






今天重写一下pandas,之前写过两篇关于pandas的文章一直觉得写的不够好。现在结合工作内容对pandas有了更深的理解。本文只讲解了我在工作中常用的函数,详细的用法可以看下方的往期文章。
Pandas的使用 pandas的增删查改安装
pip install pandas
因为pandas还依赖了其他的包需要自行下载,反正缺什么就pip什么就好了。
目录
1、pandas在工作中的使用
2、常用函数
1、pandas在工作中的使用
在工作中我用到最多的就是把非标准的数据从另一个容器中读取出来并用python进行处理,最后作为数据源存入Excel中,供其他Excel调用,如下图。

一开始我学pandas学了一堆函数,结果是现在基本都忘了。我个人使用pandas最多的是读取、存储,至于对数据的操作全部都是用python的语法进行操作的,接下来还是介绍一下常用的函数吧。
2、常用函数
先创建一个excel文件
import pandas as pd
data = {'city': ['北京', '上海', '广州', '深圳'],
'2018': [33105, 36011, 22859, 24221]}
data = pd.DataFrame(data)
data.to_excel('excel练习.xlsx', index=False)
2.1、读取数据
df = pd.read_excel('excel练习.xlsx')
print(df)
print(type(df))
print(df.values)
print(type(df.values))
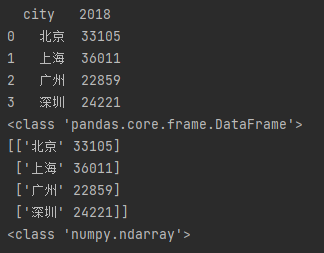
DataFrame类型用python操作不太方便,所以使用values转为numpy数组的形式(这和列表很相似,可以像列表哪样操作)。
注意:
在读取数据时可以指定一列的数据类型,最近我遇到一个问题如下图,我将数据读出来再存入文本类型的001就变为了数字的1。

想要解决这个问题只需要在读数据时添加参数converters指定编号这列为字符型。
pd.read_excel(file_path, converters={'编号': str})
读取某一列的数据
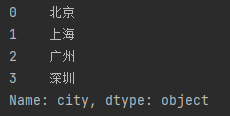
df = pd.read_excel('excel练习.xlsx')
data = df['city']
print(data)
运行结果:
2.2、存储数据
data = {'city': ['北京', '上海', '广州', '深圳'],
'2018': [33105, 36011, 22859, 24221]}
data = pd.DataFrame(data)
data.to_excel('excel练习.xlsx', index=False)
存储数据很简单,只需要将数据处理成这样,再转为DataFrame类型才可存储。
2.3、删除数据
删除包含某值的行、删除指定行/列、去重、去0值、去空值
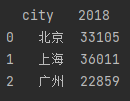
2.3.1、删除包含某值的行
data = df[df.city != '深圳']
2.3.2、删除指定行drop()(删0、1行)
data = df.drop([0, 1], axis=0)

2.3.3、删除指定列drop()
data = df.drop(['2018'], axis=1)
2.3.4、去重drop_duplicates()
data.drop_duplicates(['city'])
data.drop_duplicates(['city', '2018'], keep='last')
对指定列(这个列可以包含多个元素如:['city', '2018'])去重,默认保留第一次出现的数据,但是添加参数keep='last'可以保留最后一次出现的数据。
2.3.5、去0值
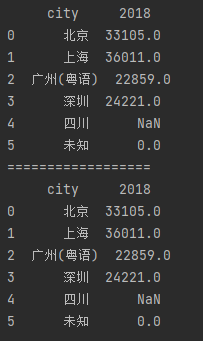
data2 = {'city': ['北京', '上海', '广州(粤语)', '深圳', '四川', '未知', 0],
'2018': [33105, 36011, 22859, 24221, np.nan, 0, 0]}
data2 = pd.DataFrame(data2)
# 方法一
df = data2[(data2.T != 0).any()]
# 方法二
df2 = data2.loc[(data2 != 0).any(1)]
print(df)
print('==================')
print(df2)
讲解:
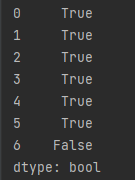
any()方法会判断每行是否符合条件,如下:
data2 = {'city': ['北京', '上海', '广州(粤语)', '深圳', '四川', '未知', 0],
'2018': [33105, 36011, 22859, 24221, np.nan, 0, 0]}
data2 = pd.DataFrame(data2)
df = (data2.T != 0).any()
指定列有0值就删除整行、参考2.3.1即可
2.3.6、去空值dropna()
data2 = {'city': ['北京', '上海', '广州(粤语)', '深圳', '四川'],
'2018': [33105, 36011, 22859, 24221, np.nan]}
data2 = pd.DataFrame(data2)
print(data2.dropna())
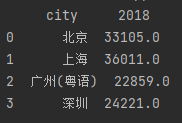
不加任何参数时只要某行包含了空值整行都会被删除。
添加axis时就可以删除包含空值的行/列
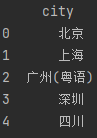
data2 = {'city': ['北京', '上海', '广州(粤语)', '深圳', '四川'],
'2018': [33105, 36011, 22859, 24221, np.nan]}
data2 = pd.DataFrame(data2)
print(data2.dropna(axis=1))
2.4、追加数据
具体可以看看
coder-谢公子:Python | Pandas如何追加写入Excel














 460
460

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









