






目录
深度学习Bert文本分类理论部分
机器学习方法:朴素贝叶斯、SVM、LR、KNN
深度学习方法:FastText、TextFCNN、TextRNN、TextRCNN、DPCNN、BERT
基本流程
一、文本预处理
1.文本去噪
2.文本分词
3.去停用词(the a 了 的)
4.文本还原 (playing --play)
5.文本消歧
6.文本替换
二、特征提取
1.词频特征
2.词性特征
3.语法特征
4.主题特征
5.N-Gram
6.TF-IDF
三、文本表示
1.词袋模型
2.One-Hot
3.Word2Vec
4.GloVe
5.EMLO
6.BERT
四、分类模型
1.机器学习
2.深度学习
3.CNN
4.RNN
5.Attention
6.GNN
神经网络中的数据格式
数据表2D数据--样本数,特征
序列3D数据--样本数,步长,特征 (如:100条推文,每条长度限制280,特征数128,则为(100,280,128))
图像4D数据--样本数,宽,高,通道数
视频5D数据--样本数,帧,宽,高,通道数
文本分类理论基础
RNN--Seq2Seq--Attention--Transformer--Bert
-
RNN
-
Seq2seq encoder-C-decoder 存在以下问题,随着序列的增多,固定维度的C能保留的信息有限,解码过程C对所有的输出贡献是相同的,这是不好的,因为C对不同的输出贡献应该不同
-
Attention机制: 存在以下问题,不能并行化,不能看到所有的输入信息,引出SelfAttention
-
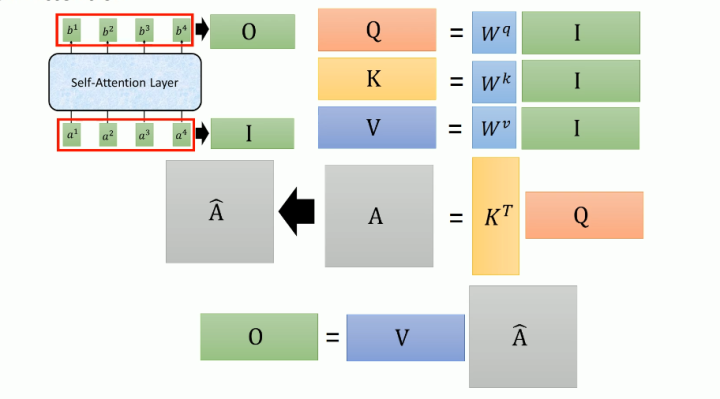
SelfAttention: QKV Q查询向量 K被查向量 V信息向量 Q对每个K做attention,其实就是一些列矩阵运算,下图比较容易理解。
文本分类实战--代码、结果
Bert中文文本分类的实战
代码目录:

bert——pretrained 存放官方下载好的预训练模型,本次使用的是小型bert-base
models存放自己写的模型
pytorch_pretrained 存放bert源码,里面包含各种tokenizer等包
THUCNews存放数据和训练好的模型
model模型部分:
1.首先设定需要的参数类
##配置类
class Config(object):
'''
配置参数
'''
def __init__(self,dataset):
self.model_name = 'RenBert'
#传入训练集测试集和验证集
self.train_path = dataset + '/data/train.txt'
self.test_path = dataset + '/data/test.txt'
self.dev_path = dataset + '/data/dev.txt'
# dataset
self.datasetpkl = dataset + '/data/dataset.pkl'
#传入类别
self.class_list = [x.strip() for x in open(dataset + '/data/class.txt').readlines()]
#训练结果保存
self.save_path = dataset + '/saved_dict/' + self.model_name + '.ckpt'
#设备配置
self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
#超过1000batch效果没有提升,提前结束训练
self.require_improvement = 1000
self.num_classes = len(self.class_list)
self.num_epochs = 3
self.batch_size = 128 ##一次输入128句话
self.learning_rate = 1e-5
##每句话长度,长切短补
self.pad_size = 32
##bert预训练模型的路径
self.bert_path = 'bert_pretrain'
#bert的tokenizer
self.tokenizer = BertTokenizer.from_pretrained(self.bert_path)
#参数为bert_config.json中
self.hidden_size = 7682.模型构建类
# ##模型构建类
class Model(nn.Module):
def __init__(self,config):
super(Model, self).__init__()
self.bert = BertModel.from_pretrained(config.bert_path) ##模型的加载路径
for param in self.bert.parameters():
param.requires_grad = True ##是否进行Finetune
self.fc = nn.Linear(config.hidden_size,config.num_classes)
def forward(self,x): ##forward
##x的格式,x[ids,seq_len,mask],(通过查看BertModel的输入)
context = x[0] ##shape[128,32]
mask = x[2] ##shape[128,32]
_,pooled = self.bert(context, attention_mask=mask, output_all_encoded_layers=True) ## 不是bert中的12层都输出,只输出最后一层shape[128,768]
out = self.fc(pooled) #shape[128,10] 类别数为10
return out
3.utils存放的主要为:数据迭代器类(其他暂不做描述)迭代器只在调用时生成当前需要的这部分数据,而不是一次性生成所有数据;我们知道,程序在运行时会加载所有需要的数据,而训练Bert模型时每个epoch都需要打乱数据集内部顺序,如果一次性生成所有epoch需要的数据并加载到内存,很容易出现内存不足的情况;而使用迭代器就能够极大的降低内存的占用。迭代器的原理是按顺序在数据集中每次返回batch_size个数据,如果最后的数据量不足batch_size,则将剩余的数据全部返回;这里没有添加 shuffle,后期会改进(没有shuffle会使模型记录样本之间的先后关系)
from tqdm import tqdm
import torch
import time
from datetime import timedelta
import pickle as pkl
import os
PAD, CLS = '[PAD]', '[CLS]'
def load_dataset(file_path,config):
contents=[]
##1打开文件,删除空格 2.内容和标签用split('\t')划分 3.内容token(分词,分字) 4.cls+内容token 5.mask 6.token2id
with open(file_path,'r',encoding='UTF-8') as f:
for line in tqdm(f):
line = line.strip()
if not line:
continue
content,label= line.split('\t')
token = config.tokenizer.tokenize(content)
token =[CLS] + token #每个句子都添加了一个标志位
seq_len = len(token)
mask = []
token_ids = config.tokenizer.convert_tokens_to_ids(token)
##字符长度处理。小于32,大于32
pad_size = config.pad_size
#原长为20,小于32的部分用0填充,0-20是1,21-32是0,大于32的句子,截断0-32填充1
if pad_size:
if len(token) < pad_size:
mask = [1]*len(token_ids) + [0]*(pad_size - len(token))
token_ids = token_ids + ([0] * (pad_size-len(token)))
else:
mask = [1] * pad_size
token_ids =token_ids[:pad_size]
seq_len = pad_size
contents.append((token_ids,int(label),seq_len,mask))
return contents
def bulid_dataset(config):
"""
返回值 train, dev ,test
:param config:
:return:
"""
if os.path.exists(config.datasetpkl):
dataset = pkl.load(open(config.datasetpkl, 'rb'))
train = dataset['train']
dev = dataset['dev']
test = dataset['test']
else:
train = load_dataset(config.train_path, config)
dev = load_dataset(config.dev_path, config)
test = load_dataset(config.test_path, config)
dataset = {}
dataset['train'] = train
dataset['dev'] = dev
dataset['test'] = test
pkl.dump(dataset, open(config.datasetpkl, 'wb'))
return train, dev, test
##创建数据迭代器
'''
迭代器只在调用时生成当前需要的这部分数据,而不是一次性生成所有数据;我们知道,程序在运行时会加载所有需要的数据,
而训练Bert模型时每个epoch都需要打乱数据集内部顺序,如果一次性生成所有epoch需要的数据并加载到内存,
很容易出现内存不足的情况;而使用迭代器就能够极大的降低内存的占用
'''
##迭代器的原理是按顺序在数据集中每次返回batch_size个数据,如果最后的数据量不足batch_size,则将剩余的数据全部返回
class DatasetIterator(object):
def __init__(self,dataset,batch_size,device):
self.dataset = dataset
self.batch_size = batch_size
self.device = device
self.index = 0
self.n_batches =len(dataset)//batch_size
self.residue = False #记录batch是否为整数
if len(dataset)%batch_size!=0:
self.residue = True
def __next__(self):
if self.residue and self.index==self.n_batches:
batches = self.dataset[self.index*self.batch_size:len(self.dataset)]
self.index += 1
batches=self._to_tensor(batches)
return batches
elif self.index>self.n_batches:
self.index=0
raise StopIteration
else:
batches = self.dataset[self.index*self.batch_size:(self.index+1)*self.batch_size]
self.index+=1
batches = self._to_tensor(batches)
return batches
def _to_tensor(self, datas):
x = torch.LongTensor([item[0] for item in datas]).to(self.device) # 样本
y = torch.LongTensor([item[1] for item in datas]).to(self.device) # 标签
seq_len = torch.LongTensor([item[2] for item in datas]).to(self.device) # 序列真实长度
mask = torch.LongTensor([item[3] for item in datas]).to(self.device) # 序列真实长度
return (x, seq_len, mask), y ##x的格式,x[ids,seq_len,mask],(通过查看BertModel的输入)
def __iter__(self):
return self
def __len__(self):
if self.residue:
return self.n_batches
else:
return self.n_batches + 1
def bulid_iterator(dataset, config):
iter = DatasetIterator(dataset, config.batch_size, config.device)
return iter
def get_time_dif(start_time):
"""
获取已经使用的时间
:param start_time:
:return:
"""
end_time = time.time()
time_dif = end_time - start_time
return timedelta(seconds=int(round(time_dif)))4.train.py模型的训练过程
主要过程:1.根据配置文件、设置梯度衰减的参数 2.配置优化器 3.开启train()
对每个样本需要进行的操作 4.得到模型输出 5.清空梯度 6.计算损失函数 7.损失函数反向传播到每个参数的梯度 8.梯度参数更更新 9.计算每个样本的预测值 10.计算预测的准确率 11.准确率,损失小于历史最小损失,保存模型参数 12.loss长时间没有更新,自动结束训练 13.最后test(),测试模型效果
第一部分函数def train():
def train(config,model,train_iter,dev_iter,test_iter):
'''
:param config:
:param model:
:param train_iter:
:param dev_iter:
:param test_iter:
:return:
'''
start_time=time.time()
model.train() ##设置为训练模式
##列出所有参数
param_optimizer=list(model.named_parameters())
##不需要衰减的参数
no_decay=['bias','LayerNorm.bias','LayerNorm.weight']
##1指定哪些参数需要更新,哪些参数不需要更新
optimizer_grouped_parameters=[
{'params':[p for n,p in param_optimizer if not any (nd in n for nd in no_decay)],'weight_decay':0.01}, ##找出需要更新的参数
{'params': [p for n, p in param_optimizer if any(nd in n for nd in no_decay)],'weight_decay':0.0}
]
##2.配置优化器
optimizer= BertAdam(params=optimizer_grouped_parameters,
lr=config.learning_rate,
warmup=0.05,
t_total=len(train_iter)*config.num_epochs)
total_batch=0 #记录进行多少batch
dev_best_loss=float('inf') ##记录校验集最好的loss
last_improve=0 #记录上次校验集loss下降的batch数 上一次哪个batch更新了loss
flag=False ##模型训练是否长时间无提升
model.train()
for epoch in range(config.num_epochs):
print('Epoch[{}/{}]'.format(epoch+1,config.num_epochs))
for i,(trains,labels) in enumerate(train_iter): ##每次取出一个batch数,更新一次梯度
outputs = model(trains)
model.zero_grad()##梯度清零
loss =F.cross_entropy(outputs,labels) ##计算损失
loss.backward(retain_graph=False) ##反向传播
optimizer.step() ##更新优化器参数
if total_batch%100==0:
true = labels.data.cpu() ##真实标签
predict = torch.max(outputs.data,1)[1].cpu() #预测标签
train_acc = metrics.accuracy_score(true,predict) ##计算准确率
dev_acc,dev_loss =evaluate(config,model,dev_iter) ##计算校验集的准确率和损失
if dev_loss < dev_best_loss:
dev_best_loss = dev_loss
torch.save(model.state_dict(),config.save_path) ##保存最好的模型
improve = '*'
last_improve = total_batch
else:
improve = ''
time_dif=utils.get_time_dif(start_time)
msg = 'Iter:{0:>6},Train Loss:{1:>5.2},Train Acc{2:>6.2},Val Loss:{3:>5.2},Val Acc:{4:>6.2%},Time:{5} {6}' ##打印日志
print(msg.format(total_batch, loss.item(), train_acc, dev_loss, dev_acc, time_dif, improve))
model.train()
total_batch+=1
if total_batch-last_improve > config.require_improvement:
print('已经超过1000次没有提升,自动退出')
flag = True
break
if flag:
break
test(config, model, test_iter)
def evaluate:
def evaluate(config,model,dev_iter,test=False):
"""
:param config:
:param model:
:param dev:
:param iter:
:return:
"""
# 在 eval模式下,dropout层会让所有的激活单元都通过,而batchnorm层会停止计算和更新mean和var,直接使用在训练阶段已经学出的mean和var值。
model.eval()
loss_total=0
predict_all= np.array([],dtype=int)
labels_all= np.array([],dtype=int)
with torch.no_grad():
for texts,labels in dev_iter:
outputs = model(texts)
loss = F.cross_entropy(outputs,labels)
loss_total += loss
labels=labels.data.cpu().numpy()
# torch.max 返回两个值,一个每个样本最大分类类别的概率,一个是最大值对应的索引,参数1是对每行求最大值
predict = torch.max(outputs.data,1)[1].cpu().numpy()
labels_all=np.append(labels_all,labels)
predict_all=np.append(predict_all,predict)
acc = metrics.accuracy_score(labels_all,predict_all)
if test:
report=metrics.classification_report(labels_all,predict_all,target_names=config.class_list,digits=4)
confusion = metrics.confusion_matrix(labels_all,predict_all)
return acc,loss_total / len(dev_iter), report,confusion
return acc,loss_total / len(dev_iter)
def test:
def test(config, model, test_iter):
'''
读取训练好的模型,启用 eval()模式,dropout层会让所有的激活单元都通过,batch norm 层会停止计算和更新mean和var,直接使用在训练阶段已经学出的mean和var值。
调用评估函数计算测试集的损失、准确率等信息
:param config:
:param model:
:param test_iter:
:return:
'''
model.load_state_dict(torch.load(config.save_path))
model.eval()
start_time = time.time()
test_acc,test_loss,test_report,test_confusion = evaluate(config,model,test_iter,test=True)
msg = 'Test Loss:{0:>5.2}, Test Acc:{1:>6.2%}'
print(msg.format(test_loss, test_acc))
print("Precision,Recall and F1-Score")
print(test_report)
print('Confusion Maxtrix')
print(test_confusion)
time_dif = utils.get_time_dif(start_time)
print('使用时间:', time_dif)
5.main.py
parser = argparse.ArgumentParser(description='RenBert-text-classfication')
parser.add_argument('--model',type=str ,default='RenBert',help='choose a model')
args = parser.parse_args()
if __name__=='__main__':
dataset = 'THUCNews'
model_name = args.model
x = import_module('models.' + model_name)
config = x.Config(dataset)
np.random.seed(1)
torch.manual_seed(1)
torch.cuda.manual_seed_all(4)
torch.backends.cudnn.deterministic =True
start_time = time.time()
print('加载数据集')
train_data,dev_data,test_data = utils.bulid_dataset(config)
train_iter=utils.bulid_iterator(train_data,config)
# for i,(trains,labels) in enumerate(train_iter):
# print(i,labels)
dev_iter = utils.bulid_iterator(dev_data,config)
test_iter = utils.bulid_iterator(test_data , config)
time_dif = utils.get_time_dif(start_time)##准备数据结束
print('数据准备时间为:',time_dif)
#模型训练
model = x.Model(config).to(config.device)
train.train(config,model,train_iter,dev_iter,test_iter)
# train.test(config,model,test_iter)
6.运行结果(此为GPU上运行的)
加载数据集
数据准备时间为: 0:00:01
Epoch[1/3]
/home/blues/Renyz/text_classfication/pytorch_pretrained/optimization.py:275: UserWarning: This overload of add_ is deprecated:
add_(Number alpha, Tensor other)
Consider using one of the following signatures instead:
add_(Tensor other, *, Number alpha) (Triggered internally at /opt/conda/conda-bld/pytorch_1639180543123/work/torch/csrc/utils/python_arg_parser.cpp:1050.)
next_m.mul_(beta1).add_(1 - beta1, grad)
Iter: 0,Train Loss: 2.5,Train Acc 0.094,Val Loss: 2.5,Val Acc:10.16%,Time:0:00:09 *
Iter: 100,Train Loss: 1.7,Train Acc 0.44,Val Loss: 1.8,Val Acc:41.89%,Time:0:00:50 *
Iter: 200,Train Loss: 1.5,Train Acc 0.47,Val Loss: 1.2,Val Acc:61.18%,Time:0:01:31 *
Iter: 300,Train Loss: 0.85,Train Acc 0.72,Val Loss: 0.9,Val Acc:71.20%,Time:0:02:13 *
Iter: 400,Train Loss: 0.77,Train Acc 0.79,Val Loss: 0.78,Val Acc:75.56%,Time:0:02:56 *
Iter: 500,Train Loss: 0.73,Train Acc 0.79,Val Loss: 0.74,Val Acc:77.01%,Time:0:03:38 *
Iter: 600,Train Loss: 0.71,Train Acc 0.76,Val Loss: 0.63,Val Acc:80.45%,Time:0:04:21 *
Iter: 700,Train Loss: 0.74,Train Acc 0.77,Val Loss: 0.6,Val Acc:81.03%,Time:0:05:04 *
Iter: 800,Train Loss: 0.53,Train Acc 0.81,Val Loss: 0.59,Val Acc:81.68%,Time:0:05:47 *
Iter: 900,Train Loss: 0.58,Train Acc 0.83,Val Loss: 0.55,Val Acc:83.30%,Time:0:06:29 *
Iter: 1000,Train Loss: 0.42,Train Acc 0.84,Val Loss: 0.52,Val Acc:84.02%,Time:0:07:12 *
Iter: 1100,Train Loss: 0.41,Train Acc 0.88,Val Loss: 0.52,Val Acc:84.12%,Time:0:07:55
Iter: 1200,Train Loss: 0.47,Train Acc 0.84,Val Loss: 0.49,Val Acc:84.99%,Time:0:08:39 *
Iter: 1300,Train Loss: 0.45,Train Acc 0.87,Val Loss: 0.5,Val Acc:84.78%,Time:0:09:21
Iter: 1400,Train Loss: 0.64,Train Acc 0.79,Val Loss: 0.49,Val Acc:85.03%,Time:0:10:04
Epoch[2/3]
Iter: 1500,Train Loss: 0.52,Train Acc 0.84,Val Loss: 0.49,Val Acc:85.07%,Time:0:10:46
Iter: 1600,Train Loss: 0.39,Train Acc 0.86,Val Loss: 0.49,Val Acc:85.06%,Time:0:11:29 *
Iter: 1700,Train Loss: 0.37,Train Acc 0.89,Val Loss: 0.48,Val Acc:85.65%,Time:0:12:12 *
Iter: 1800,Train Loss: 0.31,Train Acc 0.94,Val Loss: 0.45,Val Acc:86.16%,Time:0:12:55 *
Iter: 1900,Train Loss: 0.41,Train Acc 0.88,Val Loss: 0.45,Val Acc:86.26%,Time:0:13:37 *
Iter: 2000,Train Loss: 0.45,Train Acc 0.88,Val Loss: 0.44,Val Acc:86.67%,Time:0:14:20 *
Iter: 2100,Train Loss: 0.48,Train Acc 0.85,Val Loss: 0.43,Val Acc:86.92%,Time:0:15:02 *
Iter: 2200,Train Loss: 0.25,Train Acc 0.92,Val Loss: 0.43,Val Acc:86.99%,Time:0:15:44 *
Iter: 2300,Train Loss: 0.31,Train Acc 0.91,Val Loss: 0.43,Val Acc:87.01%,Time:0:16:25
Iter: 2400,Train Loss: 0.34,Train Acc 0.91,Val Loss: 0.44,Val Acc:86.56%,Time:0:17:05
Iter: 2500,Train Loss: 0.29,Train Acc 0.92,Val Loss: 0.42,Val Acc:87.46%,Time:0:17:48 *
Iter: 2600,Train Loss: 0.46,Train Acc 0.86,Val Loss: 0.42,Val Acc:87.27%,Time:0:18:28
Iter: 2700,Train Loss: 0.39,Train Acc 0.86,Val Loss: 0.42,Val Acc:87.10%,Time:0:19:11 *
Iter: 2800,Train Loss: 0.56,Train Acc 0.8,Val Loss: 0.42,Val Acc:87.36%,Time:0:19:51
Epoch[3/3]
Iter: 2900,Train Loss: 0.34,Train Acc 0.91,Val Loss: 0.41,Val Acc:87.63%,Time:0:20:33 *
Iter: 3000,Train Loss: 0.36,Train Acc 0.86,Val Loss: 0.41,Val Acc:87.70%,Time:0:21:13
Iter: 3100,Train Loss: 0.27,Train Acc 0.91,Val Loss: 0.41,Val Acc:87.84%,Time:0:21:56 *
Iter: 3200,Train Loss: 0.49,Train Acc 0.9,Val Loss: 0.41,Val Acc:87.72%,Time:0:22:36
Iter: 3300,Train Loss: 0.38,Train Acc 0.91,Val Loss: 0.4,Val Acc:87.93%,Time:0:23:19 *
Iter: 3400,Train Loss: 0.42,Train Acc 0.88,Val Loss: 0.41,Val Acc:87.70%,Time:0:23:59
Iter: 3500,Train Loss: 0.31,Train Acc 0.88,Val Loss: 0.4,Val Acc:87.66%,Time:0:24:40
Iter: 3600,Train Loss: 0.3,Train Acc 0.92,Val Loss: 0.4,Val Acc:87.86%,Time:0:25:20
Iter: 3700,Train Loss: 0.46,Train Acc 0.85,Val Loss: 0.4,Val Acc:87.82%,Time:0:26:03 *
Iter: 3800,Train Loss: 0.33,Train Acc 0.91,Val Loss: 0.4,Val Acc:87.89%,Time:0:26:45 *
Iter: 3900,Train Loss: 0.4,Train Acc 0.88,Val Loss: 0.39,Val Acc:88.11%,Time:0:27:27 *
Iter: 4000,Train Loss: 0.29,Train Acc 0.91,Val Loss: 0.39,Val Acc:88.17%,Time:0:28:08
Iter: 4100,Train Loss: 0.33,Train Acc 0.89,Val Loss: 0.39,Val Acc:88.19%,Time:0:28:48
Iter: 4200,Train Loss: 0.46,Train Acc 0.85,Val Loss: 0.39,Val Acc:88.18%,Time:0:29:31 *
Training beyond specified 't_total'. Learning rate multiplier set to 0.0. Please set 't_total' of WarmupLinearSchedule correctly.
Training beyond specified 't_total'. Learning rate multiplier set to 0.0. Please set 't_total' of WarmupLinearSchedule correctly.
Test Loss: 0.38, Test Acc:88.28%
Precision,Recall and F1-Score
precision recall f1-score support
finance 0.8707 0.8550 0.8628 1000
realty 0.9026 0.9080 0.9053 1000
stocks 0.8115 0.7920 0.8016 1000
education 0.9150 0.9260 0.9205 1000
science 0.8525 0.7920 0.8212 1000
society 0.8819 0.8960 0.8889 1000
politics 0.8298 0.8680 0.8485 1000
sports 0.9574 0.9660 0.9617 1000
game 0.9127 0.9200 0.9163 1000
entertainment 0.8907 0.9050 0.8978 1000
accuracy 0.8828 10000
macro avg 0.8825 0.8828 0.8824 10000
weighted avg 0.8825 0.8828 0.8824 10000
Confusion Maxtrix
[[855 23 75 4 8 6 17 2 4 6]
[ 16 908 16 6 4 20 8 8 5 9]
[ 67 29 792 4 51 2 39 4 9 3]
[ 3 0 3 926 4 21 22 2 6 13]
[ 13 14 45 13 792 19 28 3 43 30]
[ 3 10 4 21 8 896 35 0 7 16]
[ 13 10 29 16 12 26 868 5 4 17]
[ 1 1 2 2 3 5 11 966 0 9]
[ 5 4 9 5 35 5 7 2 920 8]
[ 6 7 1 15 12 16 11 17 10 905]]
使用时间: 0:00:07
Process finished with exit code 0
Bert+CNN中文文本分类的实战
其余部分没有变化,只是模型代码进行了变化
import torch
import torch.nn as nn
from pytorch_pretrained import BertModel,BertTokenizer
import torch.nn.functional as F
class Config(object):
def __init__(self,dataset):
self.model_name='RenBertCNN'
self.train_path = dataset + '/data/train.txt'
self.dev_path = dataset +'/data/dev.txt'
self.test_path = dataset + '/data/test.txt'
self.datasetpkl = dataset +'/data/dataset.pkl'
self.class_list = [x.strip() for x in open(dataset +'/data/class.txt').readlines()]
self.num_classes = len(self.class_list)
self.save_path = dataset + '/saved_dict/' + self.model_name + '.ckpt'
self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
self.require_improvement = 1000
self.num_epochs = 3
self.batch_size = 128
self.pad_size = 32
self.learning_rate = 1e-5
self.bert_path = './bert_pretrain'
self.tokenizer = BertTokenizer.from_pretrained(self.bert_path)
self.hidden_size = 768
##CNN中参数
self.filter_sizes=(2,3,4)
self.num_filters = 256
self.dropout = 0.5
class Model(nn.Module):
def __init__(self,config):
super(Model, self).__init__()
self.bert = BertModel.from_pretrained(config.bert_path)
for param in self.bert.parameters():
param.requires_grad = True
self.convs=nn.ModuleList(
[nn.Conv2d(in_channels=1, out_channels=config.num_filters, kernel_size=(k,config.hidden_size)) for k in config.filter_sizes]
)
self.dropout = nn.Dropout(config.dropout)
self.fc = nn.Linear(config.num_filters*len(config.filter_sizes) , config.num_classes)
def forward(self,x):
context = x[0]
mask = x[2]
encoder_out,pooled = self.bert(context, attention_mask = mask ,output_all_encoded_layers = False)
out = encoder_out.unsqueeze(1)
out = torch.cat([self.conv_and_pool(out,conv) for conv in self.convs],1)
out = self.dropout(out)
out = self.fc(out)
return out
def conv_and_pool(self,x,conv):
x = conv(x)
x = F.relu(x)
x = x.squeeze(3)
size = x.size(2)
x = F.max_pool1d(x, size)
x = x.squeeze(2)
return x
实验结果如下:
加载数据集
数据准备时间为: 0:00:01
Epoch[1/3]
/home/blues/Renyz/text_classfication/pytorch_pretrained/optimization.py:275: UserWarning: This overload of add_ is deprecated:
add_(Number alpha, Tensor other)
Consider using one of the following signatures instead:
add_(Tensor other, *, Number alpha) (Triggered internally at /opt/conda/conda-bld/pytorch_1639180543123/work/torch/csrc/utils/python_arg_parser.cpp:1050.)
next_m.mul_(beta1).add_(1 - beta1, grad)
Iter: 0,Train Loss: 2.4,Train Acc 0.078,Val Loss: 2.4,Val Acc:10.37%,Time:0:00:08 *
Iter: 100,Train Loss: 1.7,Train Acc 0.45,Val Loss: 1.8,Val Acc:39.96%,Time:0:00:59 *
Iter: 200,Train Loss: 1.3,Train Acc 0.56,Val Loss: 1.1,Val Acc:63.37%,Time:0:01:51 *
Iter: 300,Train Loss: 0.83,Train Acc 0.69,Val Loss: 0.86,Val Acc:72.98%,Time:0:02:42 *
Iter: 400,Train Loss: 0.74,Train Acc 0.79,Val Loss: 0.74,Val Acc:76.47%,Time:0:03:34 *
Iter: 500,Train Loss: 0.69,Train Acc 0.78,Val Loss: 0.67,Val Acc:78.99%,Time:0:04:26 *
Iter: 600,Train Loss: 0.68,Train Acc 0.82,Val Loss: 0.62,Val Acc:80.85%,Time:0:05:18 *
Iter: 700,Train Loss: 0.77,Train Acc 0.78,Val Loss: 0.58,Val Acc:82.13%,Time:0:06:10 *
Iter: 800,Train Loss: 0.45,Train Acc 0.88,Val Loss: 0.57,Val Acc:82.66%,Time:0:07:02 *
Iter: 900,Train Loss: 0.55,Train Acc 0.84,Val Loss: 0.53,Val Acc:83.76%,Time:0:07:54 *
Iter: 1000,Train Loss: 0.38,Train Acc 0.89,Val Loss: 0.52,Val Acc:84.13%,Time:0:08:47 *
Iter: 1100,Train Loss: 0.44,Train Acc 0.86,Val Loss: 0.5,Val Acc:84.55%,Time:0:09:39 *
Iter: 1200,Train Loss: 0.47,Train Acc 0.84,Val Loss: 0.49,Val Acc:85.13%,Time:0:10:32 *
Iter: 1300,Train Loss: 0.45,Train Acc 0.84,Val Loss: 0.5,Val Acc:84.63%,Time:0:11:23
Iter: 1400,Train Loss: 0.68,Train Acc 0.77,Val Loss: 0.49,Val Acc:85.01%,Time:0:12:16 *
Epoch[2/3]
Iter: 1500,Train Loss: 0.45,Train Acc 0.87,Val Loss: 0.47,Val Acc:85.39%,Time:0:13:09 *
Iter: 1600,Train Loss: 0.37,Train Acc 0.87,Val Loss: 0.48,Val Acc:85.22%,Time:0:14:01
Iter: 1700,Train Loss: 0.44,Train Acc 0.88,Val Loss: 0.45,Val Acc:86.28%,Time:0:14:56 *
Iter: 1800,Train Loss: 0.32,Train Acc 0.91,Val Loss: 0.44,Val Acc:86.54%,Time:0:15:50 *
Iter: 1900,Train Loss: 0.42,Train Acc 0.87,Val Loss: 0.43,Val Acc:86.56%,Time:0:16:44 *
Iter: 2000,Train Loss: 0.47,Train Acc 0.89,Val Loss: 0.42,Val Acc:87.29%,Time:0:17:38 *
Iter: 2100,Train Loss: 0.46,Train Acc 0.86,Val Loss: 0.42,Val Acc:87.27%,Time:0:18:32 *
Iter: 2200,Train Loss: 0.34,Train Acc 0.9,Val Loss: 0.43,Val Acc:87.04%,Time:0:19:24
Iter: 2300,Train Loss: 0.35,Train Acc 0.89,Val Loss: 0.43,Val Acc:86.82%,Time:0:20:17
Iter: 2400,Train Loss: 0.37,Train Acc 0.89,Val Loss: 0.43,Val Acc:86.94%,Time:0:21:09
Iter: 2500,Train Loss: 0.36,Train Acc 0.88,Val Loss: 0.41,Val Acc:87.69%,Time:0:22:04 *
Iter: 2600,Train Loss: 0.41,Train Acc 0.91,Val Loss: 0.41,Val Acc:87.48%,Time:0:22:56
Iter: 2700,Train Loss: 0.38,Train Acc 0.88,Val Loss: 0.41,Val Acc:87.29%,Time:0:23:51 *
Iter: 2800,Train Loss: 0.56,Train Acc 0.8,Val Loss: 0.4,Val Acc:87.46%,Time:0:24:45 *
Epoch[3/3]
Iter: 2900,Train Loss: 0.35,Train Acc 0.89,Val Loss: 0.4,Val Acc:87.96%,Time:0:25:38 *
Iter: 3000,Train Loss: 0.35,Train Acc 0.88,Val Loss: 0.39,Val Acc:88.02%,Time:0:26:32 *
Iter: 3100,Train Loss: 0.34,Train Acc 0.91,Val Loss: 0.39,Val Acc:87.96%,Time:0:27:26 *
Iter: 3200,Train Loss: 0.53,Train Acc 0.87,Val Loss: 0.4,Val Acc:87.83%,Time:0:28:18
Iter: 3300,Train Loss: 0.39,Train Acc 0.9,Val Loss: 0.39,Val Acc:88.06%,Time:0:29:11 *
Iter: 3400,Train Loss: 0.38,Train Acc 0.9,Val Loss: 0.4,Val Acc:87.75%,Time:0:30:02
Iter: 3500,Train Loss: 0.28,Train Acc 0.91,Val Loss: 0.39,Val Acc:88.10%,Time:0:30:53
Iter: 3600,Train Loss: 0.33,Train Acc 0.92,Val Loss: 0.39,Val Acc:87.93%,Time:0:31:44
Iter: 3700,Train Loss: 0.4,Train Acc 0.86,Val Loss: 0.39,Val Acc:88.06%,Time:0:32:37 *
Iter: 3800,Train Loss: 0.39,Train Acc 0.87,Val Loss: 0.39,Val Acc:87.96%,Time:0:33:28
Iter: 3900,Train Loss: 0.39,Train Acc 0.88,Val Loss: 0.38,Val Acc:88.34%,Time:0:34:21 *
Iter: 4000,Train Loss: 0.23,Train Acc 0.95,Val Loss: 0.38,Val Acc:88.07%,Time:0:35:12
Iter: 4100,Train Loss: 0.34,Train Acc 0.88,Val Loss: 0.38,Val Acc:88.15%,Time:0:36:03
Iter: 4200,Train Loss: 0.48,Train Acc 0.86,Val Loss: 0.38,Val Acc:88.17%,Time:0:36:56 *
Training beyond specified 't_total'. Learning rate multiplier set to 0.0. Please set 't_total' of WarmupLinearSchedule correctly.
Training beyond specified 't_total'. Learning rate multiplier set to 0.0. Please set 't_total' of WarmupLinearSchedule correctly.
Test Loss: 0.37, Test Acc:88.73%
Precision,Recall and F1-Score
precision recall f1-score support
finance 0.8735 0.8630 0.8682 1000
realty 0.9055 0.9100 0.9077 1000
stocks 0.8202 0.8030 0.8115 1000
education 0.9296 0.9370 0.9333 1000
science 0.8446 0.7990 0.8212 1000
society 0.8791 0.8940 0.8865 1000
politics 0.8392 0.8770 0.8577 1000
sports 0.9746 0.9610 0.9678 1000
game 0.9165 0.9110 0.9137 1000
entertainment 0.8895 0.9180 0.9035 1000
accuracy 0.8873 10000
macro avg 0.8872 0.8873 0.8871 10000
weighted avg 0.8872 0.8873 0.8871 10000
Confusion Maxtrix
[[863 19 68 4 6 10 18 1 4 7]
[ 13 910 17 7 8 17 11 4 3 10]
[ 71 24 803 2 47 4 32 5 7 5]
[ 2 1 2 937 6 18 14 1 6 13]
[ 9 11 46 9 799 20 31 1 46 28]
[ 4 16 4 18 7 894 35 1 6 15]
[ 14 9 24 14 17 25 877 1 1 18]
[ 3 2 3 3 2 6 10 961 0 10]
[ 5 6 9 4 41 6 8 2 911 8]
[ 4 7 3 10 13 17 9 9 10 918]]
使用时间: 0:00:07
测试集上的精度略有提高
Bert+RNN中文文本分类的实战
模型代码部分:
import torch
import torch.nn as nn
from pytorch_pretrained import BertModel,BertTokenizer
import torch.nn.functional as F
class Config(object):
def __init__(self,dataset):
self.model_name='RenBertRNN'
self.train_path = dataset + '/data/train.txt'
self.dev_path = dataset +'/data/dev.txt'
self.test_path = dataset + '/data/test.txt'
self.datasetpkl = dataset +'/data/dataset.pkl'
self.class_list = [x.strip() for x in open(dataset +'/data/class.txt').readlines()]
self.num_classes = len(self.class_list)
self.save_path = dataset + '/saved_dict/' + self.model_name + '.ckpt'
self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
self.require_improvement = 1000
self.num_epochs = 3
self.batch_size = 128
self.pad_size = 32
self.learning_rate = 1e-5
self.bert_path = './bert_pretrain'
self.tokenizer = BertTokenizer.from_pretrained(self.bert_path)
self.hidden_size = 768
##RNN中参数
self.rnn_hidden = 256
self.num_layers = 2
self.dropout = 0.5
class Model(nn.Module):
def __init__(self,config):
super(Model, self).__init__()
self.bert = BertModel.from_pretrained(config.bert_path)
for param in self.bert.parameters():
param.requires_grad = True
self.lstm=nn.LSTM(config.hidden_size,config.rnn_hidden,batch_first=True,dropout=config.dropout,bidirectional=True) ##双向的LSTM
self.dropout = nn.Dropout(config.dropout)
self.fc = nn.Linear(config.rnn_hidden*2 , config.num_classes)
def forward(self,x):
context = x[0]
mask = x[2]
encoder_out,text_cls = self.bert(context, attention_mask = mask ,output_all_encoded_layers = False)
out,_ = self.lstm(encoder_out)
out = self.dropout(out) #shape[128,32,512]
out = out[:,-1,:] #shape[128,512]
out = self.fc(out)
return out
训练结果:
加载数据集
数据准备时间为: 0:00:01
/home/blues/anaconda3/envs/ryztorch/lib/python3.7/site-packages/torch/nn/modules/rnn.py:65: UserWarning: dropout option adds dropout after all but last recurrent layer, so non-zero dropout expects num_layers greater than 1, but got dropout=0.5 and num_layers=1
"num_layers={}".format(dropout, num_layers))
Epoch[1/3]
/home/blues/Renyz/text_classfication/pytorch_pretrained/optimization.py:275: UserWarning: This overload of add_ is deprecated:
add_(Number alpha, Tensor other)
Consider using one of the following signatures instead:
add_(Tensor other, *, Number alpha) (Triggered internally at /opt/conda/conda-bld/pytorch_1639180543123/work/torch/csrc/utils/python_arg_parser.cpp:1050.)
next_m.mul_(beta1).add_(1 - beta1, grad)
Iter: 0,Train Loss: 2.3,Train Acc 0.12,Val Loss: 2.3,Val Acc:10.00%,Time:0:00:08 *
Iter: 100,Train Loss: 1.9,Train Acc 0.41,Val Loss: 2.0,Val Acc:36.33%,Time:0:00:51 *
Iter: 200,Train Loss: 1.6,Train Acc 0.49,Val Loss: 1.3,Val Acc:56.20%,Time:0:01:34 *
Iter: 300,Train Loss: 1.0,Train Acc 0.66,Val Loss: 0.97,Val Acc:70.00%,Time:0:02:18 *
Iter: 400,Train Loss: 0.83,Train Acc 0.75,Val Loss: 0.82,Val Acc:74.63%,Time:0:03:02 *
Iter: 500,Train Loss: 0.69,Train Acc 0.8,Val Loss: 0.76,Val Acc:76.96%,Time:0:03:46 *
Iter: 600,Train Loss: 0.7,Train Acc 0.81,Val Loss: 0.67,Val Acc:79.70%,Time:0:04:31 *
Iter: 700,Train Loss: 0.83,Train Acc 0.76,Val Loss: 0.63,Val Acc:80.53%,Time:0:05:15 *
Iter: 800,Train Loss: 0.49,Train Acc 0.86,Val Loss: 0.6,Val Acc:81.88%,Time:0:06:00 *
Iter: 900,Train Loss: 0.59,Train Acc 0.83,Val Loss: 0.58,Val Acc:82.51%,Time:0:06:45 *
Iter: 1000,Train Loss: 0.46,Train Acc 0.84,Val Loss: 0.54,Val Acc:83.46%,Time:0:07:30 *
Iter: 1100,Train Loss: 0.49,Train Acc 0.85,Val Loss: 0.53,Val Acc:83.85%,Time:0:08:15 *
Iter: 1200,Train Loss: 0.56,Train Acc 0.84,Val Loss: 0.5,Val Acc:85.01%,Time:0:09:00 *
Iter: 1300,Train Loss: 0.48,Train Acc 0.84,Val Loss: 0.52,Val Acc:84.33%,Time:0:09:43
Iter: 1400,Train Loss: 0.69,Train Acc 0.8,Val Loss: 0.51,Val Acc:84.39%,Time:0:10:26
Epoch[2/3]
Iter: 1500,Train Loss: 0.46,Train Acc 0.82,Val Loss: 0.49,Val Acc:85.22%,Time:0:11:12 *
Iter: 1600,Train Loss: 0.49,Train Acc 0.82,Val Loss: 0.51,Val Acc:84.75%,Time:0:11:55
Iter: 1700,Train Loss: 0.45,Train Acc 0.89,Val Loss: 0.49,Val Acc:85.51%,Time:0:12:40 *
Iter: 1800,Train Loss: 0.33,Train Acc 0.91,Val Loss: 0.47,Val Acc:86.01%,Time:0:13:25 *
Iter: 1900,Train Loss: 0.46,Train Acc 0.84,Val Loss: 0.46,Val Acc:86.00%,Time:0:14:10 *
Iter: 2000,Train Loss: 0.49,Train Acc 0.86,Val Loss: 0.45,Val Acc:86.59%,Time:0:14:55 *
Iter: 2100,Train Loss: 0.52,Train Acc 0.83,Val Loss: 0.45,Val Acc:86.55%,Time:0:15:40 *
Iter: 2200,Train Loss: 0.34,Train Acc 0.91,Val Loss: 0.44,Val Acc:86.95%,Time:0:16:25 *
Iter: 2300,Train Loss: 0.33,Train Acc 0.88,Val Loss: 0.44,Val Acc:86.86%,Time:0:17:08
Iter: 2400,Train Loss: 0.34,Train Acc 0.88,Val Loss: 0.45,Val Acc:86.61%,Time:0:17:51
Iter: 2500,Train Loss: 0.32,Train Acc 0.91,Val Loss: 0.44,Val Acc:87.03%,Time:0:18:36 *
Iter: 2600,Train Loss: 0.42,Train Acc 0.88,Val Loss: 0.43,Val Acc:87.29%,Time:0:19:21 *
Iter: 2700,Train Loss: 0.38,Train Acc 0.88,Val Loss: 0.43,Val Acc:86.95%,Time:0:20:04
Iter: 2800,Train Loss: 0.58,Train Acc 0.8,Val Loss: 0.42,Val Acc:87.13%,Time:0:20:49 *
Epoch[3/3]
Iter: 2900,Train Loss: 0.37,Train Acc 0.87,Val Loss: 0.42,Val Acc:87.68%,Time:0:21:34 *
Iter: 3000,Train Loss: 0.35,Train Acc 0.91,Val Loss: 0.43,Val Acc:87.38%,Time:0:22:18
Iter: 3100,Train Loss: 0.32,Train Acc 0.91,Val Loss: 0.41,Val Acc:87.97%,Time:0:23:05 *
Iter: 3200,Train Loss: 0.58,Train Acc 0.88,Val Loss: 0.42,Val Acc:87.45%,Time:0:23:49
Iter: 3300,Train Loss: 0.39,Train Acc 0.88,Val Loss: 0.41,Val Acc:87.87%,Time:0:24:35 *
Iter: 3400,Train Loss: 0.48,Train Acc 0.9,Val Loss: 0.41,Val Acc:87.91%,Time:0:25:20
Iter: 3500,Train Loss: 0.43,Train Acc 0.88,Val Loss: 0.42,Val Acc:87.61%,Time:0:26:04
Iter: 3600,Train Loss: 0.33,Train Acc 0.91,Val Loss: 0.41,Val Acc:87.92%,Time:0:26:48
Iter: 3700,Train Loss: 0.42,Train Acc 0.84,Val Loss: 0.4,Val Acc:88.09%,Time:0:27:35 *
Iter: 3800,Train Loss: 0.35,Train Acc 0.89,Val Loss: 0.41,Val Acc:87.73%,Time:0:28:19
Iter: 3900,Train Loss: 0.46,Train Acc 0.84,Val Loss: 0.4,Val Acc:88.06%,Time:0:29:05 *
Iter: 4000,Train Loss: 0.24,Train Acc 0.95,Val Loss: 0.4,Val Acc:87.94%,Time:0:29:49
Iter: 4100,Train Loss: 0.39,Train Acc 0.89,Val Loss: 0.4,Val Acc:87.94%,Time:0:30:33
Iter: 4200,Train Loss: 0.49,Train Acc 0.86,Val Loss: 0.4,Val Acc:88.10%,Time:0:31:18
Training beyond specified 't_total'. Learning rate multiplier set to 0.0. Please set 't_total' of WarmupLinearSchedule correctly.
Training beyond specified 't_total'. Learning rate multiplier set to 0.0. Please set 't_total' of WarmupLinearSchedule correctly.
Test Loss: 0.39, Test Acc:88.23%
Precision,Recall and F1-Score
precision recall f1-score support
finance 0.8744 0.8420 0.8579 1000
realty 0.9045 0.9090 0.9067 1000
stocks 0.7907 0.8160 0.8031 1000
education 0.9146 0.9420 0.9281 1000
science 0.8328 0.7820 0.8066 1000
society 0.8835 0.8950 0.8892 1000
politics 0.8389 0.8540 0.8464 1000
sports 0.9659 0.9620 0.9639 1000
game 0.9166 0.9120 0.9143 1000
entertainment 0.9009 0.9090 0.9049 1000
accuracy 0.8823 10000
macro avg 0.8823 0.8823 0.8821 10000
weighted avg 0.8823 0.8823 0.8821 10000
Confusion Maxtrix
[[842 22 87 4 9 8 18 2 3 5]
[ 15 909 17 8 8 17 9 5 4 8]
[ 59 24 816 2 47 2 36 4 6 4]
[ 3 1 5 942 5 13 12 2 5 12]
[ 17 11 54 15 782 23 29 3 43 23]
[ 3 15 5 20 9 895 30 1 7 15]
[ 14 11 29 16 20 33 854 4 1 18]
[ 3 3 3 3 1 3 13 962 0 9]
[ 3 3 12 6 40 5 11 2 912 6]
[ 4 6 4 14 18 14 6 11 14 909]]
使用时间: 0:00:08
Process finished with exit code 0
Bert+RCNN中文文本分类的实战
原理:比较RNN多了一个maxpool
模型代码:(注意维度的变换)
import torch
import torch.nn as nn
from pytorch_pretrained import BertModel,BertTokenizer
import torch.nn.functional as F
class Config(object):
def __init__(self,dataset):
self.model_name='RenBertRNN'
self.train_path = dataset + '/data/train.txt'
self.dev_path = dataset +'/data/dev.txt'
self.test_path = dataset + '/data/test.txt'
self.datasetpkl = dataset +'/data/dataset.pkl'
self.class_list = [x.strip() for x in open(dataset +'/data/class.txt').readlines()]
self.num_classes = len(self.class_list)
self.save_path = dataset + '/saved_dict/' + self.model_name + '.ckpt'
self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
self.require_improvement = 1000
self.num_epochs = 3
self.batch_size = 128
self.pad_size = 32
self.learning_rate = 1e-5
self.bert_path = './bert_pretrain'
self.tokenizer = BertTokenizer.from_pretrained(self.bert_path)
self.hidden_size = 768
##RNN中参数
self.rnn_hidden = 256
self.num_layers = 2
self.dropout = 0.5
class Model(nn.Module):
def __init__(self,config):
super(Model, self).__init__()
self.bert = BertModel.from_pretrained(config.bert_path)
for param in self.bert.parameters():
param.requires_grad = True
self.lstm=nn.LSTM(config.hidden_size,config.rnn_hidden,config.num_classes,batch_first=True,dropout=config.dropout,bidirectional=True) ##双向的LSTM
self.maxpool = nn.MaxPool1d(config.pad_size) #?
self.dropout = nn.Dropout(config.dropout)
self.fc = nn.Linear(config.rnn_hidden*2 , config.num_classes)
def forward(self,x):
context = x[0]
mask = x[2]
encoder_out,text_cls = self.bert(context, attention_mask = mask ,output_all_encoded_layers = False)
out,_ = self.lstm(encoder_out) #shape[128,32,512]
out = F.relu(out)
out = out.permute(0,2,1) ##维度调换shape[128,512,32]
out = self.maxpool(out) #shape[128,512,1]
out = out.squeeze() ##清除数字为1的维度
out = self.fc(out)
return out
实验结果:
加载数据集
数据准备时间为: 0:00:01
Epoch[1/3]
/home/blues/Renyz/text_classfication/pytorch_pretrained/optimization.py:275: UserWarning: This overload of add_ is deprecated:
add_(Number alpha, Tensor other)
Consider using one of the following signatures instead:
add_(Tensor other, *, Number alpha) (Triggered internally at /opt/conda/conda-bld/pytorch_1639180543123/work/torch/csrc/utils/python_arg_parser.cpp:1050.)
next_m.mul_(beta1).add_(1 - beta1, grad)
Iter: 0,Train Loss: 2.3,Train Acc 0.062,Val Loss: 2.3,Val Acc:10.00%,Time:0:00:12 *
Iter: 100,Train Loss: 2.3,Train Acc 0.16,Val Loss: 2.3,Val Acc:10.00%,Time:0:01:09 *
Iter: 200,Train Loss: 2.3,Train Acc 0.12,Val Loss: 2.3,Val Acc:10.00%,Time:0:02:08 *
Iter: 300,Train Loss: 2.3,Train Acc 0.1,Val Loss: 2.3,Val Acc:10.00%,Time:0:03:06 *
Iter: 400,Train Loss: 2.3,Train Acc 0.16,Val Loss: 2.3,Val Acc:17.45%,Time:0:04:04 *
Iter: 500,Train Loss: 2.2,Train Acc 0.12,Val Loss: 2.2,Val Acc:15.12%,Time:0:05:03 *
Iter: 600,Train Loss: 2.1,Train Acc 0.17,Val Loss: 2.2,Val Acc:15.64%,Time:0:06:01 *
Iter: 700,Train Loss: 2.2,Train Acc 0.11,Val Loss: 2.2,Val Acc:16.37%,Time:0:06:59 *
Iter: 800,Train Loss: 2.2,Train Acc 0.15,Val Loss: 2.2,Val Acc:16.76%,Time:0:07:57 *
Iter: 900,Train Loss: 2.2,Train Acc 0.1,Val Loss: 2.2,Val Acc:16.56%,Time:0:08:54
Iter: 1000,Train Loss: 2.2,Train Acc 0.16,Val Loss: 2.2,Val Acc:16.61%,Time:0:09:52 *
Iter: 1100,Train Loss: 2.1,Train Acc 0.13,Val Loss: 2.2,Val Acc:16.52%,Time:0:10:48
Iter: 1200,Train Loss: 2.2,Train Acc 0.13,Val Loss: 2.2,Val Acc:16.29%,Time:0:11:45
Iter: 1300,Train Loss: 2.2,Train Acc 0.18,Val Loss: 2.2,Val Acc:16.31%,Time:0:12:40
Iter: 1400,Train Loss: 2.2,Train Acc 0.13,Val Loss: 2.2,Val Acc:15.92%,Time:0:13:36
Epoch[2/3]
Iter: 1500,Train Loss: 2.1,Train Acc 0.15,Val Loss: 2.2,Val Acc:16.64%,Time:0:14:32
Iter: 1600,Train Loss: 2.1,Train Acc 0.18,Val Loss: 2.2,Val Acc:16.64%,Time:0:15:28
Iter: 1700,Train Loss: 2.2,Train Acc 0.15,Val Loss: 2.2,Val Acc:16.31%,Time:0:16:24
Iter: 1800,Train Loss: 2.2,Train Acc 0.17,Val Loss: 2.2,Val Acc:16.96%,Time:0:17:23 *
Iter: 1900,Train Loss: 2.2,Train Acc 0.16,Val Loss: 2.2,Val Acc:16.55%,Time:0:18:19
Iter: 2000,Train Loss: 2.2,Train Acc 0.22,Val Loss: 2.2,Val Acc:16.38%,Time:0:19:15
Iter: 2100,Train Loss: 2.1,Train Acc 0.16,Val Loss: 2.2,Val Acc:16.54%,Time:0:20:11
Iter: 2200,Train Loss: 2.2,Train Acc 0.16,Val Loss: 2.2,Val Acc:16.07%,Time:0:21:07
Iter: 2300,Train Loss: 2.1,Train Acc 0.2,Val Loss: 2.2,Val Acc:16.06%,Time:0:22:03
Iter: 2400,Train Loss: 2.1,Train Acc 0.16,Val Loss: 2.2,Val Acc:16.76%,Time:0:23:00
Iter: 2500,Train Loss: 2.1,Train Acc 0.13,Val Loss: 2.2,Val Acc:16.59%,Time:0:23:56
Iter: 2600,Train Loss: 2.1,Train Acc 0.19,Val Loss: 2.2,Val Acc:16.34%,Time:0:24:52
Iter: 2700,Train Loss: 2.1,Train Acc 0.23,Val Loss: 2.2,Val Acc:17.29%,Time:0:25:50 *
Iter: 2800,Train Loss: 2.1,Train Acc 0.19,Val Loss: 2.2,Val Acc:17.43%,Time:0:26:48 *
Epoch[3/3]
Iter: 2900,Train Loss: 2.1,Train Acc 0.19,Val Loss: 2.2,Val Acc:17.35%,Time:0:27:43
Iter: 3000,Train Loss: 2.1,Train Acc 0.17,Val Loss: 2.2,Val Acc:16.97%,Time:0:28:39
Iter: 3100,Train Loss: 2.2,Train Acc 0.1,Val Loss: 2.2,Val Acc:17.44%,Time:0:29:38 *
Iter: 3200,Train Loss: 2.2,Train Acc 0.12,Val Loss: 2.2,Val Acc:17.32%,Time:0:30:36 *
Iter: 3300,Train Loss: 2.2,Train Acc 0.16,Val Loss: 2.1,Val Acc:17.58%,Time:0:31:34 *
Iter: 3400,Train Loss: 2.1,Train Acc 0.15,Val Loss: 2.1,Val Acc:17.73%,Time:0:32:32 *
Iter: 3500,Train Loss: 2.2,Train Acc 0.12,Val Loss: 2.1,Val Acc:17.83%,Time:0:33:30 *
Iter: 3600,Train Loss: 2.2,Train Acc 0.16,Val Loss: 2.1,Val Acc:18.01%,Time:0:34:29 *
Iter: 3700,Train Loss: 2.2,Train Acc 0.19,Val Loss: 2.1,Val Acc:17.97%,Time:0:35:26 *
Iter: 3800,Train Loss: 2.0,Train Acc 0.2,Val Loss: 2.1,Val Acc:18.13%,Time:0:36:23
Iter: 3900,Train Loss: 2.1,Train Acc 0.16,Val Loss: 2.1,Val Acc:18.23%,Time:0:37:21 *
Iter: 4000,Train Loss: 2.1,Train Acc 0.15,Val Loss: 2.1,Val Acc:18.19%,Time:0:38:20 *
Iter: 4100,Train Loss: 2.2,Train Acc 0.15,Val Loss: 2.1,Val Acc:18.33%,Time:0:39:15
Iter: 4200,Train Loss: 2.2,Train Acc 0.16,Val Loss: 2.1,Val Acc:18.26%,Time:0:40:12
Training beyond specified 't_total'. Learning rate multiplier set to 0.0. Please set 't_total' of WarmupLinearSchedule correctly.
Training beyond specified 't_total'. Learning rate multiplier set to 0.0. Please set 't_total' of WarmupLinearSchedule correctly.
/home/blues/anaconda3/envs/ryztorch/lib/python3.7/site-packages/sklearn/metrics/_classification.py:1318: UndefinedMetricWarning: Precision and F-score are ill-defined and being set to 0.0 in labels with no predicted samples. Use `zero_division` parameter to control this behavior.
_warn_prf(average, modifier, msg_start, len(result))
/home/blues/anaconda3/envs/ryztorch/lib/python3.7/site-packages/sklearn/metrics/_classification.py:1318: UndefinedMetricWarning: Precision and F-score are ill-defined and being set to 0.0 in labels with no predicted samples. Use `zero_division` parameter to control this behavior.
_warn_prf(average, modifier, msg_start, len(result))
/home/blues/anaconda3/envs/ryztorch/lib/python3.7/site-packages/sklearn/metrics/_classification.py:1318: UndefinedMetricWarning: Precision and F-score are ill-defined and being set to 0.0 in labels with no predicted samples. Use `zero_division` parameter to control this behavior.
_warn_prf(average, modifier, msg_start, len(result))
Test Loss: 2.1, Test Acc:18.11%
Precision,Recall and F1-Score
precision recall f1-score support
finance 0.0000 0.0000 0.0000 1000
realty 0.0000 0.0000 0.0000 1000
stocks 0.0000 0.0000 0.0000 1000
education 0.8322 0.8230 0.8276 1000
science 0.0000 0.0000 0.0000 1000
society 0.0000 0.0000 0.0000 1000
politics 0.0000 0.0000 0.0000 1000
sports 0.1096 0.9880 0.1974 1000
game 0.0000 0.0000 0.0000 1000
entertainment 0.0000 0.0000 0.0000 1000
accuracy 0.1811 10000
macro avg 0.0942 0.1811 0.1025 10000
weighted avg 0.0942 0.1811 0.1025 10000
Confusion Maxtrix
[[ 0 0 0 11 0 0 0 989 0 0]
[ 0 0 0 12 0 0 0 988 0 0]
[ 0 0 0 10 0 0 0 990 0 0]
[ 0 0 0 823 0 0 0 177 0 0]
[ 0 0 0 21 0 0 0 979 0 0]
[ 0 0 0 46 0 0 0 954 0 0]
[ 0 0 0 19 0 0 0 981 0 0]
[ 0 0 0 12 0 0 0 988 0 0]
[ 0 0 0 18 0 0 0 982 0 0]
[ 0 0 0 17 0 0 0 983 0 0]]
使用时间: 0:00:09
Process finished with exit code 0
实验结果不对,后期再更正。。。















 2029
2029











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









