







文章目录
0 课程导读
0.1 学习课程三要素
- 端正学习态度:坚持上课!认真完成作业!难!
- 从内心深处:喜欢钻研底层技术!更难!
- 多动手:PL/0编译器 + ANTLR工具
0.2 章节划分
2456语法分析(重点)
3词法分析(重点)
78语义分析(难点)
(具体见下面1.3的各个环节展开)
第一章 引 论
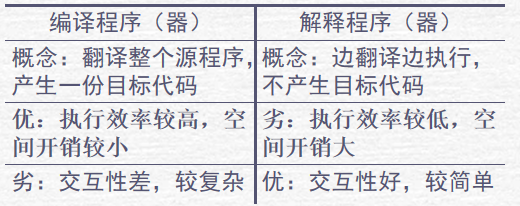
1.1 什么是编译程序
**翻译程序:**将一种语言(源语言)翻译成 另一种逻辑上等价的语言(目标语言)的程序。
**编译程序:**源语言为高级语言,目标语言 是低级语言(汇编或机器语言)的翻译程序。

重点:高级语言程序到可执行代码的转换过程

- 预处理程序:将源程序汇集在一起,并且负责文件合并、宏展开等任务。
- 另外,如果产生的目标程序是汇编代码形式,则需要经汇编程序翻译成机器代码。
1.2 解释程序
1.3 编译过程和编译程序的结构
重点:编译程序的功能和组织结构
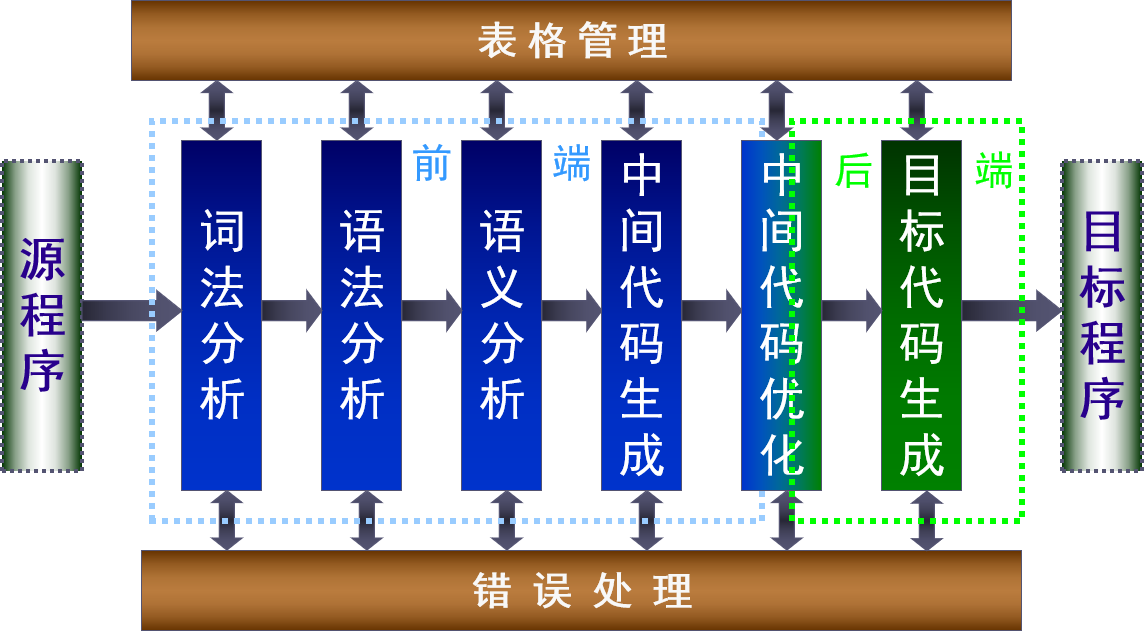
(下面将各个环节展开简单说明,具体内容分别在对应章节)
1.3.1 词法分析(扫描器,Scanner )
从左到右,逐个字符读入源程序,对 构成源程序的字符流进行扫描和分解,从而识别出各个单词,并给予种别(属性) 和内部形式(值)构成单词的内部表示。
第3章有详细的介绍。
例:Pascal源程序片段

1.3.2 语法分析(分析器,Analyzer)
在词法分析的基础上,对单词序列进 行语法检查,即分析源程序的语法结构, 并用明确的结构(如语法树)表示。
第2、4、5、6章有详细的介绍。
例:Pascal源程序片段

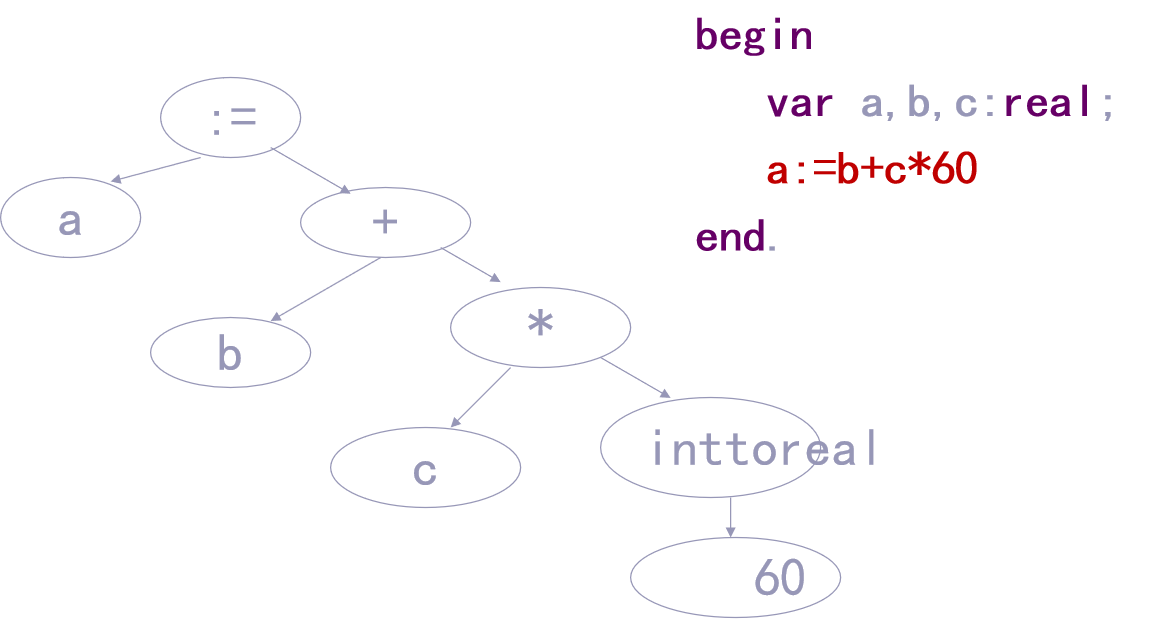
1.3.3 语义分析
检查程序有无语义错误,为代码生成阶 段收集类型信息,同时,解释程序的意义。
第7章和第8章有详细的介绍。
例:Pascal源程序片段
1.3.4 中间代码生成
在进行了上述的词法分析,语法分析和语义分析阶 段的工作之后,有的编译程序将源程序变成一种内部表示形式,这种内部表示形式叫做中间语言或中间代码。
所谓“中间代码”是一种结构简单、含义明确的记 号系统,这种记号系统可以设计为多种多样的形式,重 要的设计原则为两点:一是容易生成;二是容易将它翻 译成目标代码。
第8章有详细的介绍。

1.3.5 中间代码优化
代码优化──可多次
局部优化:
- 合并已知量 ── 编译时计算常量表达式
- 共享子表达式 ── 删除多余代码
- 降低运算强度 ── 乘方──乘
- 改变计算顺序 ── 减少指令、减少中间量
循环优化:
- 循环不变部分外提
- 下标地址计算优化
- 降低运算强度 ── 乘 ──加
与机器有关的优化:
- 使用特殊指令 ── 如计数转移指令
- 寄存器分配 第10章有详细的介绍。
1.3.6 目标代码的生成
把中间代码变换成特定机器上的绝对 指令代码或可重定位的指令代码或汇编指 令代码。
第11章有详细的介绍。
举个栗子:代码优化和目标代码的生成

1.表格管理(符号表)
为了合理的管理表格(构造、查找、更新), 设立一些专门子程序称为表格管理程序负责管 理表格。 (见下图)
2.出错处理
编译程序在各个阶段应诊断和报告源程序中 的错误,包括词法错误、语法错误和语义错误 等。

1.4 编译程序的组织
1.4.1 前端和后端

- 前端:与源语言有关,而与目标机无关的编译程序
- 后端:与目标机有关,而与源语言无关的编译程序
1.4.2 分遍(趟,PASS)问题
是对源程序或源程序的中间结果从头到尾扫描并完成规定任务的过程
1.5 编译程序的实现方法
1.预处理方法
用于语言的扩充。设已有L语言的编译器,其扩充语言L1的编译器可通过语言转换程序将L1程序转换为L程序,利用L的编译器,从而实现L1的编译器。
2.移植法
同一语言的编译器在不同机器间的移植。方法: a 目标代码的转换 b 修改中间代码到目标代码的转换
3.自展法
自我扩展,自己编写自己的编译器。
4.工具法
利用编译阶段各个部分的自动生成工具自动生成,例如常用的yacc和lex。
1.6 课后练习

【学习笔记汇总】
持续更新
【学习资料】
- 教材:《编译原理(第3版)王生原》
- 软件下载:PL0(VS2010版)(待上传)
- 待补充:可能是ppt、github等
















 496
496











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











