









 本文介绍了如何在OriginPro中利用批处理功能进行数据导入、清理、转换、统计分析和导出,包括在同一worksheet中对不同列的处理,以及项目文件内不同Workbook之间的数据互连。通过实例演示了如何实现批量处理,减少重复工作和提高效率。
本文介绍了如何在OriginPro中利用批处理功能进行数据导入、清理、转换、统计分析和导出,包括在同一worksheet中对不同列的处理,以及项目文件内不同Workbook之间的数据互连。通过实例演示了如何实现批量处理,减少重复工作和提高效率。
1. 引言
使用OriginPro进行批处理操作。
在处理大量数据时,重复处理往往会让人感到单调乏味。如果不采用批量处理的方法,不仅会浪费大量时间和精力,还可能会导致数据处理的错误和遗漏。因此,合理利用Origin软件内置的批处理功能,可以极大地提高数据处理效率。
Origin软件提供了一系列强大的批处理功能,让我们能够快速轻松地处理大量数据。以下是一些常用的Origin批处理功能及其应用场景:
-
数据导入:Origin可以轻松导入大量数据,支持多种文件格式,如CSV、Excel、文本文件等。通过使用批处理功能,可以一次性导入多个文件,快速整理数据。
-
数据清理:在数据处理之前,往往需要对数据进行清理。使用Origin的批处理功能,可以快速删除空值、缺失值、异常值等,提高数据质量。
-
数据转换:在数据处理过程中,经常需要进行数据转换。Origin的批处理功能可以将数据进行缩放、平移、旋转等操作,以便后续分析。
-
数据统计分析:Origin内置了丰富的统计函数和图形绘制功能,使用批处理功能可以快速对大量数据进行统计分析,并生成相应的图表。
-
数据导出:处理完数据后,我们需要将结果导出并进行可视化展示。Origin的批处理功能支持将数据导出为多种格式,如Excel、PDF、CSV等,方便结果展示和分析。
总之,Origin的批处理功能为我们提供了极大的便利性,可以快速高效地处理大量数据。在应用过程中,我们需要根据具体的数据处理需求合理选择相应的批处理功能,以达到事半功倍的效果。
2 导入操作中的批处理
当你有大量数据格式相同的csv,dat,txt文件时,可以采用origin内置的导入指令实现数据的批量处理。
示例采用Origin2017
打开一个新的origin空白项目文件,点击
将一个数据文件导入到origin中,并对其进行数据操作,比如平滑,非线性拟合,FFT变换等,得操作新生成的worksheet都在数据所在的workbook中。
完成操作之后,实现批处理的过程是,点击
选中需要重复操作的文件,导入到origin中,新导入的文件进行了和第一个文件一样的操作, 包括但不限于数据拟合,数据平滑,数据FFT,数据绘图等。
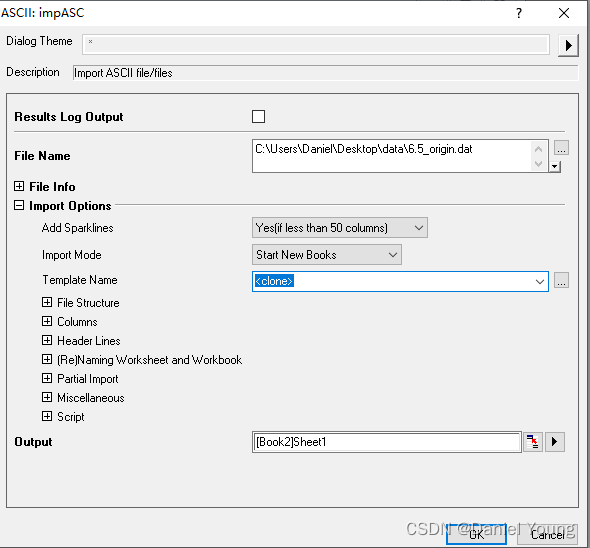
Import mode选择start New Books, Template Name 选择 < clone >,这样使得当前第一个操作完的workbook可以作为模板引导其他数据文件的导入。点击ok,完成批量导入以及批量处理。
加入图片
通过将图片嵌入到worksheet中,也可实现对图片的批量处理,并且保存复制其第一次处理的样式。
右键worksheet的空白区域
选择需要加入的图片
将图片嵌入到Worksheet中
或者将图片加入到Workbook中也是可行的
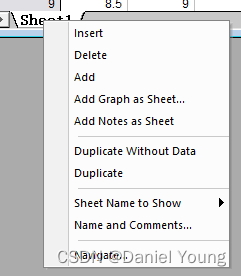
3 同一个worksheet中对不同列做相同处理的方法
以平滑为例
先对第二列数据做平滑操作,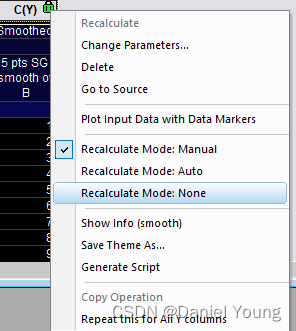
选择最后一个Repeat this for All Y colums,就可以对所有Y列进行相同的操作,包括但不限于通过set Value设置函数的操作,平滑的操作等。只要是在同一个Worksheet中带有绿锁的(链接原数据)的列基本上都可以使用这个方法进行批量处理。
4 项目文件内不同Workbook之间的互连——地址寻址
在一个opj工程文件内,有时需要将不同Workbook的某几列数据汇总到一个新的Workbook,如果是采用复制黏贴的话,对于大量数据的处理比较复杂。由于origin2017内每个元素都存在自己的调用地址,因此可以采用地址调用的方式,快速汇总这些数据。
以调用同一工程文件夹下不同Workbook的数据为例
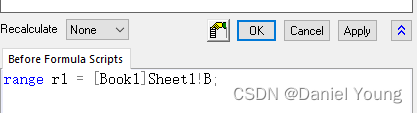
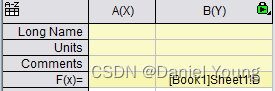
首先是要获取相应列的地址,如果采用copy-paste link的方法,所获得的是每个单元格的地址,不利于大批量调用。因此,这里我们采用range variable的方法来获取不同列的地址名,并利用F(x)或Set Value抓取列数据。
首先选择需要放置新数据的列,右键打开菜单选择Set Column Values,打开赋值界面
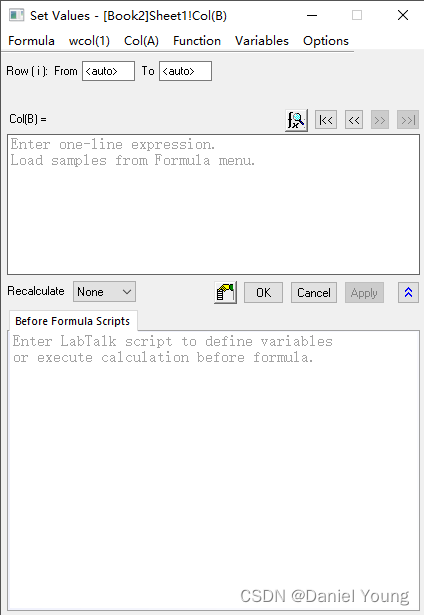
选择菜单栏的Variables,下拉菜单中找到Add Range Variable
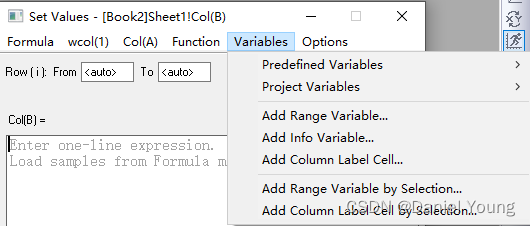
此时选择一个需要导入的列add, 并ok。这是在Set Values界面的下方就会出现以r1命名的range函数,等号后面就是相应列的地址。将这个名称复制并粘贴到F(x)=,通过更改相应的名称,我们就能快速获取不同workbook中的对应列数据。
5 总结
之前发文章介绍了originpy的python第三方库的使用,在批量获取origin文件中的拟合参数有比较不错的应用。同样利用地址寻址,也能实现这个功能。任何工具只要足够的熟练,都能带来不错的效果。
ps: 之前在网上也找过通过建立template来使用Batch processing 或者通过建立filter来使用import wizard的数据批量导入处理的方法,学习成本高,而且没有详细的教程,没法实现我想要的功能,,因此找了比较其他的方法实现数据的批量处理,简单高效,不用去管Batch processing 和 import wizard的复杂参数输入。
持续更新一些科研遇到的数据处理小技巧,欢迎交流。

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









