







详见官方文档:InfluxDB OSS 1.8 Documentation
目录
2.1.2、field(字段) & field key(字段键) & field value(字段值) & field set(字段集)
2.1.3、tag(标签) & tag key(标签键) & tag value(标签值) & tag set(标签集)
2.1.5、retention policy(RP,保留策略)
2.5.2、新的 InfluxDB 存储引擎:从 LSM Tree 到 B+Tree 再返回创建 Time Structured Merge Tree
2.6、Time Series Index(TSI,时间序列指数)
3.7、将InfluxDB OSS实例迁移到InfluxDB Enterprise集群
3.7.1、将OSS实例迁移到InfluxDB Enterprise
1、InfluxDB 1.8文档
InfluxDB是一个时间序列数据库,只在处理高写入查询负载。它是 TICK 堆栈的一个组成部分。 InfluxDB 旨在用作任何涉及大量时间戳数据的用例的后备存储,包括 DevOps 监控、应用程序指标、物联网传感器数据和实时分析。
1.1、主要特征
以下是 InfluxDB 当前支持的一些特性,使其成为处理时间序列数据的绝佳选择:
- 专门为时间序列数据编写的自定义高性能数据存储。 TSM 引擎允许高速摄取和数据压缩;
- 完全用 Go 编写。它编译成没有外部依赖的单个二进制文件;
- 简单、高性能的写入和查询 HTTP API;
- 插件支持其他数据摄取协议,例如 Graphite、collectd 和 OpenTSDB;
- 专为轻松查询聚合数据而设计的富有表现力的类似 SQL 的查询语言;
- 标签(Tag)允许对系列(Series)进行索引,以实现快速高效的查询;
- 保留策略有效地自动使陈旧数据过期;
- 连续查询自动计算聚合数据,使频繁查询更高效。
InfluxDB 的开源版本在单个节点上运行。如果您需要高可用性来消除单点故障,请考虑使用 InfluxDB 企业版。
1.2、下载InfluxDB OSS
在 InfluxData 下载页面下载最新的 InfluxDB 开源 (OSS) 版本。
Get InfluxDB | #1 Ranked Time Series Database | InfluxData
2、InfluxDB概念
2.1、InfluxDB关键概念
在深入研究 InfluxDB 之前,最好熟悉数据库的一些关键概念。本文档介绍了关键的 InfluxDB 概念和元素。
下一节将参考下面打印出来的数据。这些数据是虚构的,但代表了 InfluxDB 中的可信设置。它们显示了从 2015 年 8 月 18 日午夜到 2015 年 8 月 18 日上午 6:12 的时间段内,两位科学家(langstroth 和 perpetua)在两个地点(地点 1 和地点 2)计算的蝴蝶和蜜蜂数量。假设数据存在于名为 my_database 的数据库中,并受 autogen 保留策略的约束(更多关于数据库和保留策略的信息)。
| time时间(timestamp key) | butterflies蝴蝶(field key) | honeybees蜜蜂(field key) | location地点(tag key) | scientist科学家(tag key) |
|---|---|---|---|---|
| 2015-08-18T00:00:00Z | 12 | 23 | 1 | langstroth |
| 2015-08-18T00:00:00Z | 1 | 30 | 1 | perpetua |
| 2015-08-18T00:06:00Z | 11 | 28 | 1 | langstroth |
| 2015-08-18T00:06:00Z | 3 | 28 | 1 | perpetua |
| 2015-08-18T05:54:00Z | 2 | 11 | 2 | langstroth |
| 2015-08-18T06:00:00Z | 1 | 10 | 2 | langstroth |
| 2015-08-18T06:06:00Z | 8 | 23 | 2 | perpetua |
| 2015-08-18T06:12:00Z | 7 | 22 | 2 | perpetua |
2.1.1、database(数据库)
- 数据库:用户、保留策略、连续查询和时间序列数据的逻辑容器。
我们将要介绍的所有内容都存储在数据库中——示例数据在数据库 my_database 中。 InfluxDB 数据库类似于传统的关系数据库,用作用户、保留策略、连续查询,当然还有时间序列数据的逻辑容器。有关这些主题的更多信息,请参阅身份验证和授权以及连续查询。
数据库可以有多个用户、连续查询、保留策略和度量。 InfluxDB 是一个无模式数据库,这意味着可以随时轻松添加新的度量、标签和字段。它旨在使处理时间序列数据变得很棒。
2.1.2、timestamp(时间戳)
InfluxDB 是一个时间序列数据库,因此从我们所做的一切的根源开始是有意义的:时间戳(timestamp)。时间戳是与点关联的日期和时间。时间戳以 RFC3339 UTC 格式显示与特定数据相关联的日期和时间。
在上面的数据中有一个名为 time 的列存储时间戳 - InfluxDB 中的所有数据都有该列。
2.1.2、field(字段) & field key(字段键) & field value(字段值) & field set(字段集)
样本数据时间戳后的的两列,称为蝴蝶和蜜蜂,是字段。字段由字段键和字段值组成。
- 字段:InfluxDB 数据结构中记录元数据和实际数据值的键值对。 InfluxDB 数据结构中需要字段,并且它们没有被索引 - 对字段值的查询会扫描与指定时间范围匹配的所有点,因此相对于标签而言性能不高。
- 字段键:构成字段的键值对的键部分。字段键是字符串,它们存储元数据。
- 字段值:构成字段的键值对的值部分。字段值是实际数据;它们可以是字符串、浮点数、整数或布尔值。字段值始终与时间戳相关联。
- 字段集:一个点上的字段键和字段值的集合。
字段键(蝴蝶和蜜蜂)是字符串;字段键蝴蝶告诉我们字段值 12-7 指的是蝴蝶,字段键蜜蜂告诉我们字段值 23-22 指的是蜜蜂。字段值是您的数据;它们可以是字符串、浮点数、整数或布尔值,并且由于 InfluxDB 是一个时间序列数据库,因此字段值始终与时间戳相关联。示例数据中的字段值为:
12 23
1 30
11 28
3 28
2 11
1 10
8 23
7 22在上面的数据中,字段键(field-key)和字段值(field-value)对的集合构成了一个字段集(field set)。以下是示例数据中的所有八个字段集:
butterflies = 12 honeybees = 23蝴蝶 = 12 蜜蜂 = 23
butterflies = 1 honeybees = 30蝴蝶 = 1 蜜蜂 = 30
butterflies = 11 honeybees = 28蝴蝶 = 11 蜜蜂 = 28
butterflies = 3 honeybees = 28蝴蝶 = 3 蜜蜂 = 28
butterflies = 2 honeybees = 11蝴蝶 = 2 蜜蜂 = 11
butterflies = 1 honeybees = 10蝴蝶 = 1 蜜蜂 = 10
butterflies = 8 honeybees = 23蝴蝶 = 8 蜜蜂 = 23
butterflies = 7 honeybees = 22蝴蝶 = 7 蜜蜂 = 22字段(field)是 InfluxDB 数据结构的必需部分——您不能在没有字段的情况下在 InfluxDB 中拥有数据。同样重要的是要注意字段没有索引。使用字段值作为过滤器的查询必须扫描与查询中其他条件匹配的所有值。因此,这些查询相对于标签查询而言性能不佳(更多关于标签的内容如下)。通常,字段不应包含经常查询的元数据。
2.1.3、tag(标签) & tag key(标签键) & tag value(标签值) & tag set(标签集)
样本数据中的最后两列,称为位置和科学家,是标签(tag)。标签由标签键(tag key)和标签值(tag value)组成。
- 标签:InfluxDB 数据结构中记录元数据的键值对。标签是数据结构的一个可选部分,但它们对于存储经常查询的元数据很有用;标签被编入索引,因此对标签的查询是高效的。查询提示:将标签与字段进行比较;字段没有被索引。
- 标签键:构成标签的键值对的键部分。标签键是字符串,它们存储元数据。标记键已编入索引,因此对标记键的查询是高效的。
- 标签值:构成标签的键值对的值部分。标签值是字符串,它们存储元数据。标记值已编入索引,因此对标记值的查询是高效的。
- 标签集:一个点上的标签键和标签值的集合。
标签键和标签值都存储为字符串和记录元数据(metadata)。样本数据中的标签键是位置和科学家。标签键位置有两个标签值:1 和 2。标签键科学家也有两个标签值:langstroth 和 perpetua。
在上面的数据中,标签集(tag set)是所有标签键值对的不同组合。样本数据中的四个标签集是:
- location = 1, scientist = langstroth
位置 = 1,科学家 = langstroth
- location = 2, scientist = langstroth
位置 = 2,科学家 = langstroth
- location = 1, scientist = perpetua
位置 = 1,科学家 = perpetua
- location = 2, scientist = perpetua
位置 = 2,科学家 = perpetua标签是可选的。您不需要在数据结构中包含标签,但使用它们通常是一个好主意,因为与字段不同,标签是索引的。这意味着对标签的查询速度更快,并且标签非常适合存储经常查询的元数据。
避免使用以下保留键:_field、_measurement、time。如果保留键作为标签或字段键包含,则关联点将被丢弃。
为什么索引很重要? -> 假设您注意到大多数查询都集中在字段键 honeybees 和 butterflies 的值上,因为字段没有被索引,所以 InfluxDB 在提供响应之前会扫描第一个查询中的每个蝴蝶值和第二个查询中的每个蜜蜂值。这种行为会损害查询响应时间——尤其是在更大范围内。为了优化您的查询,重新排列您的模式可能是有益的,以便字段(蝴蝶和蜜蜂)成为标签,标签(位置和科学家)成为字段,现在蝴蝶和蜜蜂是标签,InfluxDB 在执行上述查询时不必扫描它们的每一个值 - 这意味着您的查询更快。
2.1.4、measurement(度量/测量)
- 度量/测量:InfluxDB 数据结构中描述存储在相关字段中的数据的部分。测量是字符串。
测量充当标签、字段和时间列的容器,测量名称是存储在相关字段中的数据的描述。度量名称是字符串,对于任何 SQL 用户来说,度量在概念上类似于表。样本数据中唯一的衡量指标是人口普查。 census 这个名字告诉我们,字段值记录了蝴蝶和蜜蜂的数量——而不是它们的大小、方向或某种幸福指数。
2.1.5、retention policy(RP,保留策略)
- 保留策略:描述 InfluxDB 保存数据的时间(持续时间),集群中存储数据的多少副本(复制因子),以及分片组覆盖的时间范围(分片组持续时间)。每个数据库的 RP 都是唯一的,并且与测量和标签集一起定义了一个系列。
保留策略描述了 InfluxDB 保留数据的时间 (DURATION) 以及该数据在集群中存储的副本数 (REPLICATION)。当您创建数据库时,InfluxDB 会创建一个名为 autogen 的保留策略,其持续时间为无限,复制因子设置为 1,分片组持续时间设置为 7 天。在样本数据中,人口普查测量中的所有内容都属于 autogen 保留策略。 InfluxDB 自动创建该保留策略;它具有无限的持续时间和设置为 1 的复制因子。
单个度量可以属于不同的保留策略。
2.1.6、series(系列)
- 系列:由共享度量、标签集和字段键定义的数据逻辑分组。
上述样本数据由八个系列组成:
| Series number系列号 | Measurement测量 | Tag set 标签集 | Field key 字段键 |
|---|---|---|---|
| series 1系列 1 | census人口普查 | location = 1,scientist = langstroth位置 = 1,科学家 = langstroth | butterflies蝴蝶 |
| series 2系列 2 | census人口普查 | location = 2,scientist = langstroth位置 = 2,科学家 = langstroth | butterflies蝴蝶 |
| series 3系列 3 | census人口普查 | location = 1,scientist = perpetua位置 = 1,科学家 = perpetua | butterflies蝴蝶 |
| series 4系列 4 | census人口普查 | location = 2,scientist = perpetua位置 = 2,科学家 = perpetua | butterflies蝴蝶 |
| series 5系列 5 | census人口普查 | location = 1,scientist = langstroth位置 = 1,科学家 = langstroth | honeybees蜜蜂 |
| series 6系列 6 | census人口普查 | location = 2,scientist = langstroth位置 = 2,科学家 = langstroth | honeybees蜜蜂 |
| series 7系列 7 | census人口普查 | location = 1,scientist = perpetua位置 = 1,科学家 = perpetua | honeybees蜜蜂 |
| series 8系列 8 | census人口普查 | location = 2,scientist = perpetua位置 = 2,科学家 = perpetua | honeybees蜜蜂 |
在设计架构和在 InfluxDB 中处理数据时,理解系列的概念是必不可少的。
2.1.7、point(点)
- 点:在 InfluxDB 中,一个点代表一条数据记录,类似于 SQL 数据库表中的一行。每个点:① 具有测量值、标签集、字段键、字段值和时间戳;② 由其系列和时间戳唯一标识。
您不能在一个系列中存储多个具有相同时间戳的点。如果您将一个点写入具有与现有点匹配的时间戳的系列,则该字段集将成为旧字段集和新字段集的并集,并且任何关系都将转到新字段集。
例如,这里有一个点:
name: census
-----------------
time butterflies honeybees location scientist
2015-08-18T00:00:00Z 1 30 1 perpetua此示例中的点是系列 3 和 7 的一部分,由测量(人口普查)、标签集(位置 = 1、科学家 = perpetua)、字段集(蝴蝶 = 1、蜜蜂 = 30)和时间戳定义2015-08-18T00:00:00Z。
2.2、InfluxDB其他概念
- aggregation(聚合):一个 InfluxQL 函数,它返回一组点的聚合值。有关可用和即将到来的聚合的完整列表,请参阅 InfluxQL 函数。
- batch(批):InfluxDB 行协议格式的数据点集合,由换行符 (0x0A) 分隔。可以使用对写入端点的单个 HTTP 请求将一批点提交到数据库。通过大大减少 HTTP 开销,这使得使用 InfluxDB API 的写入性能更高。 InfluxData 建议批量大小为 5,000-10,000 点,尽管不同的用例可能更适合显着更小或更大的批量。
- bucket(桶):存储桶是时间序列数据存储在 InfluxDB 2.0 中的命名位置。在 InfluxDB 1.8+ 中,数据库和保留策略 (database/retention-policy) 的每个组合代表一个存储桶。使用 InfluxDB 1.8+ 中包含的 InfluxDB 2.0 API 兼容性端点与存储桶进行交互。
- continuous query(CQ,连续查询):在数据库中自动并定期运行的 InfluxQL 查询。
- duration(持续时间):确定 InfluxDB 存储数据多长时间的保留策略的属性。早于持续时间的数据会自动从数据库中删除。
- function(函数):InfluxQL 聚合、选择器和转换。
- identifier(标识符):指连续查询名称、数据库名称、字段键、度量名称、保留策略名称、订阅名称、标签键和用户名的标记。
- InfluxDB line protocol(InfluxDB线路协议):用于将点写入 InfluxDB 的基于文本的格式。
- metastore(元存储):包含有关系统状态的内部信息。 Metastore 包含用户信息、数据库、保留策略、分片元数据、连续查询和订阅。
- node(节点):一个独立的流入过程。
- now()(now()):本地服务器的纳秒时间戳。
- points per second(每秒点数):不推荐使用的对数据持久保存到 InfluxDB 的速率的度量。该模式允许甚至鼓励记录每个点的多个度量值,从而使每秒的点数不明确。写入速度通常以每秒值引用,这是一个更精确的度量。
- query(查询):从 InfluxDB 检索数据的操作。
- replication factor(复制因子):保留策略的属性,用于确定要在集群中同时存储(或保留)多少数据副本。复制副本可确保在数据节点(或更多)不可用时数据可用。对于三个或更少的节点,默认复制因子等于数据节点的数量。对于三个以上的节点,默认复制因子为 3。要更改默认复制因子,请在保留策略中指定复制因子 n。
- schema(模式):数据在 InfluxDB 中的组织方式。 InfluxDB 模式的基础是数据库、保留策略、系列、度量、标签键、标签值和字段键。
- selector(选择器):一个 InfluxQL 函数,它从指定点的范围内返回一个点。有关可用和即将推出的选择器的完整列表,请参阅 InfluxQL 函数。
- series cardinality(系列基数):InfluxDB 实例中唯一数据库、度量、标签集和字段键组合的数量。例如,假设一个 InfluxDB 实例有一个数据库和一个度量。单次测量有两个标签键:电子邮件和状态。如果存在三封不同的电子邮件,并且每个电子邮件地址与两种不同的状态相关联,则测量的系列基数为 6 (3 * 2 = 6):
email电子邮件 status地位 lorr@influxdata.comlorr@influxdata.com start开始 lorr@influxdata.comlorr@influxdata.com finish结束 marv@influxdata.commarv@influxdata.com start开始 marv@influxdata.commarv@influxdata.com finish结束 cliff@influxdata.com悬崖@influxdata.com start开始 cliff@influxdata.com悬崖@influxdata.com finish结束 请注意,在某些情况下,由于存在相关标签,简单地执行该乘法可能会高估系列基数。从属标签是由另一个标签限定范围的标签,不会增加系列基数。如果我们将标签 firstname 添加到上面的示例中,则系列基数不会是 18 (3 * 2 * 3 = 18)。它将在 6 处保持不变,因为名字已经由电子邮件标签限定:
email电子邮件 status地位 firstname名 lorr@influxdata.comlorr@influxdata.com start开始 lorraine洛林 lorr@influxdata.comlorr@influxdata.com finish结束 lorraine洛林 marv@influxdata.commarv@influxdata.com start开始 marvin马文 marv@influxdata.commarv@influxdata.com finish结束 marvin马文 cliff@influxdata.com悬崖@influxdata.com start开始 clifford克里福德 cliff@influxdata.com悬崖@influxdata.com finish结束 clifford克里福德 - server(服务器):运行 InfluxDB 的虚拟机或物理机。每台服务器应该只有一个 InfluxDB 进程。
- shard(分片):分片包含实际的编码和压缩数据,并由磁盘上的 TSM 文件表示。每个分片都属于一个且只有一个分片组。单个分片组中可能存在多个分片。每个分片都包含一组特定的系列。落在给定分片组中给定系列上的所有点都将存储在磁盘上的同一个分片(TSM 文件)中。
- shard duration(分片持续时间):分片持续时间决定了每个分片组跨越的时间。具体时间间隔由保留策略的 SHARD DURATION 决定。有关详细信息,请参阅保留策略管理。例如,给定一个将 SHARD DURATION 设置为 1w 的保留策略,每个分片组将跨越一周,并包含该周内具有时间戳的所有点。
- shard group(分片组):分片组是分片的逻辑容器。分片组按时间和保留策略进行组织。每个包含数据的保留策略都至少有一个关联的分片组。给定的分片组包含所有分片,其中包含分片组覆盖的时间间隔的数据。每个分片组跨越的时间间隔是分片持续时间。
- subscription(订阅):订阅允许 Kapacitor 以推送模型而不是基于查询数据的拉取模型接收来自 InfluxDB 的数据。当 Kapacitor 配置为使用 InfluxDB 时,订阅将自动将订阅数据库的每次写入从 InfluxDB 推送到 Kapacitor。订阅可以使用 TCP 或 UDP 传输写入。
- transformation(转型):一个 InfluxQL 函数,它返回从指定点计算的一个值或一组值,但不返回这些点的聚合值。有关可用和即将到来的聚合的完整列表,请参阅 InfluxQL 函数。
- Time Structured Merge tree(TSM,时间结构化合并树):为 InfluxDB 专门构建的数据存储格式。与现有的 B+ 或 LSM 树实现相比,TSM 允许更大的压缩和更高的读写吞吐量。
- user(用户):启用身份验证后,InfluxDB 仅执行使用有效用户名和密码发送的 HTTP 请求。InfluxDB 中有两种用户:① 管理员用户拥有对所有数据库的读和写访问权限以及对管理查询和用户管理命令的完全访问权限;② 非管理员用户对每个数据库具有 READ、WRITE 或 ALL(READ 和 WRITE)访问权限。
- values per second(每秒值):数据持久保存到 InfluxDB 的速率的首选度量。写入速度通常以每秒值表示。要计算每秒值的速率,请将每秒写入的点数乘以每个点存储的值数。例如,如果每个点有四个字段,并且每批 5000 个点每秒写入 10 次,那么每秒值的速率为每点 4 个字段值 * 每批 5000 个点 * 每秒 10 个批 = 200,000 个值/第二。
- Write Ahead Log(WAL,预写日志):最近写入点的临时缓存。为了减少访问永久存储文件的频率,InfluxDB 在 WAL 中缓存新点,直到它们的总大小或年龄触发刷新到更永久的存储。这允许将写入有效地批处理到 TSM。可以查询 WAL 中的点,并且它们会在系统重新启动后持续存在。在进程启动时,必须在系统接受新写入之前刷新 WAL 中的所有点。
2.2、InfluxDB 和 SQL数据库 的比较
InfluxDB 类似于 SQL 数据库,但在许多方面有所不同。 InfluxDB 专为时间序列数据而构建。关系数据库可以处理时间序列数据,但没有针对常见的时间序列工作负载进行优化。 InfluxDB 旨在存储大量时间序列数据并快速对该数据执行实时分析。
2.2.1、时机就是一切
在 InfluxDB 中,时间戳标识任何给定数据系列中的单个点。这就像一个 SQL 数据库表,其中主键是系统预先设置的,并且始终是时间。InfluxDB 还认识到您的模式偏好可能会随着时间而改变。在 InfluxDB 中,您不必预先定义模式。数据点可以具有测量上的一个字段、测量上的所有字段或介于两者之间的任何数字。您只需为该新字段写入一个点即可将新字段添加到测量中。
2.2.2、术语
下表是 SQL 数据库中名为 foodships 的表的(非常)简单示例,其中未索引列 #_foodships 和索引列 park_id、planet 和 time。
+---------+---------+---------------------+--------------+
| park_id | planet | time | #_foodships |
+---------+---------+---------------------+--------------+
| 1 | Earth | 1429185600000000000 | 0 |
| 1 | Earth | 1429185601000000000 | 3 |
| 1 | Earth | 1429185602000000000 | 15 |
| 1 | Earth | 1429185603000000000 | 15 |
| 2 | Saturn | 1429185600000000000 | 5 |
| 2 | Saturn | 1429185601000000000 | 9 |
| 2 | Saturn | 1429185602000000000 | 10 |
| 2 | Saturn | 1429185603000000000 | 14 |
| 3 | Jupiter | 1429185600000000000 | 20 |
| 3 | Jupiter | 1429185601000000000 | 21 |
| 3 | Jupiter | 1429185602000000000 | 21 |
| 3 | Jupiter | 1429185603000000000 | 20 |
| 4 | Saturn | 1429185600000000000 | 5 |
| 4 | Saturn | 1429185601000000000 | 5 |
| 4 | Saturn | 1429185602000000000 | 6 |
| 4 | Saturn | 1429185603000000000 | 5 |
+---------+---------+---------------------+--------------+这些相同的数据在 InfluxDB 中如下所示:
name: foodships
tags: park_id=1, planet=Earth
time #_foodships
---- ------------
2015-04-16T12:00:00Z 0
2015-04-16T12:00:01Z 3
2015-04-16T12:00:02Z 15
2015-04-16T12:00:03Z 15
name: foodships
tags: park_id=2, planet=Saturn
time #_foodships
---- ------------
2015-04-16T12:00:00Z 5
2015-04-16T12:00:01Z 9
2015-04-16T12:00:02Z 10
2015-04-16T12:00:03Z 14
name: foodships
tags: park_id=3, planet=Jupiter
time #_foodships
---- ------------
2015-04-16T12:00:00Z 20
2015-04-16T12:00:01Z 21
2015-04-16T12:00:02Z 21
2015-04-16T12:00:03Z 20
name: foodships
tags: park_id=4, planet=Saturn
time #_foodships
---- ------------
2015-04-16T12:00:00Z 5
2015-04-16T12:00:01Z 5
2015-04-16T12:00:02Z 6
2015-04-16T12:00:03Z 5参考上面的例子,一般来说:
- InfluxDB 度量(如foodships)类似于 SQL 数据库表。
- InfluxDB 标签(如park_id 和 planet)就像 SQL 数据库中的索引列。
- InfluxDB 字段 (如#_foodships) 就像 SQL 数据库中的未索引列。
- InfluxDB 点(如 2015-04-16T12:00:00Z 5)类似于 SQL 行。
基于数据库术语的这种比较,InfluxDB 连续查询和保留策略类似于 SQL 数据库中的存储过程。它们被指定一次,然后定期自动执行。
当然,SQL 数据库和 InfluxDB 之间存在一些重大差异。 SQL JOIN 不适用于 InfluxDB 测量;您的架构设计应该反映这种差异。而且,正如我们上面提到的,测量就像一个 SQL 表,其中主索引总是预设为时间。 InfluxDB 时间戳必须在 UNIX 时代 (GMT) 中或格式化为在 RFC3339 下有效的日期时间字符串。
2.2.3、查询语言
InfluxDB 支持多种查询语言:① Flux;② InfluxQL。
1、Flux
Flux 是一种数据脚本语言,专为查询、分析和处理时间序列数据而设计。从 InfluxDB 1.8.0 开始,Flux 可与 InfluxQL 一起用于生产。
对于那些熟悉 InfluxQL 的人来说,Flux 旨在解决自引入 InfluxDB 1.0 以来我们收到的许多出色的功能请求。
Flux 是在 InfluxDB OSS 2.0 和 InfluxDB Cloud 中处理数据的主要语言,InfluxDB Cloud 是一个普遍可用的平台即服务 (PaaS),可跨多个云服务提供商使用。将 Flux 与 InfluxDB 1.8+ 一起使用可以让您熟悉 Flux 概念和语法,并轻松过渡到 InfluxDB 2.0。
2、InfluxQL
InfluxQL 是一种类似于 SQL 的查询语言,用于与 InfluxDB 进行交互。它经过精心设计,让那些来自其他 SQL 或类似 SQL 环境的人感到熟悉,同时还提供了特定于存储和分析时间序列数据的功能。然而,InfluxQL 不是 SQL,并且缺乏对 SQL 高级用户习惯的更高级操作(如 UNION、JOIN 和 HAVING)的支持。 Flux 提供了此功能。
InfluxQL 的 SELECT 语句遵循 SQL SELECT 语句的形式:
SELECT <stuff> FROM <measurement_name> WHERE <some_conditions>其中 WHERE 是可选的。要获得上述部分中的 InfluxDB 输出,您需要输入:
SELECT * FROM "foodships"如果您只想查看土星的数据,您可以输入:
SELECT * FROM "foodships" WHERE "planet" = 'Saturn'如果您想查看 2015 年 4 月 16 日 12:00:01 UTC 之后土星的数据,您可以输入:
SELECT * FROM "foodships" WHERE "planet" = 'Saturn' AND time > '2015-04-16 12:00:01'如上例所示,InfluxQL 允许您在 WHERE 子句中指定查询的时间范围。您可以使用包含在单引号中的日期时间字符串,其格式为 YYYY-MM-DD HH:MM:SS.mmm(mmm 是毫秒并且是可选的,您还可以指定微秒或纳秒)。您还可以使用 now() 的相对时间,它指的是服务器的当前时间戳:
SELECT * FROM "foodships" WHERE time > now() - 1h该查询输出 foodships 度量中的数据,其中时间戳比服务器的当前时间减去一小时新。使用 now() 指定持续时间的选项是:
| Letter信 | Meaning意义 |
|---|---|
| nsns | nanoseconds纳秒 |
| u or µu 或 µ | microseconds微秒 |
| ms小姐 | milliseconds毫秒 |
| ss | seconds秒 |
| m米 | minutes分钟 |
| hH | hours小时 |
| dd | days天 |
| ww | weeks周 |
InfluxQL 还支持正则表达式、表达式中的算术、SHOW 语句和 GROUP BY 语句。InfluxQL 函数包括 COUNT、MIN、MAX、MEDIAN、DERIVATIVE 等。
2.2.4、InfluxDB不是CRUD
InfluxDB 是一个针对时间序列数据进行了优化的数据库。这些数据通常来自分布式传感器组、大型网站的点击数据或金融交易列表等来源。这些数据的一个共同点是它在聚合中更有用。一篇文章说您的计算机的 CPU 在星期二 12:38:35 UTC 的利用率为 12%,很难从中得出结论。当与该系列的其余部分结合并可视化时,它会变得更加有用。这是随着时间的推移开始显示趋势的地方,并且可以从数据中得出可行的见解。另外,时序数据一般只写一次,很少更新。
结果是 InfluxDB 不是一个完整的 CRUD 数据库,而是更像一个 CR-ud,将创建和读取数据的性能优先于更新和销毁,并防止一些更新和销毁行为以使创建和读取性能更高:
- 要更新一个点,请插入一个具有相同测量值、标签集和时间戳的点。
- 您可以删除或删除一个系列,但不能基于字段值删除单个点。作为一种解决方法,您可以搜索字段值,检索时间,然后根据时间字段删除。
- 您还不能更新或重命名标签 - 请参阅 GitHub 问题 #4157 了解更多信息。要修改一系列点的标记,请找到具有违规标记值的点,将值更改为所需的值,将点写回,然后删除具有旧标记值的系列。
- 您不能通过标签键(而不是值)删除标签 - 请参阅 GitHub 问题 #8604。
2.3、InfluxDB设计见解和权衡
- InfluxDB 是一个时间序列数据库。针对这个用例进行优化需要一些权衡,主要是为了以功能为代价来提高性能。下面列出了一些导致权衡的设计见解:
- 对于时间序列用例,我们假设如果多次发送相同的数据,那么它就是客户端刚刚发送多次的完全相同的数据。优点:简化的冲突解决提高了写入性能。缺点:不能存储重复数据;在极少数情况下可能会覆盖数据。
- 删除很少发生。当它们确实发生时,几乎总是针对大量冷写的旧数据。优点:限制对删除的访问可以提高查询和写入性能。缺点:删除功能受到很大限制。
- 对现有数据的更新很少发生,有争议的更新永远不会发生。时间序列数据主要是从未更新的新数据。优点:限制对更新的访问可以提高查询和写入性能。缺点:更新功能受到很大限制。
- 绝大多数写入都是针对具有最近时间戳的数据,并且数据是按时间升序添加的。优点:按时间升序添加数据的性能明显更高。缺点:使用随机时间或时间不按升序写入点的性能显着降低。
- 规模至关重要。数据库必须能够处理大量的读取和写入。优点:数据库可以处理大量的读取和写入。缺点:InfluxDB 开发团队被迫做出权衡以提高性能。
- 能够写入和查询数据比拥有高度一致的视图更重要。优点:写入和查询数据库可以由多个客户端在高负载下完成。缺点:如果数据库负载过重,查询返回可能不包括最近的点。
- 许多时间序列都是短暂的。经常有时间序列只出现几个小时然后就消失了,例如启动并报告一段时间然后关闭的新主机。优点:InfluxDB 擅长管理不连续的数据。缺点:无模式设计意味着不支持某些数据库功能,例如没有交叉表连接。
- 没有一个点是太重要的。优点:InfluxDB 有非常强大的工具来处理聚合数据和大型数据集。缺点:点没有传统意义上的ID,它们是通过时间戳和序列来区分的。
2.4、InfluxDB架构设计和数据布局
每个 InfluxDB 用例都是独一无二的,您的架构反映了这种独特性。通常,为查询而设计的模式会导致更简单且性能更高的查询。
2.4.1、存储数据的位置(标签或字段)
您的查询应该指导您在标签中存储哪些数据以及在字段中存储哪些数据:
- 将常用查询和分组(group() 或 GROUP BY)元数据存储在标签中。
- 如果每个数据点包含不同的值,则将数据存储在字段中。
- 将数值存储为字段(标签值仅支持字符串值)。
2.4.2、避免过多的系列
InfluxDB 索引以下数据元素以加快读取速度:① measurement(测量);② tags(标签)。
标签值已编入索引,而字段值未编入索引。这意味着按标签查询比按字段查询更高效。但是,当创建的索引过多时,写入和读取都可能开始变慢。
每组唯一的索引数据元素构成一个序列键。包含高度可变信息(如唯一 ID、哈希和随机字符串)的标签会导致大量系列,也称为高系列基数。高系列基数是许多数据库工作负载高内存使用的主要驱动因素。因此,为了减少内存消耗,请考虑将高基数值存储在字段值中,而不是标签或字段键中。
2.4.3、使用推荐的命名约定
命名标签和字段键时使用以下约定:
1、避免在标签和字段键中保留关键字
不是必需的,但避免在标签和字段键中使用保留关键字可以简化编写查询,因为您不必将键括在双引号中。此外,如果标签或字段键包含 [A-z,_] 以外的字符,则必须在 InfluxQL 中将其括在双引号中或在 Flux 中使用括号表示法。
2、避免使用相同的标签和字段名称
避免对标签和字段键使用相同的名称。这通常会导致查询数据时出现意外行为。
3、避免在测量和键中编码数据
将数据存储在标签值或字段值中,而不是标签键、字段键或测量中。如果您将架构设计为将数据存储在标签和字段值中,您的查询将更容易编写和更高效。此外,您将通过在写入数据时不创建度量和键来保持低基数。要了解有关高系列基数的性能影响的更多信息,请参阅如何查找和减少高系列基数。
- 比较架构:
比较以下由线路协议表示的有效模式。
推荐:以下模式将元数据存储在单独的裁剪、绘图和区域标签中。 temp 字段包含可变数值数据。
Good Measurements schema - Data encoded in tags (recommended)
-------------
weather_sensor,crop=blueberries,plot=1,region=north temp=50.1 1472515200000000000
weather_sensor,crop=blueberries,plot=2,region=midwest temp=49.8 1472515200000000000
不推荐:以下模式在测量中存储多个属性(作物、地块和区域)连接 (blueberries.plot-1.north),类似于
Graphite 指标。
Bad Measurements schema - Data encoded in the measurement (not recommended)
-------------
blueberries.plot-1.north temp=50.1 1472515200000000000
blueberries.plot-2.midwest temp=49.8 1472515200000000000
不推荐:以下模式将多个属性(作物、地块和区域)连接起来(blueberries.plot-1.north)存储在字段键
中。
Bad Keys schema - Data encoded in field keys (not recommended)
-------------
weather_sensor blueberries.plot-1.north.temp=50.1 1472515200000000000
weather_sensor blueberries.plot-2.midwest.temp=49.8 1472515200000000000- 比较查询:
比较 Good Measurements 和 Bad Measurements 模式的以下查询。
Flux 查询计算北部地区蓝莓的平均温度。
易于查询:良好的测量数据很容易按区域标签值过滤,如下例所示。
// Query *Good Measurements*, data stored in separate tag values (recommended)
from(bucket: "<database>/<retention_policy>")
|> range(start:2016-08-30T00:00:00Z)
|> filter(fn: (r) => r._measurement == "weather_sensor" and r.region == "north" and
r._field == "temp")
|> mean()
难以查询:Bad Measurements 需要正则表达式从测量中提取绘图和区域,如下例所示。
// Query *Bad Measurements*, data encoded in the measurement (not recommended)
from(bucket: "<database>/<retention_policy>")
|> range(start:2016-08-30T00:00:00Z)
|> filter(fn: (r) => r._measurement =~ /\.north$/ and r._field == "temp")
|> mean()
复杂的测量使一些查询变得不可能。例如,使用 Bad Measurements 模式无法计算两个图的平均温度。
查询模式的 InfluxQL 示例:
# Query *Bad Measurements*, data encoded in the measurement (not recommended)
> SELECT mean("temp") FROM /\.north$/
# Query *Good Measurements*, data stored in separate tag values (recommended)
> SELECT mean("temp") FROM "weather_sensor" WHERE "region" = 'north'
4、避免在一个标签中包含多条信息
将具有多个部分的单个标签拆分为单独的标签可简化查询并通过减少对正则表达式的需求来提高性能。
考虑以下由线路协议表示的模式:
Schema 1 - Multiple data encoded in a single tag
-------------
weather_sensor,crop=blueberries,location=plot-1.north temp=50.1 1472515200000000000
weather_sensor,crop=blueberries,location=plot-2.midwest temp=49.8 1472515200000000000Schema 1 数据将多个单独的参数、绘图和区域编码为一个长标签值 (plot-1.north)。将此与以下以线路协议表示的模式进行比较:
Schema 2 - Data encoded in multiple tags
-------------
weather_sensor,crop=blueberries,plot=1,region=north temp=50.1 1472515200000000000
weather_sensor,crop=blueberries,plot=2,region=midwest temp=49.8 1472515200000000000使用 Flux 或 InfluxQL 计算北部地区蓝莓的平均温度。模式 2 更可取,因为使用多个标签,您不需要正则表达式。
查询模式的Flux示例:
// Schema 1 - Query for multiple data encoded in a single tag
from(bucket:"<database>/<retention_policy>")
|> range(start:2016-08-30T00:00:00Z)
|> filter(fn: (r) => r._measurement == "weather_sensor" and r.location =~ /\.north$/ and r._field == "temp")
|> mean()
// Schema 2 - Query for data encoded in multiple tags
from(bucket:"<database>/<retention_policy>")
|> range(start:2016-08-30T00:00:00Z)
|> filter(fn: (r) => r._measurement == "weather_sensor" and r.region == "north" and r._field == "temp")
|> mean()
查询模式的InfluxQL示例:
# Schema 1 - Query for multiple data encoded in a single tag
> SELECT mean("temp") FROM "weather_sensor" WHERE location =~ /\.north$/
# Schema 2 - Query for data encoded in multiple tags
> SELECT mean("temp") FROM "weather_sensor" WHERE region = 'north'2.4.4、分片组(shard group)持续时间管理
1、分片组持续时间概览
InfluxDB 将数据存储在分片组中。分片组按保留策略 (RP) 进行组织,并存储时间戳落在称为分片持续时间的特定时间间隔内的数据。
如果没有提供分片组持续时间,则分片组持续时间由创建 RP 时的 RP 持续时间决定。默认值为:
| RP DurationRP 持续时间 | Shard Group Duration分片组持续时间 |
|---|---|
| < 2 days< 2 天 | 1 hour1小时 |
| >= 2 days and <= 6 months>= 2 天且 <= 6 个月 | 1 day1天 |
| > 6 months> 6 个月 | 7 days7天 |
分片组持续时间也可以根据 RP 进行配置。要配置分片组持续时间,请参阅保留策略管理。
2、分片组持续时间权衡
确定最佳分片组持续时间需要找到以下之间的平衡:
- 更长的分片带来更好的整体性能:更长的分片组持续时间让 InfluxDB 在同一逻辑位置存储更多数据。这减少了数据重复,提高了压缩效率,并在某些情况下提高了查询速度。
- 更短的分片提供的灵活性:短的分片组持续时间允许系统更有效地删除数据并记录增量备份。当 InfluxDB 强制执行 RP 时,它会丢弃整个分片组,而不是单个数据点,即使这些点比 RP 持续时间还要早。只有当分片组的持续时间结束时间超过 RP 持续时间时,才会删除分片组。例如,如果您的 RP 的持续时间为一天,则 InfluxDB 将每小时丢弃一小时的数据,并且始终有 25 个分片组。一天中每个小时一个分片组,加上一个部分到期、但只有等到整个分片组超过 24 小时才会被删除的额外分片组。
注意要考虑的特殊用例:按时间过滤模式数据(例如标签、系列、测量值)的查询。例如,如果您想在一小时内过滤模式数据,则必须将分片组持续时间设置为 1 小时。有关详细信息,请参阅按时间过滤架构数据。
3、分片组持续时间建议
默认分片组持续时间适用于大多数情况。但是,高吞吐量或长时间运行的实例将受益于使用更长的分片组持续时间。以下是针对更长分片组持续时间的一些建议:
| RP DurationRP 持续时间 | Shard Group Duration分片组持续时间 |
|---|---|
| <= 1 day<= 1 天 | 6 hours6个小时 |
| > 1 day and <= 7 days> 1 天且 <= 7 天 | 1 day1天 |
| > 7 days and <= 3 months> 7 天且 <= 3 个月 | 7 days7天 |
| > 3 months> 3 个月 | 30 days30天 |
| infinite无穷 | 52 weeks or longer52 周或更长 |
注意:INF(无限)不是有效的分片组持续时间。在数据覆盖数十年且永远不会被删除的极端情况下,像 1040w(20 年)这样长的分片组持续时间是完全有效的。
在设置分片组持续时间之前要考虑的其他因素:
- 分片组应该是最频繁查询的最长时间范围的两倍。
- 分片组每个分片组应包含超过 100,000 个点。
- 分片组每个系列应包含超过 1,000 个点。
回填的分片组持续时间:覆盖了过去一个大的时间范围的历史数据的大量插入,将立刻触发大量分片的创建。并发访问和写入成百上千个分片的开销会很快导致性能下降和内存耗尽。在写入历史数据时,我们强烈建议临时设置更长的分片组持续时间,以减少创建的分片。通常,52 周的分片组持续时间非常适合回填。
2.5、内存索引和时间结构合并树 (TSM)
InfluxDB 存储引擎看起来非常类似于 LSM 树。它有一个预写日志和一组只读数据文件,这些文件在概念上类似于 LSM 树中的 SSTables。 TSM 文件包含排序的、压缩的系列数据。
InfluxDB 将为每个时间块创建一个分片。例如,如果您有一个无限期的保留策略,则会为每 7 天的时间块创建分片。这些分片中的每一个都映射到底层存储引擎数据库。这些数据库中的每一个都有自己的 WAL 和 TSM 文件。
2.5.1、存储引擎
存储引擎将多个组件联系在一起,并提供了用于存储和查询系列数据的外部接口。它由许多组件组成,每个组件都起到特定的作用:
- 内存索引 - 内存索引是跨分片的共享索引,提供对测量、标签和系列的快速访问。索引由引擎使用,但并不特定于存储引擎本身。
- WAL(预写日志) - WAL 是一种写入优化的存储格式,它允许写入是持久的,但不容易查询。对 WAL 的写入附加到固定大小的段。
- Cache(缓存) - 缓存是存储在 WAL 中的数据的内存表示。它在运行时被查询并与存储在 TSM 文件中的数据合并。
- FileStore - FileStore 调解对磁盘上所有 TSM 文件的访问。它确保在替换现有文件以及删除不再使用的 TSM 文件时自动安装 TSM 文件。
- Compactor - Compactor 负责将优化程度较低的 Cache 和 TSM 数据转换为读取优化程度更高的格式。它通过压缩系列、删除已删除的数据、优化索引以及将较小的文件组合成较大的文件来实现这一点。
- 压缩计划器 - 压缩计划器确定哪些 TSM 文件已准备好进行压缩,并确保多个并发压缩不会相互干扰。
- 压缩 - 压缩由各种编码器和解码器处理特定数据类型。一些编码器是相当静态的,并且总是以相同的方式编码相同的类型;其他人根据数据的形状切换压缩策略。
- Writers/Readers - 每种文件类型(WAL 段、TSM 文件、墓碑等)都有用于处理格式的 Writers 和 Readers。
1、WAL(预写日志)
WAL 被组织成一堆看起来像 _000001.wal 的文件。文件编号是单调递增的,称为 WAL 段。当一个段的大小达到 10MB 时,它会关闭并打开一个新的。每个 WAL 段存储多个压缩的写入和删除块。当写入时,新点被序列化,使用 Snappy 压缩,并写入 WAL 文件。该文件是 fsync 的,并且在返回成功之前将数据添加到内存索引中。这意味着需要将批处理点放在一起才能实现高吞吐量性能。 (对于许多用例,最佳批量大小似乎是每批 5,000-10,000 个点。)WAL 中的每个条目都遵循 TLV 标准,其中一个字节表示条目的类型(写入或删除),一个 4 字节的 uint32 表示压缩块的长度,然后是压缩块。
2、Cache(缓存)
缓存是当前存储在 WAL 中的所有数据点的内存副本。这些点由键组织,键是度量、标签集和唯一字段。每个字段都保留为其自己的时间排序范围。缓存数据在内存中时不会被压缩。对存储引擎的查询会将缓存中的数据与 TSM 文件中的数据合并。查询在查询处理时对从缓存中生成的数据副本执行。这样,在查询运行时进入的写入不会影响结果。发送到缓存的删除将清除给定键或给定键的特定时间范围。Cache 公开了一些用于快照行为的控件。两个最重要的控制是内存限制。有一个下限,cache-snapshot-memory-size,当超过时将触发 TSM 文件的快照并删除相应的 WAL 段。还有一个上限,cache-max-memory-size,超过这个上限会导致缓存拒绝新的写入。这些配置对于防止内存不足的情况以及向客户端应用背压以比实例可以持久地更快地写入数据很有用。每次写入都会检查内存阈值。其他快照控件是基于时间的。空闲阈值 cache-snapshot-write-cold-duration 强制缓存在指定间隔内未收到写入时快照到 TSM 文件。通过重新读取磁盘上的 WAL 文件,重新创建内存缓存。
3、TSM文件
TSM 文件是内存映射的只读文件的集合。这些文件的结构看起来非常类似于 LevelDB 或其他 LSM 树变体中的 SSTable。
TSM 文件由四个部分组成:页眉、块、索引和页脚:
+--------+------------------------------------+-------------+--------------+
| Header | Blocks | Index | Footer |
|5 bytes | N bytes | N bytes | 4 bytes |
+--------+------------------------------------+-------------+--------------+Header 是一个魔数,用于标识文件类型和版本号。
+-------------------+
| Header |
+-------------------+
| Magic │ Version |
| 4 bytes │ 1 byte |
+-------------------+Blocks(块)是成对的 CRC32 校验和和数据的序列。块数据对文件是不透明的。 CRC32 用于块级错误检测。块的长度存储在索引中。
+--------------------------------------------------------------------+
│ Blocks │
+---------------------+-----------------------+----------------------+
| Block 1 | Block 2 | Block N |
+---------------------+-----------------------+----------------------+
| CRC | Data | CRC | Data | CRC | Data |
| 4 bytes | N bytes | 4 bytes | N bytes | 4 bytes | N bytes |
+---------------------+-----------------------+----------------------+块之后是文件中块的索引。索引由一系列索引条目组成,这些条目按字典顺序按键排序,然后按时间排序。该键包括测量名称、标签集和一个字段。每个点的多个字段在 TSM 文件中创建多个索引条目。每个索引条目以键长度和键开头,然后是块类型(float、int、bool、string)和该键后面的索引块条目数。每个索引块条目由块的最小和最大时间、块所在文件的偏移量和块的大小组成。 TSM 文件中包含密钥的每个块都有一个索引块条目。
+-----------------------------------------------------------------------------+
│ Index │
+-----------------------------------------------------------------------------+
│ Key Len │ Key │ Type │ Count │Min Time │Max Time │ Offset │ Size │...│
│ 2 bytes │ N bytes │1 byte│2 bytes│ 8 bytes │ 8 bytes │8 bytes │4 bytes │ │
+-----------------------------------------------------------------------------+最后一部分是存储索引开始的偏移量的页脚。
+---------+
│ Footer │
+---------+
│Index Ofs│
│ 8 bytes │
+---------+4、Compression(压缩)
查询时对每个块进行压缩以减少存储空间和磁盘 IO。一个块包含给定系列和字段的时间戳和值。每个块都有一个字节头,后面是压缩时间戳,然后是压缩值。
+--------------------------------------------------+
| Type | Len | Timestamps | Values |
|1 Byte | VByte | N Bytes | N Bytes │
+--------------------------------------------------+时间戳和值使用取决于数据类型及其形状的编码分别压缩和存储。独立存储它们允许时间戳编码用于所有时间戳,同时允许不同字段类型的不同编码。例如,一些点可能能够使用游程编码,而其他点可能不能。每个值类型还包含一个 1 字节的标头,指示剩余字节的压缩类型。四个高位存储压缩类型,四个低位由编码器在需要时使用。
- Timestamps(时间戳):时间戳编码是自适应的,并且基于被编码的时间戳的结构。它使用 delta 编码、缩放和使用 simple8b 运行长度编码的压缩的组合,以及在需要时回退到不压缩。时间戳分辨率是可变的,但可以精确到纳秒,需要多达 8 个字节来存储未压缩。在编码期间,首先对值进行增量编码。第一个值是起始时间戳,后续值是与先前值的差异。这通常会将值转换为更容易压缩的更小的整数。许多时间戳也是单调递增的,并且落在均匀的时间边界上,例如每 10 秒一次。当时间戳具有这种结构时,它们会按最大公约数(也是 10 倍)进行缩放。这具有将非常大的整数增量转换为更小的压缩更好的效果。使用这些调整后的值,如果所有增量都相同,则使用游程编码存储时间范围。如果无法进行游程编码并且所有值都小于 (1 « 60) - 1(在纳秒分辨率下约为 36.5 年),则使用 simple8b 编码对时间戳进行编码。 Simple8b 编码是一种 64 位字对齐整数编码,它将多个整数打包成一个 64 位字。如果任何值超过最大值,则增量存储未压缩,每个块使用 8 个字节。未来的编码可能会使用修补方案,例如修补参考帧 (PFOR) 来更有效地处理异常值。
- Floats(浮点数):浮点数使用 Facebook Gorilla 论文的实现进行编码。当值接近时,编码将连续的值异或在一起以产生小的结果。然后使用控制位存储增量,以指示 XOR 值中有多少前导零和尾随零。我们的实现去除了论文中描述的时间戳编码,只对浮点值进行编码。
- Integers(整数):整数编码根据未压缩数据中的值范围使用两种不同的策略。编码值首先使用 ZigZag 编码进行编码。这在一个正整数范围内交错正整数和负整数。例如,[-2,-1,0,1] 变为 [3,1,0,2]。如果所有 ZigZag 编码值都小于 (1 « 60) - 1,则使用 simple8b 编码对其进行压缩。如果任何值大于最大值,则所有值都未压缩地存储在块中。如果所有值都相同,则使用游程编码。这对于经常保持不变的值非常有效。
- Booleans(布尔值):布尔值使用简单的位打包策略进行编码,其中每个布尔值使用 1 位。编码的布尔数使用可变字节编码存储在块的开头。
- Strings(字符串):字符串使用 Snappy 压缩进行编码。每个字符串被连续打包,它们被压缩为一个更大的块。
5、Compactions(压实)
压实是以写入优化格式存储的数据迁移到读取优化格式的重复过程。当分片对写入很热时,会发生多个压缩阶段:
- Snapshots(快照):缓存和 WAL 中的值必须转换为 TSM 文件以释放 WAL 段使用的内存和磁盘空间。这些压缩基于缓存内存和时间阈值发生。
- Level Compactions(级别压实):级别压实(级别 1-4)随着 TSM 文件的增长而发生。 TSM 文件从快照压缩到 1 级文件。压缩多个级别 1 文件以生成级别 2 文件。该过程继续进行,直到文件达到级别 4(完全压实)和 TSM 文件的最大大小。除非需要运行删除、索引优化压实或完全压实,否则它们不会被进一步压实。较低级别的压实使用避免 CPU 密集型活动(如解压缩和组合块)的策略。更高级别(因此不太频繁)的压实将重新组合块以完全压实它们并增加压缩比。
- Index Optimization(索引优化):当许多 4 级 TSM 文件累积时,内部索引会变得更大并且访问成本更高。索引优化压实在一组新的 TSM 文件中拆分系列和索引,将给定系列的所有点排序到一个 TSM 文件中。在索引优化之前,每个 TSM 文件都包含大多数或所有系列的点,因此每个都包含相同的系列索引。在索引优化之后,每个 TSM 文件都包含来自最少系列的点,并且文件之间几乎没有系列重叠。因此,每个 TSM 文件都有一个较小的唯一系列索引,而不是完整系列列表的副本。此外,来自特定系列的所有点在 TSM 文件中都是连续的,而不是分布在多个 TSM 文件中。
- Full Compactions(完全压实):完全压实(级别 4 压实)在分片因写入长时间变冷或在分片上发生删除时运行。完全压缩产生一组最佳的 TSM 文件,并包括来自级别和索引优化压实的所有优化。一旦分片完全压实,除非存储新的写入或删除,否则不会在其上运行其他压实。
6、Writes(写)
写入被附加到当前 WAL 段,也被添加到缓存中。每个 WAL 段都有一个最大大小。当前文件填满后,写入将滚动到新文件。缓存也是大小有界的;当缓存变得太满时,会拍摄快照并启动 WAL 压缩。如果入站写入率持续超过 WAL 压缩率,缓存可能会变得太满,在这种情况下,新的写入将失败,直到快照进程赶上。当 WAL 段填满并关闭时,Compactor 对缓存进行快照并将数据写入新的 TSM 文件。当 TSM 文件被成功写入并 fsync'd 时,它被 FileStore 加载和引用。
7、Updates(更新)
更新(为已经存在的点写入更新的值)作为正常写入发生。由于缓存值会覆盖现有值,因此较新的写入优先。如果写入将覆盖先前 TSM 文件中的点,则这些点在查询运行时合并,并且较新的写入优先。
8、Deletes(删除)
通过将删除条目写入测量或系列的 WAL,然后更新 Cache 和 FileStore,会发生删除。缓存驱逐所有相关条目。 FileStore 为每个包含相关数据的 TSM 文件写入一个墓碑文件。这些墓碑文件用于在启动时忽略块以及在压缩期间删除已删除的条目。针对部分删除的系列的查询在查询时处理,直到压缩从 TSM 文件中完全删除数据。
9、Queries(查询)
当存储引擎执行查询时,它本质上是对与特定系列键和字段关联的给定时间的查找。首先,我们对数据文件进行搜索以查找包含与查询匹配的时间范围以及包含匹配系列的文件。一旦我们选择了数据文件,我们接下来需要找到系列键索引条目在文件中的位置。我们对每个 TSM 索引运行二进制搜索以查找其索引块的位置。通常情况下,这些块不会在多个 TSM 文件中重叠,我们可以线性搜索索引条目以找到要读取的起始块。如果有重叠的时间块,则对索引条目进行排序以确保更新的写入优先,并且可以在查询执行期间按顺序处理这些块。当迭代索引条目时,从块部分顺序读取块。块被解压缩,我们寻找特定的点。
2.5.2、新的 InfluxDB 存储引擎:从 LSM Tree 到 B+Tree 再返回创建 Time Structured Merge Tree
编写新的存储格式应该是最后的手段。那么 InfluxData 是如何最终编写出我们自己的引擎的呢? InfluxData 已经尝试了许多存储格式,发现每种存储格式都缺乏一些基本的方式。 InfluxDB 的性能要求非常高,最终压倒了其他存储系统。 InfluxDB 0.8 版本允许多个存储引擎,包括 LevelDB、RocksDB、HyperLevelDB 和 LMDB。 InfluxDB 0.9 行使用 BoltDB 作为底层存储引擎。这篇文章是关于 0.9.5 发布的时间结构化合并树存储引擎,它是 InfluxDB 0.11+ 中唯一支持的存储引擎,包括整个 1.x 系列。
时间序列数据用例的属性使其对许多现有的存储引擎具有挑战性。在 InfluxDB 开发过程中,InfluxData 尝试了一些更流行的选项。我们从 LevelDB 开始,这是一个基于 LSM 树的引擎,它针对写入吞吐量进行了优化。之后我们尝试了 BoltDB,这是一个基于内存映射 B+Tree 的引擎,针对读取进行了优化。最后,我们最终构建了自己的存储引擎,该引擎在许多方面与 LSM 树相似。
借助我们的新存储引擎,我们能够通过 B+Tree 设置将磁盘空间使用量减少多达 45 倍,并且写入吞吐量和压缩率比我们在 LevelDB 及其变体中看到的还要高。这篇文章将介绍这种演变的细节,最后深入了解我们的新存储引擎及其内部工作原理。
2.5.3、时间序列数据的属性
时间序列数据的工作量与正常的数据库工作量有很大不同。有许多因素共同导致很难扩展和保持性能:
- 数十亿个单独的数据点;
- 高写入吞吐量;
- 高读取吞吐量;
- 大删除(数据过期);
- 主要是插入/追加工作负载,很少更新。
第一个也是最明显的问题是规模问题。在 DevOps、IoT 或 APM 中,每天很容易收集数亿或数十亿个独特的数据点。例如,假设我们有 200 台虚拟机或服务器正在运行,每台服务器平均每 10 秒收集 100 次测量值。假设一天有 86,400 秒,单次测量将在一天内每台服务器产生 8,640 个点。这为我们提供了每天总共 172,800,000 (200 * 100 * 8,640) 个单独的数据点。我们在传感器数据用例中发现了相似或更大的数字。
数据量大意味着写入吞吐量可能非常高。我们经常收到设置请求,每秒可以处理数十万次写入。一些较大的公司只会考虑每秒可以处理数百万次写入的系统。同时,时间序列数据可以是一个高读取吞吐量的用例。确实,如果您要跟踪 700,000 个独特的指标或时间序列,您就不能希望将它们全部可视化。这导致许多人认为您实际上并没有读取进入数据库的大部分数据。然而,除了人们在屏幕上显示的仪表板之外,还有用于监控大量时间序列数据或将其与其他类型数据结合的自动化系统。
在 InfluxDB 内部,动态计算的聚合函数可能会将数万个不同的时间序列组合到一个视图中。这些查询中的每一个都必须读取每个聚合数据点,因此对于 InfluxDB,读取吞吐量通常比写入吞吐量高很多倍。
鉴于时间序列主要是仅附加工作负载,您可能会认为在 B+Tree 上获得出色的性能是可能的。键空间中的追加是高效的,您可以实现每秒超过 100,000 次。但是,我们有这些附加发生在单独的时间序列中。因此,插入最终看起来更像是随机插入,而不是仅附加插入。
我们在时间序列数据中发现的最大问题之一是,在数据超过一定年龄后删除所有数据是很常见的。这里的常见模式是用户拥有高精度数据,这些数据会保存很短的时间,比如几天或几个月。然后,用户对这些数据进行下采样并将其聚合到较低精度的汇总中,这些汇总保留的时间要长得多。简单的实现是在每条记录超过其过期时间后简单地删除它。但是,这意味着一旦写入的第一个点达到其到期日期,系统就会处理与写入一样多的删除,这是大多数存储引擎的设计初衷。让我们深入了解我们尝试过的两种存储引擎的细节,以及这些属性如何对我们的性能产生重大影响。
2.5.4、LevelDB和日志结构化合并树
当 InfluxDB 项目开始时,我们选择 LevelDB 作为存储引擎,因为我们在作为 InfluxDB 前身的产品中使用它来存储时间序列数据。我们知道它具有出色的写入吞吐量属性,并且一切似乎“正常工作”。
LevelDB 是一个日志结构化合并树(LSM 树)的实现,它是作为 Google 的一个开源项目构建的。它公开了一个用于对键空间进行排序的键值存储的 API。最后一部分对于时间序列数据很重要,因为它允许我们快速扫描时间范围,只要时间戳在键中。
LSM 树基于接受写入的日志和两个称为 Mem Tables 和 SSTables 的结构。这些表表示已排序的键空间。 SSTables 是只读文件,会不断被其他 SSTables 替换,这些 SSTables 将插入和更新合并到键空间中。
LevelDB 为我们带来的两个最大优势是高写入吞吐量和内置压缩。然而,随着我们更多地了解人们对时间序列数据的需求,我们遇到了一些无法克服的挑战。
我们遇到的第一个问题是 LevelDB 不支持热备份。如果要对数据库进行安全备份,则必须将其关闭然后复制。 LevelDB 变体 RocksDB 和 HyperLevelDB 解决了这个问题,但还有另一个更紧迫的问题,我们认为它们无法解决。
我们的用户需要一种自动管理数据保留的方法。这意味着我们需要大规模删除。在 LSM 树中,删除与写入一样昂贵,甚至更多。删除写入称为墓碑的新记录。之后,查询将结果集与任何墓碑合并,以从查询返回中清除已删除的数据。稍后,将运行压缩以删除 SSTable 文件中的 tombstone 记录和底层已删除记录。
为了绕过删除操作,我们将数据拆分为我们所谓的分片,这些分片是连续的时间块。分片通常会保存 1 天或 7 天的数据。每个分片映射到底层 LevelDB。这意味着我们可以通过关闭数据库并删除底层文件来删除一整天的数据。
RocksDB 的用户此时可能会提出一个名为 ColumnFamilies 的功能。将时间序列数据放入 Rocks 时,通常会将时间块拆分为列族,然后在时间到时将其删除。这是相同的一般想法:创建一个单独的区域,当您删除大量数据时,您可以只删除文件而不是更新索引。删除列族是一种非常有效的操作。但是,列族是一个相当新的功能,我们还有另一个分片用例。
将数据组织成碎片意味着它可以在集群内移动,而无需检查数十亿个键。在撰写本文时,无法将一个 RocksDB 中的列族移动到另一个。旧分片通常不适合写入,因此移动它们既便宜又容易。我们将获得额外的好处,即在键空间中有一个对写入冷的位置,因此以后进行一致性检查会更容易。
将数据组织到分片中有一段时间效果很好,直到大量数据进入 InfluxDB。 LevelDB 将数据拆分为许多小文件。在一个进程中打开数十或数百个这样的数据库最终会产生一个大问题。拥有六个月或一年数据的用户将用完文件句柄。这不是我们在大多数用户中发现的问题,但是任何将数据库推到极限的人都会遇到这个问题,我们无法解决这个问题。打开的文件句柄太多。
2.5.5、BoltDB 和 mmap B+树
在与 LevelDB 及其变体斗争了一年之后,我们决定转向 BoltDB,这是一个深受 LMDB 启发的纯 Golang 数据库,一个用 C 编写的 mmap B+Tree 数据库。它具有与 LevelDB 相同的 API 语义:键值存储键空间是有序的。我们的许多用户都感到惊讶。我们自己发布的 LevelDB 变体与 LMDB(mmap B+Tree)的测试表明,RocksDB 表现最好。
然而,除了纯粹的写入性能之外,还有其他一些考虑因素进入了这个决定。在这一点上,我们最重要的目标是获得可以在生产中运行和备份的稳定的东西。 BoltDB 还具有使用纯 Go 编写的优势,这极大地简化了我们的构建链,并且可以轻松地为其他操作系统和平台构建。
对我们来说最大的胜利是 BoltDB 使用单个文件作为数据库。在这一点上,我们最常见的错误报告来源是文件句柄用完的人。 Bolt 同时解决了热备份问题和文件限制问题。如果这意味着我们将拥有一个可以构建的更可靠和稳定的系统,我们愿意对写入吞吐量进行打击。我们的理由是,对于任何推动非常大的写入负载的人,他们无论如何都会运行集群。
我们发布了基于 BoltDB 的 0.9.0 到 0.9.2 版本。从发展的角度来看,这是令人愉快的。干净的 API,在我们的 Go 项目中快速轻松地构建,并且可靠。但是,运行一段时间后,我们发现写入吞吐量存在很大问题。在数据库超过几 GB 后,写入将开始 IOPS 峰值。一些用户能够通过将 InfluxDB 安装在具有几乎无限 IOPS 的大型硬件上来解决这个问题。但是,大多数用户都使用云中资源有限的虚拟机。我们必须想办法减少一次将一堆点写入数十万个系列的影响。
对于 0.9.3 和 0.9.4 版本,我们的计划是在 Bolt 前面放置一个预写日志 (WAL)。这样我们就可以减少随机插入密钥空间的次数。相反,我们会缓冲多个彼此相邻的写入,然后一次刷新它们。然而,这只有助于延迟问题。高 IOPS 仍然是一个问题,对于任何在中等工作负载下运行的人来说,它很快就会出现。然而,我们在 Bolt 之前构建第一个 WAL 实现的经验让我们有信心解决写入问题。 WAL 本身的表现很棒,指数根本跟不上。在这一点上,我们再次开始思考如何创建类似于 LSM 树的东西来跟上我们的写入负载。因此诞生了时间结构化合并树。
2.6、Time Series Index(TSI,时间序列指数)
2.6.1、概述
为了支持大量的时间序列,即数据库存储的唯一时间序列数量的基数非常高,InfluxData 添加了新的时间序列索引(TSI)。 InfluxData 支持客户使用 InfluxDB 数以千万计的时间序列。然而,InfluxData 的目标是扩大到数亿,最终达到数十亿。使用 InfluxData 的 TSI 存储引擎,用户应该能够拥有数百万个独特的时间序列。目标是系列的数量应该不受服务器硬件上的内存量的限制。重要的是,数据库中存在的系列数量对数据库启动时间的影响可以忽略不计。这项工作代表了自 2016 年 InfluxData 发布时间序列合并树 (TSM) 存储引擎以来数据库中最重要的技术进步。
2.6.2、背景资料
InfluxDB 实际上看起来像两个数据库,一个时间序列数据存储和一个用于度量、标签和字段元数据的倒排索引。
1、Time-Structed Merge Tree(TSM,时间结构合并树)
时间结构合并树 (TSM) 引擎解决了获取原始时间序列数据的最大吞吐量、压缩和查询速度的问题。在 TSI 之前,倒排索引是一种内存中的数据结构,它是在数据库启动时根据 TSM 中的数据构建的。这意味着对于每个测量值、标签键值对和字段名称,内存中都有一个查找表,用于将这些元数据位映射到底层时间序列。对于具有大量临时序列的用户,随着新时间序列的创建,内存利用率继续增加。而且,启动时间增加了,因为所有这些数据都必须在启动时加载到堆上。
2、Time Series Index(TSI,时间序列指数)
新的时间序列索引 (TSI) 将索引移动到我们内存映射的磁盘上的文件。这意味着我们让操作系统处理最近最少使用 (LRU) 内存。与原始时间序列数据的 TSM 引擎非常相似,我们有一个带有内存结构的预写日志,该结构在查询时与内存映射索引合并。后台例程不断运行以将索引压缩为越来越大的文件,以避免在查询时进行过多的索引合并。在幕后,我们使用 Robin Hood Hashing 等技术进行快速索引查找,并使用 HyperLogLog++ 来保留基数估计的草图。后者将使我们能够将内容添加到查询语言中,例如 SHOW CARDINALITY 查询。
3、TSI解决的问题和待解决的问题
时间序列索引 (TSI) 解决的主要问题是短暂的时间序列。最常见的是,这发生在希望通过将标识符放入标签中来跟踪每个进程指标或每个容器指标的用例中。例如,Kubernetes 的 Heapster 项目就是这样做的。对于不再适合写入或查询的系列,它们不会占用内存空间。Heapster 项目和类似用例没有解决的问题是限制 SHOW 查询返回的数据范围。我们将来会对查询语言进行更新,以按时间限制这些结果。我们也没有解决让所有这些系列热读和写的问题。对于这个问题,横向扩展集群是解决方案。我们将不得不继续优化查询语言和引擎以处理大量系列。我们需要在语言中添加防护栏和限制,并最终添加溢出到磁盘的查询处理。这项工作将在 InfluxDB 的每个版本中进行。
2.6.3、详细信息
当 InfluxDB 摄取数据时,我们不仅存储值,还索引测量和标签信息,以便快速查询。在早期版本中,索引数据只能存储在内存中,但是,这需要大量 RAM,并且对机器可以容纳的系列数量设置了上限。这个上限通常介于 1 - 4 百万系列之间,具体取决于所使用的机器。
时间序列指数 (TSI) 的开发是为了让我们能够超越该上限。 TSI 将索引数据存储在磁盘上,这样我们就不再受 RAM 的限制。 TSI 使用操作系统的页面缓存将热数据拉入内存,让冷数据留在磁盘上。
1、启用TSI
要启用 TSI,请在 InfluxDB 配置文件 (influxdb.conf) 中设置以下行(一定要包括双引号。):
index-version = "tsi1"2、Tooling
如果要对索引问题进行故障排除,可以使用 influx_inspect dumptsi 命令。此命令允许您打印索引、文件或一组文件的摘要统计信息。此命令一次仅适用于一个索引。
如果要将现有分片从内存索引转换为 TSI 索引,或者如果现有 TSI 索引已损坏,则可以使用 buildtsi 命令从底层 TSM 数据创建索引。如果您有要重建的现有 TSI 索引,请首先删除分片中的索引目录。此命令在服务器级别工作,但您可以选择添加数据库、保留策略和分片过滤器以仅应用于分片子集。
3、了解TSI
File organization(文件组织):TSI(时间序列索引)是一个基于日志结构的合并树数据库,用于 InfluxDB 系列数据。 TSI由几个部分组成:
- Index(索引):包含单个分片的整个索引数据集。
- Partition(分区):包含分片数据的分片分区。
- LogFile:包含新写入的系列作为内存索引,并作为 WAL 持久化。
- IndexFile:包含从 LogFile 构建或从两个连续索引文件合并的不可变的内存映射索引。
- 还有一个 SeriesFile,其中包含整个数据库中的一组所有系列键。数据库中的每个分片共享同一个系列文件。
Write(写):当写入进入系统时会发生以下情况:
- 系列被添加到系列文件中,或者如果它已经存在则被查找。这将返回一个自动递增的系列 ID。
- 该系列被发送到索引。该索引维护现有系列 ID 的咆哮位图,并忽略已创建的系列。
- 该系列被散列并发送到适当的分区。
- 分区将系列作为条目写入日志文件。
- LogFile 将系列写入磁盘上的预写日志文件,并将系列添加到一组内存索引中。
Compaction(压实):启用压实后,InfluxDB 每秒都会检查是否需要压实。如果在 compact-full-write-cold-duration 期间(默认为 4h)没有写入,InfluxDB 会压实所有 TSM 文件。否则,InfluxDB 将 TSM 文件分组到压实级别(由文件被压实的次数确定),并尝试组合文件并更有效地压缩它们。
一旦 LogFile 超过阈值 (5MB),InfluxDB 就会创建一个新的活动日志文件,并且之前的日志文件开始压实成一个 IndexFile。第一个索引文件位于级别 1 (L1)。日志文件被视为级别 0 (L0)。也可以通过将两个较小的索引文件合并在一起来创建索引文件。例如,如果存在两个连续的 L1 索引文件,InfluxDB 会将它们合并为一个 L2 索引文件。
InfluxDB 优先安排压实,使用以下指南:
- 级别越低(文件被压实的次数越少),压实它的权重就越大。
- 一个级别中的可压实文件越多,该级别的优先级就越高。如果每个级别中的文件数量相等,则首先压实较低级别。
- 如果较高级别有更多的压实候选者,它可能会在较低级别之前被压实。 InfluxDB 将收集组的数量(要压实成单个下一代文件的文件的集合)乘以每个级别的指定权重(0.4、0.3、0.2 和 0.1),以确定压实优先级。
重要的压实配置设置:压实工作负载由数据库的摄取率和以下限制配置设置驱动:
- cache-snapshot-memory-size:指定在将数据写入 TSM 文件之前保留在内存中的 write-cache 大小。
- cache-snapshot-write-cold-duration:如果缓存不超过 cache-snapshot-memory-size 大小,则指定在将数据写入 TSM 文件之前将数据保留在内存中的时间长度,而没有任何传入数据。
- max-concurrent-compactions:一次可以运行的压实数。
- compact-throughput:控制压实引擎的平均磁盘 IO。
- compact-throughput-burst:控制压实引擎的最大磁盘 IO。
- compact-full-write-cold-duration:在调度完全压实之前,分片必须在多长时间内没有收到写入或删除。
这些配置设置对于负载不规则的系统特别有用,在高使用期间限制压实,并在负载较低期间让压实赶上。在负载稳定的系统中,如果压实会干扰其他操作,通常情况下,系统的负载过小,配置更改不会有太大帮助。
Reads(读取):该索引提供了几个用于检索数据集的 API 调用,例如:
- MeasurementIterator():返回测量名称的排序列表。
- TagKeyIterator():返回测量中标签键的排序列表。
- TagValueIterator():返回标签键的标签值的排序列表。
- MeasurementSeriesIDIterator():返回测量的所有系列 ID 的排序列表。
- TagKeySeriesIDIterator():返回标签键的所有系列 ID 的排序列表。
- TagValueSeriesIDIterator():返回标签值的所有系列 ID 的排序列表。
这些迭代器都可以使用多个合并迭代器进行组合。对于每种类型的迭代器(measurement、tag key、tag value、series id),都有多种合并迭代器类型:
- Merge(合并):从两个迭代器中删除重复项。
- Intersect(相交):仅返回存在于两个迭代器中的项目。
- Difference(区别):仅从第一个迭代器返回第二个迭代器中不存在的项目。
例如,带有 region != 'us-west' 的 WHERE 子句跨两个分片操作的查询将构造一组迭代器,如下所示:
DifferenceSeriesIDIterators(
MergeSeriesIDIterators(
Shard1.MeasurementSeriesIDIterator("m"),
Shard2.MeasurementSeriesIDIterator("m"),
),
MergeSeriesIDIterators(
Shard1.TagValueSeriesIDIterator("m", "region", "us-west"),
Shard2.TagValueSeriesIDIterator("m", "region", "us-west"),
),
)Log File Structure(日志文件结构):日志文件被简单地构造为按顺序写入磁盘的 LogEntry 对象列表。日志文件被写入直到它们达到 5MB,然后它们被压缩成索引文件。日志中的条目对象可以是以下任意一种:
- 添加系列;
- 删除系列;
- 删除测量;
- 删除标签键;
- 删除标签值
日志文件上的内存索引跟踪以下内容:
- 按名称测量;
- 按测量标记键;
- 按标签键标记值;
- 测量系列;
- 按标签值排列;
- 系列、测量值、标签键和标签值的墓碑。
日志文件还维护系列 ID 存在和墓碑的位集。这些位集与其他日志文件和索引文件合并,以在启动时重新生成完整的索引位集。
Index File Structure(索引文件结构):索引文件是一个不可变文件,它跟踪与日志文件类似的信息,但所有数据都被索引并写入磁盘,以便可以直接从内存映射中访问。
索引文件包含以下部分:
- TagBlocks:维护单个标签键的标签值索引。
- MeasurementBlock:维护测量索引及其标签键。
- Trailer:存储文件的偏移信息以及用于基数估计的 HyperLogLog 草图。
Manifest:MANIFEST 文件存储在索引目录中,并列出了属于该索引的所有文件以及它们应该被访问的顺序。每次发生压缩时都会更新此文件。目录中任何不在索引文件中的文件都是正在压缩的索引文件。
FileSet(文件集):文件集是 InfluxDB 进程运行时获得的清单的内存快照。这是在某个时间点提供一致的索引视图所必需的。该文件集还有助于对其所有文件进行引用计数,因此在文件的所有阅读器都完成之前,不会通过压缩删除任何文件。
2.7、InfluxDB文件系统布局
InfluxDB 文件系统布局取决于用于安装 InfluxDB 的操作系统、安装方法或容器化平台。
2.7.1、InfluxDB文件结构
InfluxDB 文件结构包括以下内容:
- Data directory(数据目录):InfluxDB 存储时间序列数据(TSM 文件)的目录路径。要自定义此路径,请使用 [data].dir 配置选项。
- WAL directory(WAL目录):InfluxDB 存储预写日志 (WAL) 文件的目录路径。要自定义此路径,请使用 [data].wal-dir 配置选项。
- Metastore directory(元存储目录):InfluxDB Metastore 的目录路径,存储有关用户、数据库、保留策略、分片和连续查询的信息。要自定义此路径,请使用 [meta].dir 配置选项。
2.7.2、InfluxDB配置文件
一些操作系统和包管理器在磁盘上存储一个默认的 InfluxDB 配置文件。有关使用 InfluxDB 配置文件的更多信息,请参阅配置 InfluxDB。
2.7.3、文件系统布局
1、macOS
| Path | Default |
|---|---|
| Data directory | ~/.influxdb/data/ |
| WAL directory | ~/.influxdb/wal/ |
| Metastore directory | ~/.influxdb/meta/ |
~/.influxdb/
data/
TSM directories and files
wal/
WAL directories and files
meta/
meta.db2、Linux
| Path | Default |
|---|---|
| Data directory | ~/.influxdb/data/ |
| WAL directory | ~/.influxdb/wal/ |
| Metastore directory | ~/.influxdb/meta/ |
~/.influxdb/
data/
TSM directories and files
wal/
WAL directories and files
meta/
meta.db3、Windows
| Path | Default |
|---|---|
| Data directory | %USERPROFILE%\.influxdb\data\ |
| WAL directory | %USERPROFILE%\.influxdb\wal\ |
| Metastore directory | %USERPROFILE%\.influxdb\meta\ |
%USERPROFILE%\.influxdb\
data/
TSM directories and files
wal/
WAL directories and files
meta/
meta.db4、Docker
| Path | Default |
|---|---|
| Data directory | /var/lib/influxdb/data/ |
| WAL directory | /var/lib/influxdb/wal/ |
| Metastore directory | /var/lib/influxdb/meta/ |
/var/lib/influxdb/
data/
TSM directories and files
wal/
WAL directories and files
meta/
meta.db5、Kubernetes
| Path | Default |
|---|---|
| Data directory | /var/lib/influxdb/data/ |
| WAL directory | /var/lib/influxdb/wal/ |
| Metastore directory | /var/lib/influxdb/meta/ |
/var/lib/influxdb/
data/
TSM directories and files
wal/
WAL directories and files
meta/
meta.db3、InfluxDB指南
3.1、InfluxDB命令行界面
InfluxDB 的命令行界面 (influx) 是 HTTP API 的交互式 shell。使用 influx 写入数据(手动或从文件中)、交互式查询数据以及查看不同格式的查询输出。
3.1.1、启动influx
如果您通过包管理器安装 InfluxDB,则 CLI 安装在 /usr/bin/influx(macOS 上为 /usr/local/bin/influx)。要访问 CLI,首先启动 influxd 数据库进程,然后在终端中启动 influx。进入 shell 并成功连接到 InfluxDB 节点后,您将看到以下输出:
$ influx
Connected to http://localhost:8086 version 1.8.10
InfluxDB shell version: 1.8.10注意:InfluxDB 和 CLI 的版本应该相同。否则,查询可能会出现解析问题。
您现在可以直接在终端中输入 InfluxQL 查询以及一些特定于 CLI 的命令。您可以随时使用帮助来获取可用命令的列表。如果要取消长时间运行的 InfluxQL 查询,请使用 Ctrl+C 取消。
3.1.2、环境变量
以下环境变量可用于配置 influx 客户端使用的设置。它们可以指定为小写或大写,但大写版本优先。
- HTTP_PROXY:定义用于 HTTP 的代理服务器。
值格式:[protocol://]<host>[:port]
如:HTTP_PROXY=http://localhost:1234
- HTTPS_PROXY:定义用于 HTTPS 的代理服务器。对于 HTTPS,优先于 HTTP_PROXY。
值格式:值格式:[protocol://]<host>[:port]
如:HTTPS_PROXY=https://localhost:1443
- NO_PROXY:不应通过任何代理的主机名列表。如果仅设置为星号“*”,则匹配所有主机。
值格式:逗号分隔的主机列表
如:NO_PROXY=123.45.67.89,123.45.67.903.1.3、influx参数
在开始时,您可以将几个参数传递给 influx。用 $ influx --help 列出它们。下面的列表简要讨论了每个选项。我们在本节末尾提供了有关 -execute、-format 和 -import 的详细信息。
-compressed 如果导入文件被压缩,则设置为 true。与 -import 一起使用。
-consistency 'any|one|quorum|all' 设置写入一致性级别。
-database 'database name' influx 连接的数据库。
-execute 'command' 执行 InfluxQL 命令并退出。请参阅 -execute 。
-format 'json|csv|column' 指定服务器响应的格式。请参阅-format。
-host '主机名' influx 连接的主机。默认情况下,InfluxDB 在 localhost 上运行。
-import 从文件中导入新数据或从文件中导入以前导出的数据库。请参阅 -import。
-password 'password' 密码涌入用于连接到服务器。如果您将其留空(-password ''),influx 将提示输
入密码。或者,使用 INFLUX_PASSWORD 环境变量设置 CLI 的密码。
-path 要导入的文件的路径。与 -import 一起使用。
-port 'port #' influx 连接的端口。默认情况下,InfluxDB 在端口 8086 上运行。
-pps 每秒允许导入多少点。默认情况下,pps 为零,influx 不会限制导入。与 -import 一起使用。
-precision 'rfc3339|h|m|s|ms|u|ns' 指定时间戳的格式/精度:rfc3339 (YYYY-MM-
DDTHH:MM:SS.nnnnnnnnnZ), h (小时), m (分钟) , s (秒), ms (毫秒), u (微秒), ns (纳秒)。精度
默认为纳秒。
注意:将精度设置为 rfc3339 (-precision rfc3339) 可与 -execute 选项一起使用,但不能与 -import
选项一起使用。所有其他精度格式(例如,h、m、s、ms、u 和 ns)都与 -execute 和 -import 选项一起使
用。
-pretty 打开 json 格式的漂亮打印。
-ssl 对请求使用 HTTPS。
-unsafeSsl 禁用 SSL 证书验证。在使用自签名证书通过 HTTPS 连接时使用。
-username 'username' influx 用来连接服务器的用户名。或者,使用 INFLUX_USERNAME 环境变量设置 CLI 的用户名。
-version 显示 InfluxDB 版本并退出。执行InfluxQL命令并使用-execute退出:
执行不需要数据库规范的查询:
$ influx -execute 'SHOW DATABASES'
name: databases
---------------
name
NOAA_water_database
_internal
telegraf
pirates执行需要数据库规范的查询,并更改时间戳精度:
$ influx -execute 'SELECT * FROM "h2o_feet" LIMIT 3' -database="NOAA_water_database" -precision=rfc3339
name: h2o_feet
--------------
time level description location water_level
2015-08-18T00:00:00Z below 3 feet santa_monica 2.064
2015-08-18T00:00:00Z between 6 and 9 feet coyote_creek 8.12
2015-08-18T00:06:00Z between 6 and 9 feet coyote_creek 8.005使用-format执行服务器响应的格式:
默认格式为列:
$ influx -format=column
[...]
> SHOW DATABASES
name: databases
---------------
name
NOAA_water_database
_internal
telegraf
pirates将格式更改为 csv:
$ influx -format=csv
[...]
> SHOW DATABASES
name,name
databases,NOAA_water_database
databases,_internal
databases,telegraf
databases,pirates将格式更改为 json:
$ influx -format=json
[...]
> SHOW DATABASES
{"results":[{"series":[{"name":"databases","columns":["name"],"values":[["NOAA_water_database"],["_internal"],["telegraf"],["pirates"]]}]}]}
将格式更改为 json 并打开漂亮的打印:
$ influx -format=json -pretty
[...]
> SHOW DATABASES
{
"results": [
{
"series": [
{
"name": "databases",
"columns": [
"name"
],
"values": [
[
"NOAA_water_database"
],
[
"_internal"
],
[
"telegraf"
],
[
"pirates"
]
]
}
]
}
]
}
使用-import从文件中导入数据:
导入文件有两个部分:
- DDL(Data Definition Language,数据定义语言):包含用于创建相关数据库和管理保留策略的 InfluxQL 命令。如果您的数据库和保留策略已经存在,您的文件可以跳过此部分。
- DML(Data Manipulation Language,数据操作语言):列出相关数据库和(如果需要)保留策略,并包含在线协议中的数据。
例如,文件(datarrr.txt):
# DDL
CREATE DATABASE pirates
CREATE RETENTION POLICY oneday ON pirates DURATION 1d REPLICATION 1
# DML
# CONTEXT-DATABASE: pirates
# CONTEXT-RETENTION-POLICY: oneday
treasures,captain_id=dread_pirate_roberts value=801 1439856000
treasures,captain_id=flint value=29 1439856000
treasures,captain_id=sparrow value=38 1439856000
treasures,captain_id=tetra value=47 1439856000
treasures,captain_id=crunch value=109 1439858880命令:
$influx -import -path=datarrr.txt -precision=s结果:
2015/12/22 12:25:06 Processed 2 commands
2015/12/22 12:25:06 Processed 5 inserts
2015/12/22 12:25:06 Failed 0 inserts注意:对于大型数据集,influx 每 100,000 个点写出一条状态消息。
例如:
2015/08/21 14:48:01 Processed 3100000 lines.
Time elapsed: 56.740578415s.
Points per second (PPS): 54634关于-import的注意事项:
- 通过使用 -pps 设置导入允许的每秒点数,允许数据库摄取点。默认情况下,pps 为零,influx 不会限制导入。
- 导入使用 .gz 文件,只需在命令中包含 -compressed 。
- 在数据文件中包含时间戳。 InfluxDB 将为没有时间戳的点分配相同的时间戳。这可能导致意外的覆盖行为。
- 如果您的数据文件有超过 5,000 个点,则可能需要将该文件拆分为多个文件,以便将您的数据批量写入 InfluxDB。我们建议分批写入 5,000 到 10,000 点。较小的批次和更多的 HTTP 请求将导致性能欠佳。默认情况下,HTTP 请求在 5 秒后超时。 InfluxDB 仍然会在超时后尝试写入这些点,但不会确认它们是否已成功写入。
3.1.4、influx命令
在 CLI 中输入帮助以获取可用命令的部分列表。
1、命令
下面的列表简要讨论了每个命令。
auth 提示您输入用户名和密码。 influx 在查询数据库时使用这些凭据。或者,使用 INFLUX_USERNAME 和 INFLUX_PASSWORD 环境变量设置 CLI 的用户名和密码。
chunked 在发出查询时打开来自服务器的分块响应。默认情况下启用此设置。
chunk size <size> 设置分块响应的大小。默认大小为 10,000。将其设置为 0 会将块大小重置为其默认值。
clear [ database | db | retention policy | rp ]清除数据库或保留策略的当前上下文。connect <host:port> 在不退出 shell 的情况下连接到不同的服务器。默认情况下,influx 连接到 localhost:8086。如果您未指定主机或端口,则 influx 假定缺少属性的默认设置。
consistency <level>设置写入一致性级别:any、one、quorum 或 all。Ctrl+C 终止当前运行的查询。当交互式查询由于试图返回太多数据而需要很长时间才能响应时很有用。
exit quit Ctrl+D 退出 influx shell。
format <format> 指定服务器响应的格式:json、csv 或 column。有关每种格式的示例,请参见 -format 的说明。
history 显示您的命令历史记录。要在 shell 中使用历史记录,只需使用“向上”箭头。 influx 将最后 1,000 条命令存储在主目录的 .influx_history 中。
insert 使用线路协议写入数据。见insert。
precision <format> 指定时间戳的格式/精度:rfc3339 (YYYY-MM-DDTHH:MM:SS.nnnnnnnnnZ), h (小时), m (分钟), s (秒), ms (毫秒), u (微秒),ns(纳秒)。精度默认为纳秒。
pretty 打开 json 格式的漂亮打印。
settings 输出 shell 的当前设置,包括主机、用户名、数据库、保留策略、漂亮状态、块状态、块大小、格式和写入一致性。
使用 ["<database_name>" | "<database_name>"."<retention policy_name>" ] 设置当前数据库和/或保留策略。一旦 influx 设置了当前数据库和/或保留策略,就无需在查询中指定该数据库和/或保留策略。如果不指定保留策略,influx 会自动查询使用的数据库的 DEFAULT 保留策略。
输入 insert 后跟 data in line protocol 将数据写入 InfluxDB。使用 insert into <retention policy> <line protocol> 将数据写入特定的保留策略。
将数据写入测量宝藏中标签为 Captain_id = pirate_king 的单个字段。 influx 自动将该点写入数据库的 DEFAULT 保留策略。
> INSERT treasures,captain_id=pirate_king value=2将同一点写入已存在的保留策略中:
> INSERT INTO oneday treasures,captain_id=pirate_king value=2 Using retention policy oneday >
2、查询
执行 influx 中的所有 InfluxQL 查询。
3.2、使用InfluxDB API写入数据
使用命令行界面、客户端库和用于常见数据格式(如 Graphite)的插件将数据写入 InfluxDB。
注意:以下示例使用 curl,这是一个使用 URL 传输数据的命令行工具。通过 HTTP 脚本指南了解 curl 的基础知识。
3.2.1、使用InfluxDB API创建数据库
要创建数据库,请向 /query 端点发送 POST 请求并将 URL 参数 q 设置为 CREATE DATABASE <new_database_name>。下面的示例向在 localhost 上运行的 InfluxDB 发送请求并创建 mydb 数据库:
curl -i -XPOST http://localhost:8086/query --data-urlencode "q=CREATE DATABASE mydb"3.2.2、使用InfluxDB API写入数据
InfluxDB API 是将数据写入 InfluxDB 的主要方式。
要使用 InfluxDB 1.8 API 写入数据库,请将 POST 请求发送到 /write 端点。例如,将单点写入 mydb 数据库。数据包括测量值 cpu_load_short、标签键主机和标签值为 server01 和 us-west 的区域、字段值为 0.64 的字段键值以及时间戳 1434055562000000000。
curl -i -XPOST 'http://localhost:8086/write?db=mydb'
--data-binary 'cpu_load_short,host=server01,region=us-west value=0.64 1434055562000000000'
要使用 InfluxDB 2.0 API(与 InfluxDB 1.8+ 兼容)写入数据库,请将 POST 请求发送到 /api/v2/write 端点:
curl -i -XPOST 'http://localhost:8086/api/v2/write?bucket=db/rp&precision=ns' \
--header 'Authorization: Token username:password' \
--data-raw 'cpu_load_short,host=server01,region=us-west value=0.64 1434055562000000000'
写入点时,必须在 db 查询参数中指定现有数据库。如果您未通过 rp 查询参数提供保留策略,则积分将写入 db 的默认保留策略。有关可用查询参数的完整列表,请参阅 InfluxDB API 参考文档。
POST 或 InfluxDB 线路协议的主体包含您要存储的时间序列数据。数据包括:
- 测量(必填);
- 标签:严格来说,标签是可选的,但大多数系列都包含标签,以区分数据源,并使查询既简单又高效。标签键和标签值都是字符串。
- 字段(必需):字段键是必需的,并且始终是字符串,并且默认情况下,字段值是浮点数。
- 时间戳:自 1970 年 1 月 1 日 UTC 以来,在 Unix 时间的行尾提供,以纳秒为单位 - 是可选的。如果你不指定时间戳,InfluxDB 使用服务器在 Unix 纪元中的本地纳秒时间戳。 InfluxDB 中的时间默认为 UTC 格式。
注意:避免使用以下保留键:_field、_measurement 和 time。如果保留键作为标签或字段键包含,则关联点将被丢弃。
3.2.3、配置gzip压缩
InfluxDB 支持 gzip 压缩。要减少网络流量,请考虑以下选项:
- 要接受来自 InfluxDB 的压缩数据,请将 Accept-Encoding: gzip 标头添加到 InfluxDB API 请求。
- 要在将数据发送到 InfluxDB 之前对其进行压缩,请将 Content-Encoding: gzip 标头添加到 InfluxDB API 请求中。
在Telegraf InfluxDB输出插件中启用gzip压缩:在 Telegraf 配置文件 (telegraf.conf) 中,在 [[outputs.influxdb]] 下,将 content_encoding = "identity"(默认)更改为 content_encoding = "gzip"
注意:写入 InfluxDB 2.x [[outputs.influxdb_v2]] 默认配置为压缩 gzip 格式的内容。
3.2.4、写多个点
通过用新线分隔每个点,同时将多个点发布到多个系列。以这种方式的批处理点会导致更高的性能。
以下示例将三个点写入数据库 mydb。第一个点属于具有测量 cpu_load_short 和标签集 host=server02 的系列,并具有服务器的本地时间戳。第二个点属于测量 cpu_load_short 和标签集 host=server02,region=us-west 的系列,并具有指定的时间戳 1422568543702900257。第三个点与第二个点具有相同的指定时间戳,但它被写入系列使用测量 cpu_load_short 和标签集 direction=in,host=server01,region=us-west。
curl -i -XPOST 'http://localhost:8086/write?db=mydb' --data-binary 'cpu_load_short,host=server02 value=0.67
cpu_load_short,host=server02,region=us-west value=0.55 1422568543702900257
cpu_load_short,direction=in,host=server01,region=us-west value=2.0 1422568543702900257'
3.2.5、从文件写入点
通过将 @filename 传递给 curl 从文件中写入点。文件中的数据应遵循 InfluxDB 行协议语法。
格式正确的文件 (cpu_data.txt) 示例:
cpu_load_short,host=server02 value=0.67
cpu_load_short,host=server02,region=us-west value=0.55 1422568543702900257
cpu_load_short,direction=in,host=server01,region=us-west value=2.0 1422568543702900257将 cpu_data.txt 中的数据写入 mydb 数据库:
curl -i -XPOST 'http://localhost:8086/write?db=mydb' --data-binary @cpu_data.txt注意:如果您的数据文件有超过 5,000 个点,则可能需要将该文件拆分为多个文件,以便将您的数据批量写入 InfluxDB。默认情况下,HTTP 请求在 5 秒后超时。 InfluxDB 仍然会在超时后尝试写入这些点,但不会确认它们是否已成功写入。
3.2.6、无模式设计
InfluxDB 是一个无模式数据库。您可以随时添加新的度量、标签和字段。请注意,如果您尝试写入与以前使用的类型不同的数据(例如,将字符串写入以前接受整数的字段),InfluxDB 将拒绝这些数据。
3.2.7、关于REST的说明
InfluxDB 仅使用 HTTP 作为一种方便且广泛支持的数据传输协议。
现代 Web API 选择了 REST,因为它解决了一个共同的需求。随着端点数量的增加,对组织系统的需求变得紧迫。 REST 是用于组织大量端点的行业认可的风格。这种一致性对于开发和使用 API 的人来说是件好事:参与其中的每个人都知道会发生什么。然而,REST 是一种约定。 InfluxDB 使用三个 API 端点。这个简单易懂的系统使用 HTTP 作为 InfluxQL 的传输方法。 InfluxDB API 没有尝试成为 RESTful。
3.2.8、HTTP响应摘要
- 2xx:如果你的写请求收到HTTP 204 No Content,那就是成功了!
- 4xx:InfluxDB 无法理解请求。
- 5xx:系统过载或严重受损。
例如将浮点数写入先前接收布尔值的字段:
curl -i -XPOST 'http://localhost:8086/write?db=hamlet' --data-binary 'tobeornottobe booleanonly=true'
curl -i -XPOST 'http://localhost:8086/write?db=hamlet' --data-binary 'tobeornottobe booleanonly=5'
返回:
HTTP/1.1 400 Bad Request
Content-Type: application/json
Request-Id: [...]
X-Influxdb-Version: 1.8.10
Date: Wed, 01 Mar 2017 19:38:01 GMT
Content-Length: 150
{"error":"field type conflict: input field \"booleanonly\" on measurement \"tobeornottobe\" is type float, already exists as type boolean dropped=1"}
例如将点写入不存在的数据库:
curl -i -XPOST 'http://localhost:8086/write?db=atlantis' --data-binary 'liters value=10'结果:
HTTP/1.1 404 Not Found
Content-Type: application/json
Request-Id: [...]
X-Influxdb-Version: 1.8.10
Date: Wed, 01 Mar 2017 19:38:35 GMT
Content-Length: 45
{"error":"database not found: \"atlantis\""}
3.3、使用InfluxDB API查询数据
InfluxDB API 是在 InfluxDB 中查询数据的主要方式(有关查询数据库的替代方法,请参见命令行界面和客户端库)。使用 Flux 或 InfluxQL 通过 InfluxDB API 查询数据。
注意:以下示例使用 curl,这是一个使用 URL 传输数据的命令行工具。通过 HTTP 脚本指南了解 curl 的基础知识。
3.3.1、使用Flux查询数据
对于 Flux 查询,/api/v2/query 端点接受 POST HTTP 请求。使用以下 HTTP 标头:
Accept: application/csv
Content-type: application/vnd.flux如果您启用了身份验证,请提供您的 InfluxDB 用户名和密码以及 Authorization 标头和 Token 模式。例如:授权:令牌用户名:密码。
以下示例使用 Flux: 查询 Telegraf 数据:
$ curl -XPOST localhost:8086/api/v2/query -sS \
-H 'Accept:application/csv' \
-H 'Content-type:application/vnd.flux' \
-d 'from(bucket:"telegraf")
|> range(start:-5m)
|> filter(fn:(r) => r._measurement == "cpu")' Flux 返回带注释的 CSV:
{,result,table,_start,_stop,_time,_value,_field,_measurement,cpu,host
,_result,0,2020-04-07T18:02:54.924273Z,2020-04-07T19:02:54.924273Z,2020-04-07T18:08:19Z,4.152553004641827,usage_user,cpu,cpu-total,host1
,_result,0,2020-04-07T18:02:54.924273Z,2020-04-07T19:02:54.924273Z,2020-04-07T18:08:29Z,7.608695652173913,usage_user,cpu,cpu-total,host1
,_result,0,2020-04-07T18:02:54.924273Z,2020-04-07T19:02:54.924273Z,2020-04-07T18:08:39Z,2.9363988504310883,usage_user,cpu,cpu-total,host1
,_result,0,2020-04-07T18:02:54.924273Z,2020-04-07T19:02:54.924273Z,2020-04-07T18:08:49Z,6.915093159934975,usage_user,cpu,cpu-total,host1}标题行定义表格的列标签。 cpu 测量有四个点,每个点由记录行之一表示。例如,第一个点的时间戳为 2020-04-07T18:08:19。
3.3.2、使用InfluxQL查询数据
要执行 InfluxQL 查询,请将 GET 请求发送到 /query 端点,将 URL 参数 db 设置为目标数据库,并将 URL 参数 q 设置为您的查询。您还可以通过发送相同的参数作为 URL 参数或作为带有 application/x-www-form-urlencoded 的正文的一部分来使用 POST 请求。下面的示例使用 InfluxDB API 来查询您在编写数据中遇到的同一数据库。
curl -G 'http://localhost:8086/query?pretty=true' --data-urlencode "db=mydb" --data-urlencode "q=SELECT \"value\" FROM \"cpu_load_short\" WHERE \"region\"='us-west'"InfluxDB 返回 JSON:
{
"results": [
{
"statement_id": 0,
"series": [
{
"name": "cpu_load_short",
"columns": [
"time",
"value"
],
"values": [
[
"2015-01-29T21:55:43.702900257Z",
2
],
[
"2015-01-29T21:55:43.702900257Z",
0.55
],
[
"2015-06-11T20:46:02Z",
0.64
]
]
}
]
}
]
}
注意:将 pretty=true 附加到 URL 会启用漂亮打印的 JSON 输出。虽然这对于调试或直接使用 curl 等工具进行查询时很有用,但不建议将其用于生产用途,因为它会消耗不必要的网络带宽。
3.4、Downsample(下采样)并保留数据
InfluxDB 每秒可以处理数十万个数据点。长时间处理这么多数据可能会产生存储问题。一个自然的解决方案是对数据进行下采样;仅将高精度原始数据保留有限的时间,并将较低精度的汇总数据存储更长的时间。本指南描述了如何使用 InfluxQL 自动化数据下采样和过期数据的过程。要使用 Flux 和 InfluxDB 2.0 下采样和保留数据,请参阅使用 InfluxDB 任务处理数据。
3.4.1、定义
- 连续查询 (CQ): 是一种 InfluxQL 查询,可在数据库中自动并定期运行。 CQ 需要 SELECT 子句中的函数,并且必须包含 GROUP BY time() 子句。
- 保留策略 (RP) :是 InfluxDB 数据结构的一部分,用于描述 InfluxDB 保留数据的时间。 InfluxDB 将本地服务器的时间戳与数据的时间戳进行比较,并删除早于 RP 的 DURATION 的数据。单个数据库可以有多个 RP,并且每个数据库的 RP 都是唯一的。
3.4.2、样本数据
本节使用虚构的实时数据,每隔 10 秒通过电话和网站跟踪餐厅的食品订单数量。我们将这些数据存储在名为 food_data 的数据库或存储桶中、测量订单中以及电话和网站字段中。
样本:
name: orders
------------
time phone website
2016-05-10T23:18:00Z 10 30
2016-05-10T23:18:10Z 12 39
2016-05-10T23:18:20Z 11 56
3.4.3、目标
假设从长远来看,我们只关心每隔 30 分钟通过电话和网站获得的平均订单数量。在接下来的步骤中,我们使用 RP 和 CQ 来:
- 自动将 10 秒分辨率数据聚合为 30 分钟分辨率数据;
- 自动删除超过两小时的原始、十秒分辨率数据;
- 自动删除超过 52 周的 30 分钟分辨率数据;
3.4.4、数据库准备
在将数据写入数据库 food_data 之前,我们执行以下步骤。我们在插入任何数据之前执行此操作,因为 CQ 仅针对最近的数据运行;也就是说,时间戳不早于 now() 减去 CQ 的 FOR 子句的数据,或者如果 CQ 没有 FOR 子句,则 now() 减去 GROUP BY time() 间隔。
1、创建数据库
> CREATE DATABASE "food_data"2、创建一个两小时的DEFAULT保留策略
如果我们在向数据库写入点时不提供显式 RP,则 InfluxDB 将写入默认保留策略。我们让 DEFAULT RP 保留数据两个小时,因为我们希望 InfluxDB 自动将传入的 10 秒分辨率数据写入该 RP。
使用 CREATE RETENTION POLICY 语句创建一个 DEFAULT RP:
> CREATE RETENTION POLICY "two_hours" ON "food_data" DURATION 2h REPLICATION 1 DEFAULT该查询创建了一个名为 two_hours 的 RP,它存在于数据库 food_data 中。 two_hours 将数据保留两个小时 (2h) 的 DURATION,它是数据库 food_data 的默认 RP。复制因子 (REPLICATION 1) 是必需参数,但对于单节点实例,必须始终设置为 1。
注意:当我们在步骤 1 中创建 food_data 数据库时,InfluxDB 自动生成了一个名为 autogen 的 RP,并将其设置为数据库的 DEFAULT RP。 autogen RP 具有无限的保留期。对于上面的查询,RP two_hours 将 autogen 替换为 food_data 数据库的默认 RP。
3、创建52周的保留策略
接下来,我们要创建另一个保留策略,将数据保留 52 周,而不是数据库的默认保留策略 (RP)。最终,30 分钟的汇总数据将存储在此 RP 中。
使用 CREATE RETENTION POLICY 语句创建非默认保留策略:
> CREATE RETENTION POLICY "a_year" ON "food_data" DURATION 52w REPLICATION 1该查询创建了一个名为 a_year 的保留策略 (RP),它存在于数据库 food_data 中。 a_year 设置将数据保留 52 周 (52w) 的 DURATION。省略 DEFAULT 参数可确保 a_year 不是数据库 food_data 的 DEFAULT RP。也就是说,针对未指定 RP 的 food_data 的写入和读取操作仍将转到 two_hours RP(默认 RP)。
4、创建连续查询
现在我们已经设置了 RP,我们想要创建一个连续查询 (CQ),它会自动定期将 10 秒分辨率数据下采样到 30 分钟分辨率,然后将这些结果存储在不同的测量值中不同的保留政策。
使用 CREATE CONTINUOUS QUERY 语句生成 CQ:
> CREATE CONTINUOUS QUERY "cq_30m" ON "food_data" BEGIN
SELECT mean("website") AS "mean_website",mean("phone") AS "mean_phone"
INTO "a_year"."downsampled_orders"
FROM "orders"
GROUP BY time(30m)
END该查询在数据库 food_data 中创建了一个名为 cq_30m 的 CQ。 cq_30m 告诉 InfluxDB 计算测量订单和 DEFAULT RP two_hours 中两个字段网站和电话的 30 分钟平均值。它还告诉 InfluxDB 使用字段键 mean_website 和 mean_phone 将这些结果写入保留策略 a_year 中的测量 downsampled_orders。 InfluxDB 将在前 30 分钟内每 30 分钟运行一次此查询。
注意:请注意,我们完全限定了(即,我们使用语法“<retention_policy>”。“<measurement>”)INTO 子句中的度量。 InfluxDB 需要该语法才能将数据写入除 DEFAULT RP 之外的 RP。
5、结果
有了新的 CQ 和两个新的 RP,food_data 已准备好开始接收数据。在将数据写入我们的数据库并运行一段时间后,我们会看到两个测量值:orders 和 downsampled_orders。
> SELECT * FROM "orders" LIMIT 5
name: orders
---------
time phone website
2016-05-13T23:00:00Z 10 30
2016-05-13T23:00:10Z 12 39
2016-05-13T23:00:20Z 11 56
2016-05-13T23:00:30Z 8 34
2016-05-13T23:00:40Z 17 32
> SELECT * FROM "a_year"."downsampled_orders" LIMIT 5
name: downsampled_orders
---------------------
time mean_phone mean_website
2016-05-13T15:00:00Z 12 23
2016-05-13T15:30:00Z 13 32
2016-05-13T16:00:00Z 19 21
2016-05-13T16:30:00Z 3 26
2016-05-13T17:00:00Z 4 23订单中的数据是位于两小时 RP 中的原始、十秒分辨率数据。 downsampled_orders 中的数据是聚合的 30 分钟分辨率数据,受 52 周 RP 约束。请注意,downsampled_orders 中的第一个时间戳比订单中的第一个时间戳更早。这是因为 InfluxDB 已经从时间戳早于我们本地服务器的时间戳减去两个小时的订单中删除了数据(假设我们在 2016-05-14T00:59:59Z 执行了 SELECT 查询)。 InfluxDB 只会在 52 周后开始从 downsampled_orders 中删除数据。请注意,我们在第二个 SELECT 语句中完全限定了(即,我们使用语法“<retention_policy>”.“<measurement>”)downsampled_orders。我们必须在该查询中指定 RP 以选择驻留在除 DEFAULT RP 之外的 RP 中的数据。
默认情况下,InfluxDB 每 30 分钟检查一次强制执行一次 RP。在检查之间,订单可能包含超过两个小时的数据。 InfluxDB 检查以强制执行 RP 的速率是可配置的设置,请参阅数据库配置。
使用 RP 和 CQ 的组合,我们成功地设置了我们的数据库,以在有限的时间内自动保留高精度的原始数据,创建低精度的数据,并将低精度的数据存储更长的时间。现在您已经大致了解了这些功能如何协同工作,请查看有关 CQ 和 RP 的详细文档,了解它们可以为您做的所有事情。
3.5、硬件尺寸指南
3.5.1、单节点还是集群?
如果你想要一个完全开源的 InfluxDB 单节点实例,需要比上面列出的更少的写入、查询和唯一系列,并且不需要冗余,我们推荐 InfluxDB OSS。
注意:如果没有集群的冗余,当服务器不可用时,写入和查询会立即失败。
如果您的 InfluxDB 性能需要以下任何一项,单个节点(InfluxDB OSS)可能无法满足您的需求:
- 每秒超过 750,000 次字段写入;
- 每秒超过 100 个中等查询(请参阅查询指南);
- 超过 10,000,000 系列基数;
我们推荐 InfluxDB Enterprise,它支持跨多个服务器核心的多个数据节点(一个集群)。 InfluxDB Enterprise 在集群中分布多个数据副本,提供高可用性和冗余,因此不可用节点不会显着影响集群。
3.5.2、查询指南
查询复杂性因系统影响而异。建议基于适度的查询负载。
对于简单或复杂的查询,我们建议根据需要测试和调整建议的要求。查询复杂性由以下标准定义:
| Query complexity查询复杂度 | Criteria标准 |
|---|---|
| Simple简单的 | 很少或没有函数,也没有正则表达式 |
| 时间限制在几分钟、几小时或最多 24 小时 | |
| 通常在几毫秒到几十毫秒内执行 | |
| Moderate缓和 | 有多个函数和一两个正则表达式 |
| 也可能有 GROUP BY 子句或采样多个周的时间范围 | |
| 通常在几百或几千毫秒内执行 | |
| Complex复杂的 | 具有多个聚合或转换函数或多个正则表达式 |
| 可以采样几个月或几年的非常大的时间范围 | |
| 通常需要几秒钟才能执行 |
3.5.3、InfluxDB OSS指南
在本地连接的固态驱动器 (SSD) 上运行 InfluxDB。其他存储配置的性能较低,可能无法从正常处理中的小中断中恢复。估计的准则包括每秒写入次数、每秒查询次数以及唯一序列数、CPU、RAM 和 IOPS(每秒输入/输出操作数)。
| vCPU 或 CPU | RAM | IOPS | Writes per second 每秒写入次数 | Queries* per second 每秒查询数* | Unique series 独特系列 |
|---|---|---|---|---|---|
| 2-4核 | 2-4 GB | 500 | < 5,000 | < 5 | < 100,000 |
| 4-6核 | 8-32 GB | 500-1000 | < 250,000 | < 25 | < 1,000,000 |
| 8+核 | 32+ GB | 1000+ | > 250,000 | > 25 | > 1,000,000 |
中等查询的每秒查询数。查询对系统的影响差异很大。对于简单或复杂的查询,我们建议根据需要测试和调整建议的要求。有关详细信息,请参阅查询指南。
3.5.4、存储:类型、数量和配置
1、存储量和IOPS
考虑您需要的存储类型和数量。 InfluxDB 旨在运行在固态驱动器 (SSD) 和内存优化的云实例上,例如 AWS EC2 R5 或 R4 实例。 InfluxDB 未在硬盘驱动器 (HDD) 上进行测试。为获得最佳结果,InfluxDB 服务器的存储必须至少具有 1000 IOPS 以确保恢复和可用性。我们建议至少 2000 IOPS 以便在停机后快速恢复集群数据节点。
2、字节和压缩
数据库名称、测量值、标签键、字段键和标签值仅存储一次,并且始终作为字符串存储。为每个点存储字段值和时间戳。非字符串值大约需要三个字节。字符串值需要可变空间,由字符串压缩决定。
3、分离wal和data目录
在生产环境中运行 InfluxDB 时,将 wal 目录和 data 目录存储在不同的存储设备上。这种优化显着减少了重写入负载下的磁盘争用——如果写入负载变化很大,这是一个重要的考虑因素。如果写入负载的变化不超过 15%,则可能不需要优化。
3.6、计算百分比
使用 Flux 或 InfluxQL 计算查询中的百分比。
3.6.1、Flux
Flux 可让您执行简单的数学方程式,例如计算百分比。
1、查询中的基本计算
在 Flux 查询中执行任何数学运算时,您必须完成以下步骤:
- 指定要查询的存储桶和要查询的时间范围。
- 按度量、字段和其他适用标准过滤您的数据。
- 使用以下函数之一对齐一行中的值(在 Flux 中执行数学运算所需):① 要从多个数据源查询,请使用 join() 函数;② 要从同一数据源查询,请使用 pivot() 函数。
数据变量:为了缩短示例,我们将一个基本的 Flux 查询存储在一个数据变量中以供重用。
这是 Flux 中的样子:
// Query data from the past 15 minutes pivot fields into columns so each row
// contains values for each field
data = from(bucket:"your_db/your_retention_policy")
|> range(start: -15m)
|> filter(fn: (r) => r._measurement == "measurement_name" and r._field =~ /field[1-2]/)
|> pivot(rowKey:["_time"], columnKey: ["_field"], valueColumn: "_value")
现在每一行都包含执行数学运算所需的值。例如,要添加两个字段键,从上面创建的数据变量开始,然后使用 map() 重新映射每一行中的值。
data
|> map(fn: (r) => ({ r with _value: r.field1 + r.field2}))
注意:Flux 支持基本的数学运算符,例如 +、-、/、* 和 ()。例如,要从 field1 中减去 field2,请将 + 更改为 -。
2、从两个字段计算百分比
使用上面创建的数据变量,然后使用 map() 函数将一个字段除以另一个,乘以 100,然后添加一个新的百分比字段来存储百分比值。
data
|> map(fn: (r) => ({
_time: r._time,
_measurement: r._measurement,
_field: "percent",
_value: field1 / field2 * 100.0
}))
注意:在本例中,field1 和 field2 是浮点值,因此乘以 100.0。对于整数值,乘以 100 或使用 float() 函数将整数转换为浮点数。
3、使用聚合函数计算百分比
使用 aggregateWindow() 按时间窗口化数据并在每个窗口上执行聚合函数。
from(bucket:"<database>/<retention_policy>")
|> range(start: -15m)
|> filter(fn: (r) => r._measurement == "measurement_name" and r._field =~ /fieldkey[1-2]/)
|> aggregateWindow(every: 1m, fn:sum)
|> pivot(rowKey:["_time"], columnKey: ["_field"], valueColumn: "_value")
|> map(fn: (r) => ({ r with _value: r.field1 / r.field2 * 100.0 }))
4、计算每个苹果品种占总重量的百分比
使用模拟的苹果架数据来跟踪一天中苹果的重量(按类型)。
导入样本数据:
influx -import -path=path/to/apple_stand.txt -precision=ns -database=apple_stand使用以下查询计算每个给定时间点每个品种占总重量的百分比。
from(bucket:"apple_stand/autogen")
|> range(start: 2018-06-18T12:00:00Z, stop: 2018-06-19T04:35:00Z)
|> filter(fn: (r) => r._measurement == "variety")
|> pivot(rowKey:["_time"], columnKey: ["_field"], valueColumn: "_value")
|> map(fn: (r) => ({ r with
granny_smith: r.granny_smith / r.total_weight * 100.0 ,
golden_delicious: r.golden_delicious / r.total_weight * 100.0 ,
fuji: r.fuji / r.total_weight * 100.0 ,
gala: r.gala / r.total_weight * 100.0 ,
braeburn: r.braeburn / r.total_weight * 100.0 ,}))
5、计算每个品种每小时总重的平均百分比
使用前面示例中的苹果摊位数据,使用以下查询计算每个品种每小时占总重量的平均百分比。
from(bucket:"apple_stand/autogen")
|> range(start: 2018-06-18T00:00:00.00Z, stop: 2018-06-19T16:35:00.00Z)
|> filter(fn: (r) => r._measurement == "variety")
|> aggregateWindow(every:1h, fn: mean)
|> pivot(rowKey:["_time"], columnKey: ["_field"], valueColumn: "_value")
|> map(fn: (r) => ({ r with
granny_smith: r.granny_smith / r.total_weight * 100.0,
golden_delicious: r.golden_delicious / r.total_weight * 100.0,
fuji: r.fuji / r.total_weight * 100.0,
gala: r.gala / r.total_weight * 100.0,
braeburn: r.braeburn / r.total_weight * 100.0
}))
3.6.2、InfluxQL
InfluxQL 允许您执行简单的数学方程式,这使得使用测量中的两个字段计算百分比非常简单。但是,您需要注意一些注意事项。
1、查询中的基本计算
SELECT 语句支持使用基本的数学运算符,例如 +、-、/、*、() 等。
-- Add two field keys
SELECT field_key1 + field_key2 AS "field_key_sum" FROM "measurement_name" WHERE time < now() - 15m
-- Subtract one field from another
SELECT field_key1 - field_key2 AS "field_key_difference" FROM "measurement_name" WHERE time < now() - 15m
-- Grouping and chaining mathematical calculations
SELECT (field_key1 + field_key2) - (field_key3 + field_key4) AS "some_calculation" FROM "measurement_name" WHERE time < now() - 15m2、计算查询中的百分比
使用基本的数学函数,您可以通过将一个字段值除以另一个字段值并将结果乘以 100 来计算百分比:
SELECT (field_key1 / field_key2) * 100 AS "calculated_percentage"
FROM "measurement_name" WHERE time < now() - 15m3、使用聚合函数计算百分比
如果在百分比计算中使用聚合函数,则必须使用聚合函数引用所有数据。您不能混合聚合和非聚合数据。所有聚合函数都需要一个 GROUP BY time() 子句来定义数据点被分组和聚合的时间间隔。
SELECT (sum(field_key1) / sum(field_key2)) * 100 AS "calculated_percentage" FROM "measurement_name" WHERE time < now() - 15m GROUP BY time(1m)4、样本数据
导入样本数据:
influx -import -path=path/to/apple_stand.txt -precision=ns -database=apple_stand5、计算每个苹果品种总重量的百分比
以下查询计算每个给定时间点每个品种占总重量的百分比。
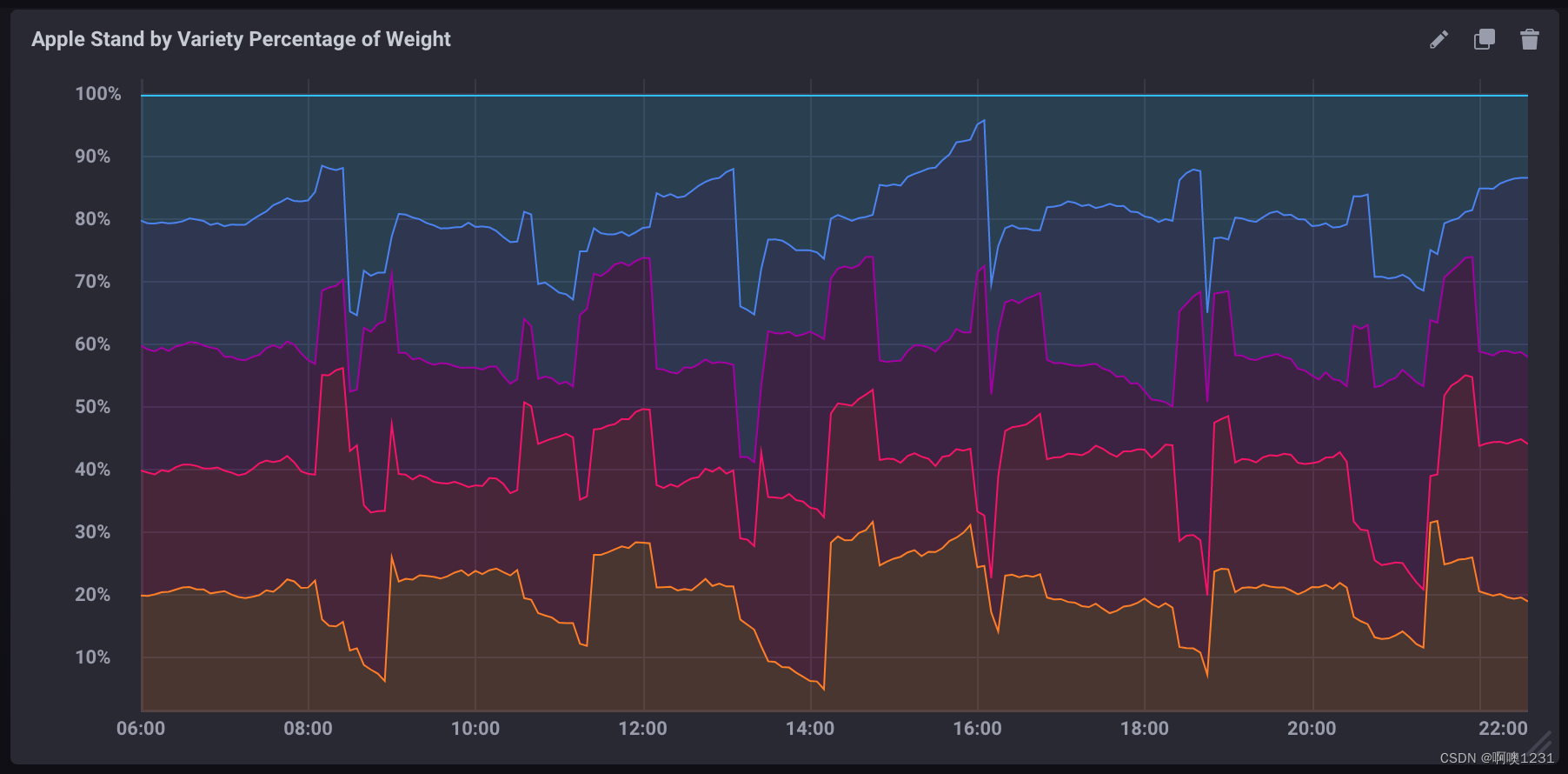
SELECT
("braeburn"/total_weight)*100,
("granny_smith"/total_weight)*100,
("golden_delicious"/total_weight)*100,
("fuji"/total_weight)*100,
("gala"/total_weight)*100
FROM "apple_stand"."autogen"."variety"如果在 Chronograf 中可视化为堆叠图,它看起来像:
6、计算每个品种的总百分比
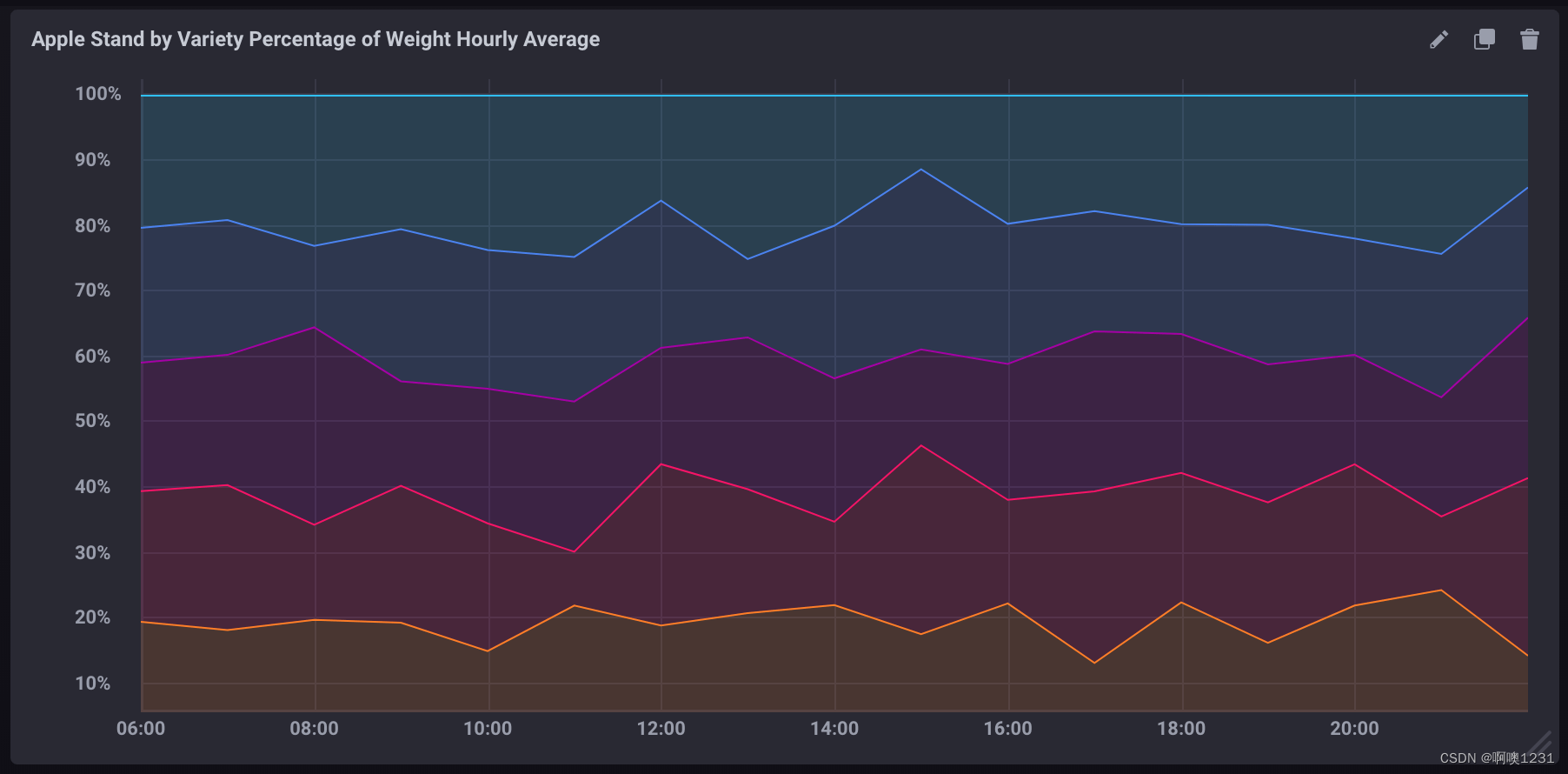
以下查询计算每个品种每小时占总重量的平均百分比。
SELECT
(mean("braeburn")/mean(total_weight))*100,
(mean("granny_smith")/mean(total_weight))*100,
(mean("golden_delicious")/mean(total_weight))*100,
(mean("fuji")/mean(total_weight))*100,
(mean("gala")/mean(total_weight))*100
FROM "apple_stand"."autogen"."variety"
WHERE time >= '2018-06-18T12:00:00Z' AND time <= '2018-06-19T04:35:00Z'
GROUP BY time(1h)请注意有关此查询的以下内容:
- 它使用聚合函数 (mean()) 来提取所有数据。
- 它包括一个 GROUP BY time() 子句,它将数据聚合到 1 小时块中。
- 它包括一个明确限制的时间窗口。没有它,聚合函数非常耗费资源。
如果在 Chronograf 中可视化为堆叠图,它看起来像:
3.7、将InfluxDB OSS实例迁移到InfluxDB Enterprise集群
将正在运行的 InfluxDB 开源 (OSS) 实例迁移到 InfluxDB Enterprise 集群。迁移将所有用户从 OSS 实例转移到 InfluxDB Enterprise 集群。
3.7.1、将OSS实例迁移到InfluxDB Enterprise
完成以下任务,将数据从 OSS 迁移到 InfluxDB Enterprise 集群,而不会停机或丢失数据。
- 将 InfluxDB OSS 和 InfluxDB Enterprise 升级到最新的稳定版本。
- Upgrade InfluxDB OSS升级 InfluxDB OSS
- Upgrade InfluxDB Enterprise升级 InfluxDB 企业版
- 在每个元节点和每个数据节点上,将您的 OSS 实例的 IP 和主机名添加到 /etc/hosts 文件中。这将允许节点与 OSS 实例进行通信。
- 在 OSS 实例上,使用带有 -portable 标志的 influxd backup 命令从 OSS 获取可移植备份:
influxd backup -portable -host <IP address>:8088 /tmp/mysnapshot - 通过运行以下命令恢复集群上的备份:
注意:InfluxDB Enterprise 使用 influxd-ctl 实用程序来备份和恢复数据。有关详细信息,请参阅 influxd-ctl 和恢复。 - 为避免数据丢失,请在完成剩余步骤的同时对 OSS 和 Enterprise 进行双重写入。这使 OSS 和集群保持活动状态以进行测试和验收工作。有关更多信息,请参阅使用 InfluxDB API 写入数据。
- 从备份开始到双写开始时从 OSS 导出数据。例如,如果您在 2020-07-19T00:00:00.000Z 进行备份,并在 2020-07-19T23:59:59.999Z 开始将数据写入 Enterprise,您将运行以下命令:
influx_inspect export -compress -start 2020-07-19T00:00:00.000Z -end 2020-07-19T23:59:59.999Z` - 将数据导入企业。
- 验证数据是否成功迁移到您的企业集群。看:
- Query data with the InfluxDB API使用 InfluxDB API 查询数据
- View data in Chronograf在 Chronograf 中查看数据
- 接下来,停止写入 OSS 实例,并将其删除。
停止写入并移除OSS:
- 停止对 InfluxDB OSS 实例的所有写入。
- 在 InfluxDB OSS 实例服务器上停止 influxdb 服务。
sudo service influxdb stop - 仔细检查服务是否已停止。以下命令不应返回任何内容:
ps ax | grep influxd - 删除 InfluxDB OSS 包。
sudo apt-get remove influxdb
3.7.2、重新平衡集群
- 使用 ALTER RETENTION POLICY 语句将所有现有保留策略的复制因子增加到集群中数据节点的数量。
- 手动重新平衡集群以满足现有分片所需的复制因子。
- 如果您使用的是 Chronograf,请将您的 Enterprise 实例添加为新数据源。















 287
287











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









