






Dataframe的基础操作
目录:
1、创建dataframe的几种方式
2、遍历dataframe
3、为dataframe增加一行
4、根据某列值索引dataframe的某一行
https://www.cnblogs.com/zmc940317/p/13615168.html
5、dataframe中的Nan和None,以及用哪个更好
python中None和NaN比较_python nan和none-CSDN博客
isnan() isnull() notnull() is not None 几个函数的判断区别

Pandas 修改单列,多列,Dataframe 数据类型方法汇总
Pandas 修改单列,多列,Dataframe 数据类型方法汇总_pandas指定列数据类型-CSDN博客
1、创建dataframe的几种方式
(1)创建空的DataFrame
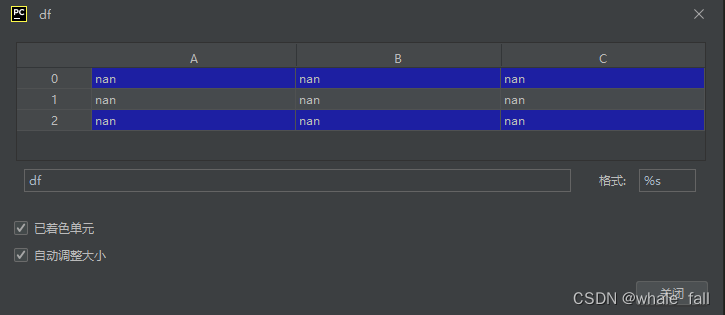
pd.DataFrame(columns=['A', 'B', 'C'], index=[0,1,2])columns参数用来定义列名,index参数用来定义行号。上面的代码创建了一个3行3列的二维数据表,所有数据项都是NaN,结果看起来是这样:
(2)手工创建有数据值的DataFrame
df = pd.DataFrame(data=['Apple','Banana','Cherry','Dates','Eggfruit'])使用data参数来声明数据,结果看起来是这样:

由于我们没有定义数据帧的列名,因此Pandas默认使用序号作为列名。和原来一样,可以使用columns参数来声明列名:
df = pd.DataFrame(data=['Apple','Banana','Cherry','Dates', 'Eggfruit'],
columns=['Fruits'])结果如下: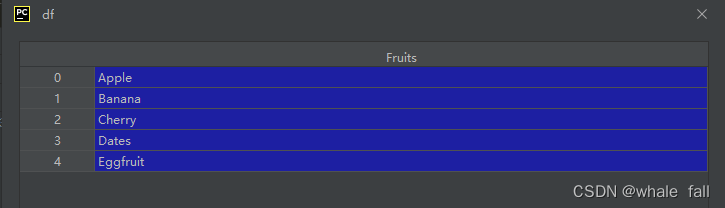
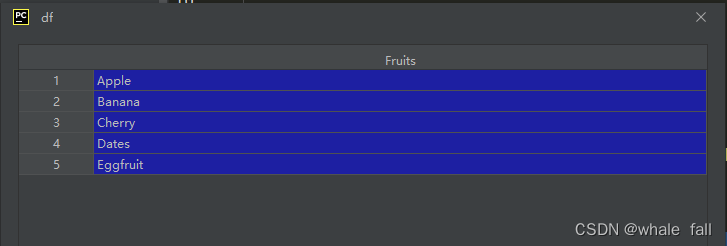
最左侧的列被称为索引,默认从0开始,和原来一样我们用index自行定义:
df = pd.DataFrame(data=['Apple','Banana','Cherry','Dates','Eggfruit'],
index = [1,2,3,4,5],
columns=['Fruits'])现在结果如下:
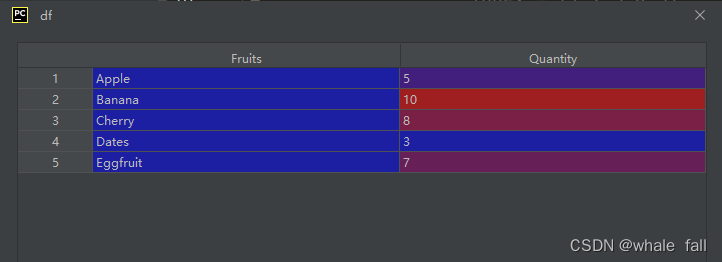
那么如果要添加一个Quantity列来表示水果数量该怎么做?即给DataFrame再增加一列:
df = pd.DataFrame(data=[['Apple',5],
['Banana',10],
['Cherry',8],
['Dates',3],
['Eggfruit',7]],
columns = ['Fruits','Quantity'],
index=[1,2,3,4,5])注意data参数和colums参数都进行了相应的调整。现在的DataFrame这样:
(3)使用列表创建DataFrame
假设我们有一个列表:
fruits_list = ['Apple','Banana','Cherry','Dates','Eggfruit'] 要把列表转换为DataFrame,直接将列表传入pd.DataFrame即可:
df = pd.DataFrame(fruits_list)得到的结果如下:
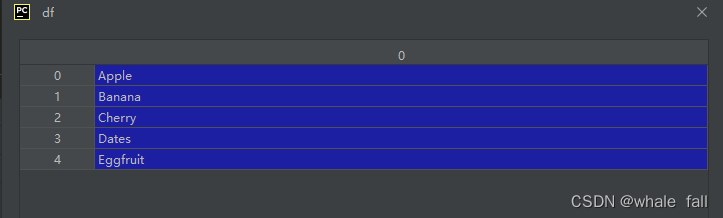
当然你可以用columns参数来定义列名,或者用index来声明行号:
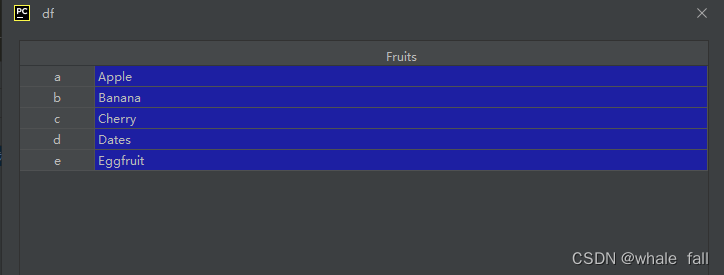
df = pd.DataFrame(fruits_list,
columns = ['Fruits'],
index = ['a','b','c','d','e'])结果如下:
(4)使用字典创建DataFrame
字典就是一组键/值对:
dict = {key1 : value1, key2 : value2, key3 : value3}当我们将上述字典对象转换为DataFrame时,看起来是这样:

容易注意到,字段的键对应成为DataFrame的列,而所有的值对应数据。 记住这个对应关系。
注意:字典的值必须是列表格式,否则会报错,例如:
dict = {"key1" : "value1", "key2" : "value2", "key3" : "value3"}
df = pd.DataFrame(dict)转换失败,报错:

将字典的值改成列表格式后:
dict = {"key1" : ["value1"], "key2" : ["value2"], "key3" : ["value3"]}
df = pd.DataFrame(dict)转换成功,结果如下:

现在假设我们要创建一个如下形状的DataFrame:
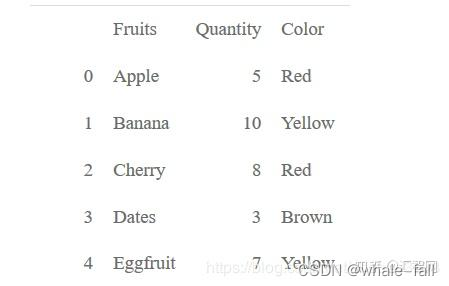
由于列名为Fruits、Quantity和Color,因此对应的字典也应当 有这几个键,而每一行的值则对应字典中的键值,字典应该是 如下的结构:
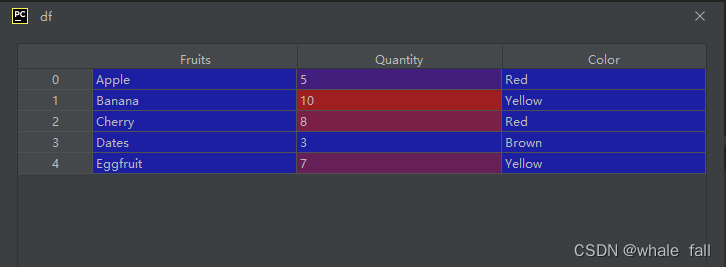
fruits_dict = { 'Fruits':['Apple','Banana','Cherry','Dates','Eggfruit'],
'Quantity': [5, 10, 8, 3, 7],
'Color': ['Red', 'Yellow', 'Red', 'Brown', 'Yellow']}现在让我们将这个字典转换为DataFrame,一句话的事儿:
df = pd.DataFrame(fruits_dict)结果如下:
(5)将excel文件转换为DataFrame
fruits_df = pd.read_excel('fruits.xlsx')2、遍历dataframe
3、为dataframe增加一行
(1)方法一,使用append()函数
append()函数可以将一个新的行添加到DataFrame的末尾。下面是一个简单的示例:
import pandas as pd
# 创建一个空的DataFrame
df = pd.DataFrame()
# 添加数据行
df = df.append({'A': 1, 'B': 2}, ignore_index=True)
df = df.append({'A': 3, 'B': 4}, ignore_index=True)在上面的示例中,我们首先创建了一个空的DataFrame。然后,我们使用append()函数两次向DataFrame中添加数据行。append()函数的第一个参数是一个字典,表示要添加的行数据。ignore_index=True参数用于重置行索引。
(2)方法二,使用loc[]方法
除了append()函数,还可以使用loc[]方法来添加数据行。下面是一个示例:
import pandas as pd
# 创建一个空的DataFrame
df = pd.DataFrame()
# 添加数据行
df.loc[0] = {'A': 1, 'B': 2}
df.loc[1] = {'A': 3, 'B': 4}在上面的示例中,我们首先创建了一个空的DataFrame。然后,我们使用loc[]方法两次向DataFrame中添加数据行。loc[]方法的第一个参数是行索引,我们在这里使用了0和1作为行索引。然后,我们将一个字典分配给该行索引,表示要添加的行数据。
需要注意的是,如果你添加的数据行数量与现有行不匹配,Pandas会自动进行填充或截断以使它们匹配。在上述示例中,我们向DataFrame中添加了两行数据,每行有两个列(’A’和’B’)。如果DataFrame的列数与添加的行不匹配,Pandas会自动添加或删除列,以使它们匹配。
总结:向Pandas DataFrame中添加数据可以使用append()函数或loc[]方法。这两种方法都很容易理解和使用。你可以根据自己的需求选择适合的方法来向DataFrame中添加数据。
参考链接:https://developer.baidu.com/article/details/2794798
4、根据某列值索引dataframe的某一行
(1)选取等于某个值的行记录 用==
df.loc[df['column_name'] == some_value](2) 选取等于某些值的行记录,即某行的某列值是否在这些范围内,用isin()
df.loc[df['column_name'].isin(some_values)](3)多种条件的选取
df.loc[(df['column_name'] == some_value) & (df['other_column_name'].isin(some_values))](4)选取不等于某些值的行记录,用 !=
df.loc[df['column_name'] != some_value](5) isin返回一系列数值,如果要选择不在这些数值范围内,不符合这个条件的用 ~
df.loc[~df['column_name'].isin(some_values)]5、read_excel()函数的各参数配置
参考链接:
python遍历多张dataframe表格(变量)的方法,其他变量也是适用_for循环同时遍历连个dataframe-CSDN博客
















 4428
4428











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









