







字符串基本运算
- len()函数查看长度
first_name='sfdhs'
len(a)
- 转义符输出“”等易误读符号
- 拼接+
name=first_name+'Jordan'
- 重复*
name*3
3*name
- for语句
枚举字符串的每个字符
name='hello world'
for c in name
print(c)
- 函数
def count(name):
n=0
for c in name:
if c in 'aeiouAEIOU' :
n+=1
return n
name ="Michale Jorden"
print(count(name))
- 字符串索引[]
下标从零开始
下标越界显示错误
索引值以 0 为开始值,-1 为从末尾的开始位置。

name[1]
- 成员运算符in
判断一个字符串是否是另一个字符串的子串
返回True或者False - 切片
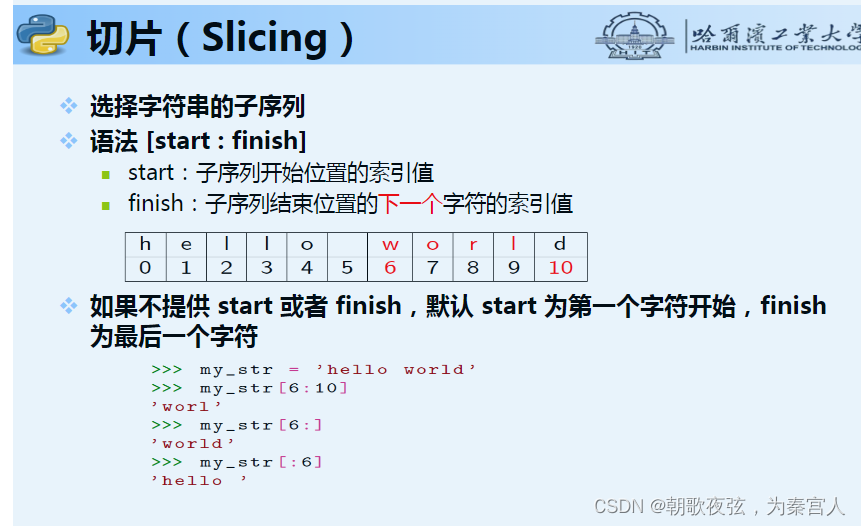
a='dfnsa'
print(a[:])
'dfnsa'
- 计数参数

- 替换replace

12.其他方法
 split切割后放在列表中
split切割后放在列表中
不加参数按照空格切
加参数按照参数左右来切(所有同类型参数)
原字符串不改变
a='namenane ne fdsa'
print(a.split('n'))
['', 'ame', 'a', 'e ', 'e fdsa']
print(a)
'namenane ne fdsa'
文件操作

f=open("name.txt","r")
读取的时候将每行回车一并读入
for line in f:
name=line.strip().title().lower()
函数联着一排写
去掉多余回车
print(name.title ())
或者
name=line.strip().lower().title()
print(name)
lower:所有字母小写
title:首字母大写
f.close()
字符串比较
直接用<>来比较
为真返回True,为假返回False
字符串的输出
格式输出:format/f-string
f-string进行相应的替换
>>> w = {'name': 'Runoob', 'url': 'www.runoob.com'}
>>> f'{w["name"]}: {w["url"]}'
'Runoob: www.runoob.com'
正则表达式
引入模块 import re


1编写程序,完成下列题目:(2分)
题目内容:
“Pig Latin”是一个英语儿童文字改写游戏,整个游戏遵从下述规则:
(1). 元音字母是‘a’、‘e’、‘i’、‘o’、‘u’。字母‘y’在不是第一个字母的情况下,也被视作元音字母。其他字母均为辅音字母。例如,单词“yearly”有三个元音字母(分别为‘e’、‘a’和最后一个‘y’)和三个辅音字母(第一个‘y’、‘r’和‘l’)。
(2). 如果英文单词以元音字母开始,则在单词末尾加入“hay”后得到“Pig Latin”对应单词。例如,“ask”变为“askhay”,“use”变为“usehay”。
(3). 如果英文单词以‘q’字母开始,并且后面有个字母‘u’,将“qu”移动到单词末尾加入“ay”后得到“Pig Latin”对应单词。例如,“quiet”变为“ietquay”,“quay”变为“ayquay”。
(4). 如果英文单词以辅音字母开始,所有连续的辅音字母一起移动到单词末尾加入“ay”后得到“Pig Latin”对应单词。例如,“tomato”变为“omatotay”, “school” 变为“oolschay”,“you” 变为“ouyay”,“my” 变为“ymay ”,“ssssh” 变为“sssshay”。
(5). 如果英文单词中有大写字母,必须所有字母均转换为小写。
输入格式:
一系列单词,单词之间使用空格分隔。
输出格式:
按照以上规则转化每个单词,单词之间使用空格分隔。
输入样例:
Welcome to the Python world Are you ready
输出样例:
elcomeway otay ethay ythonpay orldway arehay ouyay eadyray
def trans(word):
if word[0] in 'aeiou':return word+'hay'
elif len(word)>=2 and word[0]=='q' and word[1]=='u':
return word[2:]+'quay'
else:
x=0
for i in range(1,len(word)):
if word[i] in 'aeiouy':
x=i
break
return word[x:]+word[:x]+'ay'
sen=input()
sen=sen.lower()
sen=sen.split()
c=" "
for word in sen:
c=c+' '+(trans(word))
print(c.strip())
2
不定输入
题目内容:
依次判断一系列给定的字符串是否为合法的 Python 标识符。
输入格式:
一系列字符串,每个字符串占一行。
输出格式:
判断每行字符串是否为合法的 Python 标示符,如果合法则输出 True,否则输出 False。
输入样例:
abc
_def
21gh
输出样例:
True
True
False
def judge(word):
for i in range(0,len(word)):
if not (word[i] in '123465789qwertyuioplkjhgfdsazxcvbnm_'):
return False
if word[0] in '123456789': return False
return True
word=' '
import sys
while True:
word=sys.stdin.readline().strip()
if word=='':
break
print(judge(word))
3
题目内容:
依次计算一系列给定字符串的字母值,字母值为字符串中每个字母对应的编号值(A对应1,B对应2,以此类推,不区分大小写字母,非字母字符对应的值为0)的总和。例如,Colin 的字母值为 3 + 15 + 12 + 9 + 14 = 53
输入格式:
一系列字符串,每个字符串占一行。
输出格式:
计算并输出每行字符串的字母值。
输入样例:
Colin
ABC
输出样例:
53
6
import sys
while True:
word=sys.stdin.readline().strip().lower()
if word=='':
break
sum=0
for i in range(0,len(word)):
if word[i].isalpha():
sum+=ord(word[i])-96
print(sum)
















 370
370











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









