










初学数据分析,这次就来分析一下电影信息。豆瓣电影的实战项目网上文章也不少,不过还是要自己操作一下才能理解得更深刻一点,也顺便了解一下这些电影的特点。
项目涉及的是一个特殊的电影排行榜,能上榜的想必都是非常受欢迎的电影,毕竟豆瓣上的评分还有热度都是很有参考性的。所以在这里对这个排行榜的排列标准探索一下,当然也只是粗略地分析。
豆瓣用户每天都在对“看过”的电影进行“很差”到“力荐”的评价,豆瓣根据每部影片看过的人数以及该影片所得的评价等综合数据,通过算法分析产生豆瓣电影 Top 250。
数据提取
首先分析一下网页信息,排行榜地址:https://movie.douban.com/top250。
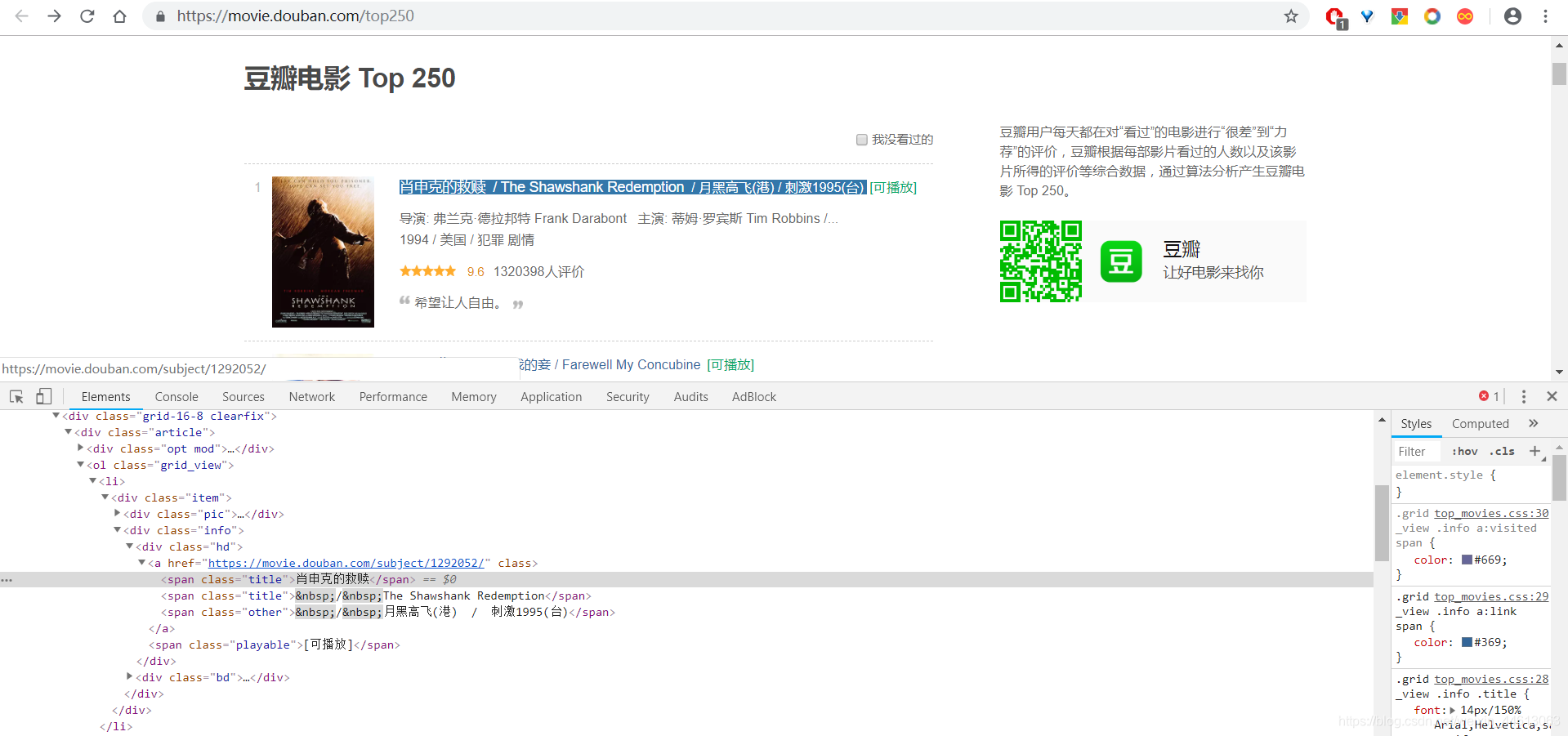
先看一下页面源代码内容,需要提取的信息都可以很快地找到。提取内容:排名、电影名、上映年份、制片国家/地区、类型、导演、评论人数、评分。
定位信息
我是采用 requests 库发送请求来获取网页,然后用 BeautifulSoup 库分析页面来获取信息。
获取请求没什么限制,甚至不需要加headers头信息,只需要把链接确认好:url = ‘https://movie.douban.com/top250?start={}&filter=’,start后面是25的倍数。分析页面就有一点麻烦,难在导演、演员和年份处在同一个 <p> 标签内,而且分离这些信息的时候无法用同一个标准,因为有些电影并没有完全给出信息,所以花了些时间在这个上面。
每个页面所有电影列表是放在一个 class=‘grid_view’ 的 <ol> 标签中的,这个标签下的每一个 <li> 标签就是每一部电影信息的Item。我采用的是BeautifulSoup库中的 css 选择方法,每个页面只有一个 <ol> 标签:
for list in range(10):
movie_content = requests.get(movie_url.format(list * 25)).text
soup = BeautifulSoup(movie_content, 'lxml')
for li in soup.select('ol li'):
movie_num = li.select('em')[0].string
movie_name = li.select('.title')[0].string
movie_info = li.select('.bd .')[0].get_text().lstrip().rstrip().split('\xa0/\xa0')
movie_year = movie_info[0].split()[-1]
movie_country = movie_info[1]
movie_type = movie_info[2]
movie_director = movie_info[0].split()[1]
movie_assess = li.select('.star span')[-1].string[:-3]
movie_score = li.select('.star span')[1].string
writer.writerow([
movie_num, movie_name, movie_year, movie_country, movie_type,
movie_director, movie_assess, movie_score
])
只需要采用 select() 方法就可以一步步提取,只不过要注意好结果是Beautiful对象还是列表、字符串。这也是上面代码中不断出现 [ ]、string 和 [ : ] 的原因。
最后会把所有信息都存入一个 csv文件,也是为了后面数据提取得更方便。要注意的是,如果在Windows上面直接打开这个csv文件会出现乱码,因为我采用的是 UTF-8 编码,想要生成可以正常显示的信息可以在 open() 中把编码改成 gb18030。
数据分析
数据导入
import pandas as pd
df = pd.read_csv('movies.csv', encoding='utf-8')
print(df.head())
为了看清楚,这里用表格展示出来:
| 0 | 名称 | 年份 | 国家 | 类型 | 导演 | 评价人数 | 评分 | |
|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 肖申克的救赎 | 1994 | 美国 | 犯罪 剧情 | 弗兰克·德拉邦特 | 1322431 | 9.6 |
| 1 | 2 | 霸王别姬 | 1993 | 中国大陆 香港 | 剧情 爱情 同性 | 陈凯歌 | 976564 | 9.6 |
| 2 | 3 | 这个杀手不太冷 | 1994 | 法国 | 剧情 动作 犯罪 | 吕克·贝松 | 1211147 | 9.4 |
| 3 | 4 | 阿甘正传 | 1994 | 美国 | 剧情 爱情 | 罗伯特·泽米吉斯 | 1041896 | 9.4 |
| 4 | 5 | 美丽人生 | 1997 | 意大利 | 剧情 喜剧 爱情 战争 | 罗伯托·贝尼尼 | 609459 | 9.5 |
重复值检查
print(df.duplicated().value_counts())
得到:
False 250
dtype: int64
检查是否有重名电影:
print(len(df.名称.unique()))
得到:
250
分析同一上映年份的电影数量
print(df["年份"].value_counts().head())
这里以表格形式展示:
| Name: 年份 | dtype: int64 |
|---|---|
| 2010 | 14 |
| 2004 | 12 |
| 1994 | 11 |
| 2011 | 10 |
| 2013 | 10 |
分析制片国家
有些电影由多个国家或地区联合制作的
area_split = df['国家'].str.split(' ').apply(pd.Series)
print(area_split.head())
这里以表格形式展示:
| 0 | 1 | 2 | 3 | 4 | 5 | |
|---|---|---|---|---|---|---|
| 0 | 美国 | NaN | NaN | NaN | NaN | NaN |
| 1 | 中国大陆 | 香港 | NaN | NaN | NaN | NaN |
| 2 | 法国 | NaN | NaN | NaN | NaN | NaN |
| 3 | 美国 | NaN | NaN | NaN | NaN | NaN |
| 4 | 意大利 | NaN | NaN | NaN | NaN | NaN |
可以看到,有些电影甚至有6个国家或地区参与制作,对于这么多的空值,可以通过先按列计数,将空值 NaN 替换为 ‘0’,再按行汇总。
all_country = area_split.apply(pd.value_counts).fillna('0')
所有的 NaN 都会替换成 ‘0’,以便于后面的统计,接下来计算每个国家参与制作电影总数排名情况:
all_country.columns = ['area1', 'area2', 'area3', 'area4', 'area5', 'area6']
all_country['area1'] = all_country['area1'].astype(int)
all_country['area2'] = all_country['area2'].astype(int)
all_country['area3'] = all_country['area3'].astype(int)
all_country['area4'] = all_country['area4'].astype(int)
all_country['area5'] = all_country['area5'].astype(int)
all_country['area6'] = all_country['area6'].astype(int)
all_country['all_counts'] = all_country['area1'] + all_country['area2']\
+ all_country['area3'] + all_country['area4']\
+ all_country['area5'] + all_country['area6']
all_country.sort_values(['all_counts'], inplace = True, ascending=False) # 降序
print(all_country.head())
得到一个国家或地区参与制作电影数的排名总情况,这里以表格形式展示:
| area1 | area2 | area3 | area4 | area5 | area6 | all_counts | |
|---|---|---|---|---|---|---|---|
| 美国 | 122 | 14 | 2 | 5 | 1 | 0 | 144 |
| 日本 | 32 | 2 | 0 | 0 | 0 | 0 | 34 |
| 英国 | 15 | 15 | 4 | 0 | 0 | 0 | 34 |
| 香港 | 19 | 6 | 0 | 0 | 0 | 0 | 25 |
| 法国 | 9 | 9 | 2 | 1 | 0 | 0 | 21 |
顺便根据最后的总数据画出直方图:
import matplotlib
import matplotlib.pyplot as plt
matplotlib.rcParams['font.family'] = 'SimHei' #配置中文字体
matplotlib.rcParams['font.size'] = 15 # 更改默认字体大小
country = pd.DataFrame({'国家':all_country['all_counts']})
country.sort_values(by='国家', ascending=False).plot(kind='bar', figsize=(10,7))
plt.show()
得到:
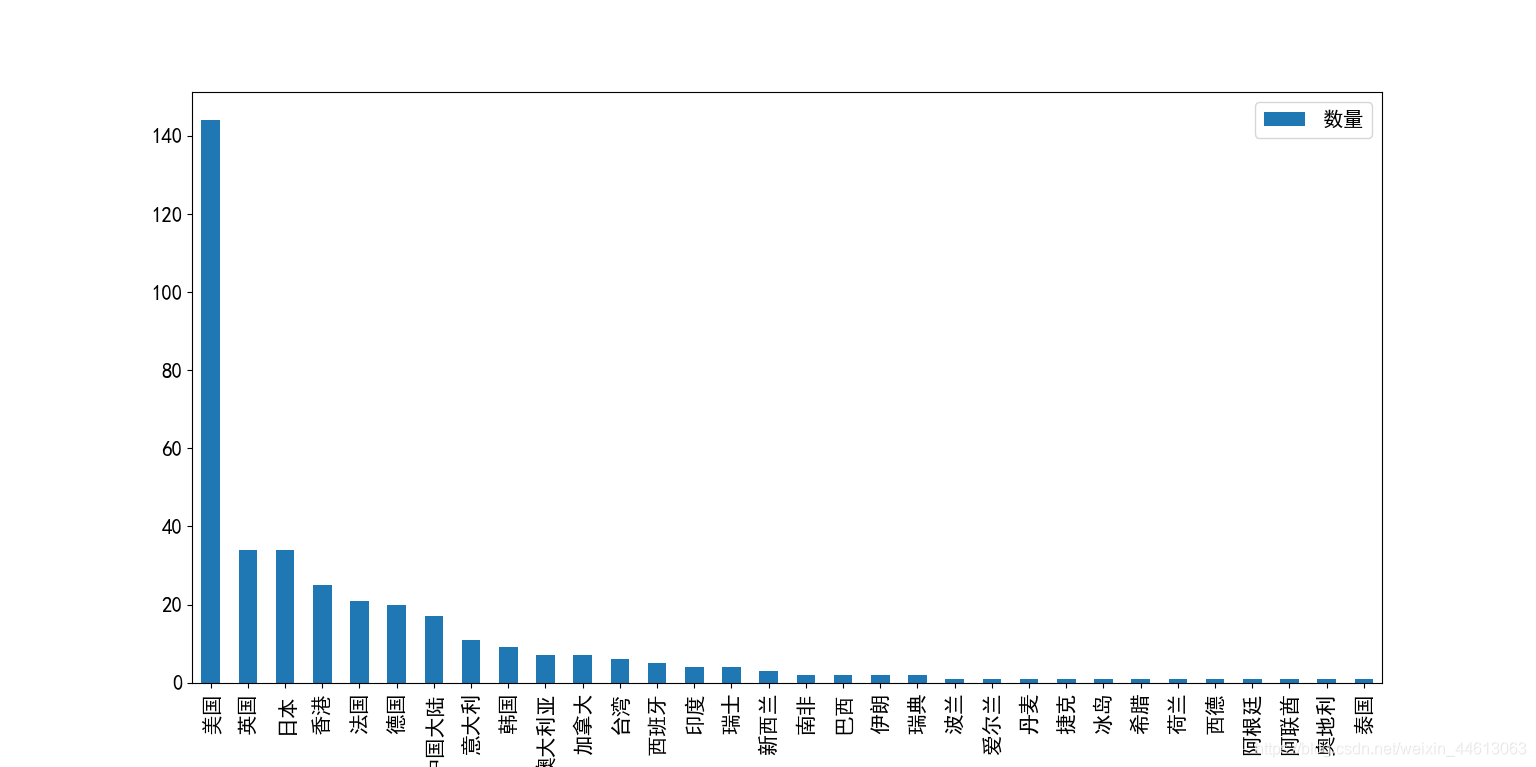
可以看到排行榜中,美国参与制作的电影数量最多,而中国大陆排第七。
分析电影类型
all_type = df['类型'].str.split(' ').apply(pd.Series)
all_type = all_type.apply(pd.value_counts).fillna('0')
all_type.columns = ['tpye1', 'type2', 'type3', 'type4', 'type5']
all_type['tpye1'] = all_type['tpye1'].astype(int)
all_type['type2'] = all_type['type2'].astype(int)
all_type['type3'] = all_type['type3'].astype(int)
all_type['type4'] = all_type['type4'].astype(int)
all_type['type5'] = all_type['type5'].astype(int)
all_type['all_counts'] = all_type['tpye1'] + all_type['type2']\
+ all_type['type3'] + all_type['type4']\
+ all_type['type5']
all_type = all_type.sort_values(['all_counts'],ascending=False)
print(all_type.head())
统计每个类型在这些电影中出现的次数,这里以表格形式展示:
| tpye1 | type2 | type3 | type4 | type5 | all_counts | |
|---|---|---|---|---|---|---|
| 剧情 | 164 | 22 | 5 | 0 | 0 | 191 |
| 爱情 | 2 | 37 | 18 | 0 | 0 | 57 |
| 冒险 | 6 | 5 | 20 | 14 | 2 | 47 |
| 喜剧 | 24 | 23 | 0 | 0 | 0 | 47 |
| 犯罪 | 12 | 23 | 6 | 3 | 0 | 44 |
顺便根据最后的总数据画出直方图:
movie_type = pd.DataFrame({'数量':all_type['all_counts']})
movie_type.sort_values(by='数量', ascending = False).plot(kind ='bar', figsize = (10,6))
plt.show()
得到:
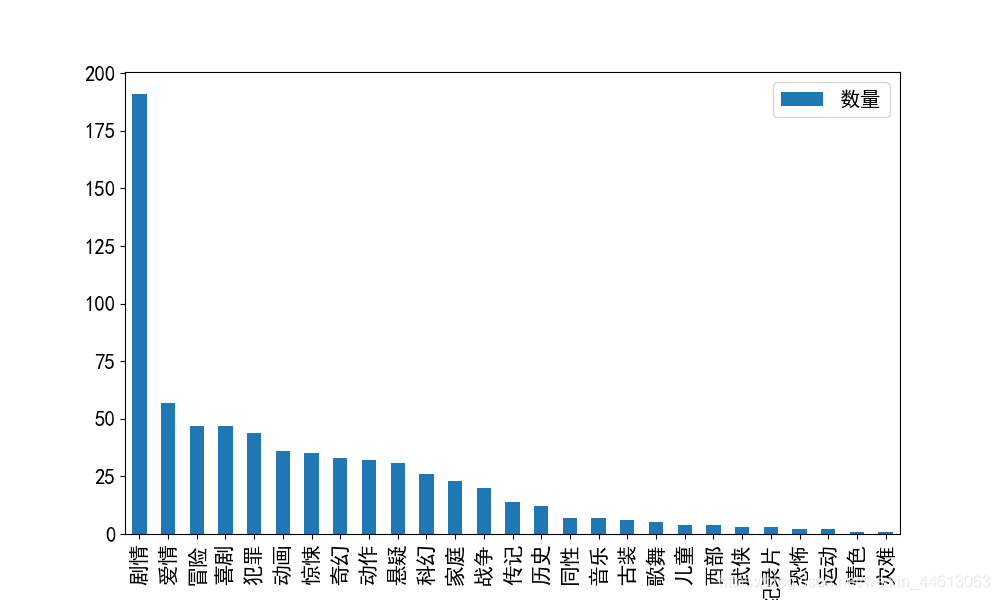
统计上榜次数最多的导演
director = df['导演'].value_counts()
print(director.head())
这里以表格形式展示:
| Name: 导演 | dtype: int64 |
|---|---|
| 克里斯托弗·诺兰 | 7 |
| 宫崎骏 | 7 |
| 史蒂文·斯皮尔伯格 | 5 |
| 王家卫 | 5 |
| 李安 | 4 |
可以见识一下大导演的风采,以后看他们拍的电影想必不会失望的。
评分与排名的关系
既然想探索一下排名究竟与各项指标有什么联系,就要分别与排名比较一下,当然这里只是举几个例子,更多的比较方法可以自己探索一下。先看一下评分:
# 评分和排名的关系散点图
plt.figure(figsize=(14,6))
plt.subplot(1,2,1)
plt.scatter(df['评分'], df['0'])
plt.xlabel('评分')
plt.ylabel('排名')
plt.gca().invert_yaxis() #修改y轴为倒序
# 评分数量直方图
plt.subplot(1,2,2)
plt.hist(df['评分'], bins=14)
plt.xlabel('评分')
plt.ylabel('出现次数')
plt.show()
结果:

评论人数与排名的关系
# 评价人数与排名的关系散点图
plt.figure(figsize=(14,6))
plt.subplot(1,2,1)
plt.scatter(df['评价人数'], df['0'])
plt.xlabel('评价人数')
plt.ylabel('排名')
plt.gca().invert_yaxis()
# 评价人数直方图
plt.subplot(1,2,2)
plt.hist(df['评价人数'], bins=14)
plt.xlabel('评价人数')
plt.ylabel('出现次数')
plt.show()
结果:
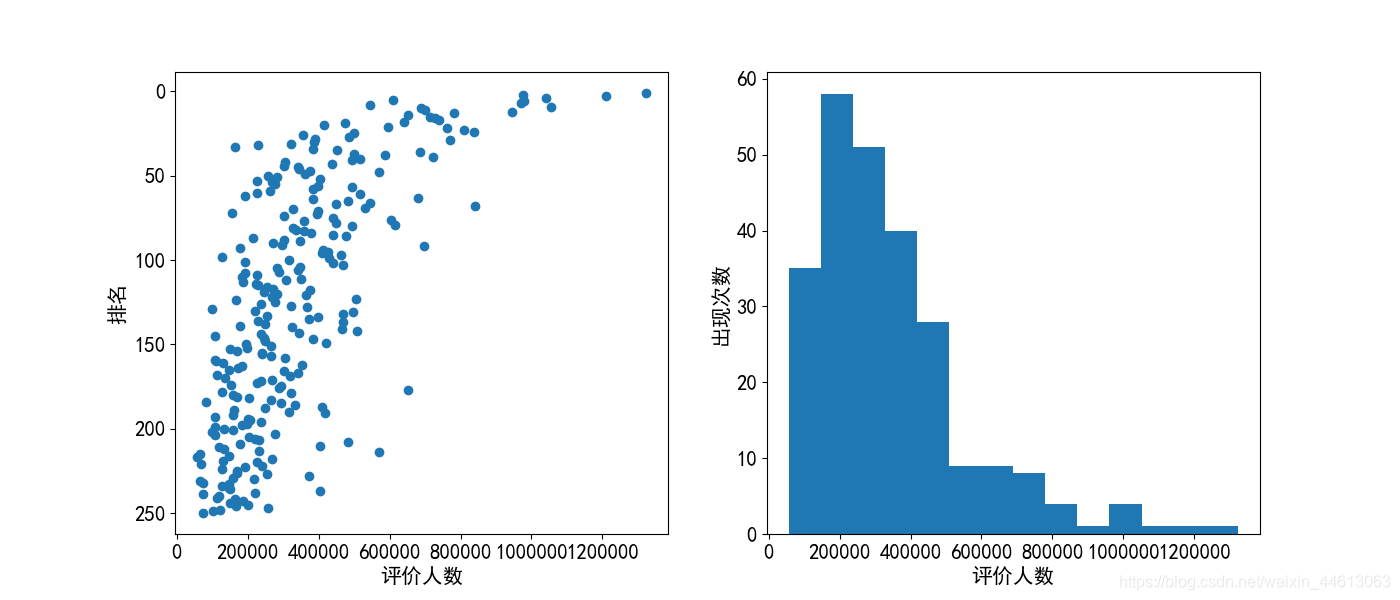
只做了一下初步分析,感兴趣的可以再深入探索。
代码的Github地址:https://github.com/Stevengz/Douban_movies_top250


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









