







0、参考资料
一、题目描述
实现 LRUCache 类:
- LRUCache(int capacity) 以正整数作为容量 capacity 初始化 LRU 缓存
- int get(int key) 如果关键字 key 存在于缓存中,则返回关键字的值,否则返回 -1 。
- void put(int key, int value) 如果关键字已经存在,则变更其数据值;如果关键字不存在,则插入该组「关键字-值」。当缓存容量达到上限时,它应该在写入新数据之前删除最久未使用的数据值,从而为新的数据值留出空间。
输入
[“LRUCache”, “put”, “put”, “get”, “put”, “get”, “put”, “get”, “get”, “get”]
[[2], [1, 1], [2, 2], [1], [3, 3], [2], [4, 4], [1], [3], [4]]
输出
[null, null, null, 1, null, -1, null, -1, 3, 4]
解释
LRUCache lRUCache = new LRUCache(2);
lRUCache.put(1, 1); // 缓存是 {1=1}
lRUCache.put(2, 2); // 缓存是 {1=1, 2=2}
lRUCache.get(1); // 返回 1
lRUCache.put(3, 3); // 该操作会使得关键字 2 作废,缓存是 {1=1, 3=3}
lRUCache.get(2); // 返回 -1 (未找到)
lRUCache.put(4, 4); // 该操作会使得关键字 1 作废,缓存是 {4=4, 3=3}
lRUCache.get(1); // 返回 -1 (未找到)
lRUCache.get(3); // 返回 3
lRUCache.get(4); // 返回 4
二、代码思路
- 使用栈来解决问题
使用栈,会存在大量的内存复制,以及找元素产生的开销;
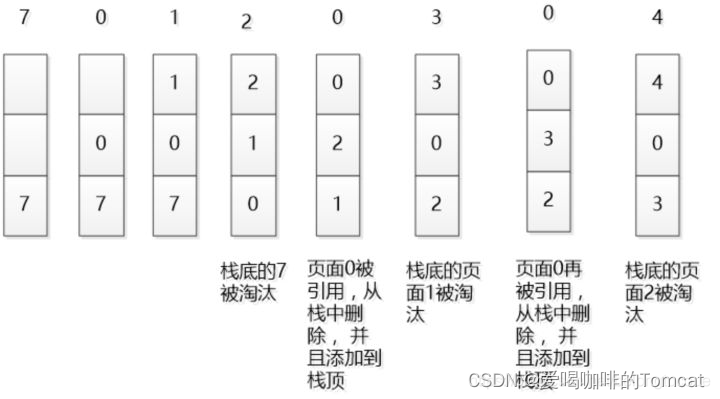
首先、先访问的元素放到栈顶,栈底永远放的是最近最少被访问的元素。
其次、如果栈中存在要访问的元素,还要从栈中,取出来该元素,并放到栈底部,其余元素依次重新排列。
最后,如果我们要增加元素,也是首先把栈底元素删掉,然后将新加的元素放到栈顶部。
- 使用LinkedListMap数据结构来解决问题
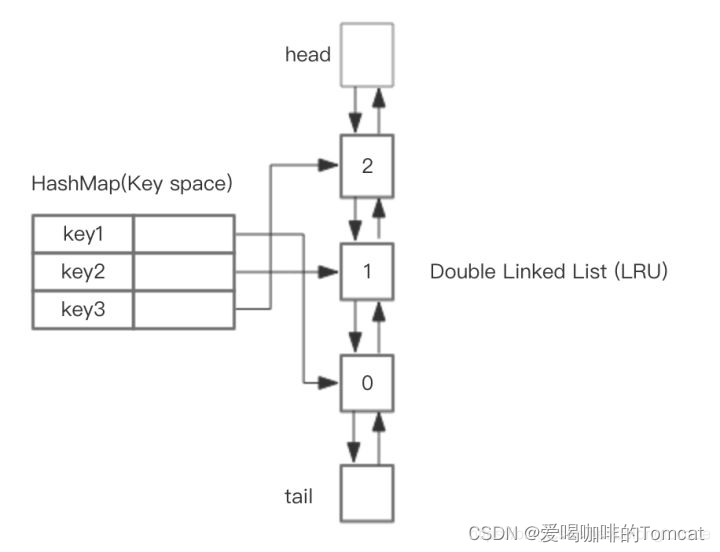
LinkedHashMap 是hash表 + 双向链表
1、我们可以通过hash值,很快找到我们要访问的缓存。
2、我们在删除缓存的时候,很容易通过hash key 找到该缓存所在位置,比如 1 ,然后我们通过链表的指针,能够不用移动内存,删掉1;同时,我们也可以通过tail指针,很容易找到,链表的尾部。
3、我们在访问缓存的时候,可以很快找到缓存,然后我们先把该位置缓存通过指针操作删掉,然后通过tail指针找到链尾,然后把最近新访问的缓存,加到链尾部分。其实LinkedHashMap 底层代码也是这么写的:
其中,after 和 before 指针是指Node节点 extends Entry 的两个指针域,也就是prev和next指针,共同维护双向链表。
https://www.cnblogs.com/xiaoxi/p/6170590.html
/**
* 通过key获取value,与HashMap的区别是:当LinkedHashMap按访问顺序排序的时候,会将访问的当前节点移到链表尾部(头结点的前一个节点)
*/
public V get(Object key) {
// 调用父类HashMap的getEntry()方法,取得要查找的元素。
Entry<K,V> e = (Entry<K,V>)getEntry(key);
if (e == null)
return null;
// 记录访问顺序。
e.recordAccess(this);
return e.value;
}
/**
* 在HashMap的put和get方法中,会调用该方法,在HashMap中该方法为空
* 在LinkedHashMap中,当按访问顺序排序时,该方法会将当前节点插入到链表尾部(头结点的前一个节点),否则不做任何事
*/
void recordAccess(HashMap<K,V> m) {
LinkedHashMap<K,V> lm = (LinkedHashMap<K,V>)m;
//当LinkedHashMap按访问排序时
if (lm.accessOrder) {
lm.modCount++;
//移除当前节点
remove();
//将当前节点插入到头结点前面
addBefore(lm.header);
}
}
/**
* 移除节点,并修改前后引用
*/
private void remove() {
before.after = after;
after.before = before;
}
private void addBefore(Entry<K,V> existingEntry) {
after = existingEntry;
before = existingEntry.before;
before.after = this;
after.before = this;
}
4、我们也有head指针,所以能够很快找到头节点,也能很快删除头节点,头部放的元素都是最近没被访问过的元素。
5、LinkedHashMap底层都给我们封装好了
- 1、可以通过boolean accessOrder,判断访问顺序,是按照插入顺序访问,还是按照LRU缓存的顺序访问。(也就是最新访问放到链尾,没访问的放到链头)
总结一下:
-
LinkedHashMap是由HashMap + 双向链表组成的。
-
LHM插入元素可以选择按顺序插入,按照访问顺序插入(LRU算法的实现)。
-
LHM访问元素的时候会将tail指针变更为最新访问的元素。实现方法在LHM中的afterNodeAccess
- 代码实现就是修改访问元素前后指针,然后把tail指针指向该节点。也就是将原来节点移动到tail。
-
LHM删除元素的时候会把指定元素删除,并通过afterNodeRemoval方法来维护LRU算法。
- 首先,维护双链表,把双链表指针修改掉。维护双链表,也就是删除该节点。
- 其次,如果修改的是tail 或 head指针,那么也要重新给头尾指针赋值。维护LRU。
-
LHM中大多方法都是用的父类HM,但是最重要的维护双链表和LRU的算法是它自己实现的,通过多态调用。也就是上述的after等方法。
三、代码题解
package leetcode;
import java.rmi.server.SkeletonMismatchException;
import java.util.Iterator;
import java.util.LinkedHashMap;
import java.util.Map;
import java.util.Set;
/*
* @author lzy
* @version 1.0
* */
public class LRU_ {
public static void main(String[] args) {
LinkedHashMap<String, String> linkedHashMap = new LinkedHashMap(4, 1, true);
//初始化缓存
linkedHashMap.put("1", "1");
linkedHashMap.put("2", "2");
linkedHashMap.put("3", "3");
linkedHashMap.put("4", "4");
//访问缓存
linkedHashMap.get("1");
//加入新的缓存,会把最近没被访问的缓存删掉,如果容量不够的话
linkedHashMap.put("5", "5");
linkedHashMap.get("2");
//集合不能按索引读元素,List集合才可以。
//如何获取LHM的头节点
linkedHashMap.remove(linkedHashMap.keySet().iterator().next());
loopLinkedHashMap(linkedHashMap);
/*测试LRU缓存的LinkedHashMap实现*/
LRU_ lru_ = new LRU_(2);
lru_.put(1, 1);
lru_.put(2, 2);
lru_.get(1);
lru_.put(3, 3);
}
public static void loopLinkedHashMap(LinkedHashMap<String, String> linkedHashMap) {
Set<Map.Entry<String, String>> entries = linkedHashMap.entrySet();
Iterator<Map.Entry<String, String>> iterator = entries.iterator();
while (iterator.hasNext()) {
System.out.println(iterator.next().getKey() + " ");
}
return;
}
LinkedHashMap<Integer, Integer> linkedHashMap;
int capacity;
public LRU_(int capacity) {
this.capacity = capacity;
this.linkedHashMap = new LinkedHashMap<>(capacity, 1, true);
}
public int get(int key) {
return linkedHashMap.get(key);
}
public void put(int key, int value) {
if (linkedHashMap.get(key) != null) {
linkedHashMap.put(key, value);
return;
}
if (linkedHashMap.keySet().size() == capacity) {
//这里没有考虑到这种情况:
//put 1,5 和 put 1,2;如果key已存在则更换其值
//那么我们考虑一下: 容量为2,先加入2,6 再加入1,5 ,再加入1,2,此时2,6就被删掉了,1,5被替换
//这显然是不对的
linkedHashMap.remove(linkedHashMap.keySet().iterator().next());
linkedHashMap.put(key, value);
} else {
linkedHashMap.put(key, value);
}
}
}















 236
236











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









