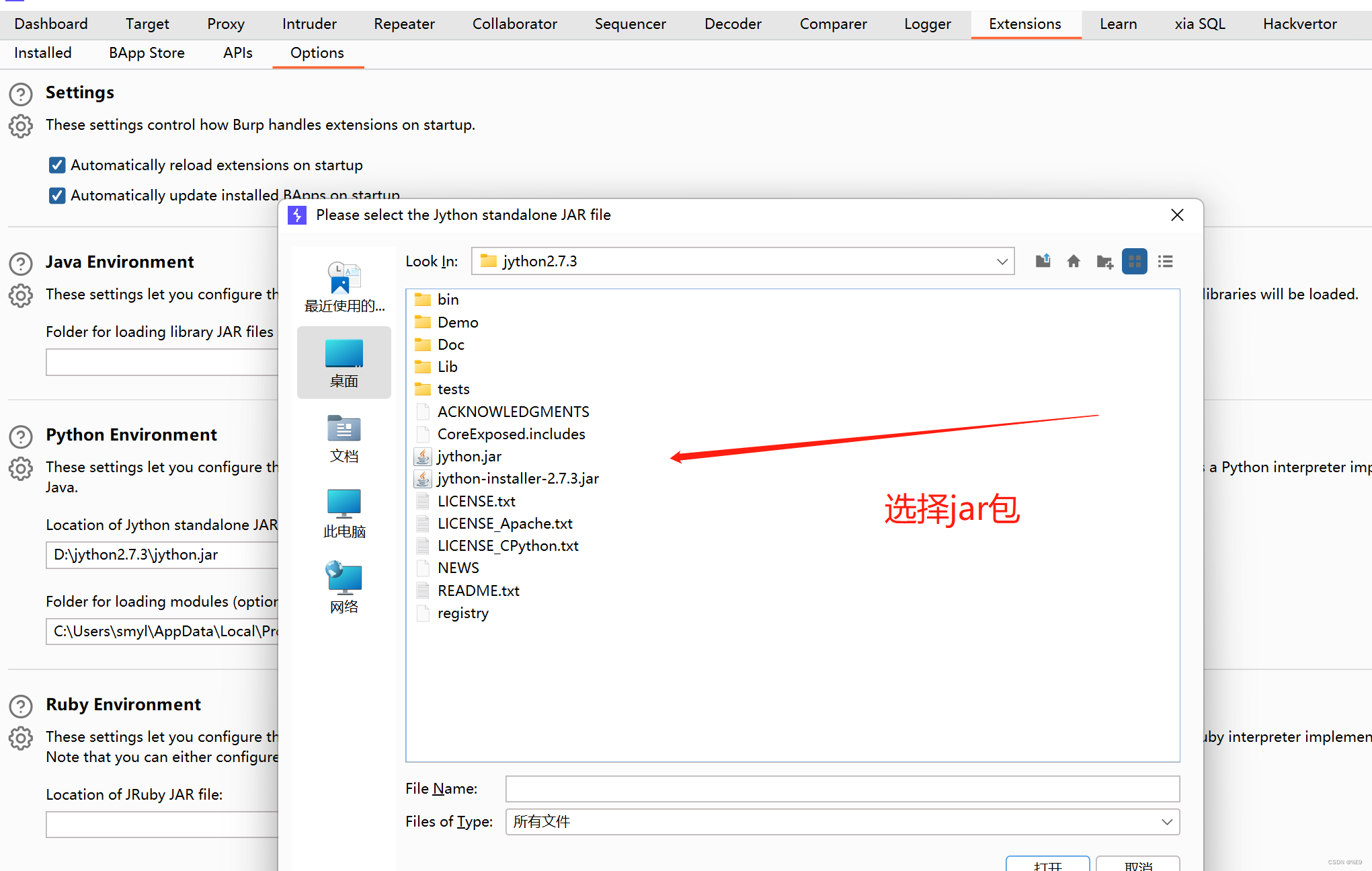
2、下载解压导入Burp
二、选择官网的扩展包
因为用了翻译有些东西明白啥意思就可以了

1、自定义记录器(custom-logger-master)
这个扩展提供了一些经常被请求的东西:在主Burp的主界面会有一个套件记录HTTP日志。
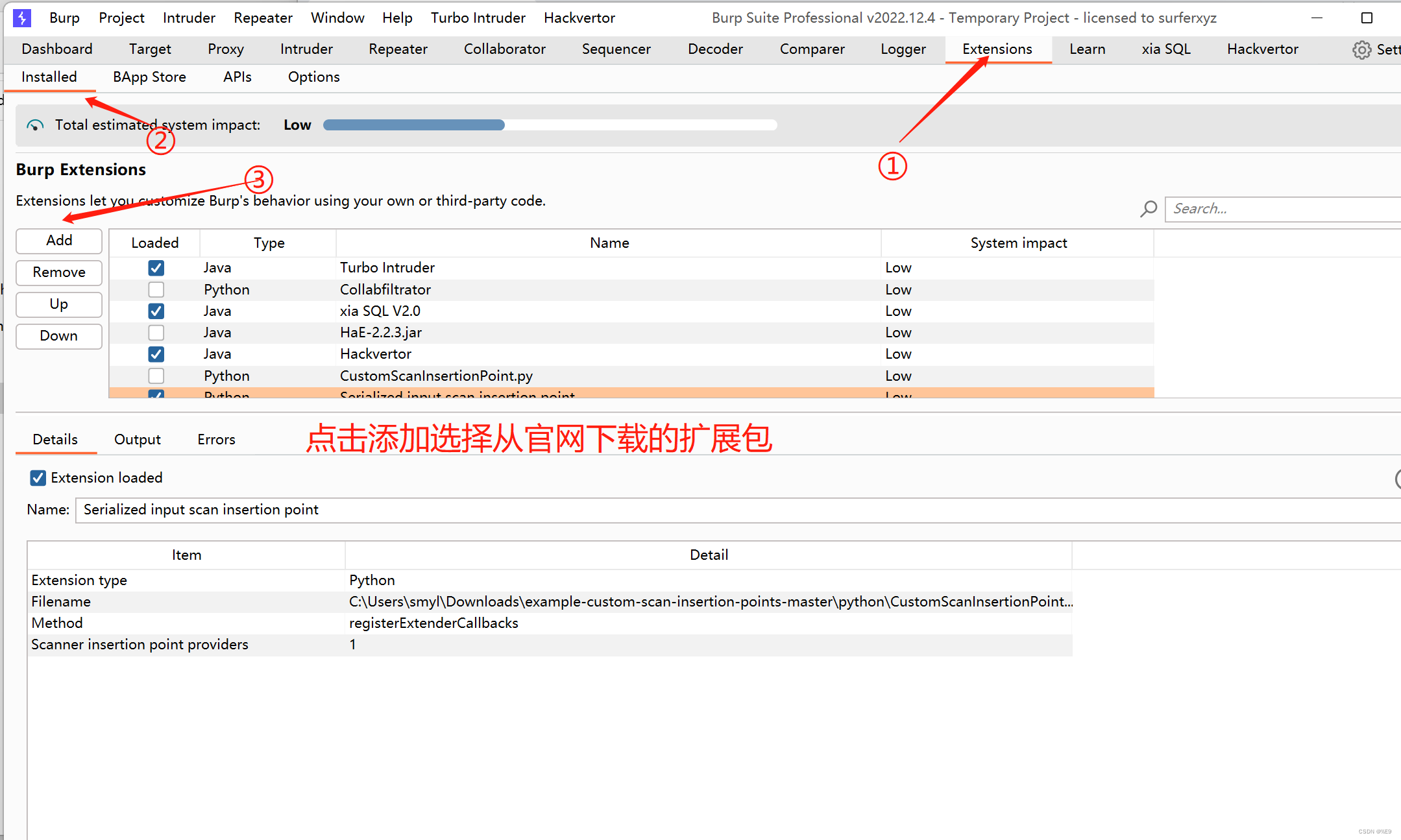
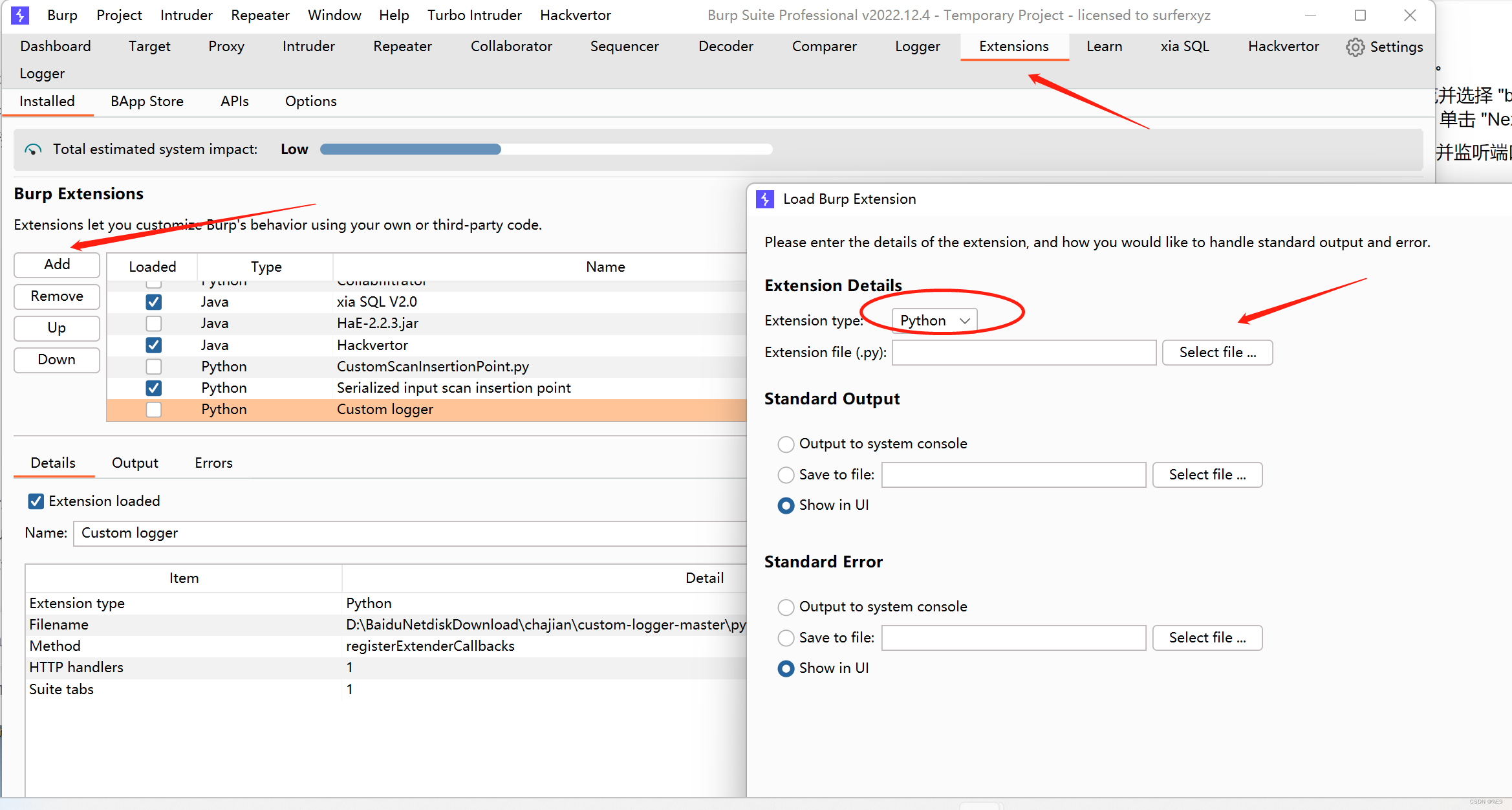
2、添加
选择pthon,不然java还得编译
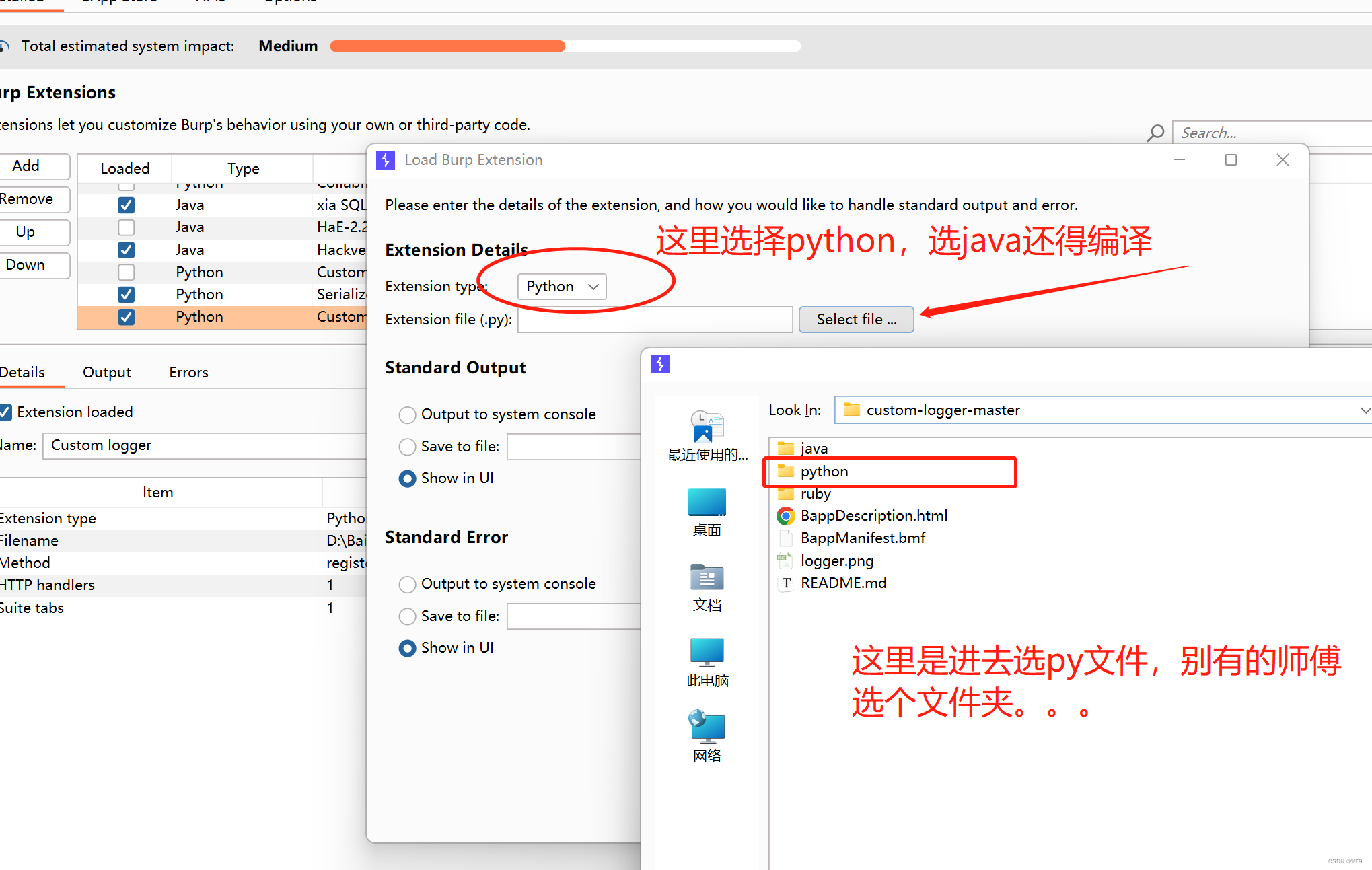
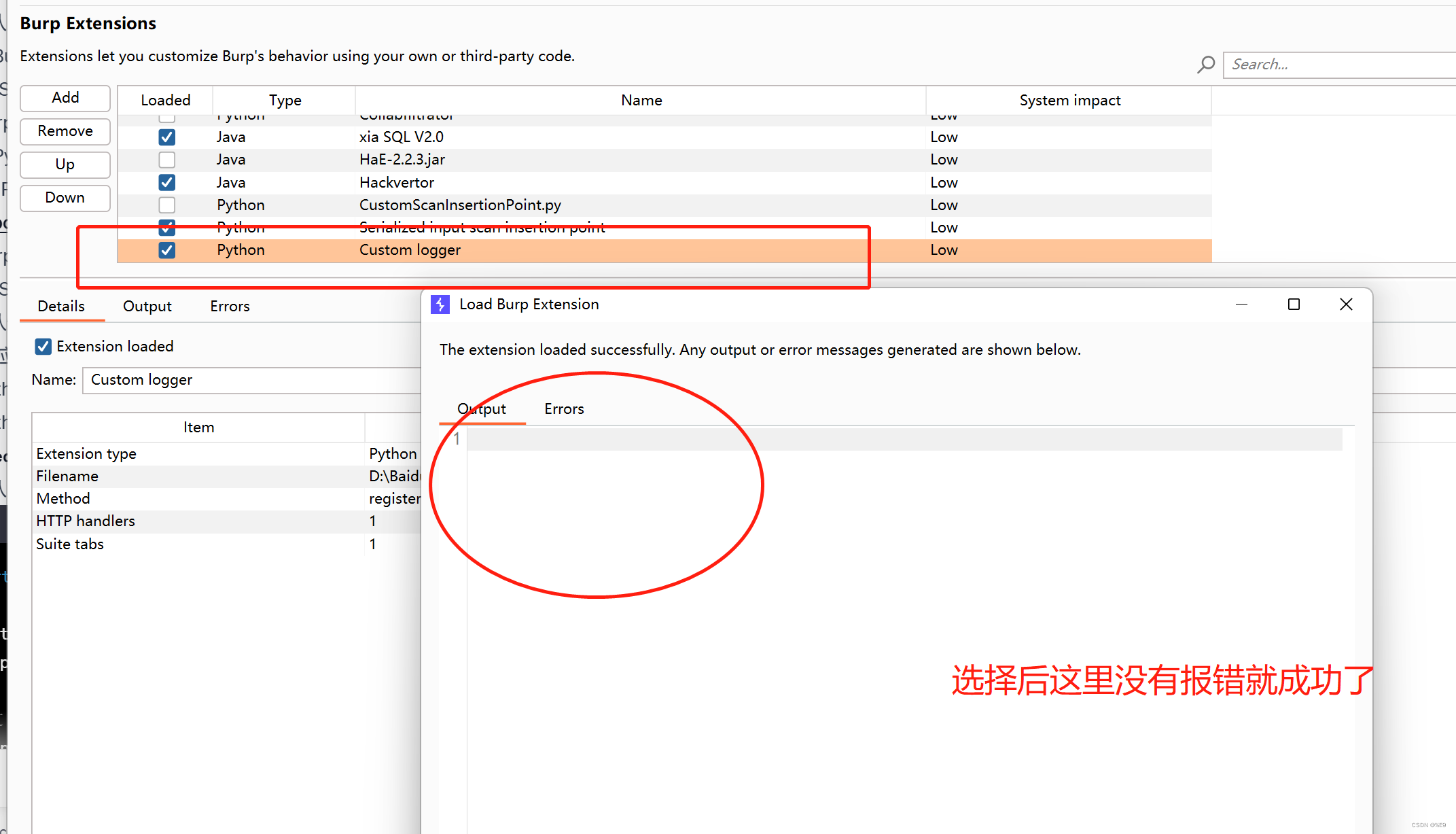
主界面上面会多出一个logger来记录你的抓包日志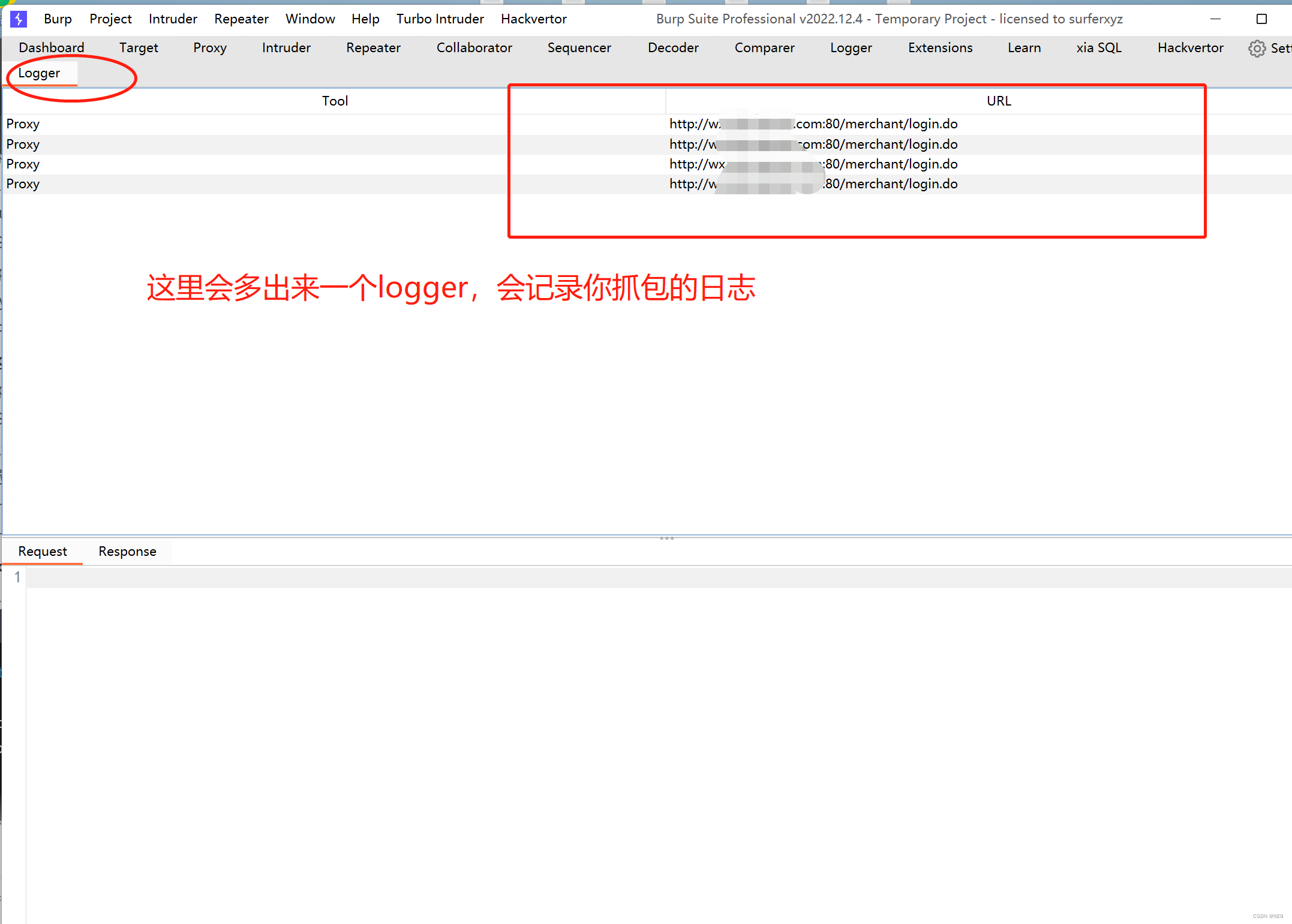
官网上的拓展包,按照上面操作就可以了!
三、编写python脚本
1、一个简单示例帮你入门
我下面这个8080端口是我自己的burp端口(自己改自己的)
这个示例就是获取当前页面的请求结果(注意:这个在本地运行就可以不是导入burp)
import requests
# 这里填写非https的网站
target_url = 'http://xxxxx.com'
burp_proxy = {'http': 'http://127.0.0.1:8080', 'https': 'http://127.0.0.1:8080'}
# 通过 Burp 代理发送 HTTP 请求
response = requests.get(target_url, proxies=burp_proxy)
print(response.content)
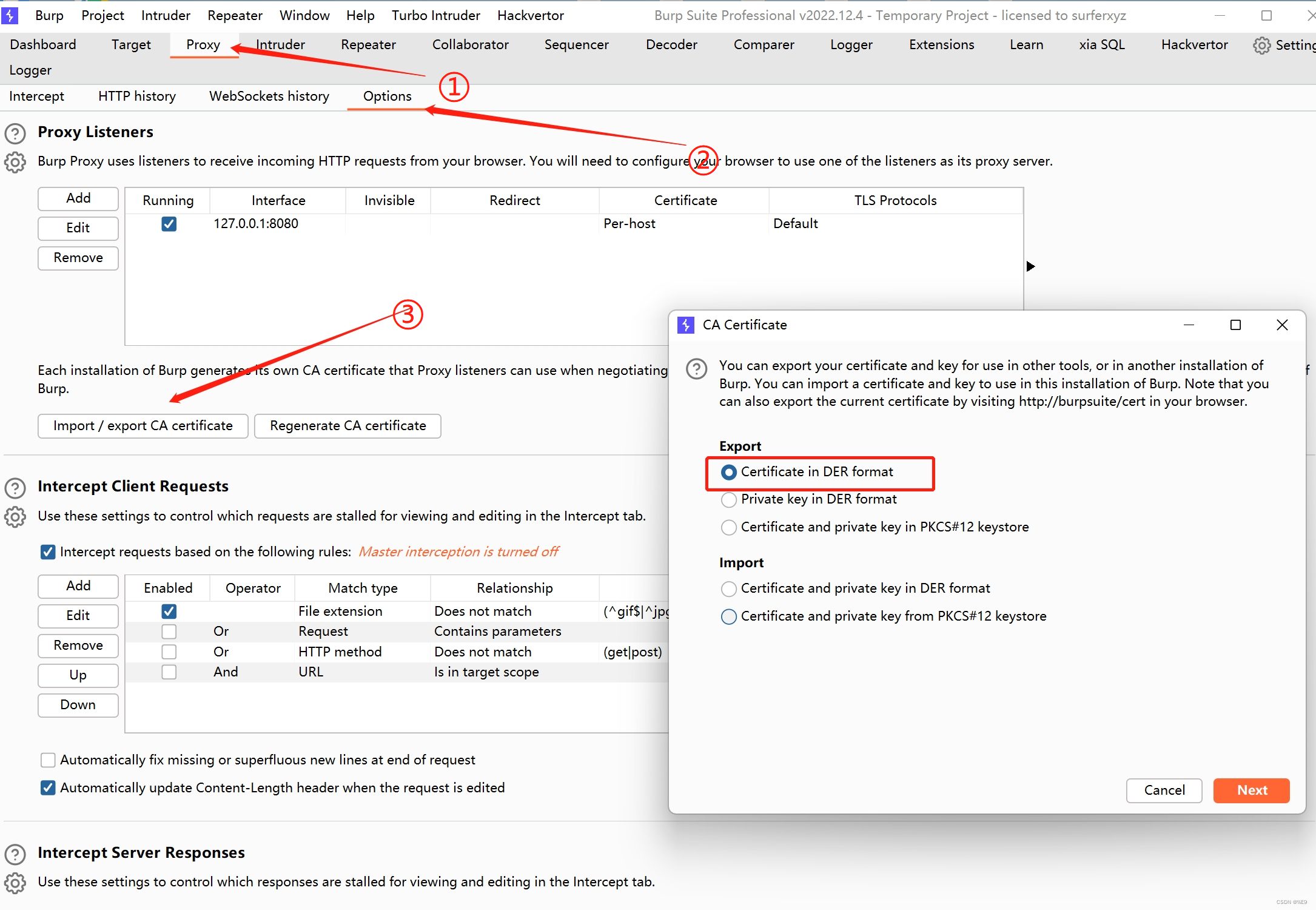
2、python导入burp证书
我们目前大部分测试的是访问 HTTPS 网站,需要将 Burp 证书导入 Python 的 requests 库。首先,从 Burp Suite 中导出证书:转到 "Proxy" > "Options" > "Import / export CA certificate",选择 "Certificate in DER format" 并导出证书文件。
3、安装certifi库 和开启Burp Suite REST API的默认端口
安装python的certifi库
pip install certifi开启Burp Suite REST API的默认端口(注意:专业版才有,可以那啥。。)you know?
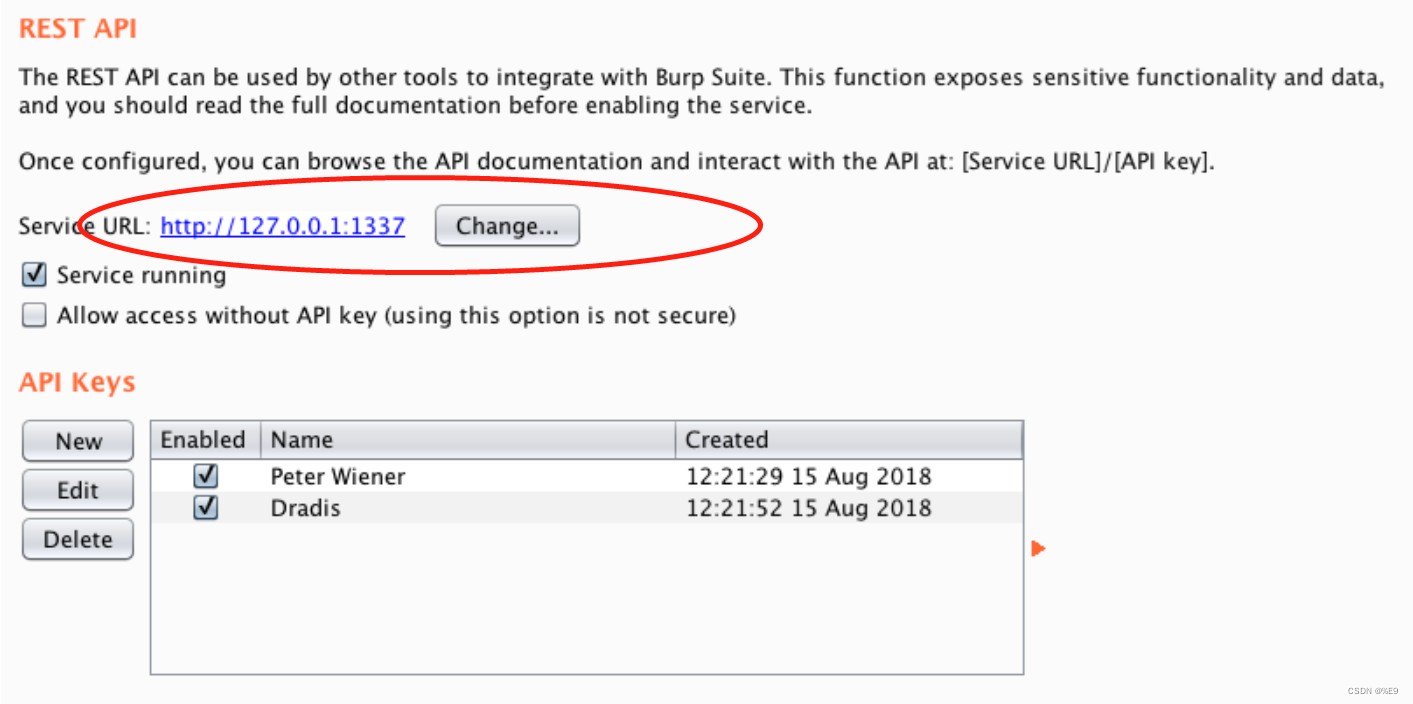
- 在 Burp Suite 中,转到 "Extender" > "Extensions" 选项卡。
- 点击 "Add" 按钮,选择 "Python" 作为扩展类型,然后浏览并选择 "burp-rest-api.py" 文件。此文件位于 Burp Suite 安装目录中的 "Extender" 文件夹中。单击 "Next",然后单击 "Close"。
- 转到 "Extender" > "APIs" 选项卡,确保 REST API 已启用并监听端口 1337。如果它没有启用,请选中 "Enable REST API" 复选框并单击 "Apply"。
4、编写代码以处理https的网站
这仅仅只是开始,有兴趣的师傅可以一起研究
import requests
import json
import time
import certifi
burp_api_url = 'http://127.0.0.1:1337'
target_url = 'https://xxxxx.com'
#证书路径
burp_cert_path = '/path/to/your/burp_certificate.der'
headers = {
'Content-Type': 'application/json',
'Cache-Control': 'no-cache'
}
# 导入 Burp 证书
cafile = certifi.where()
with open(burp_cert_path, 'rb') as infile:
burp_cert = infile.read()
with open(cafile, 'ab') as outfile:
outfile.write(burp_cert)
burp_proxy = {'http': 'http://127.0.0.1:8080', 'https': 'http://127.0.0.1:8080'}
# 创建新的扫描任务
payload = {
'urls': [target_url],
'configuration_id': 1 # 选择一个扫描配置,例如:1 为默认配置
}
response = requests.post(f'{burp_api_url}/v0.1/scan', data=json.dumps(payload), headers=headers, proxies=burp_proxy, verify=cafile)
task_id = response.json()['task_id']
print(f"Task ID: {task_id}")
# 检查任务状态
while True:
time.sleep(5) # 等待 5 秒
response = requests.get(f'{burp_api_url}/v0.1/scan/{task_id}', headers=headers, proxies=burp_proxy, verify=cafile)
task_status = response.json()['status']
print(f"Task status: {task_status}")
if task_status == 'succeeded':
break
elif task_status == 'failed':
print("Task failed.")
exit(1)
# 获取任务详细信息和漏洞报告
response = requests.get(f'{burp_api_url}/v0.1/scan/{task_id}/issues', headers=headers, proxies=burp_proxy, verify=cafile)
issues = response.json()
# 打印漏洞报告
print("\nVulnerability Report:")
for issue in issues:
print(f"\nIssue: {issue['name']}")
print(f"Severity: {issue['severity']}")
print(f"Confidence: {issue['confidence']}")
print(f"URL: {issue['url']}")
print(f"Description: {issue['description']['text']}")
print(f"Remediation: {issue['remediation']['text']}")这个脚本首先创建一个新的扫描任务,然后轮询任务状态,直到任务完成或失败。完成后,脚本获取任务详细信息,包括发现的漏洞,并打印漏洞报告。
未完待续
这篇文章写的基础太多了,下一篇准备直接上代码加注释。。。。。
此篇文章仅供学习交流使用,利用此篇文章做违法犯罪事情,均与博主无关!



















 630
630

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











