









一、实验要求
根据课本上的Hadoop的章节的内容,熟悉从系统下载、安装、命令使用,到MapReduce的简单编程实验。
二、实验内容
2.1 部署方式
Hadoop主要有两种安装方式,即传统解压包方式和Linux标准方式。安装Hadoop的同时,还要明确工作环境的构建模式。Hadoop部署环境分为单机模式、伪分布模式和分布式模式三种。
2.2 部署步骤(简述)
步骤1:制定部署规划;
步骤2:部署前工作;
步骤3:部署Hadoop;
步骤4:测试Hadoop。
2.3 准备环境
由于分布式计算需要用到很多机器,部署时用户须提供多台机器。本节使用Linux较成熟的发行版CentOS部署Hadoop,须注意的是新装系(CentOS)的机器不可以直接部署Hadoop,须做些设置后才可部署,这些设置主要为:改机器名,添加域名映射,关闭防火墙,安装JDK。
2.4 关于Hadoop依赖软件
Hadoop部署前提仅是完成修改机器名、添加域名映射、关闭防火墙和安装JDK这四个操作,其他都不需要。下面的SSH可能是部分读者关心,但实际上却完全不相关的操作或设置。
2.5 传统解压包部署
相对于标准Linux方式,解压包方式部署Hadoop有利于用户更深入理解Hadoop体系架构,建议先采用解压包方式部署Hadoop,熟悉后可采用标准Linux方式部署Hadoop。以下将实现在三台机器上部署Hadoop。
三、实现过程(截图+描述)
3.1 三台linux服务器的安装
1. 安装VMware
- VMware虚拟机软件是一个“虚拟PC”软件,它使你可以在一台机器上同时运行二个或更多Windows、DOS、LINUX系统。与“多启动”系统相比,VMWare采用了完全不同的概念。
- 我们可以通过VMware来安装我们的linux虚拟机,然后通过linux虚拟机来进行集群的安装,VMware的安装双击之后,一路下一步即可,尽量不要装在操作系统盘里面了,VMware的安装步骤省略
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-YoqWMuuS-1622388875968)(https://www.yuque.com/api/filetransfer/images?url=https%3A%2F%2Fimg-blog.csdnimg.cn%2F20210515091151461.png%3Fx-oss-process%3Dimage%2Fwatermark%2Ctype_ZmFuZ3poZW5naGVpdGk%2Cshadow_10%2Ctext_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3dlaXhpbl80NDU4OTk5MQ%3D%3D%2Csize_16%2Ccolor_FFFFFF%2Ct_70&sign=597dd73eb242c19a30e0ffce908ce4d3890e11b774df0808444f6fd056ef0ca7)]
2. 通过Vmware安装第一台linux机器
- 我们通过Vmware可以安装第一台我们的linux机器,接下来我们来看如何通过VMWare创建linux虚拟机,并给我们的虚拟机挂载操作系统
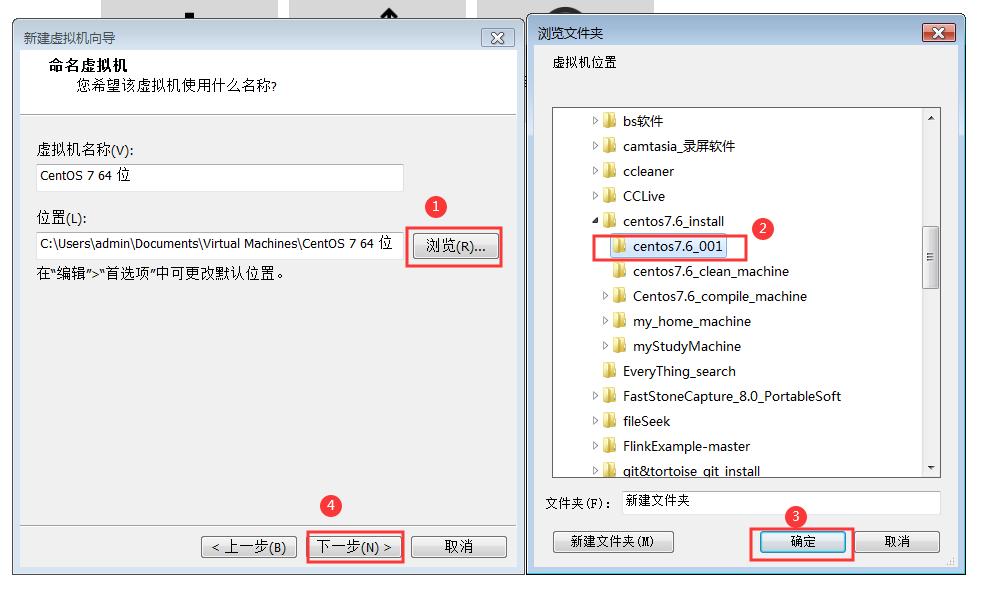
1:双击Vmware打开之后,点击创建新的虚拟机
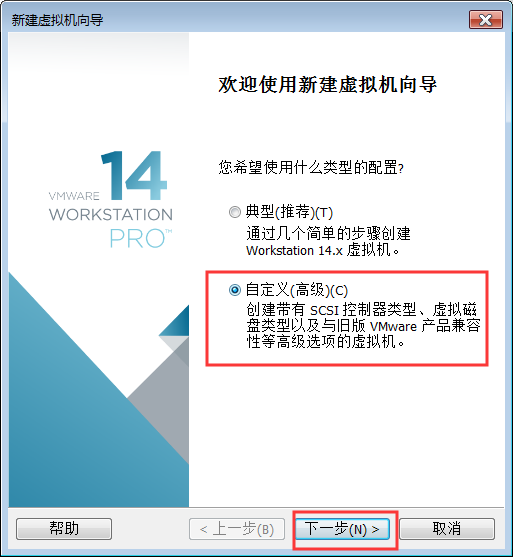
2:选择自定义安装配置
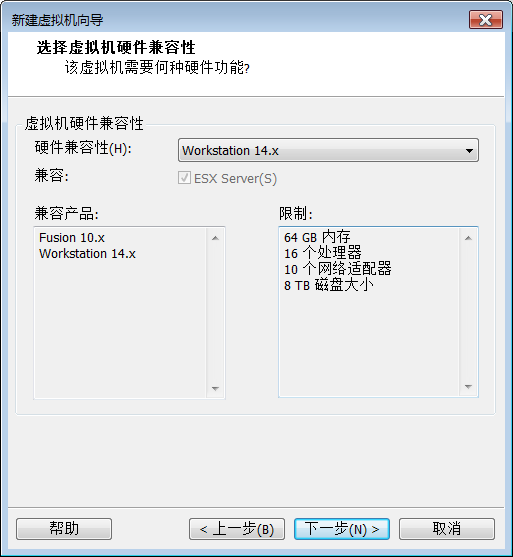
3:选择稍后安装操作系统
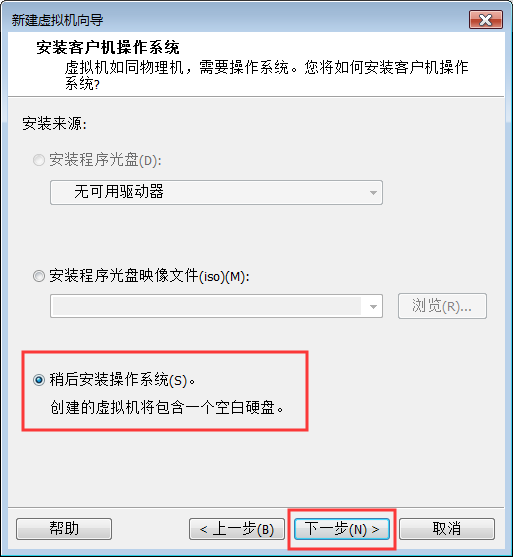
4:选择稍后安装操作系统
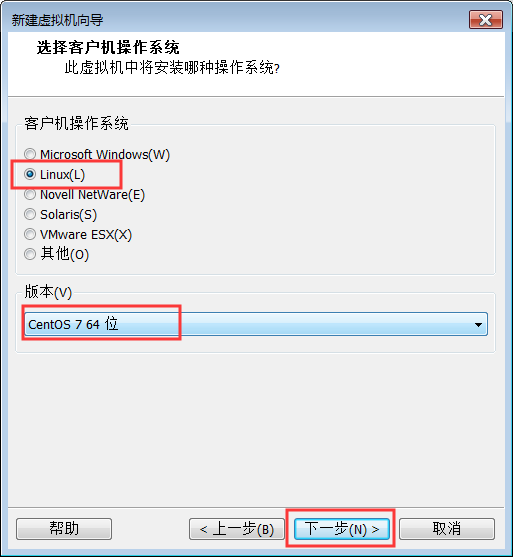
5:选择安装路径,尽量不要放在C盘,并且所在盘符的剩余空间尽量大些
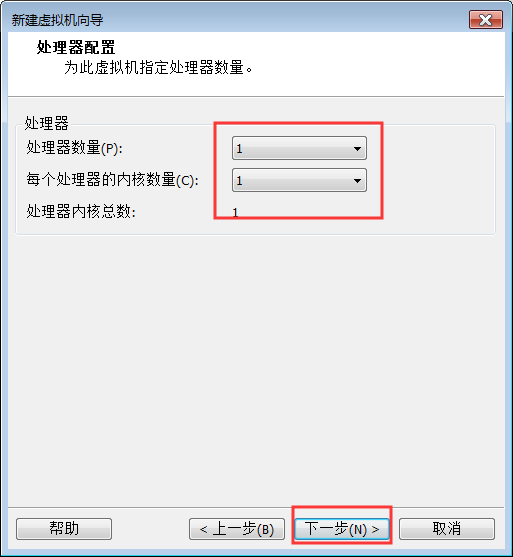
6:CPU核数,默认即可
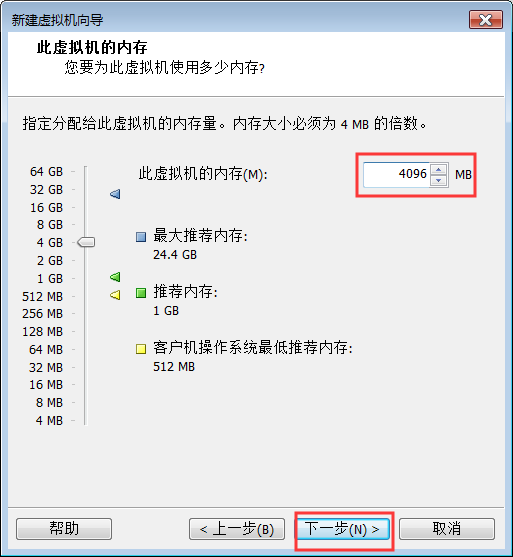
7:虚拟机内存根据自身windows电脑进行调整
例如如果windows是8GB内存,那么每台虚拟机内存给2048M内存,如果windows是16GB没存,那么每台虚拟机可以给3072M内存即可
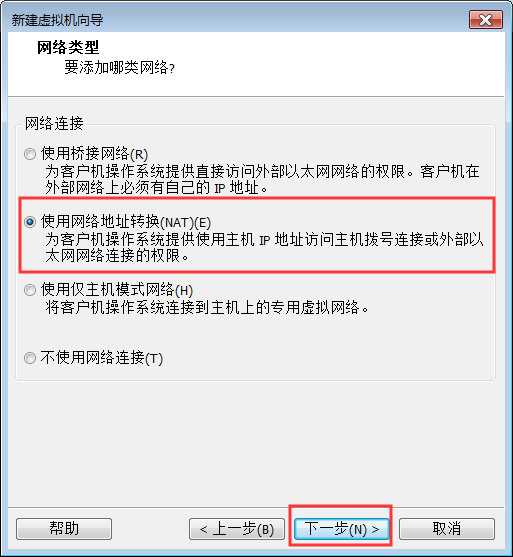
8:网络配置一定要选择NAT
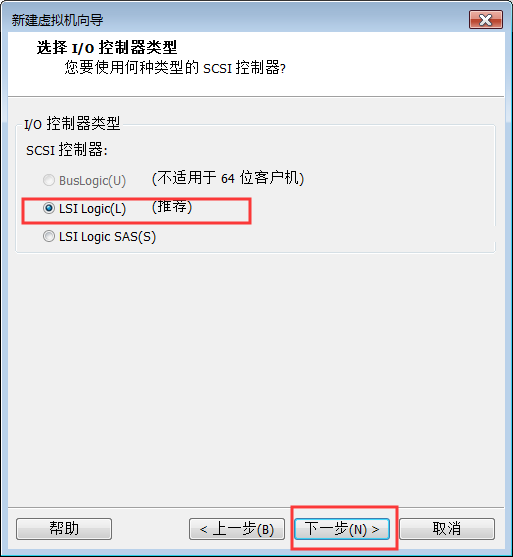
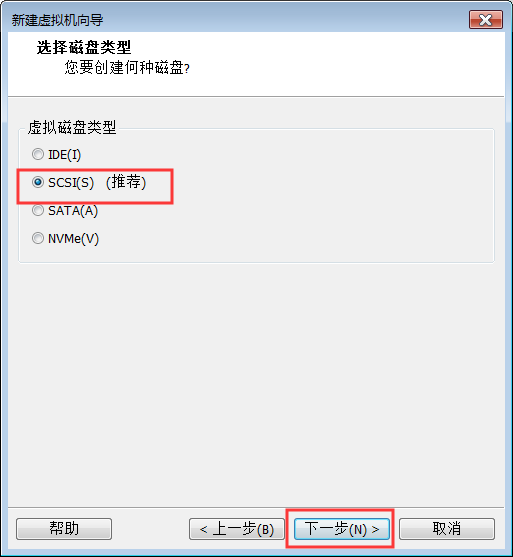
9:磁盘大小尽量给40GB
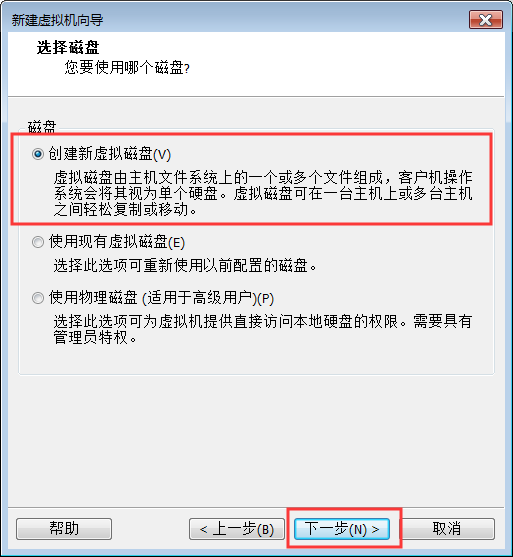
注意:千万不要勾选“立即分配所有磁盘空间”
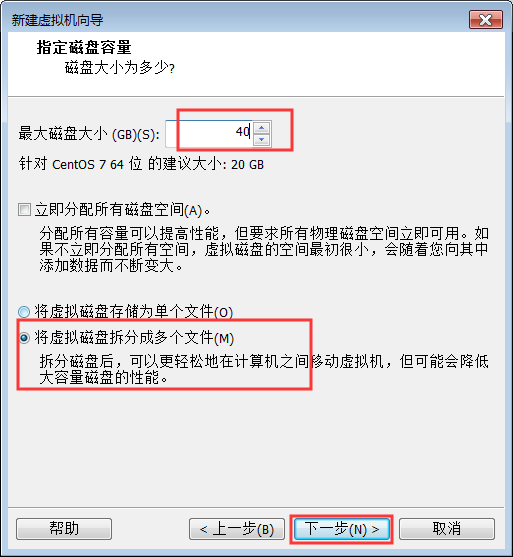
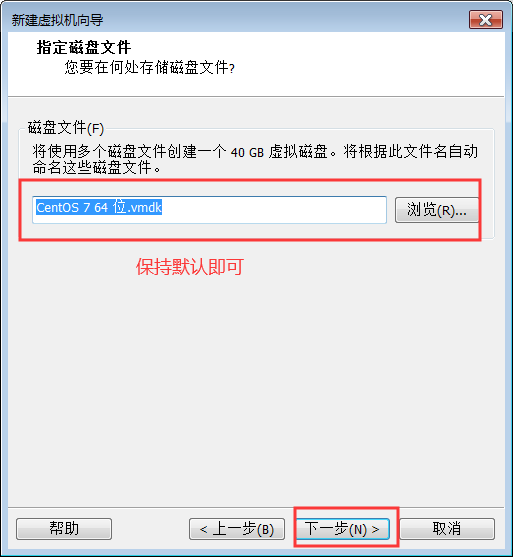
10:完成
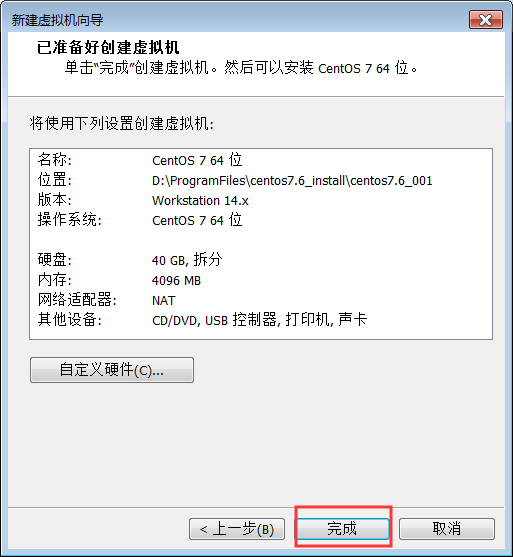
3. 为我们创建的linux虚拟机挂载操作系统
- 我们现在已经有了一台虚拟电脑了,就类似我们刚刚买了一台电脑回来,只不过不同的是我们这台虚拟电脑还没有操作系统我们需要为这台电脑挂在操作系统出来
1:通过设置来挂载操作系统
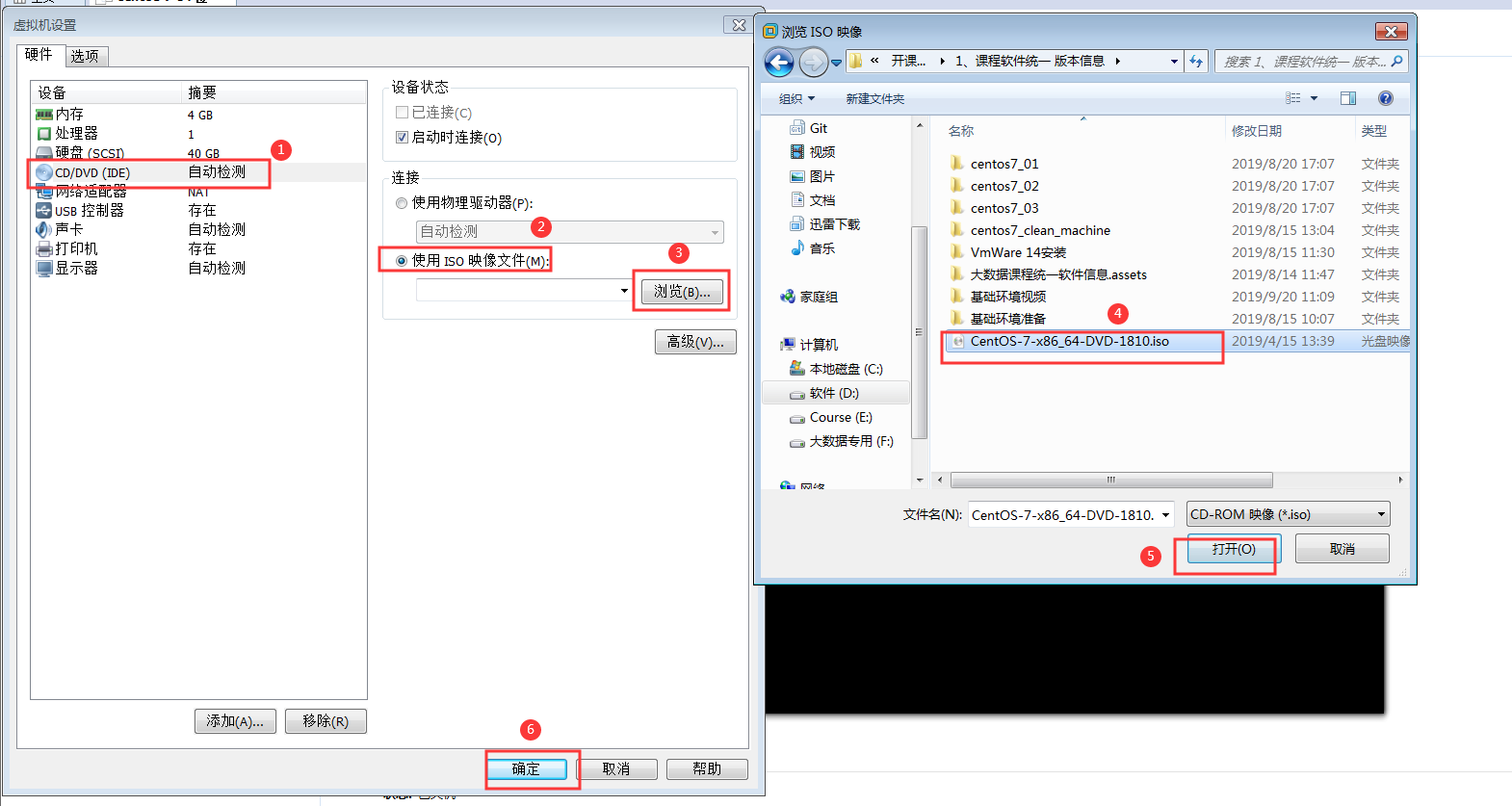
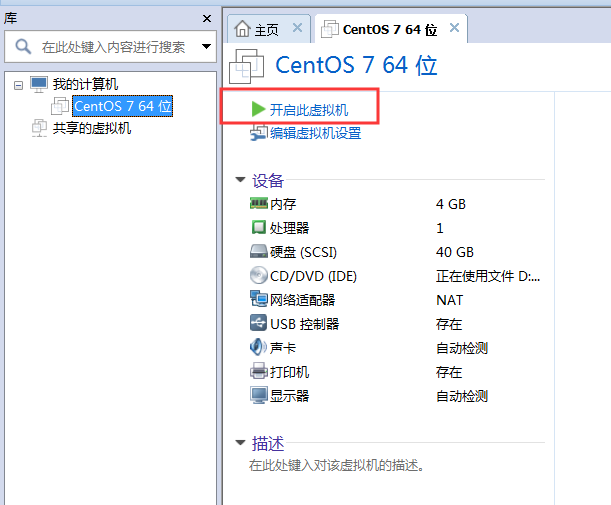
2:直接回车开始安装
用键盘的方向键,选中“Install CentOS 7”,然后按回车,开始安装
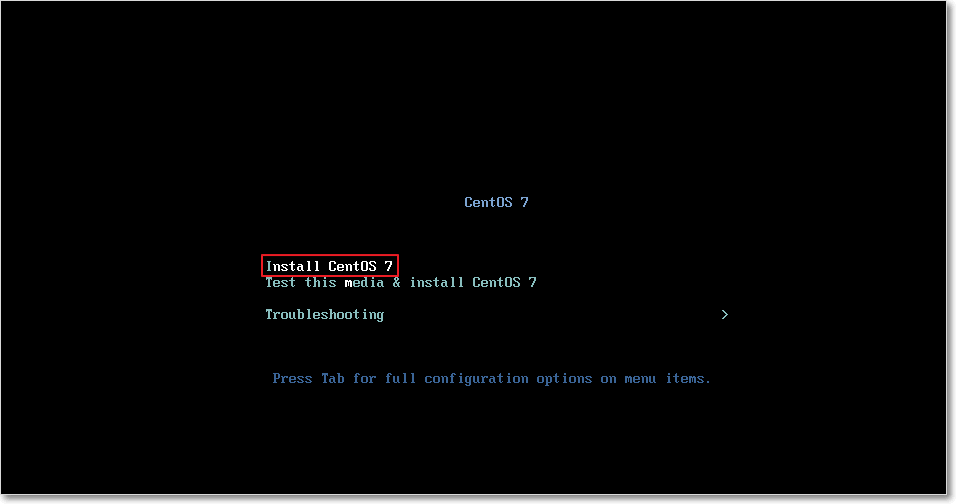
再按回车键
3:设置键盘为英文键盘
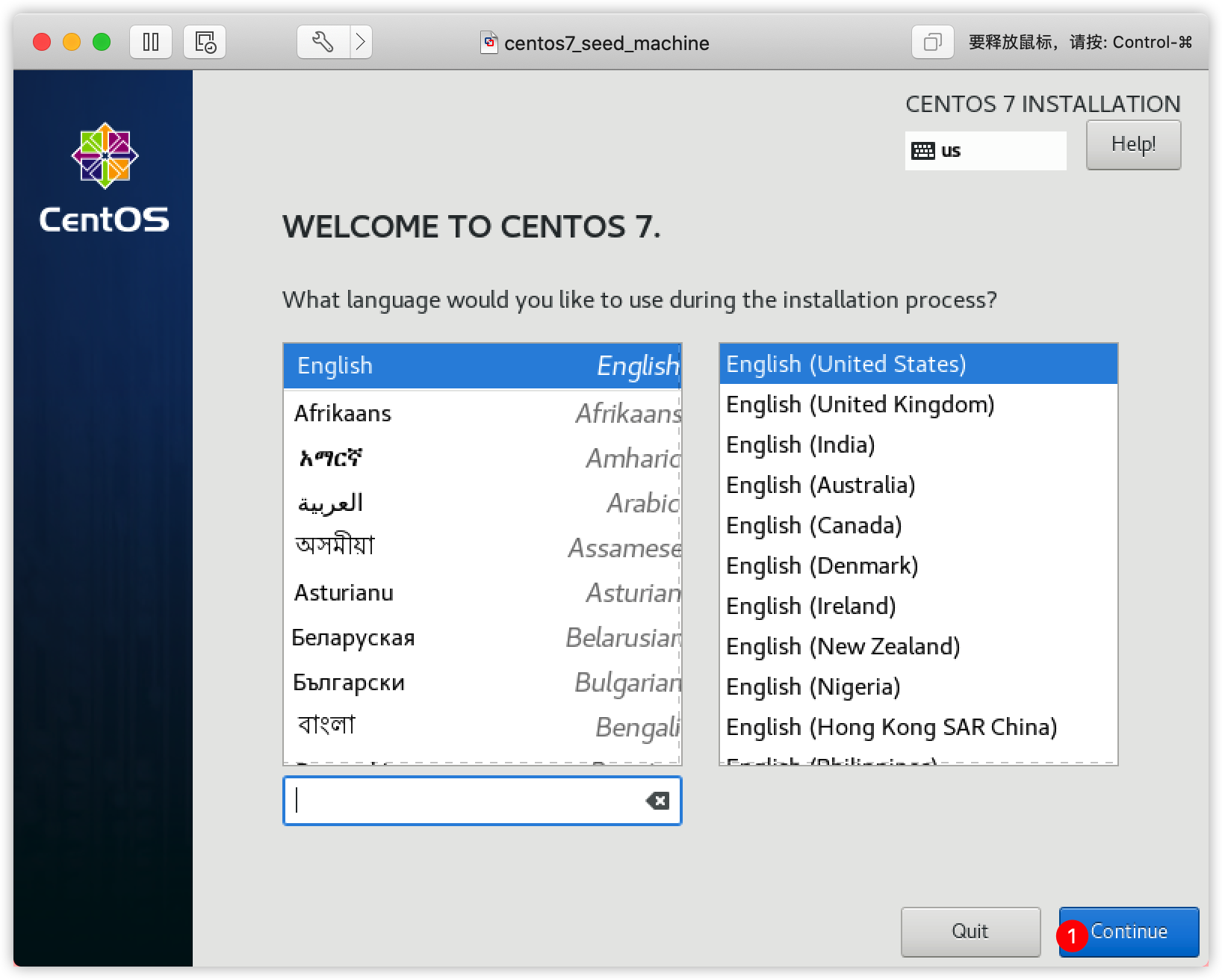
4:接下来配置这三项
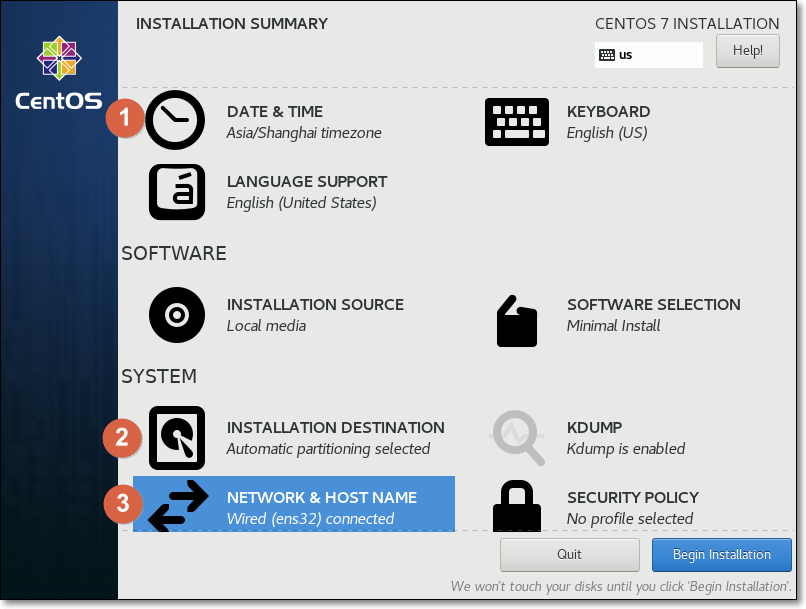
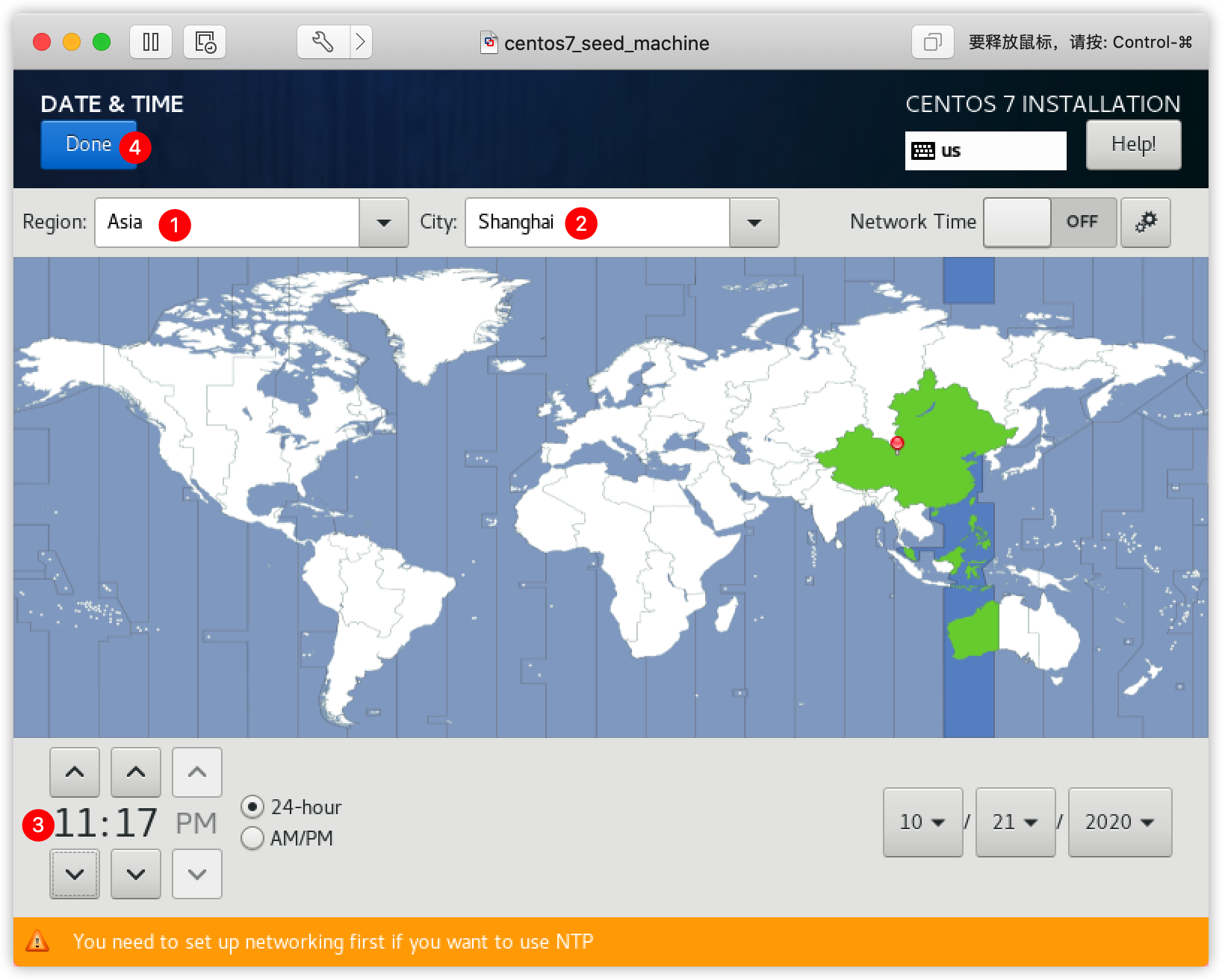
(1)设置①时区为Asia/Shanghai
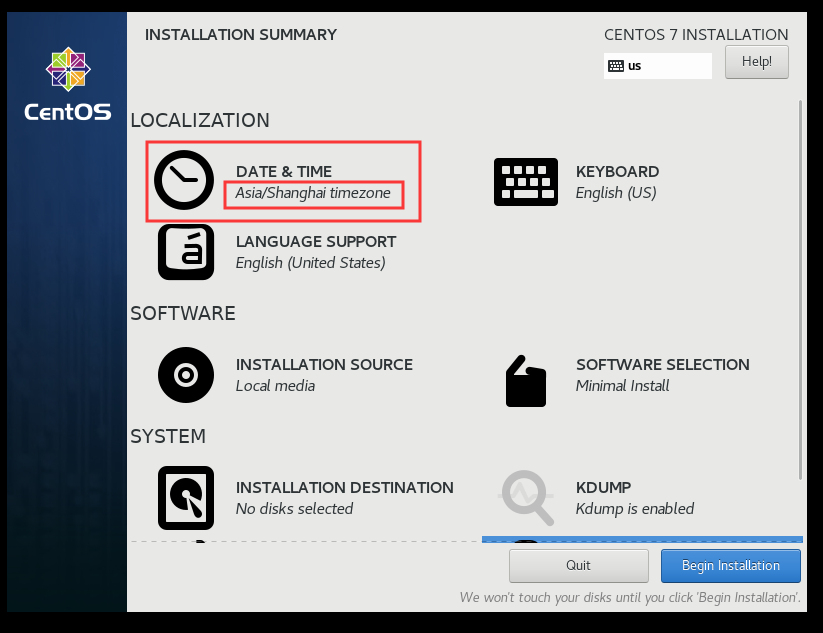
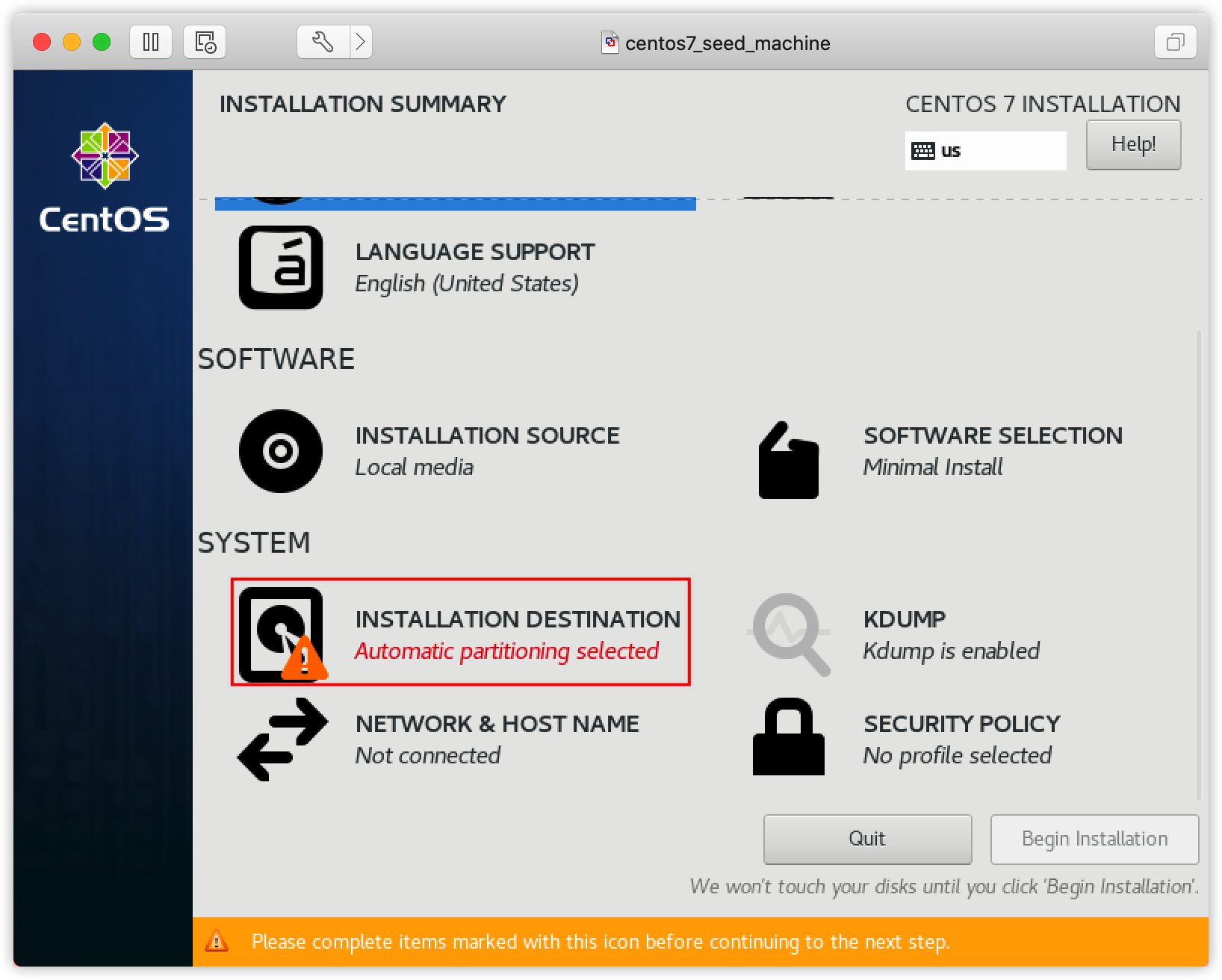
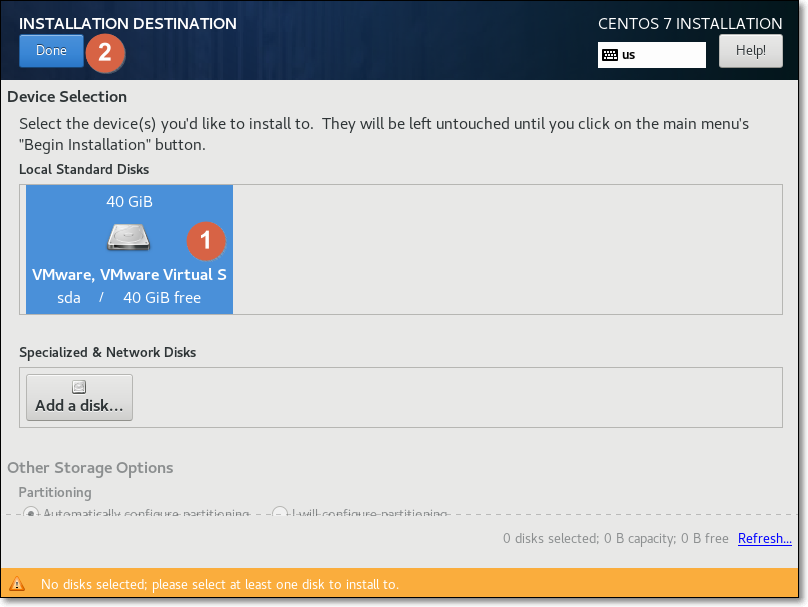
(2)设置②INSTALATION DESTINATION
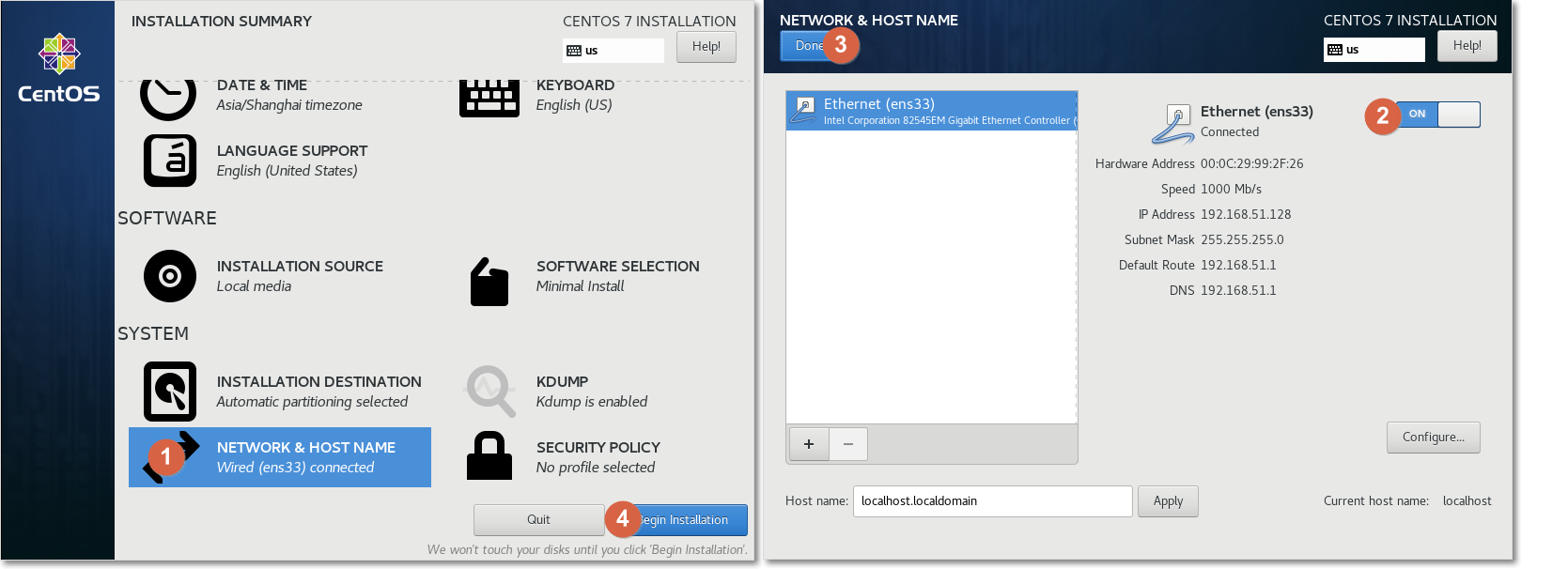
(3)设置③NETWORK & HOST NAME
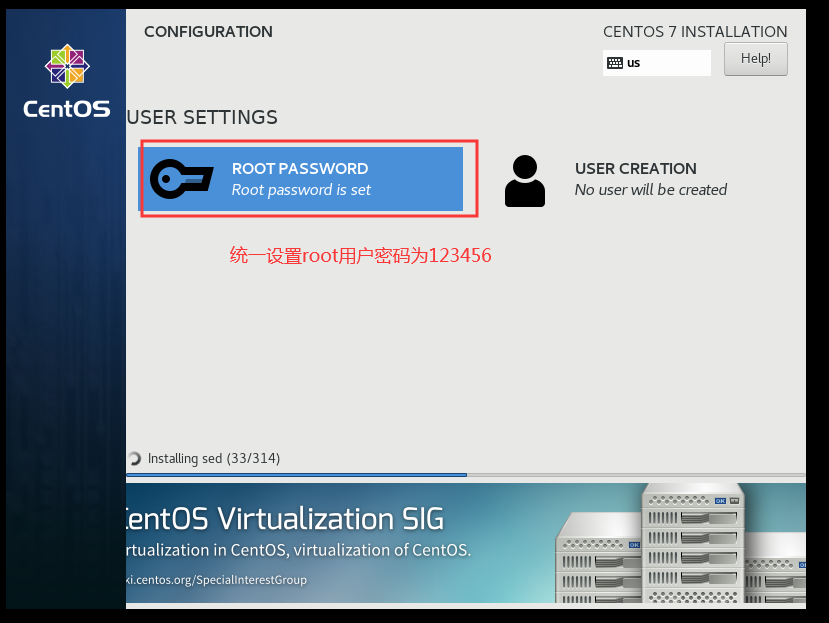
5:设置root用户密码
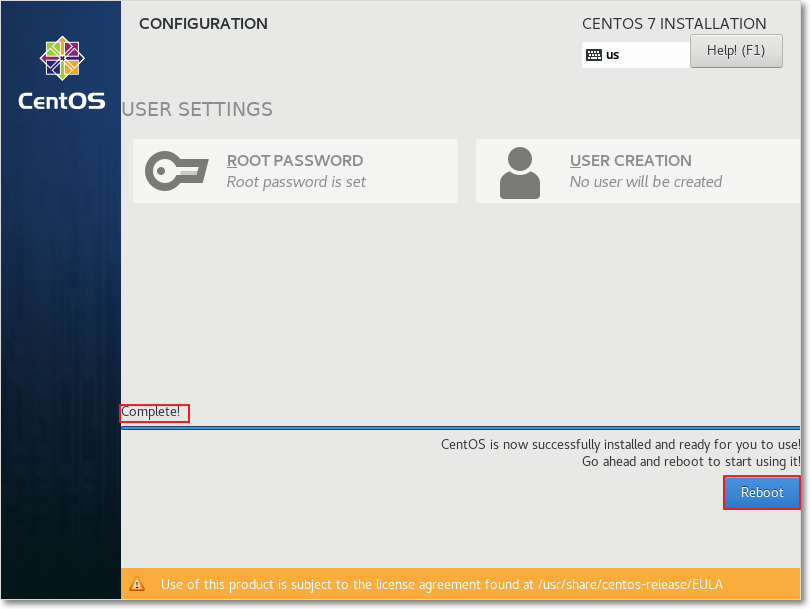
6:安装完成之后重启reboot即可
此过程稍长,耐心等待
4. 为我们的linux虚拟机设置网络配置
- 我们的linux虚拟机已经创建并挂载好了操作系统,接下来我们可以为我们的第一台虚拟机来设置网络地址了,设置网络地址比较麻烦,尽量参见视频进行一步步的操作
1:设置虚拟机的网段
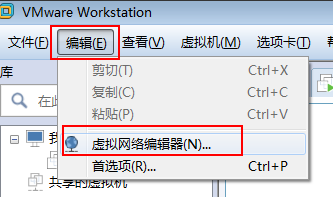
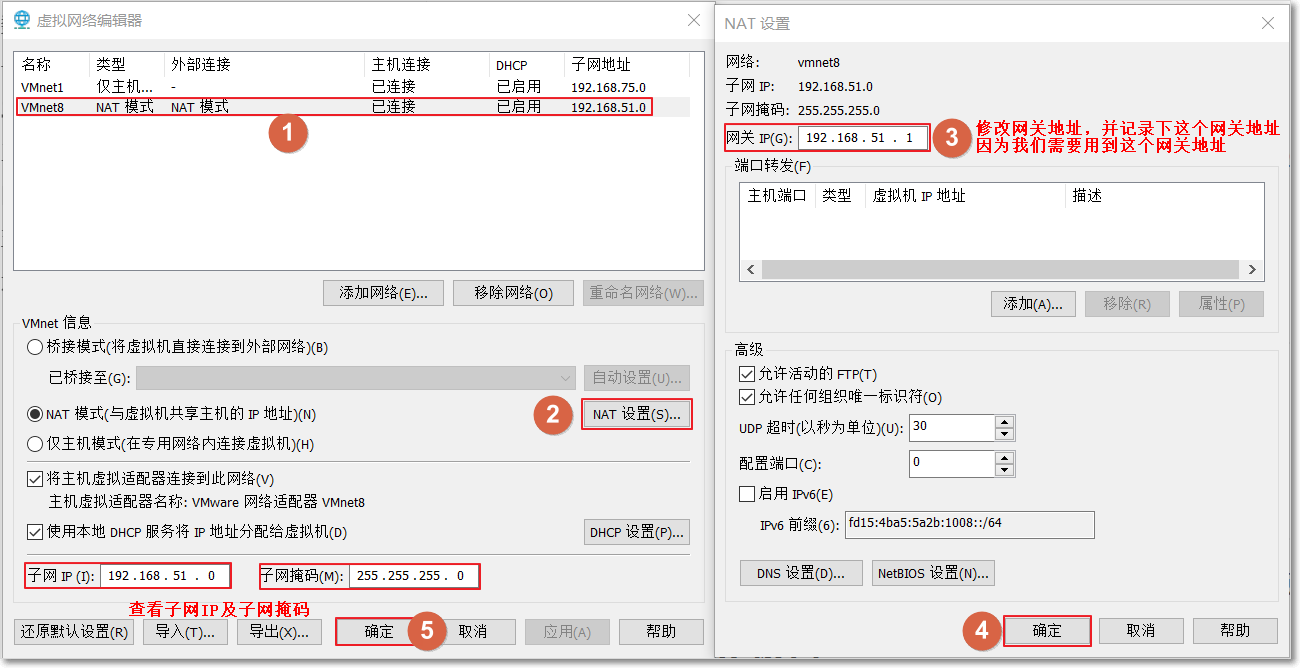
2:查看NAT模式的网关,子网IP以及子网掩码
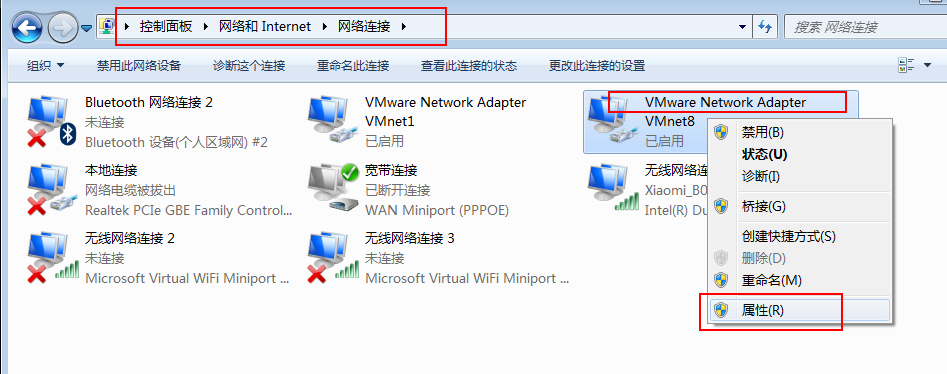
3:设置window当中的VMNet8网络地址
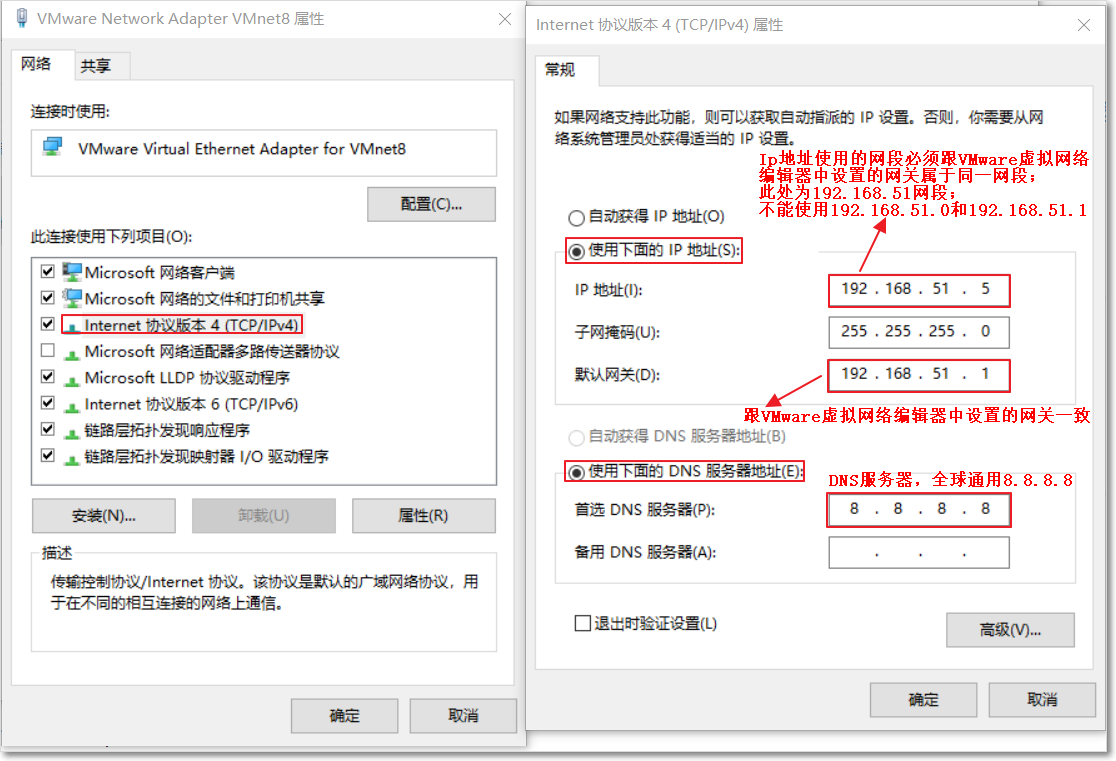
4:设置linux当中的网络
-
我们已经配置好了Vmware当中的网络、windows当中的网络;
-
剩下就是配置linux虚拟机当中的网络,配置好了linux当中的网络,我们的linux就可以联网使用了
-
登录linux
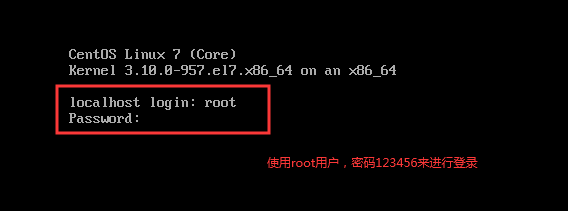
编辑配置文件
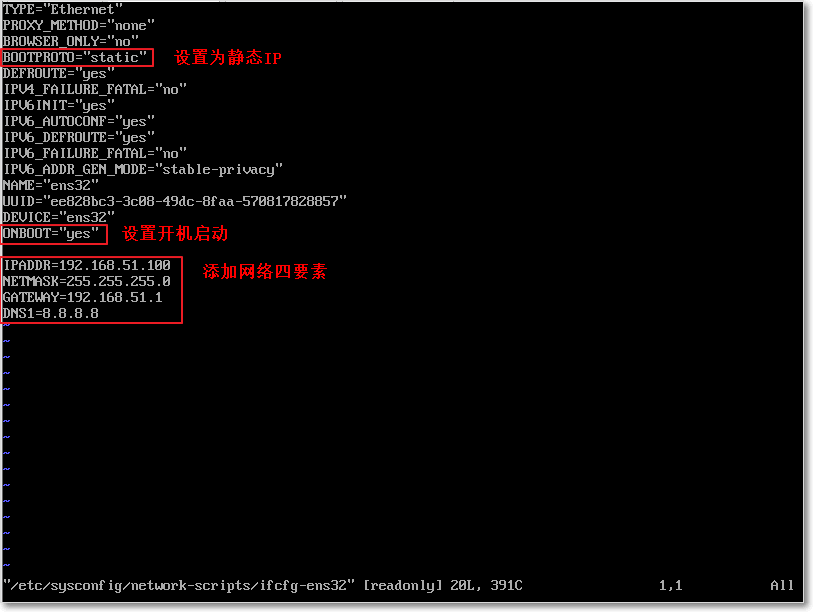
vi /etc/sysconfig/network-scripts/ifcfg-ens33
添加联网四要素
IPADDR=192.168.51.100
NETMASK=255.255.255.0
GATEWAY=192.168.51.1
DNS1=8.8.8.8
具体参考下图
更改完成配置,重启网络服务
systemctl restart network
安装一些常用的软件
yum -y install vim
yum -y install net-tools
关机
init 0
5. 克隆第一台机器
- 现在我们已经有了种子机器了,我们可以通过种子机器进行复制或者克隆出三台机器
- 关闭linux种子机器,然后准备进行克隆
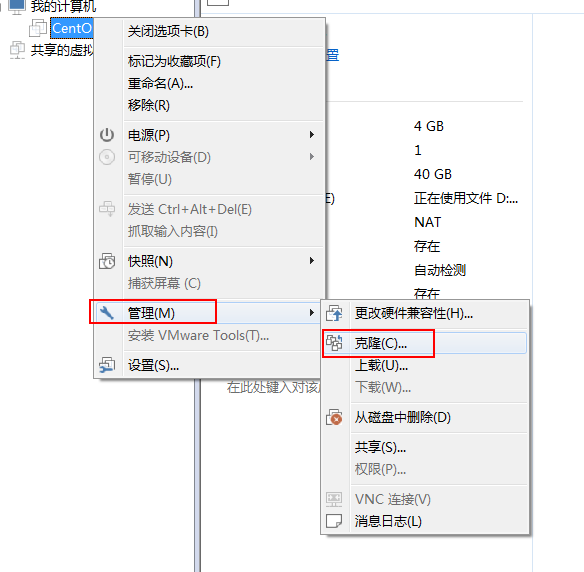
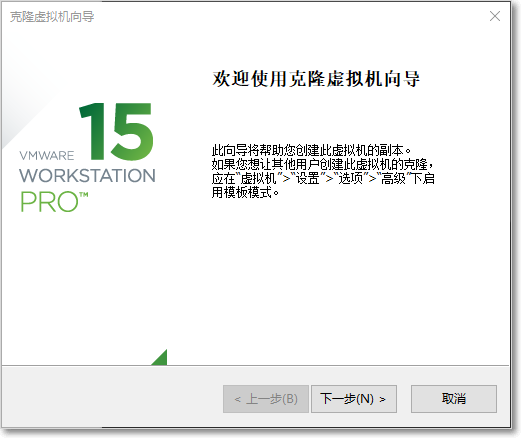
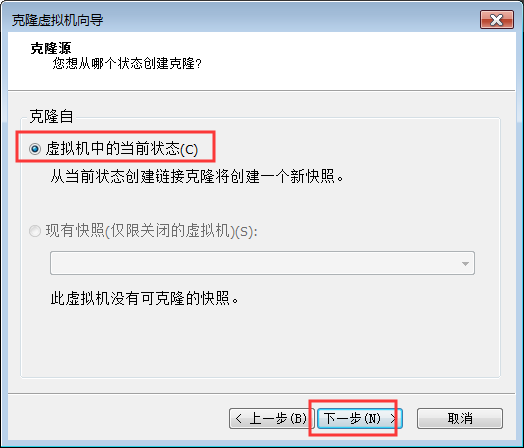
选择创建完整克隆
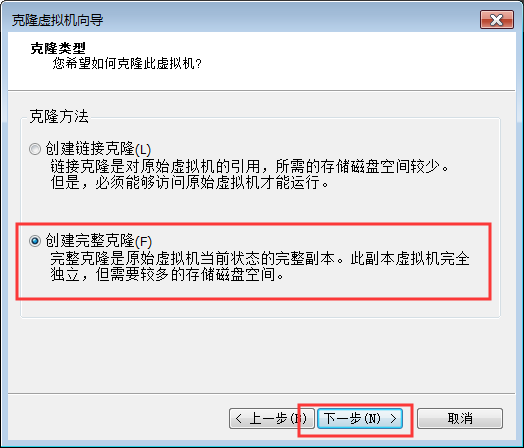
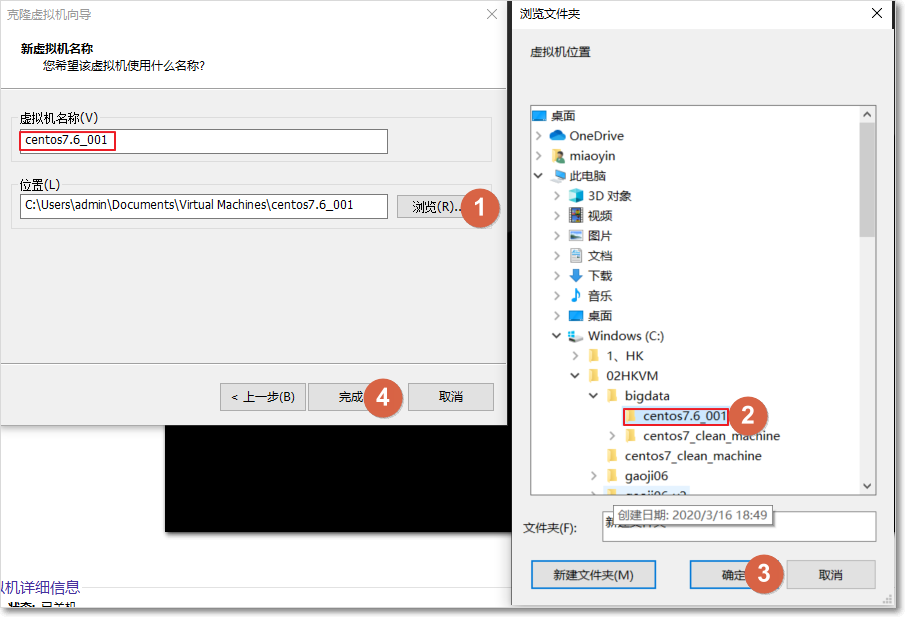
6. 更改克隆机器的IP地址
-
三台机器的ip地址分别是
192.168.51.100、192.168.51.110、192.168.51.120 -
克隆出来的机器IP地址与种子的ip地址一样,我们将第二台机器的IP地址更改为192.168.51.110即可
-
启动虚拟机,并通过root用户,密码123456来进行登录,然后来更改linux机器的IP地址
vi /etc/sysconfig/network-scripts/ifcfg-ens33
IPADDR=192.168.51.110
NETMASK=255.255.255.0
GATEWAY=192.168.51.1
DNS1=8.8.8.8
- 依照上面步骤,接着克隆第三台机器,并将第三台机器的IP地址设置为
192.168.51.120
建议:三台机器准备好后,打个快照,便于出错后恢复
3.2 安装大数据集群前的环境准备
1. 三台虚拟机关闭防火墙
三台机器执行以下命令(root用户来执行)
systemctl stop firewalld
systemctl disable firewalld
2. 三台机器关闭selinux
三台机器执行以下命令关闭selinux
vi /etc/sysconfig/selinux
SELINUX=disabled
3. 三台机器更改主机名
三台机器执行以下命令更改主机名
vi /etc/hostname
第一台机器更改内容
node01.kaikeba.com
第二台机器更改内容
node02.kaikeba.com
第三台机器更改内容
node03.kaikeba.com
4. 三台机器做主机名与IP地址的映射
三台机器执行以下命令更改主机名与IP地址的映射
vi /etc/hosts
192.168.51.100 node01.kaikeba.com node01
192.168.51.110 node02.kaikeba.com node02
192.168.51.120 node03.kaikeba.com node03
5. 三台机器时钟同步
第一种同步方式:通过网络进行时钟同步
通过网络连接外网进行时钟同步,必须保证虚拟机连上外网
三台机器都安装ntpdate
yum -y install ntpdate
阿里云时钟同步服务器
ntpdate ntp4.aliyun.com
三台机器定时任务
crontab -e
添加如下内容
*/1 * * * * /usr/sbin/ntpdate ntp4.aliyun.com;
第二种同步方式:内网某机器作为时钟同步服务器
以下操作都在root用户下面执行,通过su root切换到root用户
以192.168.51.100这台服务器的时间为准进行时钟同步
第一步:三台机器确定是否安装了ntpd的服务
三台机器确认是否安装ntpdate时钟同步工具
rpm -qa | grep ntpdate
如果没有安装,三台机器执行以下命令可以进行在线安装
yum -y install ntpdate
安装后如下图

node01安装ntp
yum -y install ntp
三台机器,执行以下命令,设置时区为中国上海时区
timedatectl set-timezone Asia/Shanghai
第二步:node01启动ntpd服务
我们需要启动node01的ntpd服务,作为服务端,对外提供同步时间的服务
启动ntpd的服务
#启动ntpd服务
systemctl start ntpd
#设置ntpd服务开机启动
systemctl enable ntpd
第三步:修改node01服务器配置
修改node01这台服务器的时钟同步配置,允许对外提供服务
vim /etc/ntp.conf
添加以下两行内容
# 同意192.168.51.0网段(修改成自己的网段)的所有机器与node01同步时间
restrict 192.168.51.0 mask 255.255.255.0 nomodify notrap
server 127.127.1.0
注释掉以下这四行内容
#server 0.centos.pool.ntp.org iburst
#server 1.centos.pool.ntp.org iburst
#server 2.centos.pool.ntp.org iburst
#server 3.centos.pool.ntp.org iburst
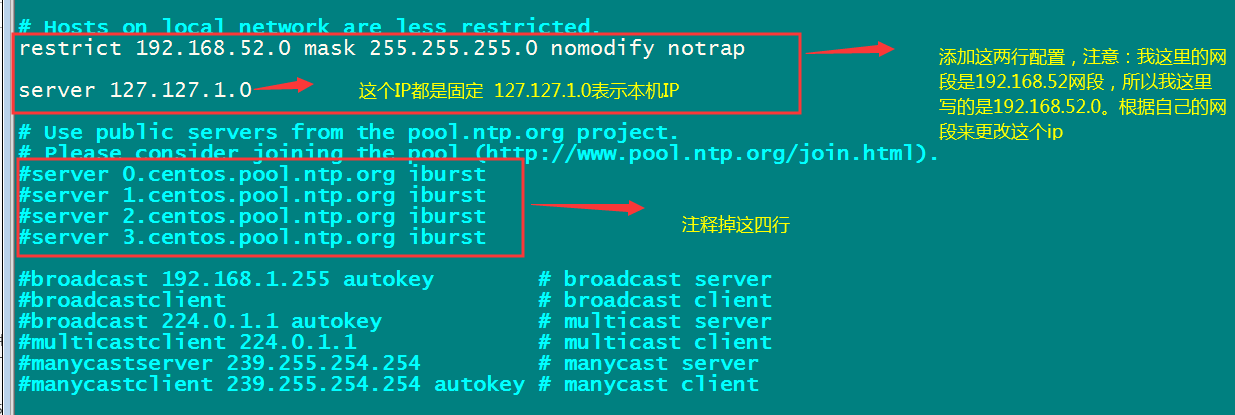
修改完成之后,重启node01的ntpd服务
systemctl restart ntpd
至此,ntpd的服务端已经安装配置完成,接下来配置客户端与服务端进行同步
第四步:配置node02与node03同步node01的时间
客户端node02与node03设置时区与node01保持一致Asia/Shanghai
node02与node03修改配置文件,保证每次时间写入硬件时钟
vim /etc/sysconfig/ntpdate
SYNC_HWCLOCK=yes
node02与node03修改定时任务,定时与node01同步时间
[root@node03 hadoop]# crontab -e
增加如下内容
*/1 * * * * /usr/sbin/ntpdate node01
6. 三台机器添加普通用户
三台linux服务器统一添加普通用户hadoop,并给以sudo权限,用于以后所有的大数据软件的安装
(目的是避免用root用户不小心执行了一些不可逆的操作)
并统一设置普通用户的密码为 123456
useradd hadoop
passwd hadoop
普通用户的密码设置为123456
三台机器为普通用户添加sudo权限
visudo
增加如下内容
hadoop ALL=(ALL) ALL
7. 三台定义统一目录
定义三台linux服务器软件压缩包存放目录,以及解压后安装目录,三台机器执行以下命令,创建两个文件夹,一个用于存放软件压缩包目录,一个用于存放解压后目录
mkdir -p /kkb/soft # 软件压缩包存放目录
mkdir -p /kkb/install # 软件解压后存放目录
chown -R hadoop:hadoop /kkb # 将文件夹权限更改为hadoop用户
创建hadoop用户之后,我们三台机器都通过hadoop用户来进行操作,以后再也不需要使用root用户来操作了
三台机器通过 su hadoop命令来切换到hadoop用户
su hadoop
8. 三台机器hadoop用户免密码登录
重启下3个linux虚拟机,让主机名生效
第一步:三台机器在hadoop用户下执行以下命令生成公钥与私钥
ssh-keygen -t rsa
执行上述命令之后,按三次Enter键即可生成了
第二步:三台机器在hadoop用户下,执行命令拷贝公钥到node01服务器
ssh-copy-id node01
第三步:node01服务器将公钥拷贝给node02与node03
node01在hadoop用户下,执行以下命令,将authorized_keys拷贝到node02与node03服务器
cd /home/hadoop/.ssh/
scp authorized_keys node02:$PWD
scp authorized_keys node03:$PWD
第四步:验证;从任意节点是否能免秘钥登陆其他节点;如node01免密登陆node02
ssh node02
9. 三台机器关机重启
三台机器在hadoop用户下执行以下命令,实现关机重启
sudo reboot -h now
10. 三台机器安装jdk
- 使用hadoop用户来重新连接三台机器,然后使用hadoop用户来安装jdk软件
- 上传压缩包到第一台服务器的/kkb/soft下面,然后进行解压,配置环境变量即可,三台机器都依次安装即可
cd /kkb/soft/
tar -xzvf jdk-8u141-linux-x64.tar.gz -C /kkb/install/
sudo vim /etc/profile
#添加以下配置内容,配置jdk环境变量
export JAVA_HOME=/kkb/install/jdk1.8.0_141
export PATH=$PATH:$JAVA_HOME/bin
让修改马上生效
source /etc/profile
建议:三台机器准备好后,打个快照,便于出错后恢复
3.3 hadoop集群的安装
- 安装环境服务部署规划
| 服务器IP | node01 | node02 | node03 |
|---|---|---|---|
| HDFS | NameNode | ||
| HDFS | SecondaryNameNode | ||
| HDFS | DataNode | DataNode | DataNode |
| YARN | ResourceManager | ||
| YARN | NodeManager | NodeManager | NodeManager |
| 历史日志服务器 | JobHistoryServer |
第一步:上传压缩包并解压
- 将我们重新编译之后支持snappy压缩的hadoop包上传到第一台服务器并解压;第一台机器执行以下命令
cd /kkb/soft/
tar -xzvf hadoop-3.1.4.tar.gz -C /kkb/install
第二步:查看hadoop支持的压缩方式以及本地库
第一台机器执行以下命令
cd /kkb/install/hadoop-3.1.4/
bin/hadoop checknative
如果出现openssl为false,那么所有机器在线安装openssl即可,执行以下命令,虚拟机联网之后就可以在线进行安装了
sudo yum -y install openssl-devel
第三步:修改配置文件
下面是配置一些hadoop环境运行所需的一些文件,如果是实验可跳过
修改hadoop-env.sh
第一台机器执行以下命令
cd /kkb/install/hadoop-3.1.4/etc/hadoop/
vim hadoop-env.sh
export JAVA_HOME=/kkb/install/jdk1.8.0_141
修改core-site.xml
第一台机器执行以下命令
vim core-site.xml
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://node01:8020</value> </property>
<property>
<name>hadoop.tmp.dir</name>
<value>/kkb/install/hadoop-3.1.4/hadoopDatas/tempDatas</value> </property> <!-- 缓冲区大小,实际工作中根据服务器性能动态调整;默认值4096 --> <property> <name>io.file.buffer.size</name> <value>4096</value> </property> <!-- 开启hdfs的垃圾桶机制,删除掉的数据可以从垃圾桶中回收,单位分钟;默认值0 -->
<property> <name>fs.trash.interval</name> <value>10080</value> </property></configuration>
修改hdfs-site.xml
第一台机器执行以下命令
vim hdfs-site.xml
<configuration>
<!-- NameNode存储元数据信息的路径,实际工作中,一般先确定磁盘的挂载目录,然后多个目录用,进行分割 -->
<!-- 集群动态上下线
<property> <name>dfs.hosts</name> <value>/kkb/install/hadoop-3.1.4/etc/hadoop/accept_host</value> </property> <property> <name>dfs.hosts.exclude</name> <value>/kkb/install/hadoop-3.1.4/etc/hadoop/deny_host</value>
</property>
-->
<property>
<name>dfs.namenode.secondary.http-address</name> <value>node01:9868</value> </property> <property>
<name>dfs.namenode.http-address</name> <value>node01:9870</value> </property>
<!-- namenode保存fsimage的路径 -->
<property> <name>dfs.namenode.name.dir</name> <value>file:///kkb/install/hadoop-3.1.4/hadoopDatas/namenodeDatas</value> </property> <!-- 定义dataNode数据存储的节点位置,实际工作中,一般先确定磁盘的挂载目录,然后多个目录用,进行分割 -->
<property> <name>dfs.datanode.data.dir</name> <value>file:///kkb/install/hadoop-3.1.4/hadoopDatas/datanodeDatas</value> </property>
<!-- namenode保存editslog的目录 -->
<property> <name>dfs.namenode.edits.dir</name>
<value>file:///kkb/install/hadoop-3.1.4/hadoopDatas/dfs/nn/edits</value>
</property>
<!-- secondarynamenode保存待合并的fsimage -->
<property> <name>dfs.namenode.checkpoint.dir</name> <value>file:///kkb/install/hadoop-3.1.4/hadoopDatas/dfs/snn/name</value> </property>
<!-- secondarynamenode保存待合并的editslog -->
<property>
<name>dfs.namenode.checkpoint.edits.dir</name> <value>file:///kkb/install/hadoop-3.1.4/hadoopDatas/dfs/nn/snn/edits</value>
</property> <property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
<property>
<name>dfs.blocksize</name>
<value>134217728</value>
</property>
</configuration>
修改mapred-site.xml
第一台机器执行以下命令
vim mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.job.ubertask.enable</name>
<value>true</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>node01:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>node01:19888</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
</configuration>
修改yarn-site.xml
第一台机器执行以下命令
vim yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node01</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
修改workers文件
第一台机器执行以下命令
vim workers
原内容替换为
node01
node02
node03
第四步:创建文件存放目录
第一台机器执行以下命令
node01机器上面创建以下目录
mkdir -p /kkb/install/hadoop-3.1.4/hadoopDatas/tempDatas
mkdir -p /kkb/install/hadoop-3.1.4/hadoopDatas/namenodeDatas
mkdir -p /kkb/install/hadoop-3.1.4/hadoopDatas/datanodeDatas
mkdir -p /kkb/install/hadoop-3.1.4/hadoopDatas/dfs/nn/edits
mkdir -p /kkb/install/hadoop-3.1.4/hadoopDatas/dfs/snn/name
mkdir -p /kkb/install/hadoop-3.1.4/hadoopDatas/dfs/nn/snn/edits
第五步:安装包的分发scp与rsync
在linux当中,用于向远程服务器拷贝文件或者文件夹可以使用scp或者rsync,这两个命令功能类似都是向远程服务器进行拷贝,只不过scp是全量拷贝,rsync可以做到增量拷贝,rsync的效率比scp更高一些
1. 通过scp直接拷贝
scp(secure copy)安全拷贝
可以通过scp进行不同服务器之间的文件或者文件夹的复制
使用语法
scp -r sourceFile username@host:destpath
用法示例
scp -r hadoop-lzo-0.4.20.jar hadoop@node01:/kkb/
node01执行以下命令进行拷贝
cd /kkb/install/
scp -r hadoop-3.1.4/ node02:$PWD
scp -r hadoop-3.1.4/ node03:$PWD
2. 通过rsync来实现增量拷贝
rsync 远程同步工具
rsync主要用于备份和镜像。具有速度快、避免复制相同内容和支持符号链接的优点。
rsync和scp区别:用rsync做文件的复制要比scp的速度快,rsync只对差异文件做更新。scp是把所有文件都复制过去。
三台机器执行以下命令安装rsync工具
sudo yum -y install rsync
(1) 基本语法
node01执行以下命令同步zk安装包
rsync -av /kkb/soft/apache-zookeeper-3.6.2-bin.tar.gz node02:/kkb/soft/
命令 选项参数 要拷贝的文件路径/名称 目的用户@主机:目的路径/名称
选项参数说明
| 选项 | 功能 |
|---|---|
| -a | 归档拷贝 |
| -v | 显示复制过程 |
(2)案例实操
(3)把node01机器上的/kkb/soft目录同步到node02服务器的hadooop用户下的/kkb/目录
rsync -av /kkb/soft node02:/kkb/soft
3. 通过rsync来封装分发脚本
我们可以通过rsync这个命令工具来实现脚本的分发,可以增量的将文件分发到我们所有其他的机器上面去
(1)需求:循环复制文件到所有节点的相同目录下
(2)需求分析:
(a)rsync命令原始拷贝:
rsync -av /kkb/soft hadoop@node02:/kkb/soft
(b)期望脚本使用方式:
xsync要同步的文件名称
(c)说明:在/home/hadoop/bin这个目录下存放的脚本,hadoop用户可以在系统任何地方直接执行。
(3)脚本实现
(a)在/home/hadoop目录下创建bin目录,并在bin目录下xsync创建文件,文件内容如下:
[hadoop@node01 ~]$ cd ~
[hadoop@node01 ~]$ mkdir bin
[hadoop@node01 bin]$ cd /home/hadoop/bin
[hadoop@node01 ~]$ touch xsync
[hadoop@node01 ~]$ vim xsync
在该文件中编写如下代码
#!/bin/bash
#1 获取输入参数个数,如果没有参数,直接退出
pcount=$#
if ((pcount==0)); then
echo no args;
exit;
fi
#2 获取文件名称
p1=$1
fname=`basename $p1`
echo $fname
#3 获取上级目录到绝对路径
pdir=`cd -P $(dirname $p1); pwd`
echo $pdir
#4 获取当前用户名称
user=`whoami`
#5 循环
for((host=1; host<4; host++)); do
echo ------------------- node0$host --------------
rsync -av $pdir/$fname $user@node0$host:$pdir
done
(b)修改脚本 xsync 具有执行权限
[hadoop@node01 bin]$ cd ~/bin/[hadoop@node01 bin]$ chmod 777 xsync
(c)调用脚本形式:xsync 文件名称
[hadoop@node01 bin]$ xsync /home/hadoop/bin/
注意:如果将xsync放到/home/hadoop/bin目录下仍然不能实现全局使用,可以将xsync移动到/usr/local/bin目录下
第六步:配置hadoop的环境变量
三台机器都要进行配置hadoop的环境变量
三台机器执行以下命令
sudo vim /etc/profile
export HADOOP_HOME=/kkb/install/hadoop-3.1.4
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
配置完成之后生效
source /etc/profile
第七步:格式化集群
-
要启动 Hadoop 集群,需要启动 HDFS 和 YARN 两个集群。
-
注意:首次启动HDFS时,必须对其进行格式化操作。本质上是一些清理和准备工作,因为此时的 HDFS 在物理上还是不存在的。格式化操作只有在首次启动的时候需要,以后再也不需要了
-
node01执行一遍即可
hdfs namenode -format
- 或者
hadoop namenode –format
- 下图高亮表示格式化成功;
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4pcqb4hg-1621041358677)(assets/image-20201019211525368.png)]
第八步:集群启动
-
启动集群有两种方式:
-
①脚本一键启动;
-
②单个进程逐个启动
1. 启动HDFS、YARN、Historyserver
-
如果配置了 etc/hadoop/workers 和 ssh 免密登录,则可以使用程序脚本启动所有Hadoop 两个集群的相关进程,在主节点所设定的机器上执行。
-
启动集群
-
主节点node01节点上执行以下命令
start-dfs.sh
start-yarn.sh
# 已过时mr-jobhistory-daemon.sh start historyserver
mapred --daemon start historyserver
- 停止集群(主节点node01节点上执行):
stop-dfs.sh
stop-yarn.sh
# 已过时 mr-jobhistory-daemon.sh stop historyserver
mapred --daemon stop historyserver
2. 单个进程逐个启动
# 在主节点上使用以下命令启动 HDFS NameNode:
# 已过时 hadoop-daemon.sh start namenode
hdfs --daemon start namenode
# 在主节点上使用以下命令启动 HDFS SecondaryNamenode:
# 已过时 hadoop-daemon.sh start secondarynamenode
hdfs --daemon start secondarynamenode
# 在每个从节点上使用以下命令启动 HDFS DataNode:
# 已过时 hadoop-daemon.sh start datanode
hdfs --daemon start datanode
# 在主节点上使用以下命令启动 YARN ResourceManager:
# 已过时 yarn-daemon.sh start resourcemanager
yarn --daemon start resourcemanager
# 在每个从节点上使用以下命令启动 YARN nodemanager:
# 已过时 yarn-daemon.sh start nodemanager
yarn --daemon start nodemanager
以上脚本位于$HADOOP_HOME/sbin/目录下。如果想要停止某个节点上某个角色,只需要把命令中的start 改为stop 即可。
3. 一键启动hadoop集群的脚本
- 为了便于一键启动hadoop集群,我们可以编写shell脚本
- 在node01服务器的/home/hadoop/bin目录下创建脚本
[hadoop@node01 bin]$ cd /home/hadoop/bin/
[hadoop@node01 bin]$ vim hadoop.sh
- 内容如下
#!/bin/bash
case $1 in
"start" ){
source /etc/profile;
/kkb/install/hadoop-3.1.4/sbin/start-dfs.sh
/kkb/install/hadoop-3.1.4/sbin/start-yarn.sh
/kkb/install/hadoop-3.1.4/sbin/mr-jobhistory-daemon.sh start historyserver
};;
"stop"){
/kkb/install/hadoop-3.1.4/sbin/stop-dfs.sh
/kkb/install/hadoop-3.1.4/sbin/stop-yarn.sh
/kkb/install/hadoop-3.1.4/sbin/mr-jobhistory-daemon.sh stop historyserver
};;
esac
- 修改脚本权限
[hadoop@node01 bin]$ chmod 777 hadoop.sh
[hadoop@node01 bin]$ ./hadoop.sh start # 启动hadoop集群
[hadoop@node01 bin]$ ./hadoop.sh stop # 停止hadoop集群
第九步:验证集群是否搭建成功
1. 访问web ui界面
- hdfs集群访问地址
http://192.168.51.100:9870/
- yarn集群访问地址
http://192.168.51.100:8088
- jobhistory访问地址:
http://192.168.51.100:19888
- 若将linux的
/etc/hosts文件的如下内容,添加到本机的hosts文件中(ip地址根据自己的实际情况进行修改)
192.168.51.100 node01.kaikeba.com node01
192.168.51.110 node02.kaikeba.com node02
192.168.51.120 node03.kaikeba.com node03
-
windows的hosts文件路径是
C:\Windows\System32\drivers\etc\hosts -
mac的hosts文件是
/etc/hosts -
那么,上边的web ui界面访问地址可以分别写程
-
hdfs集群访问地址
http://node01:9870/ -
yarn集群访问地址
http://node01:8088 -
jobhistory访问地址:
http://node01:19888
2. 所有机器查看进程脚本
- 我们也可以通过jps在每台机器上面查看进程名称,为了方便我们以后查看进程,我们可以通过脚本一键查看所有机器的进程
- 在node01服务器的/home/hadoop/bin目录下创建文件xcall
[hadoop@node01 bin]$ cd ~/bin/
[hadoop@node01 bin]$ vim xcall
- 添加以下内容
#!/bin/bash
params=$@
for (( i=1 ; i <= 3 ; i = $i + 1 )) ; do
echo ============= node0$i $params =============
ssh node0$i "source /etc/profile;$params"
done
- 然后一键查看进程并分发该脚本
chmod 777 /home/hadoop/bin/xcall
xsync /home/hadoop/bin/
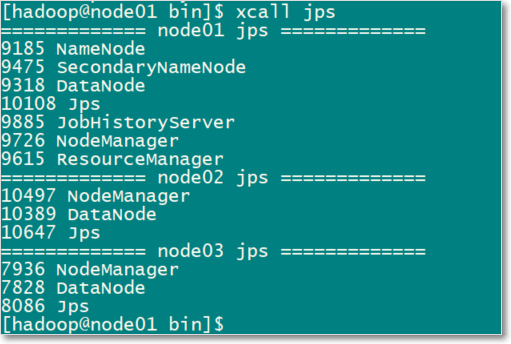
- 各节点应该启动的hadoop进程如下图
xcall jps
3. 运行一个mr例子
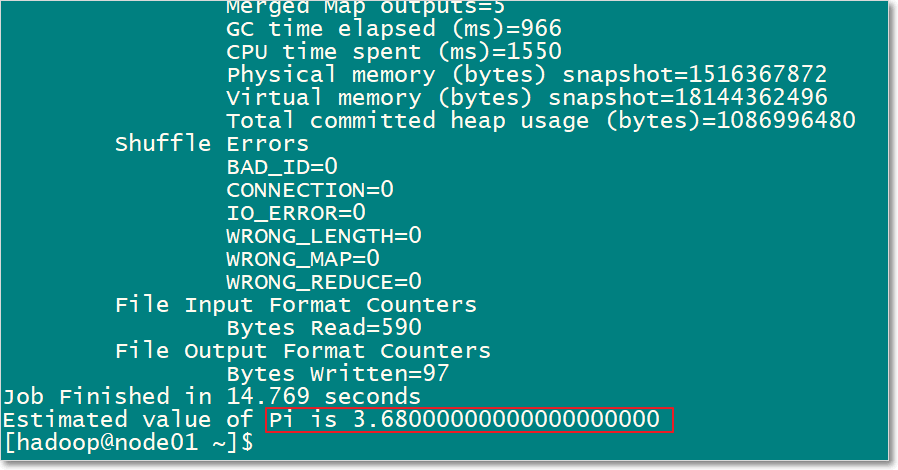
- 任一节点运行pi例子
[hadoop@node01 ~]$ hadoop jar /kkb/install/hadoop-3.1.4/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.4.jar pi 5 5
- 最后计算出pi的近似值
提醒:如果要关闭电脑时,清一定要按照以下顺序操作,否则集群可能会出问题
-
关闭hadoop集群
-
关闭虚拟机
-
关闭电脑
四、MapReduce编程实验:单词计数统计实现
- 需求:现有数据格式如下,每一行数据之间都是使用逗号进行分割,求取每个单词出现的次数
hello,hello
world,world
hadoop,hadoop
hello,world
hello,flume
hadoop,hive
hive,kafka
flume,storm
hive,oozie
第一步:创建maven工程并导入以下jar包
<properties>
<hadoop.version>3.1.4</hadoop.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>${hadoop.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/junit/junit -->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.11</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.testng</groupId>
<artifactId>testng</artifactId>
<version>RELEASE</version>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.0</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<encoding>UTF-8</encoding>
<!-- <verbal>true</verbal>-->
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.4.3</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<minimizeJar>true</minimizeJar>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
第二步:定义mapper类
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* 自定义mapper类需要继承Mapper,有四个泛型,
* keyin: k1 行偏移量 Long
* valuein: v1 一行文本内容 String
* keyout: k2 每一个单词 String
* valueout : v2 1 int
* 在hadoop当中没有沿用Java的一些基本类型,使用自己封装了一套基本类型
* long ==>LongWritable
* String ==> Text
* int ==> IntWritable
*/
public class MyMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
IntWritable intWritable = new IntWritable(1);
Text text = new Text();
/**
* 继承mapper之后,覆写map方法,每次读取一行数据,都会来调用一下map方法
*
* @param key:对应k1
* @param value:对应v1
* @param context 上下文对象。承上启下,承接上面步骤发过来的数据,通过context将数据发送到下面的步骤里面去
* @throws IOException
* @throws InterruptedException k1 v1
* 0 hello,world
* <p>
* k2 v2
* hello 1
* world 1
*/
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//获取我们的一行数据
String line = value.toString();
String[] split = line.split(",");
for (String word : split) {
//将每个单词出现都记做1次
//key2 Text类型
//v2 IntWritable类型
text.set(word);
//将我们的key2 v2写出去到下游
context.write(text, intWritable);
}
}
}
第三步:定义reducer类
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class MyReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
//第三步:分区 相同key的数据发送到同一个reduce里面去,相同key合并,value形成一个集合
/**
* (hadoop,1)
* (hive,1)
* (hadoop,1)
* (hive,1)
* (hadoop,1)
* (hive,1)
* (hadoop,1)
* -> hadoop, Iterable<IntWritable>(1,1,1,1) =>调用一次reduce()
* -> hive, Iterable<IntWritable>(1,1,1) =>调用一次reduce()
* 继承Reducer类之后,覆写reduce方法
*
* @param key
* @param values
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int result = 0;
for (IntWritable value : values) {
//将我们的结果进行累加
result += value.get();
}
//继续输出我们的数据
IntWritable intWritable = new IntWritable(result);
//将我们的数据输出
context.write(key, intWritable);
}
}
第四步:组装main程序
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
/**
* 这个类作为mr程序的入口类,这里面写main方法
*/
public class WordCount extends Configured implements Tool {
/**
* 实现Tool接口之后,需要实现一个run方法,
* 这个run方法用于组装我们的程序的逻辑,其实就是组装八个步骤
*
* @param args
* @return
* @throws Exception
*/
@Override
public int run(String[] args) throws Exception {
/***
* 第一步:读取文件,解析成key,value对,k1 v1
* 第二步:自定义map逻辑,接受k1 v1 转换成为新的k2 v2输出
* 第三步:分区。相同key的数据发送到同一个reduce里面去,key合并,value形成一个集合
* 第四步:排序 对key2进行排序。字典顺序排序
* 第五步:规约 combiner过程 调优步骤 可选
* 第六步:分组
* 第七步:自定义reduce逻辑接受k2 v2 转换成为新的k3 v3输出
* 第八步:输出k3 v3 进行保存
*/
//获取Job对象,组装我们的八个步骤,每一个步骤都是一个class类
Configuration conf = super.getConf();
Job job = Job.getInstance(conf, WordCount.class.getSimpleName());
//判断输出路径,是否存在,如果存在,则删除
FileSystem fileSystem = FileSystem.get(conf);
if (fileSystem.exists(new Path(args[1]))) {
fileSystem.delete(new Path(args[1]), true);
}
//实际工作当中,程序运行完成之后一般都是打包到集群上面去运行,打成一个jar包
//如果要打包到集群上面去运行,必须添加以下设置
job.setJarByClass(WordCount.class);
//第一步:读取文件,解析成key,value对,k1:行偏移量 v1:一行文本内容
job.setInputFormatClass(TextInputFormat.class);
//指定我们去哪一个路径读取文件
// TextInputFormat.addInputPath(job,new Path("file:///C:\\Users\\admin\\Desktop\\高级06\\Hadoop\\MapReduce&YARN\\MR第一次\\1、wordCount_input\\数据"));
TextInputFormat.addInputPath(job, new Path(args[0]));
//第二步:自定义map逻辑,接受k1 v1 转换成为新的k2 v2输出
job.setMapperClass(MyMapper.class);
//设置map阶段输出的key,value的类型,其实就是k2 v2的类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//第三步到六步:分区,排序,规约,分组都省略
//第七步:自定义reduce逻辑
job.setReducerClass(MyReducer.class);
//设置key3 value3的类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//第八步:输出k3 v3 进行保存
job.setOutputFormatClass(TextOutputFormat.class);
//一定要注意,输出路径是需要不存在的,如果存在就报错
// TextOutputFormat.setOutputPath(job,new Path("C:\\Users\\admin\\Desktop\\高级06\\Hadoop\\MapReduce&YARN\\MR第一次\\wordCount_output"));
TextOutputFormat.setOutputPath(job, new Path(args[1]));
job.setNumReduceTasks(3);
//提交job任务
boolean b = job.waitForCompletion(true);
return b ? 0 : 1;
}
/*
作为程序的入口类
*/
public static void main(String[] args) throws Exception {
Configuration configuration = new Configuration();
//提交run方法之后,得到一个程序的退出状态码
int run = ToolRunner.run(configuration, new WordCount(), args);
//根据我们 程序的退出状态码,退出整个进程
System.exit(run);
}
}
- 本地运行
- 集群运行
运行结果展示

表示运行成功~
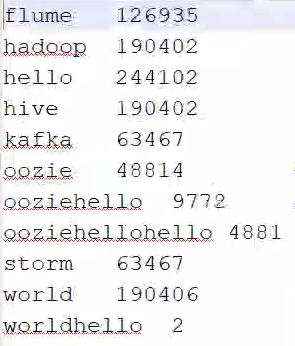
具体结果如上。
五、心得体会
综上,Hadoop部署才算真正完毕。细心的读者会发现,其实上面根本未涉及任何打通SSH操作,应当明白打通SSH只是为了sbin/start-x.sh相关脚本使用,并不是Hadoop需要的,Hadoop依赖的只是Oracle版JDK。
从开始知道需要安装Hadoop到现在Hadoop安装成功并可以使用,前前后后花费了好长时间,但是从中也吸取了很多教训:
1.不要永远照抄别人的教程。
这一点是近几天发现的,比如在所有的网上的教程,基本都是会指导你去安装一个Windows与Linux之间文件传输的工具起初我也是按照网上的教程,MobaXterm,这个软件就是那个传输工具,又在这个软件使用上花费了很大功夫,但是更具自己的理解,Linux也是一个系统既然是一个成熟的系统,那么它就肯定也会具备window绝大部分的功能,很快我就发现了,可以在Linux系统上直接去官网下载相应的jdk和Hadoop。
2.更具自己的理解去配置jdk和Hadoop
为什么这样说呢,以前在配置window上上的jdk时,网上的教程也是千奇百怪,作为一个新手去配置,总会显得好多东西很难理解,而对于Linux又是一个完全不一样的环境,在这个新的系统,就有新的系统的规则,而Linux的规则就是忘了所有的界面,就比如一个新建文件夹,在Windows中右击新建很轻松,而在Linux系统上mkdir 文件名,这并不是Linux不好,二十Linux有它自己的规则,说到这里。就很清楚了,我们需要知道Linux的规则,而规则很容易就可以从网络上获取,为什么要配置环境变量?不就是希望系统可以找到你的jdk和Hadoop吗。到这里,我们就懂了如何去操作了。
通过上述单机部署和集群部署,可以看出,Hadoop本身部署起来很简单,其大量工作其实都是前期的Linux环境配置,Hadoop安装只是解压、修改配置文件、格式化、启动和验证,关于Linux命令问题,可以参考Linux专业书籍,加以练习即可。
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











